Az adatfolyamok teljesítményének és finomhangolási útmutatónak a leképezése
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Az adatfolyamok leképezése az Azure Data Factoryben és a Synapse-folyamatokban egy kódolást nem igénylő felületet biztosít nagy volumenű adatátalakítások tervezéséhez és futtatásához. Ha nem jártas adatfolyamok leképezésében, tekintse meg az adatfolyam-leképezés áttekintését. Ez a cikk az adatfolyamok finomhangolásának és optimalizálásának különböző módjait ismerteti, hogy azok megfeleljenek a teljesítménymutatóknak.
Tekintse meg az alábbi videót, amely bemutatja, hogy milyen mintaidőzítések alakítják át az adatokat adatfolyamokkal.
Adatfolyam teljesítményének monitorozása
Miután hibakeresési módban ellenőrizte az átalakítási logikát, futtassa az adatfolyamot teljes körű tevékenységként egy folyamatban. Az adatfolyamok üzembe helyezése folyamatban történik az adatfolyam-tevékenység végrehajtásával. Az adatfolyam-tevékenység egyedi monitorozási élményt nyújt más tevékenységekhez képest, amelyek az átalakítási logika részletes végrehajtási tervét és teljesítményprofilját jelenítik meg. Az adatfolyam részletes monitorozási információinak megtekintéséhez válassza a szemüveg ikont egy folyamat tevékenységfuttatási kimenetében. További információt a leképezési adatfolyamok monitorozása című témakörben talál.

Az adatfolyamok teljesítményének monitorozása során négy lehetséges szűk keresztmetszetet kell figyelembe vennie:
- Fürt indítási ideje
- Olvasás forrásból
- Átalakítási idő
- Írás fogadóba
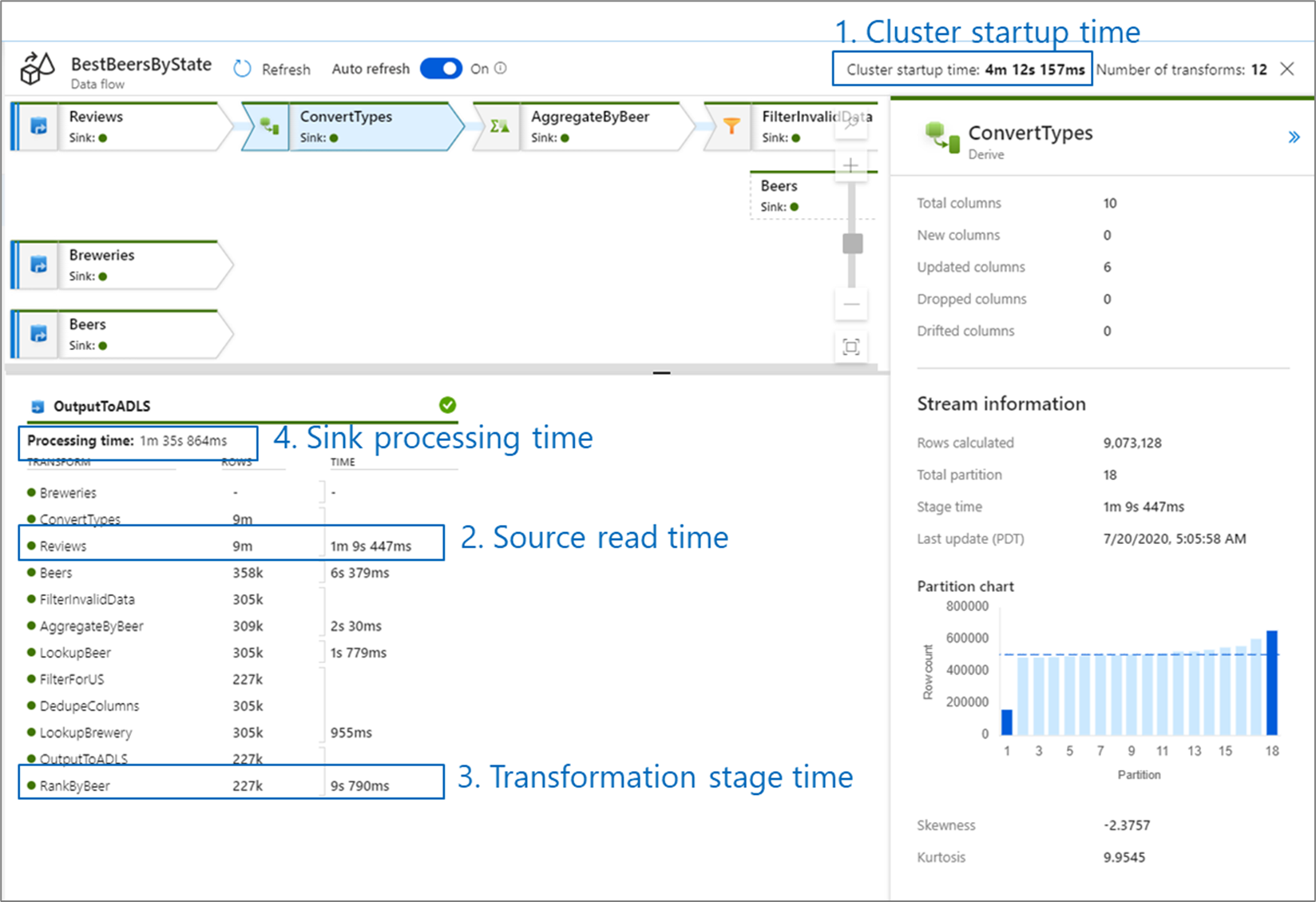
A fürt indítási ideje az Apache Spark-fürtök üzembe helyezése. Ez az érték a monitorozási képernyő jobb felső sarkában található. Az adatfolyamok egy igény szerinti modellen futnak, ahol minden feladat elkülönített fürtöt használ. Ez az indítási idő általában 3-5 percet vesz igénybe. A szekvenciális feladatok esetében az indítási idő csökkenthető az idő élettartamának engedélyezésével. További információkért tekintse meg az Integrációs modul teljesítményéről az Élettartam című szakaszt.
Az adatfolyamok egy Spark-optimalizálót használnak, amely "fázisokban" átrendezi és futtatja az üzleti logikát, hogy a lehető leggyorsabban teljesítsen. Minden egyes fogadó esetében, amelybe az adatfolyam ír, a monitorozási kimenet felsorolja az egyes átalakítási fázisok időtartamát, valamint az adatok fogadóba való írásához szükséges időt. A legnagyobb idő valószínűleg az adatfolyam szűk keresztmetszete. Ha a legnagyobb átalakítási fázis tartalmaz egy forrást, érdemes lehet áttekinteni az olvasási idő további optimalizálását. Ha egy átalakítás hosszú időt vesz igénybe, előfordulhat, hogy újraparticionálásra vagy az integrációs modul méretének növelésére van szükség. Ha a fogadó feldolgozási ideje nagy, előfordulhat, hogy fel kell skáláznia az adatbázist, vagy ellenőriznie kell, hogy nem egyetlen fájlra ad-e ki kimenetet.
Miután azonosította az adatfolyam szűk keresztmetszetét, használja az alábbi optimalizálási stratégiákat a teljesítmény javítása érdekében.
Adatfolyam-logika tesztelése
A felhasználói felületről származó adatfolyamok tervezésekor és tesztelésekor a hibakeresési mód lehetővé teszi az élő Spark-fürt interaktív tesztelését, amely lehetővé teszi az adatok előnézetének megtekintését és az adatfolyamok végrehajtását anélkül, hogy a fürt bemelegedésére vár. További információ: Hibakeresési mód.
Optimalizálás lap
Az Optimalizálás lap beállításokat tartalmaz a Spark-fürt particionálási sémájának konfigurálásához. Ez a lap az adatfolyam minden átalakításában megtalálható, és megadja, hogy az átalakítás befejezése után szeretné-e újraparticionálásra használni az adatokat. A particionálás módosítása lehetővé teszi az adatok számítási csomópontok közötti elosztásának és az adatlokalizáció optimalizálásának szabályozását, amelyek pozitív és negatív hatással lehetnek a teljes adatfolyam teljesítményére.
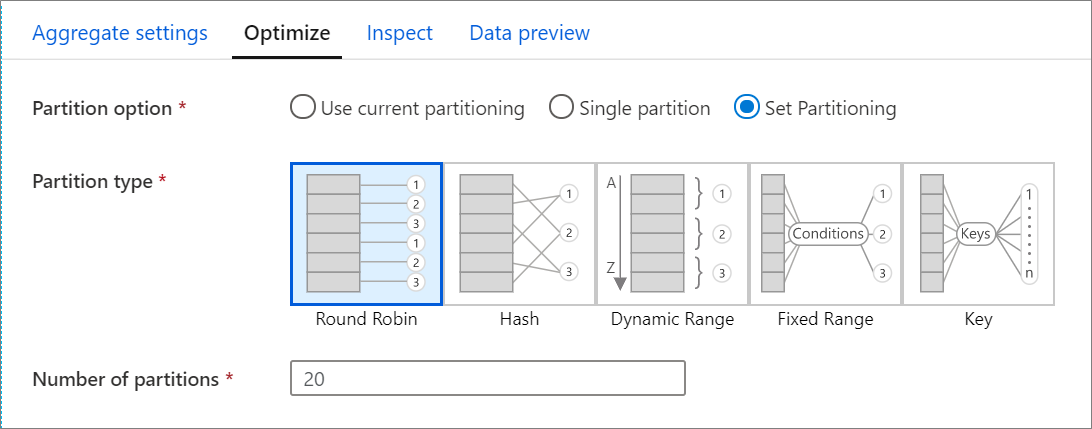
Alapértelmezés szerint az aktuális particionálás használata van kiválasztva, amely arra utasítja a szolgáltatást, hogy tartsa meg az átalakítás aktuális kimeneti particionálását. Mivel az adatok újraparticionálása időt vesz igénybe, a legtöbb forgatókönyvben az aktuális particionálás használata ajánlott. Az olyan forgatókönyvek, amelyekben az adatok újraparticionálására lehet szükség, olyan összesítéseket és illesztéseket tartalmaznak, amelyek jelentősen eltúlozza az adatokat, vagy amikor forrásparticionálást használ egy SQL-adatbázison.
Ha bármilyen átalakításon módosítani szeretné a particionálást, válassza az Optimalizálás lapot, és válassza a Particionálás beállítása választógombot. A particionálás számos lehetőséggel rendelkezik. A particionálás legjobb módja az adatkötetek, a jelölt kulcsok, a null értékek és a számosság alapján különbözik.
Fontos
Az egyetlen partíció az összes elosztott adatot egyetlen partícióba egyesíti. Ez egy nagyon lassú művelet, amely az összes alsóbb rétegbeli átalakítást és írást is jelentősen befolyásolja. Ez a lehetőség erősen elriasztja, hacsak nincs kifejezett üzleti oka annak használatára.
A következő particionálási lehetőségek minden átalakításban elérhetők:
Kerek időszeletelés
A ciklikus időszeletelés egyenlően osztja el az adatokat a partíciók között. Használjon ciklikus időszeletelést, ha nincsenek jó kulcsjelöltjei egy szilárd, intelligens particionálási stratégia implementálásához. Beállíthatja a fizikai partíciók számát.
Kivonat
A szolgáltatás az oszlopok kivonatát hozza létre egységes partíciók létrehozásához, így a hasonló értékeket tartalmazó sorok ugyanabba a partícióba esnek. Ha a Kivonat lehetőséget használja, tesztelje a lehetséges partícióeltéréseket. Beállíthatja a fizikai partíciók számát.
Dinamikus tartomány
A dinamikus tartomány a Spark dinamikus tartományait használja a megadott oszlopok vagy kifejezések alapján. Beállíthatja a fizikai partíciók számát.
Rögzített tartomány
Hozzon létre egy kifejezést, amely rögzített tartományt biztosít a particionált adatoszlopok értékeihez. A partíciók eltérésének elkerülése érdekében ennek a beállításnak a használata előtt ismernie kell az adatokat. A kifejezéshez megadott értékek egy partíciófüggvény részeként lesznek használva. Beállíthatja a fizikai partíciók számát.
Kulcs
Ha jól ismeri az adatok számosságát, a kulcsparticionálás jó stratégia lehet. A kulcsparticionálás partíciókat hoz létre az oszlop minden egyedi értékéhez. A partíciók száma nem állítható be, mert a szám az adatok egyedi értékein alapul.
Tipp.
A particionálási séma manuális beállítása átrendezi az adatokat, és ellensúlyozhatja a Spark-optimalizáló előnyeit. Ajánlott eljárás a particionálás manuális beállítása, kivéve, ha szükséges.
Naplózási szint
Ha nem követeli meg az adatfolyam-tevékenységek minden folyamatvégrehajtását az összes részletes telemetriai napló teljes naplózásához, a naplózási szintet igény szerint "Alapszintű" vagy "Nincs" értékre állíthatja. Amikor az adatfolyamokat "Részletes" módban (alapértelmezett) hajtja végre, az adatátalakítás során minden egyes partíciószinten teljes körű naplózási tevékenységet kér a szolgáltatástól. Ez költséges művelet lehet, ezért csak a részletes hibaelhárítás engedélyezése javíthatja a teljes adatfolyamot és a folyamat teljesítményét. Az "Alapszintű" mód csak az átalakítási időtartamokat naplózza, míg a "Nincs" csak az időtartamok összegzését adja meg.

Kapcsolódó tartalom
- Források optimalizálása
- Fogadók optimalizálása
- Átalakítások optimalizálása
- Adatfolyamok használata folyamatokban
További Adatfolyam teljesítményre vonatkozó cikkek:
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: