Adatok lekérdezése az Azure Data Lake-ben az Azure Data Explorer használatával
Azure Data Lake Storage egy nagy mértékben skálázható és költséghatékony Data Lake-megoldás big data-elemzésekhez. Egyesíti a nagy teljesítményű fájlrendszer erejét a nagy léptékű és gazdaságos működéssel, így csökkentheti az elemzési időt. Data Lake Storage Gen2 kiterjeszti Azure Blob Storage képességeket, és elemzési számítási feladatokra van optimalizálva.
Az Azure Data Explorer integrálható Azure Blob Storage és Azure Data Lake Storage (Gen1 és Gen2), gyors, gyorsítótárazott és indexelt hozzáférést biztosít a külső tárolóban tárolt adatokhoz. Az Azure Data Explorer előzetes betöltése nélkül elemezheti és lekérdezheti az adatokat. Egyidejűleg lekérdezheti a betöltött és a be nem betöltött külső adatokat is. További információ: Külső tábla létrehozása az Azure Data Explorer webes felhasználói felület varázslóval. Rövid áttekintést a külső táblákban talál.
Tipp
A legjobb lekérdezési teljesítmény megköveteli az azure-Data Explorer való adatbetöltést. A külső adatok előzetes betöltés nélküli lekérdezésének képessége csak előzményadatokhoz vagy ritkán lekérdezett adatokhoz használható. Optimalizálja a külső adat lekérdezési teljesítményét a legjobb eredmény érdekében.
Külső tábla létrehozása
Tegyük fel, hogy sok OLYAN CSV-fájllal rendelkezik, amely a raktárban tárolt termékek előzményadatait tartalmazza, és gyors elemzést szeretne végezni az elmúlt év öt legnépszerűbb termékének megkereséséhez. Ebben a példában a CSV-fájlok a következőképpen néznek ki:
| Időbélyeg | ProductId | TermékLeírás |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3,5in DS/HD hajlékonylemez |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Szintetizátor |
| ... | ... | ... |
A fájlok tárolása az Azure Blob Storage-ban mycompanystorage történik egy nevű tárolóban archivedproducts, dátum szerint particionálva:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Ha közvetlenül ezeken a CSV-fájlokon szeretne KQL-lekérdezést futtatni, az .create external table paranccsal definiáljon egy külső táblát az Azure Data Explorer. A külső tábla létrehozási parancsbeállításaival kapcsolatos további információkért lásd: külső táblaparancsok.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
A külső tábla mostantól látható az Azure Data Explorer webes felhasználói felületének bal oldali paneljén:
Külső tábla engedélyei
- Az adatbázis-felhasználó létrehozhat egy külső táblát. A tábla létrehozója automatikusan a tábla rendszergazdájává válik.
- A fürt, az adatbázis vagy a tábla rendszergazdája szerkesztheti a meglévő táblákat.
- Bármely adatbázis-felhasználó vagy -olvasó lekérdezhet egy külső táblát.
Külső tábla lekérdezése
Miután definiált egy külső táblát, a external_table() függvény használatával hivatkozhat rá. A lekérdezés többi része standard Kusto lekérdezésnyelv.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Külső és betöltött adatok együttes lekérdezése
A külső táblákat és a betöltött adattáblákat is lekérdezheti ugyanazon a lekérdezésen belül. A külső táblát az Azure Data Explorer, SQL-kiszolgálók vagy más forrásokból származó egyéb adatokkal is használhatja joinunion.
let( ) statement A használatával rövidített nevet rendelhet egy külső táblahivatkozáshoz.
Az alábbi példában a Termékek egy betöltött adattábla, az ArchivedProducts pedig egy korábban definiált külső tábla:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Hierarchikus adatformátumok lekérdezése
Az Azure Data Explorer lehetővé teszi a hierarchikus formátumok( például JSON, , Parquetés AvroORC) lekérdezését. Ha a hierarchikus adatsémát külső táblasémára szeretné leképezni (ha az eltér), használjon külső táblaleképezési parancsokat. Ha például a következő formátumú JSON-naplófájlokat szeretné lekérdezni:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
A külső tábladefiníció a következőképpen néz ki:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Definiáljon egy JSON-leképezést, amely az adatmezőket külső tábladefiníciós mezőkre képezi le:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
A külső tábla lekérdezésekor a rendszer meghívja a leképezést, és a kapcsolódó adatok a külső tábla oszlopaihoz lesznek leképezve:
external_table('ApiCalls') | take 10
További információ a leképezési szintaxisról: Adatleképezések.
TaxiRides külső tábla lekérdezése a súgófürtben
A súgó nevű tesztfürt használatával kipróbálhatja a különböző Azure Data Explorer képességeket. A súgófürt egy külső tábladefiníciót tartalmaz egy New York-i taxiadatkészlethez , amely több milliárd taxiúttal rendelkezik.
Külső tábla létrehozása TaxiRides
Ez a szakasz a TaxiRides külső tábla létrehozásához használt lekérdezést mutatja be a súgófürtben . Mivel ez a tábla már létrejött, kihagyhatja ezt a szakaszt, és közvetlenül a TaxiRides külső táblaadatok lekérdezéséhez léphet.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
A létrehozott TaxiRides-táblát az Azure Data Explorer webes felhasználói felületének bal oldali paneljén találja:
TaxiRides külső táblaadatok lekérdezése
Jelentkezzen be itt: https://dataexplorer.azure.com/clusters/help/databases/Samples.
TaxiRides külső tábla lekérdezése particionálás nélkül
Futtassa ezt a lekérdezést a TaxiRides külső táblán, hogy a hét minden napjára vonatkozóan megjelenítse az utazásokat a teljes adatkészletben.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Ez a lekérdezés a hét legforgalmasább napját jeleníti meg. Mivel az adatok nincsenek particionálva, a lekérdezés akár több percig is eltarthat az eredmények visszaadásához.
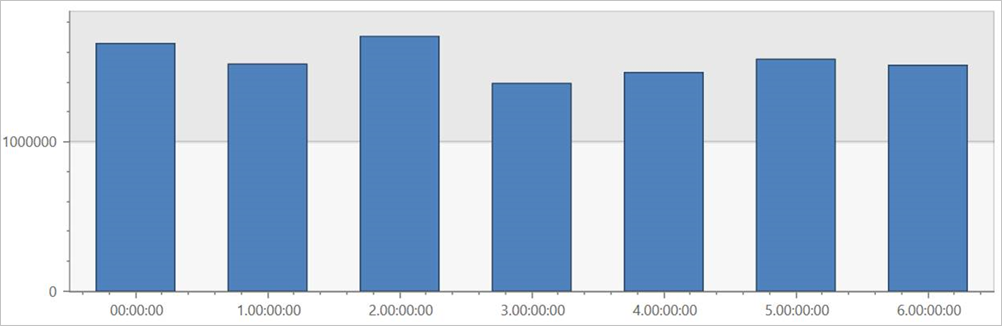
TaxiRides külső tábla lekérdezése particionálással
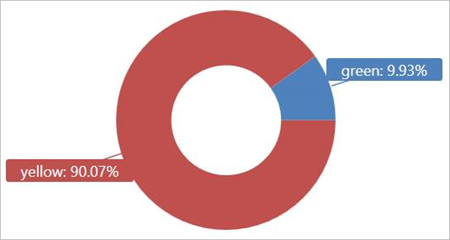
Futtassa ezt a lekérdezést a TaxiRides külső táblán a 2017 januárjában használt taxifülketípusok (sárga vagy zöld) megjelenítéséhez.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Ez a lekérdezés particionálást használ, amely optimalizálja a lekérdezési időt és a teljesítményt. A lekérdezés szűr egy particionált oszlopra (pickup_datetime), és néhány másodpercen belül visszaadja az eredményeket.
Más lekérdezéseket is írhat a TaxiRides külső táblán való futtatáshoz, és többet is megtudhat az adatokról.
A lekérdezési teljesítmény optimalizálása
Optimalizálja a lekérdezési teljesítményt a tóban az alábbi ajánlott eljárásokkal a külső adatok lekérdezéséhez.
Adatformátum
- A következő okokból használjon oszlopos formátumot az elemzési lekérdezésekhez:
- Csak a lekérdezés szempontjából releváns oszlopok olvashatók.
- Az oszlopkódolási technikák jelentősen csökkenthetik az adatméretet.
- Az Azure Data Explorer támogatja a Parquet és az ORC oszlopos formátumokat. A parquet formátum az optimalizált implementáció miatt javasolt.
Azure-régió
Ellenőrizze, hogy a külső adatok ugyanabban az Azure-régióban találhatóak-e, mint az Azure Data Explorer-fürt. Ez a beállítás csökkenti a költségeket és az adatlehívási időt.
Fájlméret
Az optimális fájlméret fájlonként több száz Mb (legfeljebb 1 GB). Kerülje a felesleges többletterhelést igénylő kis méretű fájlokat, például a lassabb fájlbesorolást és az oszlopos formátum korlátozott használatát. A fájlok számának nagyobbnak kell lennie, mint az Azure Data Explorer-fürt processzormagjainak száma.
Tömörítés
Tömörítéssel csökkentheti a távoli tárolóból lekért adatok mennyiségét. Parquet formátum esetén használja a belső Parquet tömörítési mechanizmust, amely külön tömöríti az oszlopcsoportokat, így külön olvashatja őket. A tömörítési mechanizmus használatának ellenőrzéséhez ellenőrizze, hogy a fájlok neve a következő: <filename.gz.parquet> vagy <filename.snappy.parquet>, és nem <filename.parquet.gz>.
Particionálás
Rendszerezze az adatokat "mappa" partíciókkal, amelyek lehetővé teszik, hogy a lekérdezés kihagyja az irreleváns elérési utakat. A particionálás tervezésekor vegye figyelembe a fájlméretet és a lekérdezések gyakori szűrőit, például az időbélyeget vagy a bérlőazonosítót.
Virtuális gép mérete
Válassza a több maggal és nagyobb hálózati átviteli sebességgel rendelkező virtuálisgép-termékváltozatokat (a memória kevésbé fontos). További információ: Az Azure Data Explorer-fürt megfelelő virtuálisgép-termékváltozatának kiválasztása.