Adatmodellezés az Azure Cosmos DB-ben
A KÖVETKEZŐKRE VONATKOZIK: ![]() NoSQL
NoSQL
Bár a sémamentes adatbázisok, például az Azure Cosmos DB, rendkívül egyszerűvé teszik a strukturálatlan és félig strukturált adatok tárolását és lekérdezését, érdemes némi időt szánni az adatmodellre, hogy a lehető legtöbbet hozhassa ki a szolgáltatásból a teljesítmény és a méretezhetőség, valamint a legalacsonyabb költség szempontjából.
Hogyan lesznek tárolva az adatok? Hogyan fogja lekérni és lekérdezni az alkalmazást? Az alkalmazás írásvédett vagy írási nehéz?
A cikk elolvasása után a következő kérdésekre válaszolhat:
- Mi az az adatmodellezés, és miért fontos nekem?
- Miben különbözik az Adatok modellezése az Azure Cosmos DB-ben egy relációs adatbázistól?
- Hogyan expressz adatkapcsolatokat egy nem relációs adatbázisban?
- Mikor ágyazhatok be adatokat, és mikor csatolhatok adatokat?
Számok a JSON-ban
Az Azure Cosmos DB JSON-ban menti a dokumentumokat. Ez azt jelenti, hogy alaposan meg kell határozni, hogy szükséges-e számokat sztringekké alakítani, mielőtt json-ban tároljuk őket. Minden számot ideális esetben konvertálni kell egy Stringértékké, ha fennáll a valószínűsége annak, hogy az IEEE 754 bináris64 szerint kívül esnek a dupla pontosságú számok határain. A JSON-specifikáció felhívja azokat az okokat, amelyek miatt az ezen a határon kívül eső számok használata általában rossz gyakorlat a JSON-ban a valószínű együttműködési problémák miatt. Ezek az aggodalmak különösen fontosak a partíciókulcs-oszlop esetében, mivel nem módosítható, és az adatmigrálást később módosítani kell.
Adatok beágyazása
Amikor elkezdi az adatok modellezését az Azure Cosmos DB-ben, próbálja meg az entitásokat JSON-dokumentumként ábrázolt önálló elemekként kezelni.
Összehasonlításképpen először nézzük meg, hogyan modellezhetjük az adatokat egy relációs adatbázisban. Az alábbi példa bemutatja, hogyan tárolhat egy személyt egy relációs adatbázisban.
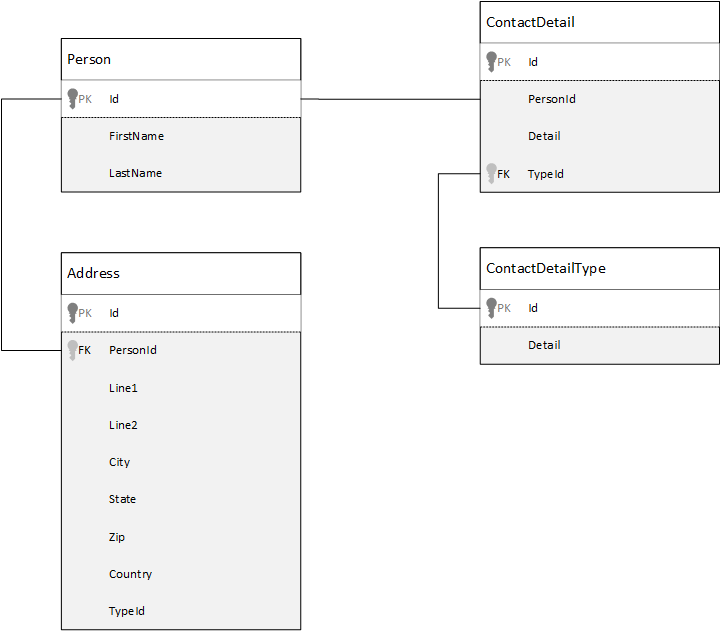
A relációs adatbázisok használatakor a stratégia az összes adat normalizálása. Az adatok normalizálásához általában egy entitást, például egy személyt kell átvenni, és különálló összetevőkre bontani. A fenti példában egy személy több kapcsolattartásiadat-rekordot és több címrekordot is tartalmazhat. A kapcsolattartási adatok tovább bonthatók a gyakori mezők, például egy típus további kinyerésével. Ugyanez vonatkozik a címre is, minden rekord lehet Otthoni vagy Vállalati típusú.
Az adatok normalizálásakor az a guiding premise, hogy ne tároljon redundáns adatokat az egyes rekordokon, és ne hivatkozzon adatokra. Ebben a példában az összes kapcsolattartási adattal és címmel rendelkező személy olvasásához a JOINS használatával hatékonyan vissza kell írnia (vagy denormalizálnia) az adatait futásidőben.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Egyetlen személy kapcsolattartási adatainak és címeinek frissítéséhez írási műveletekre van szükség számos különböző táblában.
Most nézzük meg, hogyan modellezhetjük ugyanazokat az adatokat, mint egy önálló entitás az Azure Cosmos DB-ben.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
A fenti módszerrel denormalizáltuk a személyrekordot, mivel egyetlen JSON-dokumentumbaágyaztuk be a személyhez kapcsolódó összes információt, például a kapcsolattartási adatait és a címét. Emellett, mivel nem egy rögzített sémára korlátozódunk, rugalmasan tudunk olyan műveleteket végezni, mint a különböző alakzatok kapcsolattartási adatainak teljes egészében.
A teljes személyrekord adatbázisból való lekérése mostantól egyetlen olvasási művelet egyetlen tárolón és egyetlen elemen. Egy személyrekord kapcsolattartási adatainak és címeinek frissítése egyetlen írási művelet egyetlen elemen.
Az adatok denormalizálásával előfordulhat, hogy az alkalmazásnak kevesebb lekérdezést és frissítést kell kiadnia a gyakori műveletek elvégzéséhez.
Mikor kell beágyazni?
Általában beágyazott adatmodelleket akkor érdemes használni, ha:
- Az entitások között tartalmazott kapcsolatok vannak.
- Az entitások között egy-a-néhányhoz kapcsolat van.
- Vannak olyan beágyazott adatok, amelyek ritkán változnak.
- Vannak olyan beágyazott adatok, amelyek nem növekednek kötöttség nélkül.
- Vannak olyan beágyazott adatok, amelyeket gyakran kérdeznek le együtt.
Megjegyzés
A denormalizált adatmodellek általában jobb olvasási teljesítményt biztosítanak.
Mikor nem kell beágyazni?
Bár az Azure Cosmos DB-ben a hüvelykujjszabály az, hogy mindent denormalizál, és az összes adatot egyetlen elembe ágyazza be, ez bizonyos helyzetekhez vezethet, amelyeket el kell kerülni.
Használja ezt a JSON-kódrészletet.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Így nézne ki egy beágyazott megjegyzéseket tartalmazó bejegyzésentitás, ha egy tipikus blogot vagy CMS-rendszert modelleznénk. Ezzel a példával az a probléma, hogy a megjegyzések tömbje kötetlen, ami azt jelenti, hogy egyetlen bejegyzéshez nincs (gyakorlati) korlát a megjegyzések számára. Ez problémát okozhat, mivel az elem mérete végtelenül nagy lehet, ezért érdemes elkerülni a tervezést.
Az elem méretének növekedésével az adatok átvitele a vezetéken keresztül, valamint az elem olvasása és frissítése nagy léptékben hatással lesz.
Ebben az esetben jobb lenne az alábbi adatmodellt figyelembe venni.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Ez a modell minden megjegyzéshez rendelkezik egy dokumentummal, amely a bejegyzésazonosítót tartalmazó tulajdonsággal rendelkezik. Ez lehetővé teszi, hogy a bejegyzések tetszőleges számú megjegyzést tartalmazzanak, és hatékonyan növekedhessenek. Azok a felhasználók, amelyek a legutóbbi megjegyzéseknél többet szeretnének látni, lekérdezik ezt a tárolót, és átadják a postId azonosítót, amelynek a megjegyzéstároló partíciókulcsának kell lennie.
Egy másik eset, amikor az adatok beágyazása nem jó ötlet, ha a beágyazott adatokat gyakran használják az elemek között, és gyakran változnak.
Használja ezt a JSON-kódrészletet.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Ez egy személy részvényportfólióját jelentheti. Úgy döntöttünk, hogy beágyazzuk a részvényadatokat az egyes portfóliódokumentumokba. Egy olyan környezetben, ahol a kapcsolódó adatok gyakran változnak, például egy tőzsdei alkalmazás, a gyakran változó adatok beágyazása azt jelenti, hogy folyamatosan frissíti az egyes portfóliódokumentumokat minden alkalommal, amikor egy részvényt kereskednek.
Részvény zbzb lehet kereskedni több száz alkalommal egy nap, és több ezer felhasználó is zbzb a portfólió. A fentihez hasonló adatmodellel naponta több ezer portfoliódokumentumot kellene frissíteni, ami egy olyan rendszerhez vezet, amely nem fog megfelelően méretezni.
Referenciaadatok
Az adatok beágyazása sok esetben jól működik, de vannak olyan helyzetek, amikor az adatok denormalizálása több problémát okoz, mint amennyit érdemes. Mit csinálunk most?
Nem csak a relációs adatbázisok hozhatnak létre kapcsolatokat az entitások között. A dokumentum-adatbázisokban lehetnek olyan információk egy dokumentumban, amelyek más dokumentumok adataihoz kapcsolódnak. Nem javasoljuk olyan rendszerek kiépítését, amelyek jobban megfelelnének az Azure Cosmos DB relációs adatbázisainak vagy bármely más dokumentum-adatbázisnak, de az egyszerű kapcsolatok rendben vannak, és hasznosak lehetnek.
Az alábbi JSON-ban a korábbi részvényportfólió példáját választottuk, de ezúttal a portfólió részvényelemére hivatkozunk beágyazás helyett. Így amikor a tőzsdei tétel gyakran változik a nap folyamán, az egyetlen frissítendő dokumentum az egyetlen részvénydokumentum.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Ennek a megközelítésnek a közvetlen hátránya azonban az, ha az alkalmazásnak meg kell jelenítenie az egyes részvényekre vonatkozó információkat, amelyek egy személy portfóliójának megjelenítésekor vannak tárolva; ebben az esetben több adatátjárást kell végeznie az adatbázisba az egyes részvénydokumentumok adatainak betöltéséhez. Itt döntést hoztunk az írási műveletek hatékonyságának javítása érdekében, amely gyakran fordul elő a nap folyamán, de az olvasási műveletek biztonsága sérül, amelyek esetleg kevésbé befolyásolják az adott rendszer teljesítményét.
Megjegyzés
A normalizált adatmodellek több adatváltást igényelhetnek a kiszolgálón.
Mi a helyzet a külföldi kulcsokkal?
Mivel jelenleg nincs megkötés, idegen kulcs vagy egyéb, a dokumentumok közötti kapcsolatok gyakorlatilag "gyenge kapcsolatok", és nem ellenőrzi magát az adatbázist. Ha meg szeretné győződni arról, hogy a dokumentum által hivatkozott adatok valóban léteznek, ezt az alkalmazásban vagy kiszolgálóoldali eseményindítók vagy tárolt eljárások használatával kell elvégeznie az Azure Cosmos DB-ben.
Mikor kell hivatkozni?
Általában a normalizált adatmodelleket akkor érdemes használni, ha:
- Egy-a-többhöz kapcsolatok ábrázolása.
- Több-a-többhöz kapcsolatok ábrázolása.
- A kapcsolódó adatok gyakran változnak.
- A hivatkozott adatok kötetlenek lehetnek.
Megjegyzés
A normalizálás általában jobb írási teljesítményt biztosít.
Hová tegyem a kapcsolatot?
A kapcsolat növekedése segít meghatározni, hogy melyik dokumentumban tárolja a hivatkozást.
Ha megnézzük az alábbi JSON-t, amely közzétevőket és könyveket modell.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Ha a kiadónkénti könyvek száma korlátozott növekedéssel kicsi, akkor hasznos lehet, ha a könyvhivatkozást a közzétevő dokumentumában tárolja. Ha azonban a könyvkiadónkénti könyvek száma kötetlen, akkor ez az adatmodell több, növekvő tömböt eredményezne, mint a fenti példakiadói dokumentumban.
Ha egy kicsit áttér a dolgokra, az olyan modellt eredményezne, amely továbbra is ugyanazokat az adatokat képviseli, de most elkerüli ezeket a nagy, többtáblás gyűjteményeket.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
A fenti példában elvetettük a kötetlen gyűjteményt a közzétevő dokumentumra. Ehelyett csak egy hivatkozás van a kiadóra minden könyvdokumentumban.
Hogyan több-a-többhöz típusú kapcsolatokat?
Egy relációs adatbázisban a több-a-többhöz kapcsolatok gyakran illesztőtáblákkal vannak modellezve, amelyek csak összekapcsolják más táblák rekordjait.
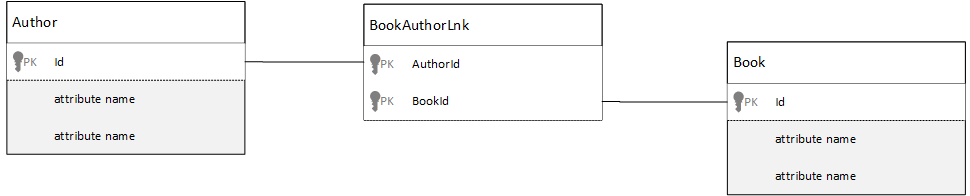
Előfordulhat, hogy a rendszer arra csábítja, hogy ugyanazt a dolgot dokumentumokkal replikálja, és az alábbihoz hasonló adatmodellt hozzon létre.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Ez működne. Ha azonban egy szerzőt a könyveivel tölt be, vagy egy könyvet a szerzővel együtt tölt be, az adatbázison mindig legalább két további lekérdezésre lenne szükség. Egy lekérdezés az összekapcsolt dokumentumra, majd egy másik lekérdezés az összekapcsolt dokumentum lekérésére.
Ha ez az illesztés csak két adatrészt ragaszt össze, akkor miért ne dobja el teljesen? Gondolja át a következő példát.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Most, ha lenne egy szerző, azonnal tudom, hogy mely könyveket írtak, és fordítva, ha lenne egy könyv dokumentum betöltött tudnám az azonosítók a szerző(k). Ezzel menti ezt a köztes lekérdezést az illesztőtáblára, csökkentve az alkalmazás által végrehajtott kiszolgálói adatváltások számát.
Hibrid adatmodellek
Most áttekintettük az adatok beágyazását (vagy denormalizálását) és hivatkozását (vagy normalizálását). Minden megközelítésnek vannak hátrányai és kompromisszumai.
Nem kell mindig vagy- vagy, ne félj egy kicsit összekeverni a dolgokat.
Az alkalmazás konkrét használati mintái és számítási feladatai alapján lehetnek olyan esetek, amikor a beágyazott és hivatkozott adatok összekeverése logikus, és egyszerűbb alkalmazáslogikához vezethet, kevesebb kiszolgálói körúttal, miközben továbbra is jó teljesítményt nyújt.
Vegye figyelembe a következő JSON-t.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Itt (többnyire) a beágyazott modellt követtük, ahol más entitásokból származó adatok vannak beágyazva a legfelső szintű dokumentumba, de más adatokra is hivatkozunk.
Ha megtekinti a könyv dokumentumot, láthatunk néhány érdekes mezőket, amikor megnézzük a tömb a szerzők. Van egy id mező, amelyet arra használunk, hogy egy szerzői dokumentumra hivatkozzon, egy normalizált modellben a szokásos gyakorlatra, de akkor a és thumbnailUrla is vanname. Elakadhattunk volna az alkalmazással id , és otthagyhattuk volna az alkalmazást, hogy a "hivatkozás" használatával további információt kérhessünk a megfelelő szerződokumentumból, de mivel az alkalmazás megjeleníti a szerző nevét és egy miniatűrképet minden megjelenített könyvvel, könyvenként menthetünk egy listában a kiszolgálóra való utazást úgy, hogy denormalizálunk néhány adatot a szerzőtől.
Persze, ha a szerző neve megváltozott, vagy frissíteni akarták a fényképüket, akkor minden könyvet frissíteni kell, amit valaha is közzétettek, de az alkalmazásunk esetében, azon a feltételezésen alapulva, hogy a szerzők gyakran nem változtatják meg a nevüket, ez elfogadható tervezési döntés.
A példában előre kiszámított összesítési értékek vannak, hogy költséges feldolgozást takarítson meg egy olvasási műveleten. A példában a szerzői dokumentumba ágyazott adatok egy része futásidőben kiszámított adatok. Minden alkalommal, amikor új könyvet tesznek közzé, létrejön egy könyvdokumentum, és a countOfBooks mező számított értékre van állítva az adott szerző számára létező könyvdokumentumok száma alapján. Ez az optimalizálás jó lenne az olvasási nehéz rendszerekben, ahol megengedhetjük magunknak, hogy számításokat végezhessünk az írásokon az olvasások optimalizálása érdekében.
Az előre kiszámított mezőkkel rendelkező modellek használata azért lehetséges, mert az Azure Cosmos DB támogatja a többdokumentumos tranzakciókat. Számos NoSQL-tároló nem tud tranzakciókat végrehajtani a dokumentumok között, ezért a korlátozás miatt olyan tervezési döntéseket javasol, mint például a "minden beágyazása". Az Azure Cosmos DB-vel kiszolgálóoldali eseményindítókat vagy tárolt eljárásokat használhat, amelyek könyveket szúrnak be és frissítik a szerzőket egy ACID-tranzakción belül. Most már nem kell mindent beágyaznia egy dokumentumba, csak azért, hogy az adatok konzisztensek legyenek.
A különböző dokumentumtípusok megkülönböztetése
Bizonyos esetekben érdemes lehet különböző dokumentumtípusokat keverni ugyanabban a gyűjteményben; Ez általában akkor fordul elő, ha több kapcsolódó dokumentumot szeretne ugyanabba a partícióba helyezni. Tegyük fel például, hogy a könyveket és a könyvértékeléseket is ugyanabban a gyűjteményben helyezi el, és particionálja a következővel bookId: . Ilyen esetben általában olyan mezővel szeretné hozzáadni a dokumentumokat, amely a típusukat azonosítja, hogy megkülönböztethesse őket.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Adatmodellezés a Azure Synapse Linkhez és az Azure Cosmos DB elemzési tárhoz
Azure Synapse Link az Azure Cosmos DB-hez egy natív felhőalapú hibrid tranzakciós és elemzési feldolgozási (HTAP) képesség, amellyel közel valós idejű elemzéseket futtathat az Azure Cosmos DB operatív adatain keresztül. Az Azure Synapse Link szoros, zökkenőmentes integrációt hoz létre az Azure Cosmos DB és az Azure Synapse Analytics között.
Ez az integráció az Azure Cosmos DB elemzési tárán keresztül történik, amely a tranzakciós adatok oszlopos ábrázolása, amely lehetővé teszi a nagy léptékű elemzéseket anélkül, hogy ez hatással lenne a tranzakciós számítási feladatokra. Ez az elemzési tár gyors, költséghatékony lekérdezésekhez használható nagy műveleti adatkészleteken anélkül, hogy adatokat másolna, és hatással lenne a tranzakciós számítási feladatok teljesítményére. Ha olyan tárolót hoz létre, amelyen engedélyezve van az elemzési tár, vagy ha egy meglévő tárolóban engedélyezi az elemzési tárat, a rendszer szinte valós időben szinkronizálja az összes tranzakciós beszúrást, frissítést és törlést az elemzési tárral, nincs szükség változáscsatorna- vagy ETL-feladatokra.
A Azure Synapse Linkkel mostantól közvetlenül csatlakozhat az Azure Cosmos DB-tárolókhoz a Azure Synapse Analyticsből, és hozzáférhet az elemzési tárhoz kérelemegységek (kérelemegységek) nélkül. Azure Synapse Analytics jelenleg támogatja a Azure Synapse Linket a Synapse Apache Sparkkal és a kiszolgáló nélküli SQL-készletekkel. Ha globálisan elosztott Azure Cosmos DB-fiókkal rendelkezik, miután engedélyezte az elemzési tárat egy tárolóhoz, az a fiók összes régiójában elérhető lesz.
Elemzési tár automatikus sémakövetkeztetése
Bár az Azure Cosmos DB tranzakciós tárolója sororientált, félig strukturált adatnak minősül, az elemzési tár oszlopos és strukturált formátumú. Ez az átalakítás automatikusan történik az ügyfelek számára az elemzési tár sémakövetkeztetési szabályainak használatával. Az átalakítási folyamatnak vannak korlátai: a beágyazott szintek maximális száma, a tulajdonságok maximális száma, a nem támogatott adattípusok és egyebek.
Megjegyzés
Az elemzési tár kontextusában a következő struktúrákat tekintjük tulajdonságnak:
- JSON "elements" vagy "string-value pairs separated by a
:". - JSON-objektumok, és által
{}elválasztva. - JSON-tömbök, és által
[]elválasztva.
Az alábbi technikákkal minimalizálhatja a sémakövetkeztetés-konverziók hatását, és maximalizálhatja az elemzési képességeket.
Normalizálás
A normalizálás értelmetlenné válik, mivel a Azure Synapse Linkkel T-SQL vagy Spark SQL használatával csatlakozhat a tárolókhoz. A normalizálás várható előnyei a következők:
- Kisebb adatlábnyom a tranzakciós és az elemzési tárban.
- Kisebb tranzakciók.
- Dokumentumonként kevesebb tulajdonság.
- Kevesebb beágyazott szinttel rendelkező adatstruktúrák.
Vegye figyelembe, hogy ez az utolsó két tényező, kevesebb tulajdonság és kevesebb szint segíti az elemzési lekérdezések teljesítményét, de csökkenti annak esélyét is, hogy az adatok egy része ne jelenjen meg az elemzési tárban. Az automatikus sémakövetkeztetési szabályokról szóló cikkben leírtak szerint az elemzési tárban szereplő szintek és tulajdonságok száma korlátozott.
A normalizálás másik fontos tényezője, hogy Azure Synapse kiszolgáló nélküli SQL-készletek legfeljebb 1000 oszlopot támogató eredményhalmazokat támogatnak, és a beágyazott oszlopok felfedése is beleszámít a korlátba. Más szóval az elemzési tár és a Kiszolgáló nélküli Synapse SQL-készletek is legfeljebb 1000 tulajdonsággal rendelkeznek.
De mi a teendő, mivel a denormalizálás az Azure Cosmos DB fontos adatmodellezési technikája? A válasz az, hogy meg kell találnia a megfelelő egyensúlyt a tranzakciós és elemzési számítási feladatokhoz.
Partíciókulcs
Az Azure Cosmos DB partíciókulcsa (PK) nem használatos az elemzési tárban. Most pedig az elemzési tár egyéni particionálásával bármilyen PK-val másolhatja az elemzési tárat. Az elkülönítés miatt kiválaszthatja a tranzakciós adatokhoz tartozó PK-t, amely az adatbetöltésre és a pontolvasásra összpontosít, míg a partíciók közötti lekérdezések Azure Synapse Linkkel végezhetők el. Lássunk egy példát:
Egy hipotetikus globális IoT-forgatókönyvben jó PK, device id mivel minden eszköz hasonló adatkötettel rendelkezik, és ezzel nem lesz gyakori elérésű partícióval kapcsolatos probléma. Ha azonban egynél több eszköz adatait szeretné elemezni, például "a tegnapi összes adatot" vagy a "városonkénti összegeket", problémákat tapasztalhat, mivel ezek partíciók közötti lekérdezések. Ezek a lekérdezések ronthatják a tranzakciós teljesítményt, mivel az átviteli sebesség egy részét a kérelemegységekben használják a futtatáshoz. A Azure Synapse Linkkel azonban kérésegységek nélkül futtathatja ezeket az elemzési lekérdezéseket. Az elemzési tár oszlopos formátuma elemzési lekérdezésekhez van optimalizálva, és Azure Synapse Link ezt a jellemzőt alkalmazza, hogy nagy teljesítményt biztosíthasson Azure Synapse Analytics-futtatókörnyezetekben.
Adattípusok és tulajdonságok neve
Az automatikus sémakövetkeztetési szabályokról szóló cikk felsorolja a támogatott adattípusokat. Bár a nem támogatott adattípus blokkolja a reprezentációt az elemzési tárban, a támogatott adattípusokat a Azure Synapse futtatókörnyezetek eltérően dolgozhatják fel. Egy példa: Ha az ISO 8601 UTC szabványt követő DateTime sztringeket használ, a Spark-készletek Azure Synapse ezeket az oszlopokat sztringként, a kiszolgáló nélküli SQL-készleteket pedig Azure Synapse a varchar(8000) oszlopként jelenítik meg.
Egy másik kihívás, hogy nem minden karaktert fogad el Azure Synapse Spark. A fehér szóközök elfogadásakor az olyan karakterek, mint a kettőspont, a súlyos ékezet és a vessző nem. Tegyük fel, hogy a dokumentum rendelkezik egy "Utónév, Vezetéknév" nevű tulajdonságtal. Ez a tulajdonság megjelenik az elemzési tárban, és a Kiszolgáló nélküli Synapse SQL-készlet probléma nélkül be tudja olvasni. Mivel azonban az elemzési tárban található, Azure Synapse Spark nem tud adatokat beolvasni az elemzési tárból, beleértve az összes többi tulajdonságot sem. A nap végén nem használhatja a Azure Synapse Sparkot, ha egy tulajdonsága nem támogatott karaktereket használ a nevükben.
Adatelsimítás
Az Azure Cosmos DB-adatok gyökérszintjén lévő összes tulajdonság oszlopként jelenik meg az elemzési tárban, és a dokumentum adatmodelljének mélyebb szintjein lévő összes többi tulajdonság JSON-ként jelenik meg, szintén beágyazott struktúrákban. A beágyazott struktúrák további feldolgozást igényelnek Azure Synapse futtatókörnyezetektől az adatok strukturált formátumban való simításához, ami nagy kihívást jelenthet a big data-forgatókönyvekben.
Az alábbi dokumentum csak két oszlopot tartalmaz az elemzési tárban, id és contactDetailsa következőt: . Minden más adat( email és phone) külön feldolgozást igényel az SQL-függvényeken keresztül, hogy külön-külön lehessen olvasni.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Az alábbi dokumentum három oszlopot tartalmaz az elemzési tárban: , idemailés phone. Minden adat közvetlenül elérhető oszlopként.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Adatrétegezés
Azure Synapse Link segítségével az alábbi szempontokból csökkentheti a költségeket:
- Kevesebb lekérdezés fut a tranzakciós adatbázisban.
- Az adatbetöltésre és pontolvasásra optimalizált PK csökkenti az adatlábnyomot, a gyakori elérésű partíciós forgatókönyveket és a partíciók felosztását.
- Az adatok rétegezése, mivel az elemzési élettartam (attl) független a tranzakciós élettartamtól (tttl). A tranzakciós adatokat néhány napig, hetekig, hónapokig tárolhatja a tranzakciós tárban, és akár évekig, akár örökre megőrizheti az adatokat az elemzési tárban. Az elemzési tár oszlopos formátuma természetes adattömörítést eredményez, 50%-tól 90%-ig. Gb-onkénti költsége pedig a tranzakciós tár tényleges árának körülbelül 10%-a. Az aktuális biztonsági mentési korlátozásokkal kapcsolatos további információkért tekintse meg az elemzési tár áttekintését.
- A környezetben nem futnak ETL-feladatok, ami azt jelenti, hogy nem kell hozzájuk kérelemegységeket kiépítenie.
Szabályozott redundancia
Ez nagyszerű alternatíva olyan helyzetekre, amikor egy adatmodell már létezik, és nem módosítható. A meglévő adatmodell pedig nem fér el jól az elemzési tárban az olyan automatikus sémakövetkező szabályok miatt, mint a beágyazott szintek korlátja vagy a tulajdonságok maximális száma. Ebben az esetben az Azure Cosmos DB változáscsatornával replikálhatja az adatokat egy másik tárolóba, és alkalmazhatja a szükséges átalakításokat egy Azure Synapse Linkbarát adatmodellhez. Lássunk egy példát:
Eset
A tároló CustomersOrdersAndItems az online megrendelések tárolására szolgál, beleértve az ügyfél és a tételek adatait: számlázási cím, szállítási cím, szállítási mód, szállítási állapot, cikkek ára stb. Csak az első 1000 tulajdonság jelenik meg, és a kulcsadatok nem szerepelnek az elemzési tárban, ami blokkolja Azure Synapse Hivatkozás használatát. A tárolóban a rekordok pB-jai vannak, ezért nem lehet módosítani az alkalmazást, és újramodellíteni az adatokat.
A probléma másik perspektívája a big data-kötet. Az elemzési részleg folyamatosan több milliárd sort használ, ami megakadályozza, hogy tttl-t használjanak a régi adatok törléséhez. A tranzakciós adatbázisban az elemzési igények miatt a teljes adatelőzmény fenntartása arra kényszeríti őket, hogy folyamatosan növeljék a kérelemegységek kiépítését, ami hatással van a költségekre. A tranzakciós és elemzési számítási feladatok ugyanazon erőforrásokért versenyeznek egy időben.
Mi a teendő?
Megoldás változáscsatornával
- A mérnöki csapat úgy döntött, hogy a Változáscsatorna használatával tölt fel három új tárolót:
Customers,Orders, ésItems. A Változáscsatorna használatával normalizálják és simítják az adatokat. A rendszer eltávolítja a szükségtelen adatokat az adatmodellből, és minden tároló közel 100 tulajdonsággal rendelkezik, így elkerülhető az adatvesztés az automatikus sémakövetkeztetési korlátok miatt. - Ezeknek az új tárolóknak engedélyezve van az elemzési tár, és az elemzési részleg most a Synapse Analytics használatával olvassa be az adatokat, csökkentve a kérelemegységek használatát, mivel az elemzési lekérdezések a Synapse Apache Sparkban és a kiszolgáló nélküli SQL-készletekben történnek.
- A tároló
CustomersOrdersAndItemstttl-et állított be, hogy csak hat hónapig őrizze meg az adatokat, ami lehetővé teszi a kérelemegységek használatának további csökkentését, mivel az Azure Cosmos DB-ben gb-onként legalább 10 kérelemegység van. Kevesebb adat, kevesebb kérelemegység.
Legfontosabb ismeretek
A cikk legnagyobb tanulsága, hogy tisztában kell lenni azzal, hogy az adatmodellezés egy sémamentes világban ugyanolyan fontos, mint valaha.
Ahogy egyetlen módon sem ábrázolhat egy adatrészt a képernyőn, az adatok modellezésére nincs egyetlen mód. Meg kell ismernie az alkalmazást, és azt, hogy az hogyan fogja előállítani, felhasználni és feldolgozni az adatokat. Ezután az itt bemutatott irányelvek alkalmazásával beállíthat egy olyan modellt, amely megfelel az alkalmazás azonnali igényeinek. Amikor az alkalmazásoknak módosítaniuk kell, a séma nélküli adatbázisok rugalmasságával egyszerűen átfoghatja és fejlesztheti az adatmodellt.
Következő lépések
Az Azure Cosmos DB-vel kapcsolatos további információkért tekintse meg a szolgáltatás dokumentációs oldalát.
Ha szeretné megtudni, hogyan skálázhatja az adatokat több partícióra, tekintse meg az Adatok particionálása az Azure Cosmos DB-ben című témakört.
Ha szeretné megtudni, hogyan modellezheti és particionálhatja az adatokat az Azure Cosmos DB-ben valós példán keresztül, tekintse meg az Adatmodellezés és particionálás – egy Real-World példa című témakört.
Tekintse meg az adatok Azure Cosmos DB-ben történő modellezését és particionálását ismertető képzési modult.
Konfigurálja és használja Azure Synapse Linket az Azure Cosmos DB-hez.
Kapacitástervezést szeretne végezni az Azure Cosmos DB-be való migráláshoz? A kapacitástervezéshez használhatja a meglévő adatbázisfürt adatait.
- Ha csak annyit tud, hogy hány virtuális mag és kiszolgáló található a meglévő adatbázisfürtben, olvassa el a kérelemegységek becslését virtuális magok vagy vCPU-k használatával
- Ha ismeri az aktuális adatbázis számítási feladatainak tipikus kérési arányait, olvassa el a kérelemegységek becslését az Azure Cosmos DB kapacitástervezővel