Tömeges másolás adatbázisból az Azure Data Explorer a Azure Data Factory sablon használatával
Az Azure Data Explorer egy gyors, teljes körűen felügyelt adatelemzési szolgáltatás. Valós idejű elemzést nyújt nagy mennyiségű adatról, amelyek számos forrásból, például alkalmazásokból, webhelyekről és IoT-eszközökről streamelnek.
Ha az Oracle Server, Netezza, Teradata vagy SQL Server adatbázisából szeretne adatokat másolni az Azure Data Explorer, hatalmas mennyiségű adatot kell betöltenie több táblából. Az adatokat általában particionálni kell az egyes táblákban, hogy egyetlen táblából egyszerre több szálat tartalmazó sorokat tölthessenek be. Ez a cikk az ezekben a forgatókönyvekben használható sablonokat ismerteti.
Azure Data Factory sablonok előre definiált Data Factory-folyamatok. Ezek a sablonok segíthetnek a Data Factory gyors használatában, és csökkentheti az adatintegrációs projektek fejlesztési idejét.
A Tömeges másolás adatbázisból azure Data Explorer sablont a Keresési és a ForEach-tevékenységek használatával hozza létre. A gyorsabb adatmásolás érdekében a sablonnal adatbázisonként vagy táblánként számos folyamatot hozhat létre.
Fontos
Ügyeljen arra, hogy a másolni kívánt adatok mennyiségének megfelelő eszközt használja.
- A Tömeges másolás adatbázisból Azure-ba Data Explorer sablonnal nagy mennyiségű adatot másolhat olyan adatbázisokból, mint az SQL Server vagy a Google BigQuery az Azure Data Explorer.
- A Data Factory Adatok másolása eszközével kis vagy közepes mennyiségű adatot tartalmazó táblákat másolhat az Azure Data Explorer.
Előfeltételek
- Azure-előfizetés. Hozzon létre egy ingyenes Azure-fiókot.
- Egy Azure-Data Explorer-fürt és -adatbázis. Hozzon létre egy fürtöt és egy adatbázist.
- Egy adat-előállító. Hozzon létre egy adat-előállítót.
- Egy adatforrás.
ControlTableDataset létrehozása
A ControlTableDataset azt jelzi, hogy a rendszer milyen adatokat másol a forrásból a folyamat célhelyére. A sorok száma az adatok másolásához szükséges folyamatok teljes számát jelzi. A ControlTableDataset tulajdonságot a forrásadatbázis részeként kell definiálnia.
A SQL Server forrástábla formátumára példa látható a következő kódban:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
A kódelemeket a következő táblázat ismerteti:
| Tulajdonság | Leírás | Példa |
|---|---|---|
| PartitionId | A másolási sorrend | 1 |
| SourceQuery | A lekérdezés, amely azt jelzi, hogy mely adatok lesznek másolva a folyamat futásideje során | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | A céltábla neve | MyAdxTable |
Ha a ControlTableDataset formátuma eltérő, hozzon létre egy hasonló ControlTableDatasetet a formátumához.
A Tömeges másolás adatbázisból Azure Data Explorer sablonba
Az Első lépések panelen válassza a Folyamat létrehozása sablonból lehetőséget a Sablongyűjtemény panel megnyitásához.
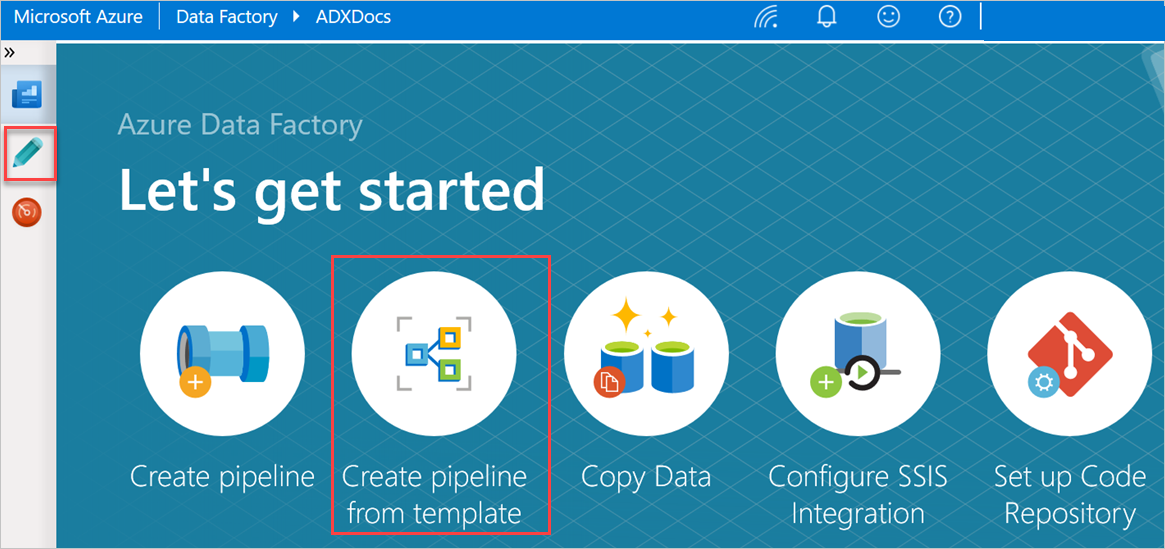
Válassza a Tömeges másolás adatbázisból Azure-ba Data Explorer sablont.
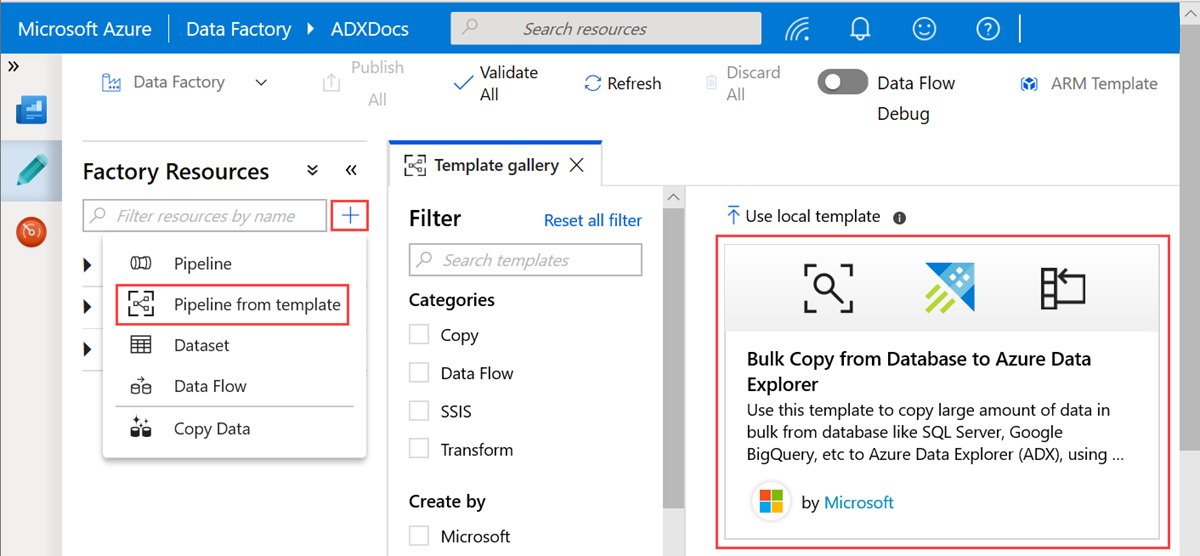
Az Adatbázisból az Azure-ba történő tömeges másolás Data Explorer panel Felhasználói bemenetek területén adja meg az adathalmazokat az alábbi módon:
a. A ControlTableDataset legördülő listában válassza ki a vezérlőtáblához társított szolgáltatást, amely jelzi, hogy a forrásból a célhelyre milyen adatok lesznek másolva, és hol lesznek elhelyezve a célhelyen.
b. A SourceDataset legördülő listában válassza ki a forrásadatbázishoz társított szolgáltatást.
c. Az AzureDataExplorerTable legördülő listában válassza ki az Azure Data Explorer táblát. Ha az adathalmaz nem létezik, hozza létre az Azure Data Explorer társított szolgáltatást az adathalmaz hozzáadásához.
d. Válassza a Sablon használata lehetőséget.
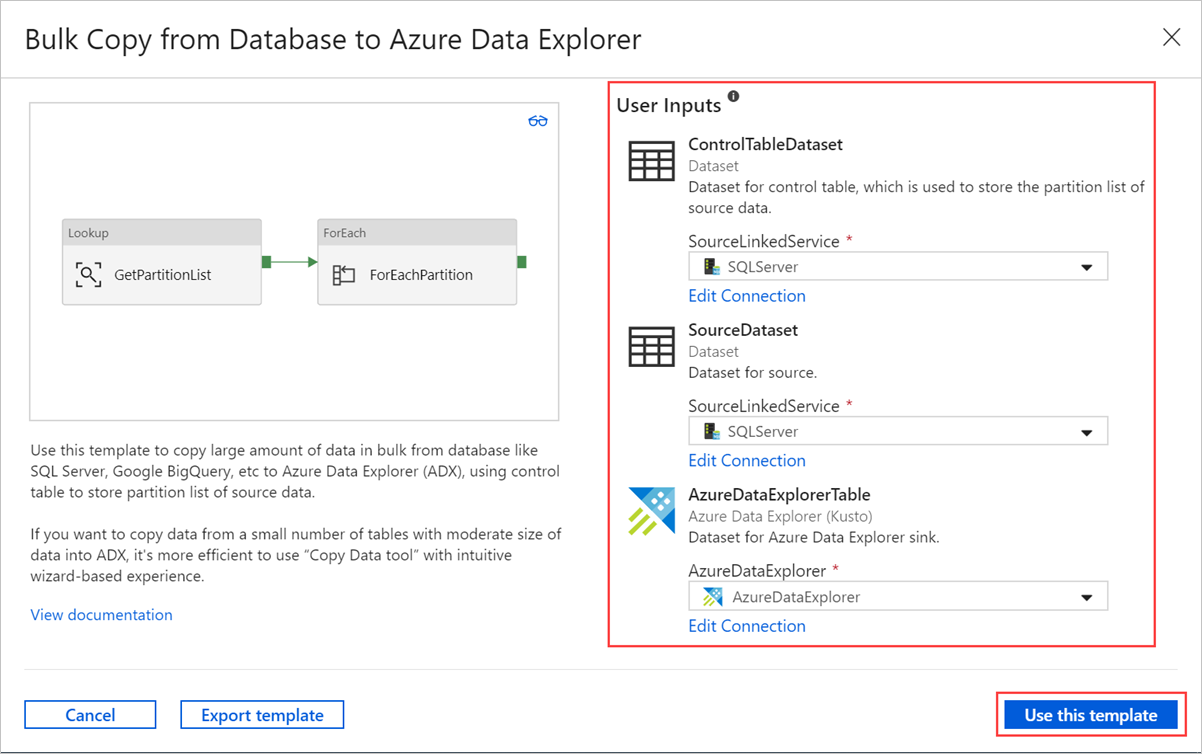
A sablonfolyamat eléréséhez jelöljön ki egy területet a vásznon a tevékenységeken kívül. A Paraméterek lapon adja meg a tábla paramétereit, beleértve a Nevet (vezérlőtábla neve) és az Alapértelmezett értéket (oszlopneveket).
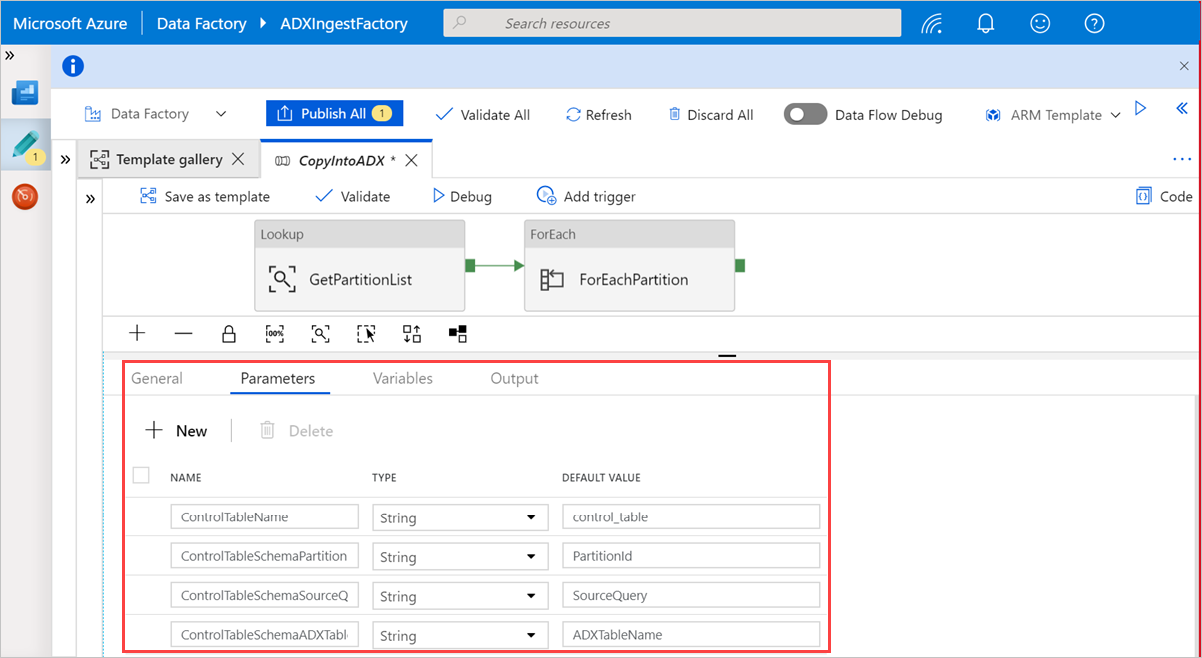
A Keresés területen válassza a GetPartitionList lehetőséget az alapértelmezett beállítások megtekintéséhez. A lekérdezés automatikusan létrejön.
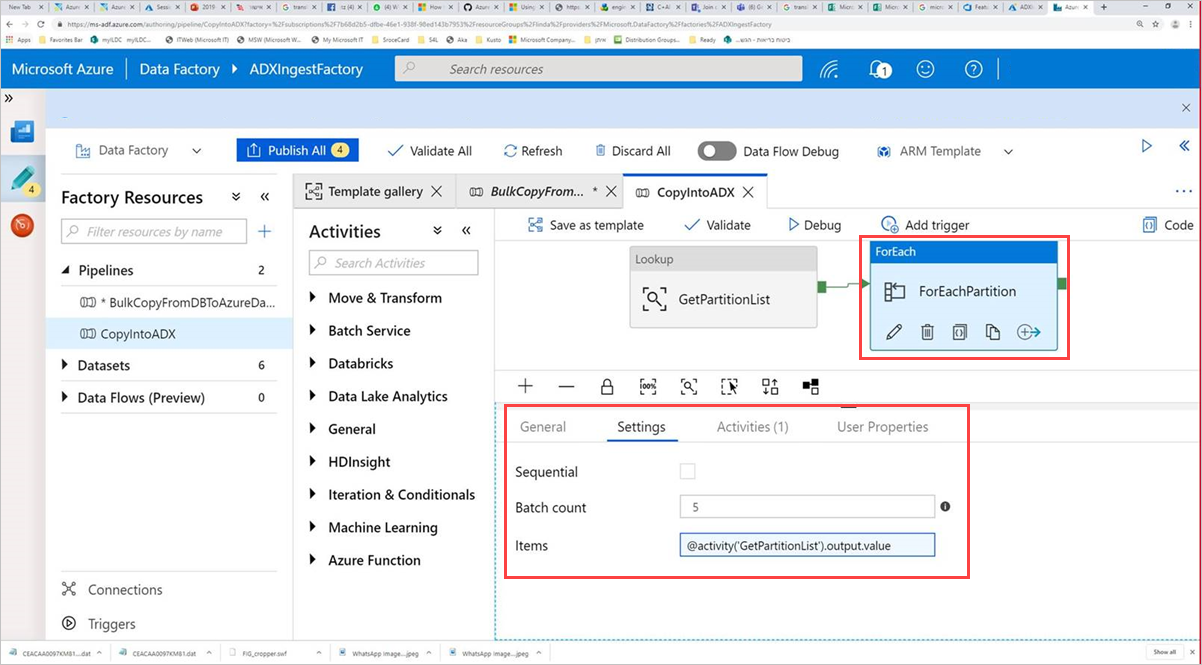
Válassza a Parancs tevékenység ForEachPartition elemét, válassza a Beállítások lapot, majd tegye a következőket:
a. A Batch count (Kötegek száma ) mezőbe írjon be egy 1 és 50 közötti számot. Ez a kijelölés határozza meg a párhuzamosan futó folyamatok számát, amíg el nem éri a ControlTableDataset sorainak számát.
b. Ha biztosítani szeretné, hogy a folyamatkötegek párhuzamosan fussanak, ne jelölje be a Szekvenciális jelölőnégyzetet.
Tipp
Az ajánlott eljárás több folyamat párhuzamos futtatása, hogy az adatok gyorsabban másolhatók legyenek. A hatékonyság növelése érdekében particionálja a forrástáblában lévő adatokat, és folyamatonként egy partíciót foglal le a dátum és a tábla szerint.
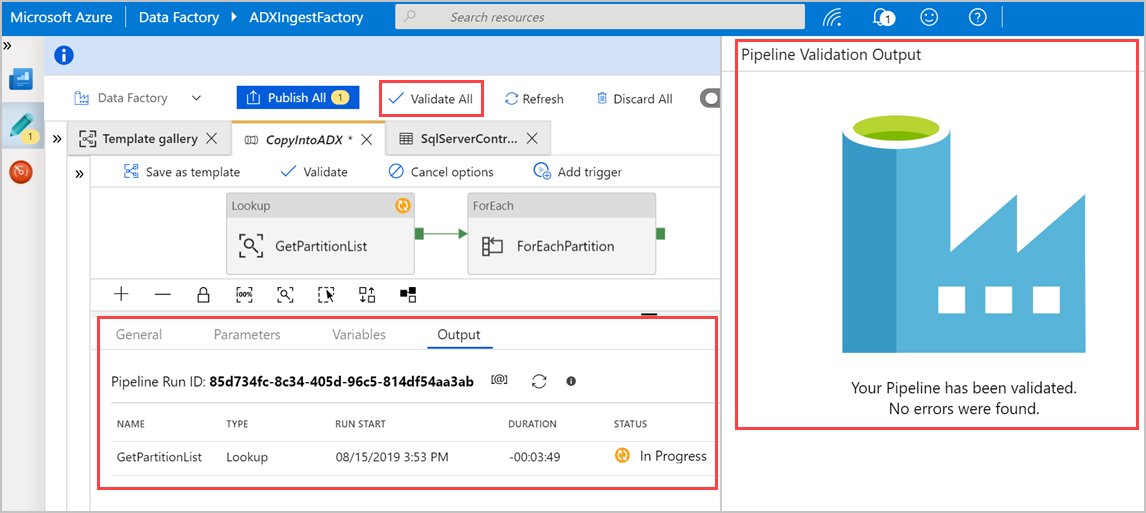
Válassza az Összes ellenőrzése lehetőséget a Azure Data Factory folyamat ellenőrzéséhez, majd tekintse meg az eredményt a Folyamatérvényesítés kimenete panelen.
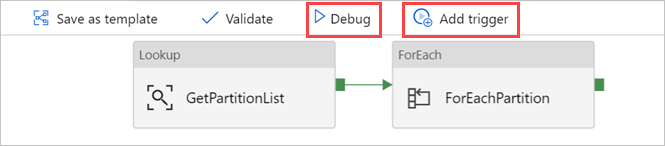
Ha szükséges, válassza a Hibakeresés lehetőséget, majd válassza az Eseményindító hozzáadása lehetőséget a folyamat futtatásához.
Mostantól a sablonnal hatékonyan másolhat nagy mennyiségű adatot az adatbázisokból és táblákból.
Kapcsolódó tartalom
- Tudnivalók a Azure Data Factory-hez készült Azure Data Explorer-összekötőről.
- Társított szolgáltatások, adathalmazok és folyamatok szerkesztése a Data Factory felhasználói felületén.
- Adatok lekérdezése az Azure Data Explorer webes felhasználói felületén.