Fogadók optimalizálása
Amikor az adatfolyamok a fogadókba írnak, az egyéni particionálás közvetlenül az írás előtt történik. A forráshoz hasonlóan a legtöbb esetben ajánlott az aktuális particionálás használata a kiválasztott partíciós beállításként. A particionált adatok sokkal gyorsabban írhatók, mint a nem particionált adatok, még a célhely sincs particionálva. Az alábbiakban a különböző fogadótípusokra vonatkozó egyedi szempontokat vesszük figyelembe.
Azure SQL Database-fogadók
Az Azure SQL Database esetében az alapértelmezett particionálásnak a legtöbb esetben működnie kell. Előfordulhat, hogy a fogadó túl sok partícióval rendelkezik az SQL-adatbázis kezeléséhez. Ha ezt a műveletet végzi, csökkentse az SQL Database-fogadó által kiosztott partíciók számát.
Ajánlott eljárás sorok törléséhez a fogadóban a forrás hiányzó sorai alapján
Az alábbi videó bemutatja, hogyan használhatja az adatfolyamokat a létezőkkel, a sor- és fogadóátalakítások módosításával ennek a gyakori mintának a eléréséhez:
A hibasorkezelés hatása a teljesítményre
Ha engedélyezi a hibasorok kezelését ("folytatás a hiba esetén") a fogadóátalakításban, a szolgáltatás további lépéseket tesz, mielőtt a kompatibilis sorokat a céltáblába íratja. Ez az extra lépés egy kis teljesítménybírság, amely az ehhez a lépéshez hozzáadott 5%-os tartományban lehet, és egy további kis teljesítménybeli találat is hozzáadható, ha azt a beállítást adja meg, hogy a nem kompatibilis sorokat is naplófájlba írja.
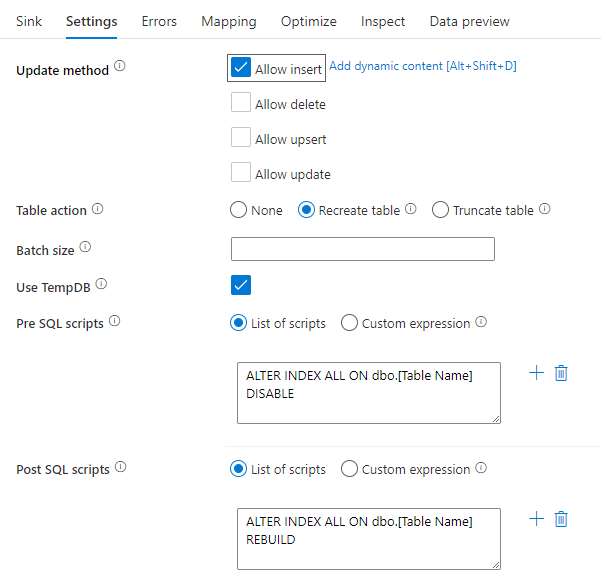
Indexek letiltása SQL-szkripttel
Az indexek letiltása egy SQL-adatbázis betöltése előtt jelentősen javíthatja a táblába való írás teljesítményét. Futtassa az alábbi parancsot, mielőtt az SQL-fogadóba írna.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Az írás befejezése után újraépítheti az indexeket az alábbi paranccsal:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Ezek natív módon is elvégezhetők az Azure SQL Database-ben vagy a Synapse-fogadóban lévő Pre- és Post-SQL-szkriptekkel az adatfolyamok leképezése során.
Figyelmeztetés
Az indexek letiltásakor az adatfolyam hatékonyan átveszi az adatbázis irányítását, és a lekérdezések jelenleg nem valószínű, hogy sikeresek lesznek. Ennek eredményeképpen az éjszaka közepén számos ETL-feladat aktiválódik az ütközés elkerülése érdekében. További információ az SQL-indexek letiltásának korlátozásairól
Az adatbázis vertikális felskálázása
Ütemezze a forrás átméretezését és az Azure SQL DB és a DW üzembe helyezését a folyamat futtatása előtt, hogy növelje az átviteli sebességet, és minimalizálja az Azure szabályozását a DTU-korlátok elérése után. A folyamat végrehajtása után átméretezheti az adatbázisokat a normál futási sebességre.
Azure Synapse Analytics-fogadók
Az Azure Synapse Analyticsbe való íráskor győződjön meg arról, hogy az előkészítés engedélyezése igaz értékre van állítva. Ez lehetővé teszi, hogy a szolgáltatás az SQL COPY paranccsal írjon, amely hatékonyan betölti az adatokat tömegesen. Az előkészítés során egy Azure Data Lake Storage gen2 vagy Azure Blob Storage-fiókra kell hivatkoznia az adatok átmeneti állapotba helyezéséhez.
Az előkészítésen kívül ugyanazok az ajánlott eljárások érvényesek az Azure Synapse Analyticsre, mint az Azure SQL Database-re.
Fájlalapú fogadók
Bár az adatfolyamok különböző fájltípusokat támogatnak, a Spark-natív parquet formátum ajánlott az optimális olvasási és írási idő érdekében.
Ha az adatok egyenletesen oszlanak el, a fájlok írásához az aktuális particionálás használata a leggyorsabb particionálási lehetőség.
Fájlnév beállításai
Fájlok írásakor többféle elnevezési lehetőség közül választhat, amelyek mindegyike hatással van a teljesítményre.
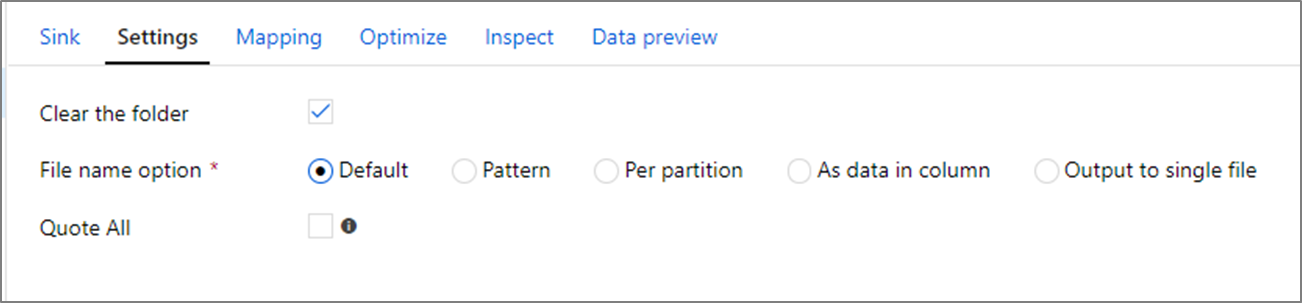
Az Alapértelmezett beállítás kiválasztása a leggyorsabb. Minden partíció megegyezik egy Spark alapértelmezett névvel rendelkező fájllal. Ez akkor hasznos, ha csak az adatmappából olvas.
Az elnevezési minta beállítása minden partíciófájlt felhasználóbarátabb névre nevez át. Ez a művelet írás után történik, és kissé lassabb, mint az alapértelmezett beállítás.
Partíciónként manuálisan nevezheti el az egyes partíciókat.
Ha egy oszlop megfelel az adatok kimenetének, oszlopadatokként kiválaszthatja a Név fájlt. Ez újrakonfigurálja az adatokat, és hatással lehet a teljesítményre, ha az oszlopok nem egyenletesen vannak elosztva.
Ha egy oszlop megfelel a mappanevek létrehozásának, válassza a Név mappát oszlopadatokként.
Az egyetlen fájl kimenete az összes adatot egyetlen partícióba egyesíti. Ez hosszú írási időt eredményez, különösen nagy adathalmazok esetén. Ez a beállítás csak akkor ajánlott, ha nincs kifejezett üzleti indok a használatára.
Azure Cosmos DB-fogadók
Amikor az Azure Cosmos DB-be ír, az adatfolyam-végrehajtás során az átviteli sebesség és a kötegméret módosítása javíthatja a teljesítményt. Ezek a módosítások csak az adatfolyam-tevékenység futtatása során lépnek érvénybe, és a befejezés után visszatérnek az eredeti gyűjteménybeállításokhoz.
Kötegméret: Általában az alapértelmezett kötegmérettől kezdve elegendő. Az érték további finomhangolásához számítsa ki az adatok durva objektumméretét, és győződjön meg arról, hogy az objektum mérete * kötegméret kisebb, mint 2 MB. Ha igen, növelheti a köteg méretét a jobb átviteli sebesség érdekében.
Átviteli sebesség: Itt adjon meg egy magasabb átviteli sebességet, hogy a dokumentumok gyorsabban írjanak az Azure Cosmos DB-be. Tartsa szem előtt a magasabb RU-költségeket a magas átviteli sebesség beállítása alapján.
Írási átviteli sebesség költségvetése: Olyan értéket használjon, amely kisebb, mint a percenkénti összes kérelemegység. Ha nagy számú Spark-partíciót tartalmazó adatfolyammal rendelkezik, a költségvetés átviteli sebességének beállítása nagyobb egyensúlyt tesz lehetővé ezen partíciók között.
Kapcsolódó tartalom
- Adatfolyamok teljesítményének áttekintése
- Források optimalizálása
- Átalakítások optimalizálása
- Adatfolyamok használata folyamatokban
További Adatfolyam teljesítményre vonatkozó cikkek: