Teljesítménytippek az Azure Cosmos DB Async Java SDK v2-hez
A KÖVETKEZŐRE VONATKOZIK: ![]() NoSQL
NoSQL
Fontos
Nem ez a legújabb Java SDK az Azure Cosmos DB-hez! Frissítse a projektet az Azure Cosmos DB Java SDK v4-re , majd olvassa el az Azure Cosmos DB Java SDK v4 teljesítménytippek útmutatóját. A frissítéshez kövesse a Migrate to Azure Cosmos DB Java SDK v4 útmutatójában és a Reactor vs RxJava útmutatóban található utasításokat.
A cikkben szereplő teljesítménytippek csak az Azure Cosmos DB Async Java SDK v2-hez tartoznak. További információkért tekintse meg az Azure Cosmos DB Async Java SDK v2 kiadási megjegyzéseit, a Maven-adattárat és az Azure Cosmos DB Async Java SDK v2 hibaelhárítási útmutatóját.
Fontos
2024. augusztus 31-én megszűnik az Azure Cosmos DB Async Java SDK v2.x; az SDK és az SDK-t használó összes alkalmazás továbbra is működni fog; Az Azure Cosmos DB egyszerűen nem nyújt további karbantartást és támogatást ehhez az SDK-hoz. Javasoljuk, hogy kövesse a fenti utasításokat az Azure Cosmos DB Java SDK v4-be való migráláshoz.
Az Azure Cosmos DB egy gyors és rugalmas elosztott adatbázis, amely zökkenőmentesen méretezhető, garantált késéssel és átviteli sebességgel. Nem kell jelentős architektúramódosításokat végeznie, vagy összetett kódot kell írnia az adatbázis Azure Cosmos DB-vel való skálázásához. A vertikális fel- és leskálázás olyan egyszerű, mint egyetlen API-hívás vagy SDK-metódushívás. Mivel azonban az Azure Cosmos DB hálózati hívásokon keresztül érhető el, ügyféloldali optimalizálásokkal csúcsteljesítmény érhető el az Azure Cosmos DB Async Java SDK v2 használatakor.
Ha tehát a "Hogyan javíthatom az adatbázis teljesítményét?" kérdésre válaszol, vegye figyelembe a következő lehetőségeket:
Kapcsolati mód: Közvetlen mód használata
Az ügyfél Azure Cosmos DB-hez való kapcsolódásának fontos hatása van a teljesítményre, különösen az ügyféloldali késés szempontjából. A ConnectionMode az ügyfél ConnectionPolicy konfigurálásához elérhető kulcskonfigurációs beállítás. Az Azure Cosmos DB Async Java SDK v2 esetében a két elérhető ConnectionModes a következő:
Az átjáró mód minden SDK-platformon támogatott, és alapértelmezés szerint ez a konfigurált beállítás. Ha az alkalmazások szigorú tűzfalkorlátozásokkal rendelkező vállalati hálózaton futnak, az átjáró mód a legjobb választás, mivel a szabványos HTTPS-portot és egyetlen végpontot használja. A teljesítménybeli kompromisszum azonban az, hogy az átjáró mód további hálózati ugrást foglal magában minden alkalommal, amikor az adatok beolvasása vagy írása az Azure Azure Cosmos DB-be történik. Emiatt a közvetlen mód jobb teljesítményt nyújt a kevesebb hálózati ugrás miatt.
A ConnectionMode a DocumentClient-példány létrehozásakor konfigurálva van a ConnectionPolicy paraméterrel.
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
Ügyfelek rendezése ugyanabban az Azure-régióban a teljesítmény érdekében
Ha lehetséges, helyezze az Azure Cosmos DB-t hívó alkalmazásokat ugyanabban a régióban, mint az Azure Cosmos DB-adatbázis. Hozzávetőleges összehasonlításként az ugyanazon régión belül az Azure Cosmos DB-be irányuló hívások 1–2 ms-on belül befejeződnek, de az USA >nyugati és keleti partja közötti késés 50 ms. Ez a késés valószínűleg a kéréstől függően változhat attól függően, hogy a kérés milyen útvonalon halad át az ügyfélről az Azure-adatközpont határára. A lehető legkisebb késést úgy érheti el, hogy a hívó alkalmazás ugyanabban az Azure-régióban található, mint a kiépített Azure Cosmos DB-végpont. Az elérhető régiók listáját az Azure-régiók című témakörben találja.
A legújabb SDK telepítése
Az Azure Cosmos DB SDK-k folyamatosan fejlődnek a legjobb teljesítmény érdekében. Tekintse meg az Azure Cosmos DB Async Java SDK v2 kiadási jegyzetoldalait a legújabb SDK meghatározásához és a fejlesztések áttekintéséhez.
Egyetlen azure Cosmos DB-ügyfél használata az alkalmazás teljes élettartama alatt
Minden AsyncDocumentClient-példány szálbiztos, és hatékony kapcsolatkezelést és cím-gyorsítótárazást végez. A hatékony kapcsolatkezelés és az AsyncDocumentClient jobb teljesítménye érdekében az alkalmazás teljes élettartama alatt ajánlott az AsyncDocumentClient appDomain-onkénti egyetlen példányát használni.
A ConnectionPolicy finomhangolása
Alapértelmezés szerint a közvetlen módú Azure Cosmos DB-kérések TCP-en keresztül jönnek létre az Azure Cosmos DB Async Java SDK v2 használatakor. Az SDK belsőleg egy speciális Közvetlen módú architektúrát használ a hálózati erőforrások dinamikus kezeléséhez és a legjobb teljesítmény eléréséhez.
Az Azure Cosmos DB Async Java SDK v2-ben a Közvetlen mód a legjobb választás az adatbázis teljesítményének javítására a legtöbb számítási feladat esetében.
- A Közvetlen mód áttekintése
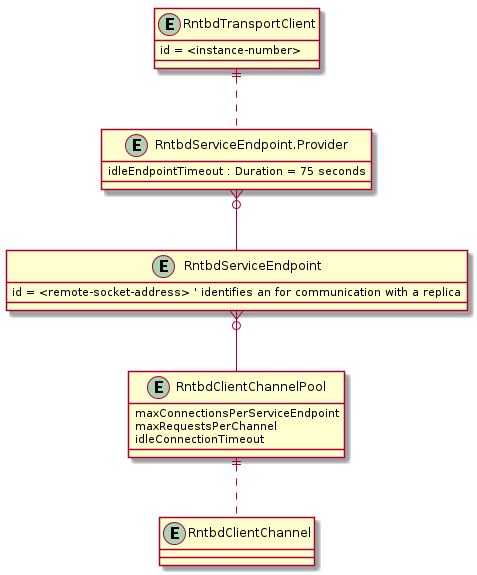
A Közvetlen módban alkalmazott ügyféloldali architektúra kiszámítható hálózatkihasználtságot és multiplexált hozzáférést tesz lehetővé az Azure Cosmos DB-replikákhoz. A fenti ábra azt mutatja be, hogyan irányítja a Közvetlen mód az ügyfélkéréseket az Azure Cosmos DB háttérrendszer replikáihoz. A közvetlen módú architektúra legfeljebb 10 csatornát foglal le az ügyféloldalon DB-replikánként. A csatorna olyan TCP-kapcsolat, amelyet egy kéréspuffer előz meg, amely 30 kérelemmélység. A replikához tartozó csatornákat a replika szolgáltatásvégpontja szükség szerint dinamikusan lefoglalja. Amikor a felhasználó közvetlen módban ad ki kérést, a TransportClient a partíciókulcs alapján átirányítja a kérést a megfelelő szolgáltatásvégpontra. A kérelemsor puffereli a kéréseket a szolgáltatásvégpont előtt.
A ConnectionPolicy konfigurációs beállításai a Közvetlen módhoz
Első lépésként használja az alábbi ajánlott konfigurációs beállításokat. Lépjen kapcsolatba az Azure Cosmos DB csapatával , ha problémákba ütközik ebben a témakörben.
Ha az Azure Cosmos DB-t használja referenciaadatbázisként (vagyis az adatbázist sok pontolvasási művelethez és kevés írási művelethez használja), akkor elfogadható lehet az idleEndpointTimeout 0 értékre (azaz időtúllépés nélkül) beállítására.
Konfigurációs beállítás Alapértelmezett bufferPageSize 8192 connectionTimeout "PT1M" idleChannelTimeout "PT0S" idleEndpointTimeout "PT1M10S" maxBufferCapacity 8388608 maxChannelsPerEndpoint 10 maxRequestsPerChannel 30 receiveHangDetectionTime "PT1M5S" requestExpiryInterval "PT5S" requestTimeout "PT1M" requestTimerResolution "PT0.5S" sendHangDetectionTime "PT10S" shutdownTimeout "PT15S"
Programozási tippek a Közvetlen módhoz
Tekintse át az Azure Cosmos DB Async Java SDK v2 hibaelhárítási cikkét alapkonfigurációként az SDK-problémák megoldásához.
Néhány fontos programozási tipp a Közvetlen mód használatakor:
Használjon többszálú módban az alkalmazásban a hatékony TCP-adatátvitel érdekében – A kérés elküldése után az alkalmazásnak elő kell fizetnie, hogy adatokat fogadjon egy másik szálon. Ha ezt nem teszi meg, a program nem kívánt "féloldalas" műveletet hajt végre, és az azt követő kérések le lesznek tiltva az előző kérés válaszára várva.
Számítási igényű számítási feladatok végrehajtása dedikált szálon – Az előző tipphez hasonló okokból az olyan műveletek, mint az összetett adatfeldolgozás, a legjobban egy külön szálba kerülnek. Egy olyan kérés, amely adatokat kér le egy másik adattárból (például ha a szál egyidejűleg használja az Azure Cosmos DB-t és a Spark-adattárakat), nagyobb késést tapasztalhat, és ajánlott egy további szálat létrehozni, amely a másik adattár válaszára vár.
- Az Azure Cosmos DB Async Java SDK v2-ben a mögöttes hálózati I/O-t a Netty kezeli. Tekintse meg ezeket a tippeket a Netty IO-szálakat blokkoló kódolási minták elkerüléséhez.
Adatmodellezés – Az Azure Cosmos DB SLA 1 KB-nál kisebb dokumentumméretet feltételez. Ha optimalizálja az adatmodellt és a programozást a kisebb dokumentumméret érdekében, általában csökken a késés. Ha 1 KB-nál nagyobb dokumentumok tárolására és lekérésére van szüksége, az ajánlott módszer az, hogy a dokumentumok az Azure Blob Storage-ban lévő adatokra hivatkoznak.
Párhuzamos lekérdezések hangolása particionált gyűjteményekhez
Az Azure Cosmos DB Async Java SDK v2 támogatja a párhuzamos lekérdezéseket, amelyek lehetővé teszik a particionált gyűjtemények párhuzamos lekérdezését. További információt az SDK-k használatához kapcsolódó kódmintákban talál. A párhuzamos lekérdezések célja, hogy javítsák a lekérdezések késését és átviteli sebességét a soros megfelelőjükkel szemben.
Tuning setMaxDegreeOfParallelism:
A párhuzamos lekérdezések több partíció párhuzamos lekérdezésével működnek. Az egyes particionált gyűjteményekből származó adatokat azonban a rendszer a lekérdezés szempontjából sorosan olvassa be. Ezért a setMaxDegreeOfParallelism használatával állítsa be azoknak a partícióknak a számát, amelyek a legnagyobb eséllyel érik el a legkiteljesítőbb lekérdezést, feltéve, hogy az összes többi rendszerfeltétel változatlan marad. Ha nem tudja a partíciók számát, a setMaxDegreeOfParallelism használatával beállíthatja a magas számot, és a rendszer a minimális (partíciók száma, felhasználó által megadott bemenet) értéket választja a párhuzamosság maximális fokaként.
Fontos megjegyezni, hogy a párhuzamos lekérdezések akkor biztosítják a legjobb előnyöket, ha az adatok egyenletesen oszlanak el az összes partíció között a lekérdezés szempontjából. Ha a particionált gyűjteményt úgy particionálják, hogy a lekérdezés által visszaadott adatok teljes vagy nagy része néhány partícióban (legrosszabb esetben egy partícióban) koncentrálódik, akkor a lekérdezés teljesítményét szűk keresztmetszetet képeznének ezek a partíciók.
Tuning setMaxBufferedItemCount:
A párhuzamos lekérdezés úgy lett kialakítva, hogy előre leküldje az eredményeket, miközben az ügyfél feldolgozza az aktuális eredményköteget. Az előkezelés segít a lekérdezések késésének általános javításában. a setMaxBufferedItemCount korlátozza az előre megadott eredmények számát. Ha beállítja aMaxBufferedItemCount értéket a visszaadott eredmények várt számára (vagy magasabb számra), akkor a lekérdezés maximális előnyt élvezhet az előkezelésből.
Az előtelepítés ugyanúgy működik, függetlenül a MaxDegreeOfParallelizmustól, és az összes partíció adatainak egyetlen puffere van.
Backoff implementálása getRetryAfterInMilliseconds időközönként
A teljesítménytesztelés során növelnie kell a terhelést, amíg a kérések kis száma nem lesz szabályozva. Ha szabályozva van, az ügyfélalkalmazásnak vissza kell adnia a kiszolgáló által megadott újrapróbálkozási időközt. A visszalépés tiszteletben tartása biztosítja, hogy minimális időt töltsön várakozással az újrapróbálkozások között.
Az ügyfél-számítási feladatok vertikális felskálázása
Ha magas átviteli sebességen (>50 000 RU/s) tesztel, az ügyfélalkalmazás szűk keresztmetszetté válhat, mivel a gép túllépi a processzor- vagy hálózati kihasználtságot. Ha eléri ezt a pontot, folytathatja az Azure Cosmos DB-fiók további leküldését az ügyfélalkalmazások több kiszolgálón való skálázásával.
Névalapú címzés használata
Használjon névalapú címzést, ahol a hivatkozások formátuma
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentIda SelfLinks (_self) helyett, amelyek formátumadbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>lehetővé teszi a hivatkozás létrehozásához használt összes erőforrás ResourceId-azonosítóinak lekérését. Emellett, mivel ezek az erőforrások újra létrejönnek (valószínűleg ugyanazzal a névvel), a gyorsítótárazás nem feltétlenül segít.A lekérdezések/olvasási hírcsatornák oldalméretének finomhangolása a jobb teljesítmény érdekében
Ha a dokumentumok tömeges olvasását olvasási csatornával (például readDocuments) vagy SQL-lekérdezés kiadásakor hajtja végre, a rendszer szegmentált módon adja vissza az eredményeket, ha az eredményhalmaz túl nagy. Alapértelmezés szerint a rendszer 100 elemből vagy 1 MB-ból álló adattömbökben adja vissza az eredményeket, attól függően, hogy melyik korlátot éri el először a rendszer.
Az összes vonatkozó eredmény lekéréséhez szükséges hálózati kerek utak számának csökkentése érdekében az x-ms-max-item-count kérelem fejlécével akár 1000-ra is növelheti az oldalméretet. Azokban az esetekben, amikor csak néhány eredményt kell megjelenítenie, például ha a felhasználói felület vagy az application API csak 10 találatot ad vissza egyszerre, az oldalméretet 10-re is csökkentheti az olvasások és lekérdezések által felhasznált átviteli sebesség csökkentése érdekében.
Az oldalméretet a setMaxItemCount metódussal is beállíthatja.
Megfelelő ütemező használata (Az eseményhurok IO Netty-szálainak ellopásának elkerülése)
Az Azure Cosmos DB Async Java SDK v2 netty használatával tiltja le az IO-t. Az SDK rögzített (a gép processzormagjainak számával egyező) számú IO-eseményhurok Netty-szálat használ az IO-műveletek végrehajtásához. Az API által visszaadott Megfigyelhető kibocsátja az eredményt az egyik megosztott IO-eseményhurok netty szálán. Ezért fontos, hogy a megosztott IO-eseményhurok Netty-szálak ne legyenek blokkolva. A cpu-igényes munka vagy az IO-eseményhurok hálós szálon történő blokkolása holtpontot okozhat, vagy jelentősen csökkentheti az SDK átviteli sebességét.
Az alábbi kód például processzorigényes munkát hajt végre az eseményhurok IO netty szálán:
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });Az eredmény beérkezése után, ha processzorigényes munkát szeretne végezni az eredményen, el kell kerülnie ezt az eseményhurok IO netty szálán. Ehelyett saját Ütemezőt is megadhat, hogy saját szálat biztosítson a munkája futtatásához.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });A munka típusától függően a megfelelő meglévő RxJava Schedulert kell használnia a munkájához. Olvassa el itt
Schedulers.További információkért tekintse meg az Azure Cosmos DB Async Java SDK v2 GitHub-oldalát .
Netty naplózásának letiltása
A Netty-kódtár naplózása beszédes, és ki kell kapcsolni (a konfigurációba való bejelentkezés letiltása nem elegendő) a további PROCESSZORköltségek elkerülése érdekében. Ha nem hibakeresési módban van, tiltsa le teljesen a Netty naplózását. Ha tehát a log4j használatával távolítja el a netty által
org.apache.log4j.Category.callAppenders()okozott további CPU-költségeket, adja hozzá a következő sort a kódbázishoz:org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);Operációs rendszer – Fájlok erőforráskorlátja
Egyes Linux-rendszerek (például a Red Hat) felső határt szabnak a megnyitott fájlok számának, így a kapcsolatok teljes számának. Futtassa a következőt az aktuális korlátok megtekintéséhez:
ulimit -aA megnyitott fájlok (nofile) számának elég nagynak kell lennie ahhoz, hogy elegendő hely legyen a konfigurált kapcsolatkészlet méretéhez és az operációs rendszer által megnyitott egyéb fájlokhoz. Módosítható, hogy nagyobb kapcsolatkészletméretet biztosíthasson.
Nyissa meg a limits.conf fájlt:
vim /etc/security/limits.confAdja hozzá/módosítsa a következő sorokat:
* - nofile 100000
Nem használt útvonalak kizárása az indexelésből a gyorsabb írás érdekében
Az Azure Cosmos DB indexelési szabályzata lehetővé teszi, hogy az Indexelési útvonalak (setIncludedPaths és setExcludedPaths) használatával megszűrje, hogy mely dokumentumelérési utakat vegye fel vagy zárja ki az indexelésből. Az indexelési útvonalak használata jobb írási teljesítményt és alacsonyabb indextárolást kínálhat azokhoz a forgatókönyvekhez, amelyekben a lekérdezési minták előre ismertek, mivel az indexelési költségek közvetlenül korrelálnak az indexelt egyedi útvonalak számával. Az alábbi kód például azt mutatja be, hogyan zárhatja ki a dokumentumok egy teljes szakaszát (más néven részösszeget) az indexelésből a "*" helyettesítő karakterrel.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);További információ: Azure Cosmos DB indexelési szabályzatok.
Kisebb kérelemegységek/másodperces használat mérése és finomhangolása
Az Azure Cosmos DB számos adatbázisműveletet kínál, beleértve a relációs és hierarchikus lekérdezéseket az UDF-ekkel, a tárolt eljárásokat és az eseményindítókat – mind az adatbázis-gyűjtemény dokumentumain. Az egyes ilyen műveletekhez kapcsolódó költségek a művelet végrehajtásához szükséges CPU, IO és memória függvényében változnak. A hardvererőforrások átgondolása és kezelése helyett egyetlen mértékként tekinthet a kérelemegységre (RU) a különböző adatbázis-műveletek végrehajtásához és az alkalmazáskérelmek kiszolgálásához szükséges erőforrásokhoz.
Az átviteli sebesség az egyes tárolókhoz beállított kérelemegységek száma alapján van kiépítve. A kérelemegység-felhasználás másodpercenkénti sebességként lesz kiértékelve. A tárolóhoz kiosztott kérelemegység-mértéket meghaladó alkalmazások korlátozottak, amíg a sebesség nem csökken a tárolóhoz kiosztott szint alá. Ha az alkalmazás magasabb átviteli sebességet igényel, további kérelemegységek kiépítésével növelheti az átviteli sebességet.
A lekérdezések összetettsége hatással van arra, hogy egy művelet hány kérelemegységet használ fel. A predikátumok száma, a predikátumok jellege, az UDF-ek száma és a forrásadatkészlet mérete mind befolyásolják a lekérdezési műveletek költségeit.
Bármely művelet (létrehozás, frissítés vagy törlés) többletterhelésének méréséhez vizsgálja meg az x-ms-request-charge fejlécet a műveletek által felhasznált kérelemegységek számának méréséhez. A ResourceResponse T vagy a FeedResponse<T>> egyenértékű RequestCharge tulajdonságát<is megtekintheti.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();Az ebben a fejlécben visszaadott kérelemdíj a kiosztott átviteli sebesség töredékét adja. Ha például 2000 RU/s van kiépítve, és ha az előző lekérdezés 1000 1 KB dokumentumot ad vissza, a művelet költsége 1000. Így egy másodpercen belül a kiszolgáló csak két ilyen kérést tart tiszteletben, mielőtt a sebesség korlátozza a későbbi kéréseket. További információ: Kérelemegységek és a kérelemegység-kalkulátor.
Túl nagy sebességkorlátozás/kérési sebesség kezelése
Amikor egy ügyfél megkísérli túllépni egy fiók fenntartott átviteli sebességét, a kiszolgálón nincs teljesítménycsökkenés, és az átviteli kapacitás használata nem lépi túl a fenntartott szintet. A kiszolgáló előzetesen a RequestRateTooLarge (HTTP-állapotkód: 429) paranccsal fejezi be a kérést, és visszaadja az x-ms-retry-after-ms fejlécet, amely azt jelzi, hogy a felhasználónak ezredmásodpercben mennyi időt kell várnia a kérés újbóli megismétlése előtt.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Az SDK-k implicit módon elkapják ezt a választ, tiszteletben tartják a kiszolgáló által megadott újrapróbálkozási fejlécet, és újrapróbálkoznak a kéréssel. Ha a fiókját nem éri el egyszerre több ügyfél, a következő újrapróbálkozás sikeres lesz.
Ha több ügyfél kumulatív működése következetesen meghaladja a kérések arányát, előfordulhat, hogy az ügyfél által belsőleg jelenleg 9-re beállított alapértelmezett újrapróbálkozási szám nem elegendő; ebben az esetben az ügyfél egy DocumentClientException 429-as állapotkódot ad az alkalmazásnak. Az alapértelmezett újrapróbálkozási szám a ConnectionPolicy-példány setRetryOptions parancsával módosítható. Alapértelmezés szerint a 429-es állapotkódú DocumentClientException 30 másodperces kumulatív várakozási idő után lesz visszaadva, ha a kérés továbbra is a kérési sebesség felett működik. Ez akkor is előfordul, ha az újrapróbálkozások aktuális száma kisebb, mint a maximális újrapróbálkozások száma, legyen az alapértelmezett érték 9 vagy felhasználó által megadott érték.
Bár az automatikus újrapróbálkozási viselkedés segít javítani a rugalmasságot és a használhatóságot a legtöbb alkalmazás esetében, a teljesítménymutatók használatakor előfordulhat, különösen a késés mérése során. Az ügyfél által megfigyelt késés megnő, ha a kísérlet eléri a kiszolgálót, és az ügyfél SDK-jának csendes újrapróbálkozását okozza. A teljesítménykísérletek során fellépő késési csúcsok elkerülése érdekében mérje meg az egyes műveletek által visszaadott díjat, és győződjön meg arról, hogy a kérések a fenntartott kérések aránya alatt működnek. További információ: Kérelemegységek.
Kisebb dokumentumok tervezése a nagyobb átviteli sebesség érdekében
Egy adott művelet kérelemdíja (a kérelem feldolgozási költsége) közvetlenül korrelál a dokumentum méretével. A nagyméretű dokumentumokon végzett műveletek többe kerülnek, mint a kis méretű dokumentumok műveletei.
Ha többet szeretne megtudni az alkalmazás méretezéshez és nagy teljesítményhez való tervezéséről, tekintse meg a particionálást és a skálázást az Azure Cosmos DB-ben.