Adatok modellezése és particionálása az Azure Cosmos DB-ben való életből vett példa használatával
A KÖVETKEZŐRE VONATKOZIK: ![]() NoSQL
NoSQL
Ez a cikk számos Azure Cosmos DB-fogalomra épül, például az adatmodellezésre, a particionálásra és a kiépített átviteli sebességre , hogy bemutassuk, hogyan lehet kezelni egy valós adattervezési gyakorlatot.
Ha általában relációs adatbázisokkal dolgozik, valószínűleg szokásokat és intuíciókat épített ki az adatmodellek tervezésére. Az Azure Cosmos DB egyedi korlátai, de egyedi erősségei miatt a legtöbb ajánlott eljárás nem fordítható le megfelelően, és az optimálisnál rosszabb megoldásokba is áthúzhatja. A cikk célja, hogy végigvezetje önt egy valós használati eset Azure Cosmos DB-n való modellezésének teljes folyamatán, az elemmodellezéstől az entitások áthelyezésén át a tárolóparticionálásig.
Fontos
Egy közösségi közreműködő hozzájárult ehhez a kódmintához, és az Azure Cosmos DB csapata nem támogatja annak karbantartását.
Esetleírás
Ebben a gyakorlatban egy blogplatform tartományát fogjuk figyelembe venni, ahol a felhasználók bejegyzéseket hozhatnak létre. A felhasználók megjegyzéseket is fűzhetnek ezekhez a bejegyzésekhez.
Tipp.
Néhány szót dőlt betűvel emeltünk ki; ezek a szavak azonosítják, hogy milyen típusú "dolgokat" kell manipulálnia a modellünknek.
További követelmények hozzáadása a specifikációnkhoz:
- A címlap megjeleníti a nemrég létrehozott bejegyzések hírcsatornáját,
- Lekérhetjük egy felhasználó összes bejegyzését, egy bejegyzéshez fűzött összes megjegyzést és a bejegyzéshez tartozó összes kedvelőt,
- A bejegyzések a szerzők felhasználónevével és a hozzájuk fűzött megjegyzések és kedvelések számával jelennek meg,
- A megjegyzéseket és kedveléseket a létrehozott felhasználók felhasználónévvel is visszaadják,
- Ha listákként jelennek meg, a bejegyzéseknek csak csonkolt összefoglalást kell bemutatniuk a tartalmukról.
A fő hozzáférési minták azonosítása
Első lépésként némi struktúrát adunk a kezdeti specifikációnkhoz a megoldás hozzáférési mintáinak azonosításával. Az Azure Cosmos DB-hez készült adatmodell tervezésekor fontos tisztában lenni azzal, hogy a modellnek mely kéréseket kell kiszolgálnia annak érdekében, hogy a modell hatékonyan kiszolgálja ezeket a kéréseket.
Az általános folyamat követésének megkönnyítése érdekében ezeket a különböző kéréseket parancsok vagy lekérdezésekként kategorizáljuk, és a CQRS-ből kölcsönözünk némi szókincset. A CQRS-ben a parancsok írási kérések (azaz a rendszer frissítésének szándékai), a lekérdezések pedig írásvédett kérések.
A platform által közzétett kérések listája:
- [C1] Felhasználó létrehozása/szerkesztése
- [1. negyedév] Felhasználó lekérése
- [C2] Bejegyzés létrehozása/szerkesztése
- [2. negyedév] Bejegyzés lekérése
- [3. negyedév] Felhasználó bejegyzésének listázása rövid formában
- [C3] Megjegyzés létrehozása
- [4. negyedév] Bejegyzések listázása
- [C4] Bejegyzés kedvelve
- [5. negyedév] Bejegyzés kedveléseinek listázása
- [6. negyedév] A rövid formában (hírcsatorna) létrehozott x legutóbbi bejegyzés listázása
Ebben a szakaszban nem gondoltunk az egyes entitások (felhasználó, bejegyzés stb.) részleteire. Ez a lépés általában az elsők közé tartozik, amelyeket a relációs tárolók tervezésekor kell kezelni. Először ezzel a lépéssel kezdjük, mert ki kell derítenünk, hogyan fordítják le az entitások a táblák, oszlopok, idegen kulcsok stb. Sokkal kevésbé aggályos egy olyan dokumentumadatbázis, amely nem kényszeríti ki a sémát íráskor.
A fő ok, amiért fontos a hozzáférési minták azonosítása az elejétől fogva, az az, hogy ez a kérések listája lesz a tesztcsomagunk. Minden alkalommal, amikor átfuttatjuk az adatmodellt, végigmegyünk az egyes kéréseken, és ellenőrizzük annak teljesítményét és méretezhetőségét. Kiszámítjuk az egyes modellekben felhasznált kérelemegységeket, és optimalizáljuk őket. Ezek a modellek az alapértelmezett indexelési szabályzatot használják, és felülbírálhatja adott tulajdonságok indexelésével, ami tovább javíthatja a ru-használatot és a késést.
V1: Az első verzió
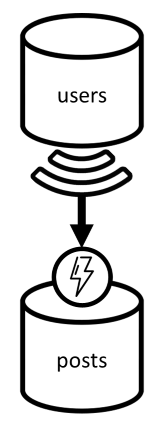
Két tárolóval kezdjük: users és posts.
Felhasználók tárolója
Ez a tároló csak a felhasználói elemeket tárolja:
{
"id": "<user-id>",
"username": "<username>"
}
Ezt a tárolót particionálással idparticionáljuk, ami azt jelenti, hogy a tárolón belül minden logikai partíció csak egy elemet tartalmaz.
Tároló bejegyzései
Ez a tároló entitásokat, például bejegyzéseket, megjegyzéseket és kedveléseket tárol:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Ezt a tárolót postIda következőképpen particionáljuk, ami azt jelenti, hogy a tárolón belül minden logikai partíció tartalmaz egy bejegyzést, az adott bejegyzéshez fűzött összes megjegyzést és az adott bejegyzéshez tartozó összes kedvelőt.
Bevezettünk egy tulajdonságot type a tárolóban tárolt elemekben, hogy megkülönböztessük a tároló által üzemeltetett három entitástípust.
Emellett úgy döntöttünk, hogy a beágyazás helyett a kapcsolódó adatokra hivatkozunk ( ebben a szakaszban az alábbi fogalmakkal kapcsolatos részleteket találjuk), mert:
- nincs felső korlátja annak, hogy a felhasználó hány bejegyzést hozhat létre,
- a bejegyzések tetszőlegesen hosszúak lehetnek,
- nincs felső határa, hogy hány megjegyzést és kedvel egy bejegyzés lehet,
- azt szeretnénk, hogy hozzá lehessen adni egy megjegyzést vagy egy hasonlót egy bejegyzéshez anélkül, hogy frissítenie kellene magát a bejegyzést.
Milyen jól teljesít a modell?
Itt az ideje, hogy felmérjük az első verzió teljesítményét és méretezhetőségét. A korábban azonosított kérések mindegyikénél megmérjük a késését és azt, hogy hány kérelemegységet használ fel. Ez a mérés egy 100 000 felhasználót tartalmazó, felhasználónként 5-50 bejegyzést tartalmazó, legfeljebb 25 megjegyzést és 100 kedvelést tartalmazó áladatkészleten történik.
[C1] Felhasználó létrehozása/szerkesztése
Ez a kérés egyszerűen implementálható, mivel egyszerűen létrehozunk vagy frissítünk egy elemet a users tárolóban. A kérések a partíciókulcsnak köszönhetően szépen elterülnek az id összes partíció között.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
7 Ms |
5.71 RU |
✅ |
[1. negyedév] Felhasználó lekérése
A felhasználó beolvasása a megfelelő elem tárolóból való users beolvasásával történik.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
2 Ms |
1 RU |
✅ |
[C2] Bejegyzés létrehozása/szerkesztése
A [C1] fájlhoz hasonlóan csak a tárolóba posts kell írnunk.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
9 Ms |
8.76 RU |
✅ |
[2. negyedév] Bejegyzés lekérése
Először lekéred a megfelelő dokumentumot a posts tárolóból. De ez nem elég, mivel a specifikációnk szerint a bejegyzés szerzőjének felhasználónevét, a megjegyzések számát és a kedvelések számát is össze kell adnunk a bejegyzéshez. A felsorolt összesítésekhez további 3 SQL-lekérdezést kell kiadni.
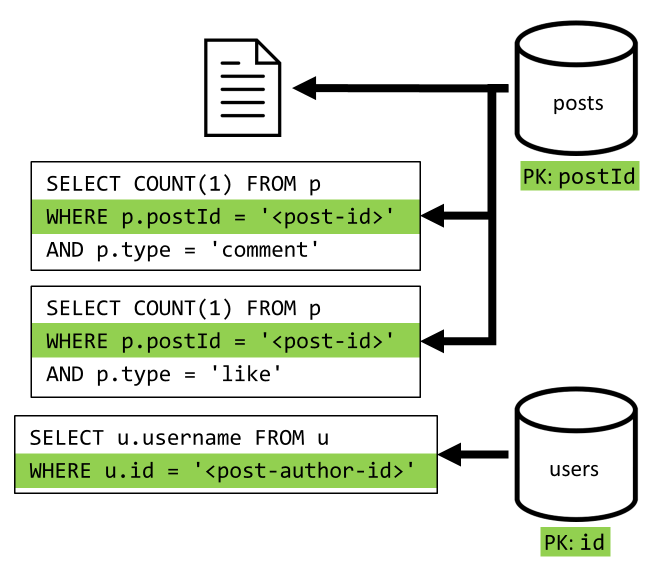
A további lekérdezések mindegyike a megfelelő tároló partíciókulcsára szűr, és pontosan ezt szeretnénk maximalizálni a teljesítmény és a méretezhetőség szempontjából. De végül négy műveletet kell végrehajtanunk, hogy egyetlen bejegyzést küldhessünk vissza, ezért ezt egy következő iterációban javítani fogjuk.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
9 Ms |
19.54 RU |
⚠ |
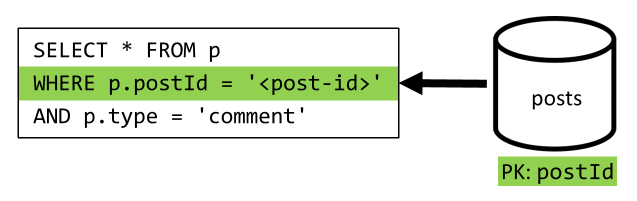
[3. negyedév] Felhasználó bejegyzésének listázása rövid formában
Először le kell kérnünk a kívánt bejegyzéseket egy SQL-lekérdezéssel, amely lekéri az adott felhasználónak megfelelő bejegyzéseket. De több lekérdezést is ki kell adnunk, hogy összesítsük a szerző felhasználónevét, valamint a megjegyzések és kedvelések számát.
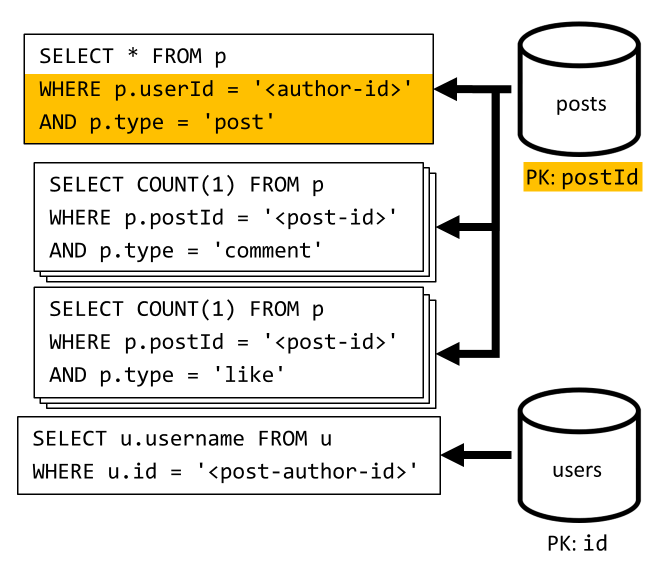
Ez a megvalósítás számos hátrányt jelent:
- a megjegyzések és kedvelések számát összesítő lekérdezéseket minden egyes, az első lekérdezés által visszaadott bejegyzéshez ki kell adni,
- a fő lekérdezés nem szűr a tároló partíciókulcsára
posts, ami egy kirakott és egy partícióvizsgálatot eredményez a tárolóban.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
130 Ms |
619.41 RU |
⚠ |
[C3] Megjegyzés létrehozása
A rendszer megjegyzést hoz létre a megfelelő elem megírásával a posts tárolóban.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
7 Ms |
8.57 RU |
✅ |
[4. negyedév] Bejegyzések listázása
Egy lekérdezéssel kezdjük, amely lekéri az adott bejegyzéshez tartozó összes megjegyzést, és ismét külön kell összesíteni a felhasználóneveket az egyes megjegyzésekhez.
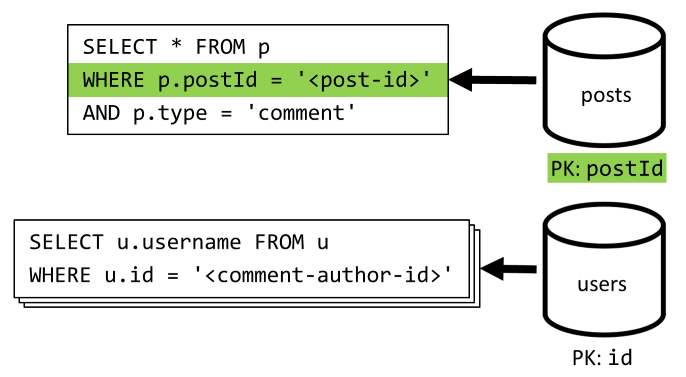
Bár a fő lekérdezés nem szűr a tároló partíciókulcsára, a felhasználónevek összesítése külön-külön bünteti az általános teljesítményt. Ezt később továbbfejlesztjük.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
23 Ms |
27.72 RU |
⚠ |
[C4] Bejegyzés kedvelve
A [C3] elemhez hasonlóan létrehozzuk a megfelelő elemet a posts tárolóban.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
6 Ms |
7.05 RU |
✅ |
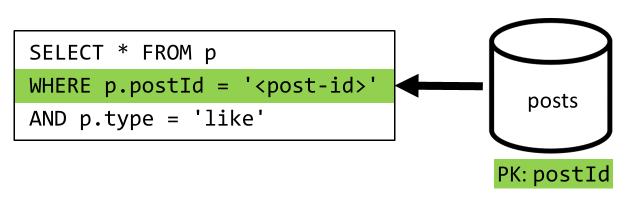
[5. negyedév] Bejegyzés kedveléseinek listázása
A [Q4] szolgáltatáshoz hasonlóan lekérdezzük a bejegyzés kedveléseit, majd összesítjük a felhasználóneveket.
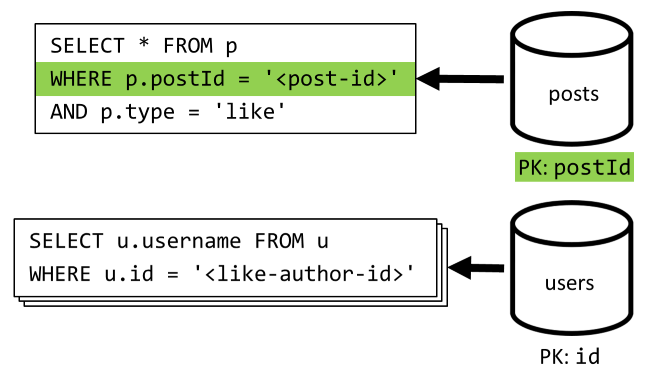
| Késés | RU-díj | Teljesítmény |
|---|---|---|
59 Ms |
58.92 RU |
⚠ |
[6. negyedév] A rövid formában (hírcsatorna) létrehozott x legutóbbi bejegyzés listázása
A legutóbbi bejegyzések lekéréséhez lekérdezzük a tárolót csökkenő posts létrehozási dátum szerint rendezve, majd összesítjük a felhasználóneveket és a megjegyzések és kedvelések számát az egyes bejegyzésekhez.
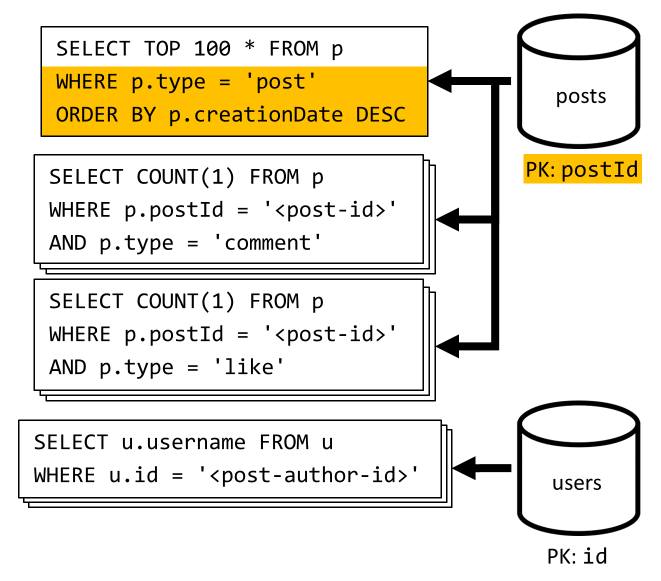
A kezdeti lekérdezés még egyszer nem szűr a tároló partíciókulcsára posts , ami költséges ki-ki- és bekapcsolását váltja ki. Ez még rosszabb, mivel egy nagyobb eredményhalmazt célozunk meg, és egy ORDER BY záradékkal rendezzük az eredményeket, ami drágábbá teszi a kérésegységeket.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
306 Ms |
2063.54 RU |
⚠ |
Tükrözés a V1 teljesítményéről
Az előző szakaszban tapasztalt teljesítményproblémákat megvizsgálva két fő problémaosztályt azonosíthatunk:
- egyes kérések esetén több lekérdezést kell kiadni ahhoz, hogy összegyűjtsük a visszaadni kívánt adatokat,
- Egyes lekérdezések nem szűrnek a megcélzott tárolók partíciókulcsára, ami egy olyan kirakást eredményez, amely akadályozza a méretezhetőséget.
Oldjuk meg ezeket a problémákat, kezdve az elsővel.
V2: Denormalizálás bevezetése az olvasási lekérdezések optimalizálásához
Bizonyos esetekben azért kell további kéréseket kiadnunk, mert a kezdeti kérés eredményei nem tartalmazzák az összes visszaadandó adatot. Az adatok denormalizálása megoldja ezt a problémát az adatkészletünkben, amikor nem relációs adattárral, például az Azure Cosmos DB-vel dolgozik.
Példánkban módosítjuk a bejegyzéselemeket, hogy hozzáadjuk a bejegyzés szerzőjének felhasználónevét, a megjegyzések számát és a kedvelések számát:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
A megjegyzéseket és az elemeket is módosítjuk, hogy hozzáadjuk annak a felhasználónak a felhasználónevét, aki létrehozta őket:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Megjegyzés denormalizálása és a darabszám kedvelése
Azt szeretnénk elérni, hogy minden alkalommal, amikor hozzáadunk egy megjegyzést vagy hasonlót, a megfelelő bejegyzésben is növeljük commentCount a vagy a likeCount megfelelő bejegyzést. A tároló particionálásakor postId posts az új elem (megjegyzés vagy hasonló) és a hozzá tartozó bejegyzés ugyanabban a logikai partícióban található. Ennek eredményeképpen egy tárolt eljárást használhatunk a művelet végrehajtásához.
Megjegyzés létrehozásakor ([C3]) ahelyett, hogy csak új elemet adnánk hozzá a posts tárolóhoz, a következő tárolt eljárást hívjuk meg a tárolón:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Ez a tárolt eljárás a bejegyzés azonosítóját és az új megjegyzés törzsét veszi paraméterként, majd:
- lekéri a bejegyzést
- növekményesen
commentCount - lecseréli a bejegyzést
- hozzáadja az új megjegyzést
Mivel a tárolt eljárások atomi tranzakciókként vannak végrehajtva, a megjegyzések értéke commentCount és tényleges száma mindig szinkronban marad.
Nyilvánvalóan hasonló tárolt eljárást hívunk, amikor új kedveléseket adunk hozzá a likeCountnövekményhez.
Felhasználónevek denormalizálása
A felhasználónevek eltérő megközelítést igényelnek, mivel a felhasználók nem csak különböző partíciókban, hanem egy másik tárolóban is ülnek. Ha az adatokat partíciók és tárolók között kell denormalizálnunk, használhatjuk a forrástároló változáscsatornáját.
A példánkban a tároló változáscsatornáját használjuk arra, hogy reagáljanak, amikor a users felhasználók frissítik a felhasználóneveket. Amikor ez történik, propagálja a módosítást egy másik tárolt eljárás meghívásával a posts tárolón:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Ez a tárolt eljárás a felhasználó azonosítóját és a felhasználó új felhasználónevét veszi paraméterként, majd:
- lekéri az összes olyan elemet, amely megfelel a
userId(például bejegyzéseknek, megjegyzéseknek vagy kedveléseknek) - minden egyes elemhez
- lecseréli a
userUsername - lecseréli az elemet
- lecseréli a
Fontos
Ez a művelet költséges, mert a tárolt eljárást a tároló minden partícióján posts végre kell hajtani. Feltételezzük, hogy a felhasználók többsége a regisztráció során kiválaszt egy megfelelő felhasználónevet, és soha nem módosítja azt, ezért ez a frissítés nagyon ritkán fog futni.
Mik a V2 teljesítménybeli nyereségei?
Beszéljünk a V2 teljesítménynövekedéséről.
[2. negyedév] Bejegyzés lekérése
Most, hogy megtörtént a denormalizálás, csak egyetlen elemet kell lekérnünk a kérés kezeléséhez.
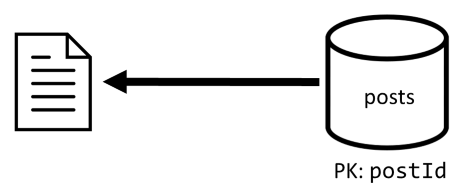
| Késés | RU-díj | Teljesítmény |
|---|---|---|
2 Ms |
1 RU |
✅ |
[4. negyedév] Bejegyzések listázása
Itt is megkímélhetjük a további kéréseket, amelyek beolvasták a felhasználóneveket, és egyetlen lekérdezéssel végződnek, amely szűri a partíciókulcsot.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
4 Ms |
7.72 RU |
✅ |
[5. negyedév] Bejegyzés kedveléseinek listázása
Pontosan ugyanaz a helyzet, amikor felsorolja a kedveléseket.
| Késés | RU-díj | Teljesítmény |
|---|---|---|
4 Ms |
8.92 RU |
✅ |
V3: Annak biztosítása, hogy minden kérés méretezhető legyen
Még mindig két kérés van, amelyeket még nem optimalizáltunk teljesen az általános teljesítménybeli fejlesztések során. Ezek a kérések a következők: [Q3] és [Q6]. Ezek olyan lekérdezéseket tartalmazó kérések, amelyek nem szűrnek a megcélzott tárolók partíciókulcsára.
[3. negyedév] Felhasználó bejegyzésének listázása rövid formában
Ez a kérés már kihasználja a V2-ben bevezetett fejlesztéseket, ami további lekérdezéseket takarít meg.

A fennmaradó lekérdezés azonban továbbra sem szűr a posts tároló partíciókulcsára.
A helyzetre való gondolkodás egyszerű:
- Ennek a kérésnek az alapján kell szűrnie,
userIdhogy egy adott felhasználó összes bejegyzését le szeretnénk kérni. - Nem működik jól, mert a
poststárolón fut, amely nem particionáltauserId. - A nyilvánvaló módon a teljesítménnyel kapcsolatos problémát úgy oldjuk meg, hogy végrehajtjuk ezt a kérést egy, a következővel particionált tárolón
userId. - Kiderült, hogy már van ilyen tárolónk: a
userstároló!
Ezért bevezetünk egy második szintű denormalizálást a teljes bejegyzések duplikálásával a users tárolóba. Ezzel hatékonyan megkapjuk a bejegyzéseink másolatát, csak egy másik dimenzió mentén particionálva, így sokkal hatékonyabban lekérhetők userId.
A users tároló most kétféle elemet tartalmaz:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Ebben a példában:
- Bevezettünk egy
typemezőt a felhasználói elemben, amely megkülönbözteti a felhasználókat a bejegyzésektől. - Hozzáadtunk egy
userIdmezőt is a felhasználói elemhez, amely redundáns aidmezővel, de kötelező, mivel auserstároló particionálásauserIdmár megtörtént (és nemida korábbiak szerint).
A denormalizálás eléréséhez ismét a változáscsatornát használjuk. Ezúttal a tároló változáscsatornájára posts reagálunk, hogy elküldjük az új vagy frissített bejegyzéseket a users tárolónak. Mivel a bejegyzések listázásához nem szükséges a teljes tartalom visszaadása, a folyamat során csonkíthatjuk őket.
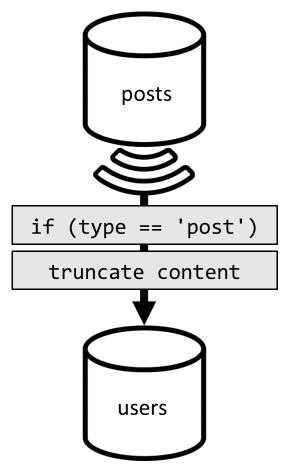
Most már átirányíthatjuk a lekérdezést a users tárolóhoz, és szűrhetjük a tároló partíciókulcsát.

| Késés | RU-díj | Teljesítmény |
|---|---|---|
4 Ms |
6.46 RU |
✅ |
[6. negyedév] A rövid formában (hírcsatorna) létrehozott x legutóbbi bejegyzés listázása
Itt is hasonló helyzettel kell foglalkoznunk: a V2-ben bevezetett denormalizálás által szükségtelenül hagyott lekérdezések megkímélése után a fennmaradó lekérdezés nem szűr a tároló partíciókulcsára:
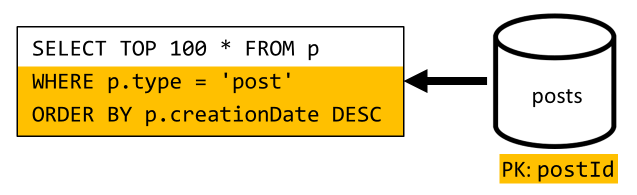
Ugyanezt a megközelítést követve a kérés teljesítményének és méretezhetőségének maximalizálásához csak egy partícióra van szükség. Csak egyetlen partíció elérésére van lehetőség, mert csak korlátozott számú elemet kell visszaadnunk. A blogolási platform kezdőlapjának feltöltéséhez csak be kell szereznünk a 100 legutóbbi bejegyzést, anélkül, hogy a teljes adatkészletet át kellene lapoznunk.
Az utolsó kérés optimalizálása érdekében bevezetünk egy harmadik tárolót a tervünkbe, amely teljes mértékben a kérés kiszolgálására szolgál. Denormalizáljuk a bejegyzéseinket az új feed tárolóban:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
A type mező particionálja ezt a tárolót, amely mindig post a mi elemeinkben található. Ezzel biztosítja, hogy a tároló összes eleme ugyanabban a partícióban üljön.
A denormalizálás eléréséhez csak a korábban bevezetett változáscsatorna-folyamathoz kell csatlakoznunk, hogy elküldjük a bejegyzéseket az új tárolóba. Az egyik fontos dolog, amit szem előtt kell tartanunk, hogy meg kell győződnünk arról, hogy csak a 100 legutóbbi bejegyzést tároljuk; ellenkező esetben a tároló tartalma meghaladhatja a partíció maximális méretét. Ez a korlátozás egy eseményindító meghívásával valósítható meg minden alkalommal, amikor egy dokumentumot hozzáad a tárolóhoz:
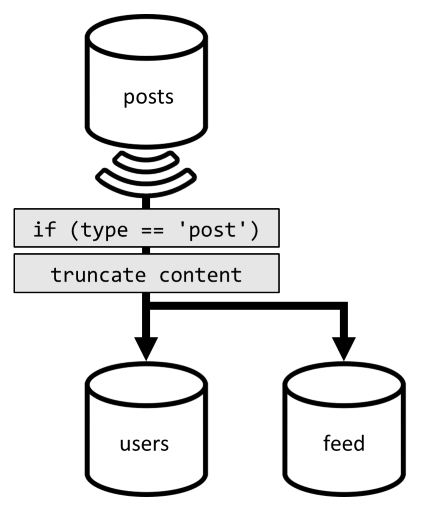
A gyűjteményt csonkolja a post-trigger törzse:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Az utolsó lépés a lekérdezés átirányítása az új feed tárolóra:
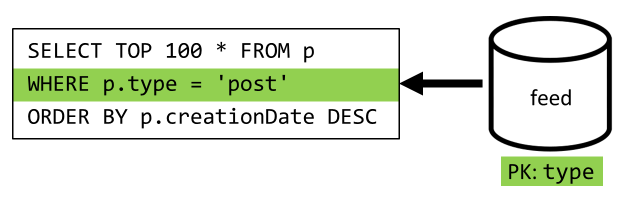
| Késés | RU-díj | Teljesítmény |
|---|---|---|
9 Ms |
16.97 RU |
✅ |
Összegzés
Tekintsük át a kialakítás különböző verzióiban bevezetett általános teljesítmény- és méretezhetőségi fejlesztéseket.
| 1. verzió | 2. verzió | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [1. negyedév] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [2. negyedév] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [3. negyedév] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [4. negyedév] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [5. negyedév] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [6. negyedév] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Optimalizáltunk egy írásvédett forgatókönyvet
Bizonyára észrevette, hogy az írási kérések (parancsok) rovására összpontosítottuk az olvasási kérések (lekérdezések) teljesítményének javítására irányuló erőfeszítéseinket. Az írási műveletek sok esetben a változáscsatornákon keresztül aktiválják a későbbi denormalizálást, ami számítási szempontból drágábbá és hosszabbá teszi őket.
Ezt azzal indokoljuk, hogy az olvasási teljesítményre összpontosítunk azzal a ténnyel, hogy a blogolási platform (mint a legtöbb közösségi alkalmazás) írásvédett. Az olvasási terhelés azt jelzi, hogy a kiszolgálni kívánt olvasási kérelmek mennyisége általában nagyságrendekkel nagyobb, mint az írási kérelmek száma. Ezért érdemes drágábban végrehajtani az írási kérelmeket, hogy az olvasási kérések olcsóbbak és jobban teljesíthessenek.
Ha megnézzük a legszélsőségesebb optimalizálást, [Q6] a 2000-nél több kérelemegységről mindössze 17 kérelemegységre ugrott; ezt úgy értük el, hogy a bejegyzéseket elemenként körülbelül 10 kérelemegység költségén denormalizáljuk. Mivel sokkal több hírcsatorna-kérést szolgálnánk ki, mint a bejegyzések létrehozása vagy frissítése, ennek a denormalizálásnak a költsége elhanyagolható, figyelembe véve a teljes megtakarítást.
A denormalizálás növekményesen alkalmazható
A cikkben ismertetett méretezhetőségi fejlesztések magukban foglalják az adatok denormalizálását és duplikálását az adatkészleten belül. Meg kell jegyezni, hogy ezeket az optimalizálásokat nem kell az 1. napon üzembe helyezni. A partíciókulcsokra szűrt lekérdezések méretezhetőbbek, de a partíciók közötti lekérdezések elfogadhatók lehetnek, ha ritkán vagy korlátozott adathalmazon keresztül hívják őket. Ha csak egy prototípust készít, vagy egy kis, ellenőrzött felhasználói bázissal rendelkező terméket indít el, akkor ezeket a fejlesztéseket valószínűleg később is megkímélheti. Fontos tehát a modell teljesítményének monitorozása , hogy eldönthesse, mikor és mikor kell behoznia őket.
Az a változáscsatorna, amelyet a frissítések más tárolókba való terjesztésére használunk, állandó módon tárolja ezeket a frissítéseket. Ez az adatmegőrzés lehetővé teszi az összes frissítés kérését a tároló és a bootstrap denormalizált nézeteinek létrehozása óta egyszeri felzárkózási műveletként, még akkor is, ha a rendszer már sok adattal rendelkezik.
Következő lépések
A gyakorlati adatmodellezés és particionálás bemutatása után érdemes lehet áttekinteni az alábbi cikkeket az általunk tárgyalt fogalmak áttekintéséhez: