Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Fontos
Az Azure Cosmos DB for PostgreSQL már nem támogatott új projektek esetén. Ne használja ezt a szolgáltatást új projektekhez. Ehelyett használja az alábbi két szolgáltatás egyikét:
Az Azure Cosmos DB for NoSQL használata nagy léptékű forgatókönyvekhez tervezett elosztott adatbázis-megoldáshoz 99,999% rendelkezésre állási szolgáltatásiszint-szerződéssel (SLA), azonnali automatikus skálázással és automatikus feladatátvétellel több régióban.
Használja az Azure Database For PostgreSQL Rugalmas fürtök funkcióját a megosztott PostgreSQL-hez a nyílt forráskódú Citus-bővítmény használatával.
Az egyes táblák elosztási oszlopának kiválasztása az egyik legfontosabb modellezési döntés. Az Azure Cosmos DB for PostgreSQL szegmensekben tárolja a sorokat a sorok terjesztési oszlopának értéke alapján.
A megfelelő választási lehetőség a kapcsolódó adatokat ugyanazon a fizikai csomóponton csoportosítja, ami gyorsabbá teszi a lekérdezéseket, és támogatja az ÖSSZES SQL-funkciót. Helytelen választás esetén a rendszer lassan fut.
Általános tippek
Az alábbi négy kritérium alapján választhatja ki az elosztott táblák ideális terjesztési oszlopát.
Válasszon egy oszlopot, amely az alkalmazás számítási feladatainak központi része.
Erre az oszlopra úgy gondolhat, mint a "szív", a "központi darab" vagy az adatok particionálásának természetes dimenziója.
Példák:
-
device_idIoT-munkaterhelésben -
security_idolyan pénzügyi alkalmazás esetében, amely nyomon követi az értékpapírokat -
user_idfelhasználói elemzésekben -
tenant_idtöbb-bérlős SaaS-alkalmazáshoz
-
Válasszon egy tisztességes számosságot és egyenletes statisztikai eloszlású oszlopot.
Az oszlopnak sok értékkel kell rendelkeznie, és alaposan és egyenletesen el kell osztania az összes szegmens között.
Példák:
- Több mint 1000 elem
- Ne válasszon olyan oszlopot, amely a sorok nagy százalékában azonos értékkel rendelkezik (adateltérés)
- Egy SaaS-számítási feladat esetén, ha egy bérlő sokkal nagyobb a többinél, az adateltéréshez vezethet. Ebben a helyzetben a bérlői elkülönítés használatával létrehozhat egy dedikált szegmenst a bérlő kezeléséhez.
Válasszon ki egy olyan oszlopot, amely a meglévő lekérdezések előnyeit élvezi.
Tranzakciós vagy üzemeltetési számítási feladatok esetén (ahol a legtöbb lekérdezés csak néhány ezredmásodpercet vesz igénybe), válasszon egy oszlopot, amely szűrőként
WHEREjelenik meg a lekérdezések legalább 80%-ának záradékaiban. Például adevice_idoszlop aSELECT * FROM events WHERE device_id=1.Az elemzési számítási feladatokhoz (ahol a legtöbb lekérdezés 1–2 másodpercet vesz igénybe) válasszon egy oszlopot, amely lehetővé teszi a lekérdezések párhuzamosságát a feldolgozó csomópontok között. Egy oszlop például gyakran előfordul a GROUP BY záradékokban, vagy egyszerre több értéket kérdez le.
Válasszon egy oszlopot, amely a nagy táblák többségében található.
Az 50 GB-nál nagyobb táblákat el kell osztani. Ha mindegyikhez ugyanazt a terjesztési oszlopot választja, lehetővé válik az oszlop adatainak munkavégző csomópontokon való együttes elhelyezése. Az együtt elhelyezés hatékonyabbá teszi a JOIN-ok és az összesítők futtatását, valamint az idegen kulcsok érvényesítését.
A többi (kisebb) tábla lehet helyi vagy referenciatábla. Ha a kisebb táblának elosztott táblákkal kell CSATLAKOZNIa, készítsen referenciatáblázatot.
Példák a használati esetekre
Általános kritériumokat láttunk a terjesztési oszlop kiválasztásához. Most lássuk, hogyan alkalmazhatók a gyakori használati esetekre.
Több-bérlős alkalmazások
A több-bérlős architektúra hierarchikus adatbázismodellezéssel osztja el a lekérdezéseket a fürt csomópontjai között. Az adathierarchia tetejét bérlőazonosítónak nevezzük, és minden táblában egy oszlopban kell tárolni.
Az Azure Cosmos DB for PostgreSQL a lekérdezéseket vizsgálja meg annak megtekintéséhez, hogy melyik bérlőazonosítót foglalja magában, és megkeresi a megfelelő táblaszegélyt. A lekérdezést egyetlen feldolgozó csomópontra irányítja, amely a szegmenst tartalmazza. Az ugyanazon a csomóponton elhelyezett összes releváns adattal rendelkező lekérdezést kolocationnak nevezzük.
Az alábbi ábra a több-bérlős adatmodellben való elhelyezést szemlélteti. Ez két táblát, a Számlák és Kampányok táblát tartalmaz, amelyeket account_id szerint osztanak el. Az árnyékolt mezők töredékeket jelölnek. A zöld szegmensek együtt vannak tárolva egy feldolgozó csomóponton, a kék szegmensek pedig egy másik munkavégző csomóponton. Figyelje meg, hogy a fiókok és kampányok közötti illesztési lekérdezések az összes szükséges adatot együtt tartalmazzák egy csomóponton, ha mindkét tábla ugyanarra a account_id korlátozódik.
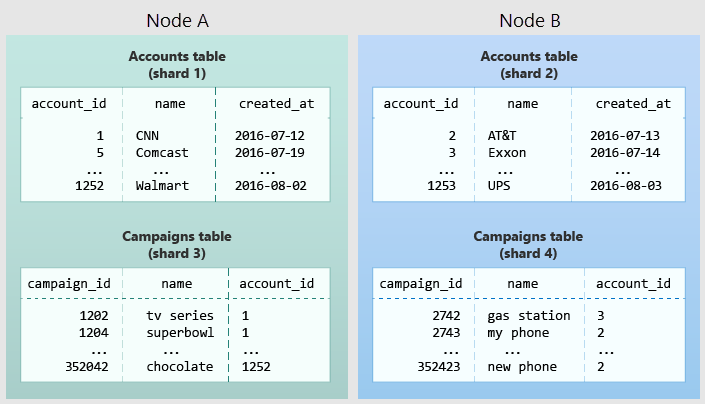
Ha saját sémájában szeretné alkalmazni ezt a tervet, azonosítsa, hogy mi minősül bérlőnek az alkalmazásban. Gyakori példa erre a cég, a fiók, a szervezet vagy az ügyfél. Az oszlop neve a következőhöz hasonló company_id lesz: vagy customer_id. Vizsgálja meg az egyes lekérdezéseket, és kérdezze meg magától, hogy működik-e, ha több WHERE záradékkal korlátozná az összes érintett táblát ugyanazzal a bérlőazonosítóval rendelkező sorokra? A több-bérlős modellben lévő lekérdezések hatóköre egy bérlőre terjed ki. Az értékesítéssel vagy leltárral kapcsolatos lekérdezések hatóköre például egy adott tárolón belül van.
Ajánlott eljárások
- Táblák elosztása egy közös tenant_id oszlop szerint. Például egy olyan SaaS-alkalmazásban, ahol a bérlők vállalatok, a tenant_id valószínűleg a company_id.
- Kis bérlőközi táblák átalakítása referenciatáblákká. Ha több bérlő osztozik egy kis információtáblán, ossza el referenciatáblázatként.
- Az összes alkalmazás-lekérdezés szűrésének korlátozása tenant_id szerint. Minden lekérdezésnek egyszerre egy bérlő adatait kell kérnie.
Olvassa el a több-bérlős oktatóanyagot, amely példát ad arra, hogyan hozhat létre ilyen alkalmazást.
Valós idejű alkalmazások
A több-bérlős architektúra hierarchikus struktúrát vezet be, és adat-elhelyezést használ a lekérdezések bérlőnkénti irányításához. Ezzel szemben a valós idejű architektúrák az adataik adott terjesztési tulajdonságaitól függenek a magas párhuzamos feldolgozás érdekében.
Az "entitásazonosítót" a valós idejű modell terjesztési oszlopainak kifejezéseként használjuk. Jellemző entitások a felhasználók, gépek vagy eszközök.
A valós idejű lekérdezések általában dátum vagy kategória szerint csoportosított numerikus aggregátumokat kérnek. Az Azure Cosmos DB for PostgreSQL elküldi ezeket a lekérdezéseket az egyes szegmenseknek részleges eredményekért, és összeállítja a végső választ a koordinátor csomópontján. A lekérdezések akkor futnak a leggyorsabban, ha a lehető legtöbb csomópont járul hozzá, és ha egyetlen csomópontnak sem kell aránytalanul nagy mennyiségű munkát végeznie.
Ajánlott eljárások
- Válasszon egy magas számosságú oszlopot terjesztési oszlopként. Összehasonlításként a rendeléstábla Állapot mezője az Új, Fizetett és Szállított értékekkel rossz választás terjesztési oszlopnak. Csak azt a néhány értéket feltételezi, amely korlátozza az adatokat tároló szegmensek számát és a feldolgozható csomópontok számát. A magas számosságú oszlopok között érdemes kiválasztani azokat az oszlopokat is, amelyeket gyakran használnak csoportosítási feltételekben vagy összekapcsolási kulcsként.
- Válasszon egy páros eloszlású oszlopot. Ha egy táblát egy olyan oszlop szerint oszt el, amely bizonyos gyakori értékeket tartalmaz, a táblában lévő adatok általában bizonyos partíciókban halmozódnak fel. A szegmenseket tartalmazó csomópontok végül több munkát végeznek, mint más csomópontok.
- Tény- és dimenziótáblák elosztása a közös oszlopokon. A ténytábla csak egy terjesztési kulccsal rendelkezhet. A másik kulcshoz összekapcsolt táblák nem lesznek elhelyezve a ténytáblával együtt. Válasszon ki egy dimenziót, amely az illesztés gyakorisága és az illesztési sorok mérete alapján van kiválasztva.
- Néhány dimenziótáblát referenciatáblákká alakít. Ha egy dimenziótáblát nem lehet a ténytáblával együtt áthelyezni, a dimenziótábla másolatainak a referenciatábla formájában az összes csomópontra való elosztásával javíthatja a lekérdezési teljesítményt.
Olvassa el a valós idejű irányítópult-oktatóanyagot , amely bemutatja, hogyan hozhat létre ilyen típusú alkalmazásokat.
Idősoradatok
Egy idősoros számítási feladatban az alkalmazások lekérdezik a legutóbbi információkat, miközben régi információkat archiválnak.
Az azure Cosmos DB for PostgreSQL-ben az idősoradatok modellezésének leggyakoribb hibája az időbélyeg használata terjesztési oszlopként. Az időalapú kivonateloszlás látszólag véletlenszerűen osztja el az időtartományokat különböző szegmensekbe ahelyett, hogy az időtartományokat szegmensekben tartanák. Az időt tartalmazó lekérdezések általában időtartományokra hivatkoznak, például a legfrissebb adatokra. Az ilyen típusú kivonateloszlás hálózati többletterheléshez vezet.
Ajánlott eljárások
- Ne válasszon időbélyeget terjesztési oszlopként. Válasszon másik terjesztési oszlopot. Több-bérlős alkalmazásokban használja a bérlőazonosítót, vagy valós idejű alkalmazásban használja az entitásazonosítót.
- Használja a PostgreSQL-tábla particionálását idő szerint. Táblaparticionálással az időrendbe rendezett adatok nagy tábláját több öröklődő táblára bonthatja, és mindegyik tábla különböző időtartományokat tartalmaz. A Postgres-particionált táblák elosztása szegmenseket hoz létre az örökölt táblákhoz.
Következő lépések
- Megtudhatja, hogyan segíti a lekérdezések gyors futtatását az elosztott adatok közötti elhelyezés .
- Megismerheti az elosztott táblák terjesztési oszlopát és más hasznos diagnosztikai lekérdezéseket.