Fürtök konfigurálása
Feljegyzés
Ezek az örökölt fürt felhasználói felületére vonatkozó utasítások, és csak az előzmény pontosságát tartalmazzák. Minden ügyfélnek a frissített létrehozási fürt felhasználói felületét kell használnia.
Ez a cikk az Azure Databricks-fürtök létrehozásakor és szerkesztésekor elérhető konfigurációs beállításokat ismerteti. A felhasználói felület használatával fürtök létrehozására és szerkesztésére összpontosít. További módszerekért tekintse meg a Databricks CLI-t, a Clusters API-t és a Databricks Terraform-szolgáltatót.
Ha szeretné eldönteni, hogy a konfigurációs beállítások melyik kombinációja felel meg a legjobban az igényeinek, tekintse meg a fürtkonfiguráció ajánlott eljárásait.
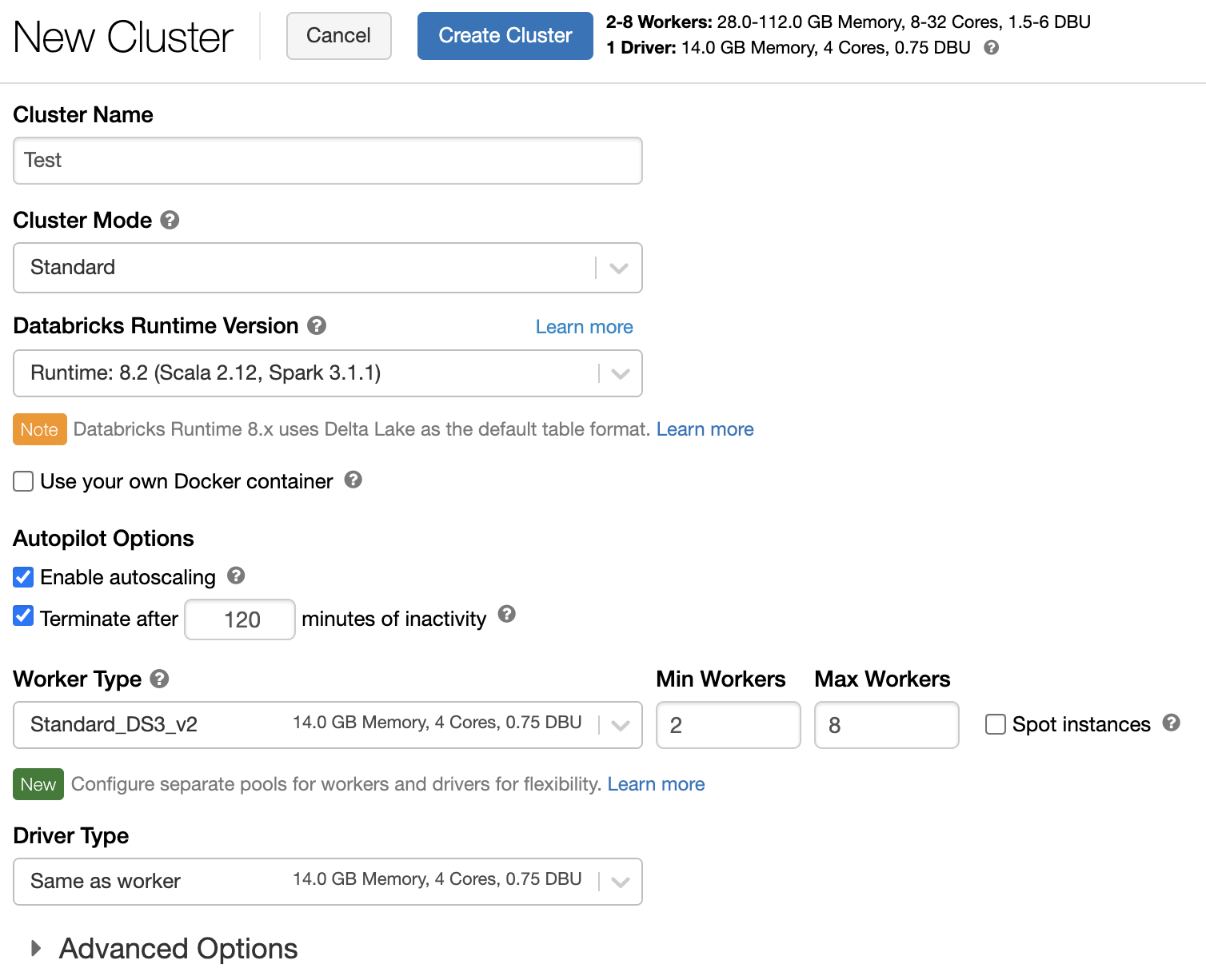
Fürtszabályzat
A fürtszabályzatok korlátozottan konfigurálják a fürtöket szabályok alapján. A szabályzatszabályok korlátozzák a fürtlétrehozáshoz elérhető attribútumokat vagy attribútumértékeket. A fürtszabályzatok olyan ACL-ekkel rendelkeznek, amelyek bizonyos felhasználókra és csoportokra korlátozzák azok használatát, és így korlátozzák, hogy mely szabályzatokat választhatja ki a fürt létrehozásakor.
Fürtszabályzat konfigurálásához válassza ki a fürtszabályzatot a Szabályzat legördülő listában.
Feljegyzés
Ha nem hoztak létre házirendeket a munkaterületen, a Szabályzat legördülő lista nem jelenik meg.
Ha az alábbiakat szeretné:
- A fürt létrehozási engedélyével kiválaszthatja a Korlátlan szabályzatot, és teljes mértékben konfigurálható fürtöket hozhat létre. A korlátlan házirend nem korlátozza a fürtattribútumokat vagy attribútumértékeket.
- A fürt létrehozhat engedélyeket és hozzáférést a fürtházirendekhez, kiválaszthatja a Korlátozás nélküli szabályzatot és azokat a szabályzatokat, amelyekhez hozzáféréssel rendelkezik.
- Csak a fürtszabályzatokhoz való hozzáféréssel kiválaszthatja azokat a szabályzatokat, amelyekhez hozzáféréssel rendelkezik.
Fürtmód
Feljegyzés
Ez a cikk az örökölt fürtök felhasználói felületét ismerteti. Az új fürtök felhasználói felületéről (előzetes verzióban) további információt a számítási konfigurációs referencia című témakörben talál. Ez magában foglal néhány terminológiai módosítást a fürtelérési típusok és módok esetében. Az új és régi fürttípusok összehasonlításához tekintse meg a fürtök felhasználói felületének változásait és a fürtelérési módokat. Az előzetes verzió felhasználói felületén:
- A standard módú fürtöket mostantól nincs elkülönítési megosztott hozzáférési módú fürtnek nevezzük.
- A táblák ACL-jeivel való magas egyidejűség mostantól megosztott hozzáférési módú fürtöknek nevezik.
Az Azure Databricks három fürtmódot támogat: Standard, High Concurrency és Single Node. Az alapértelmezett fürtmód a Standard.
Fontos
- Ha a munkaterület egy Unity Catalog-metaadattárhoz van rendelve, a magas egyidejűségi fürtök nem érhetők el. Ehelyett hozzáférési módot használ a hozzáférés-vezérlés integritásának biztosításához és az erős elkülönítési garanciák érvényesítéséhez. Lásd még az Access módokat.
- A fürt létrehozása után a fürt üzemmódja nem módosítható. Ha másik fürtmódot szeretne, létre kell hoznia egy új fürtöt.
A fürtkonfiguráció tartalmaz egy automatikus leállási beállítást, amelynek alapértelmezett értéke a fürt üzemmódjától függ:
- A standard és az egycsomópontos fürtök alapértelmezés szerint 120 perc után automatikusan leállnak.
- A magas egyidejűségi fürtök alapértelmezés szerint nem fejeződnek be automatikusan.
Standard fürtök
Figyelmeztetés
A standard módú fürtöket (más néven nincs elkülönítési megosztott fürtöket) több felhasználó is megoszthatja, a felhasználók közötti elkülönítés nélkül. Ha a magas egyidejűségi fürtmódot további biztonsági beállítások, például tábla ACL-ek vagy hitelesítő adatok átengedése nélkül használja, a standard módú fürtök ugyanazokat a beállításokat használják. A fiókadminisztrátorokkal megakadályozhatják , hogy a databricks-munkaterület rendszergazdái automatikusan generálják a belső hitelesítő adatokat az ilyen típusú fürtökön. A biztonságosabb beállítások érdekében a Databricks olyan alternatív megoldásokat javasol, mint például a tábla ACL-ekkel rendelkező nagy egyidejűségi fürtök.
Standard fürtök használata csak önálló felhasználók számára ajánlott. A standard fürtök Pythonban, SQL-ben, R-ben és Scalában fejlesztett számítási feladatokat futtathatnak.
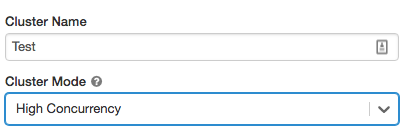
Magas egyidejűségi fürtök
A magas egyidejűségi fürt egy felügyelt felhőerőforrás. A high concurrency fürtök fő előnye, hogy részletes megosztást biztosítanak a maximális erőforrás-kihasználtsághoz és a lekérdezések minimális késéséhez.
A magas egyidejűségi fürtök SQL, Python és R nyelven fejlesztett számítási feladatokat futtathatnak. A magas egyidejűségi fürtök teljesítményét és biztonságát a felhasználói kód külön folyamatokban való futtatásával biztosítják, ami a Scalában nem lehetséges.
Emellett csak a magas egyidejűségi fürtök támogatják a táblahozzáférés-vezérlést.
Magas egyidejűségi fürt létrehozásához állítsa a fürt üzemmódotmagas egyidejűségre.
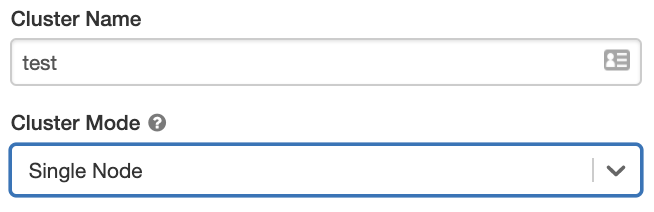
Egycsomópontos fürtök
Egyetlen csomópontfürt nem rendelkezik feldolgozóval, és Spark-feladatokat futtat az illesztőcsomóponton.
Ezzel szemben a Standard fürtökhöz az illesztőcsomópont mellett legalább egy Spark-feldolgozó csomópont szükséges a Spark-feladatok végrehajtásához.
Egycsomópontos fürt létrehozásához állítsa a fürtmódot egyetlen csomópontra.
Az egycsomópontos fürtök használatával kapcsolatos további információkért lásd az egycsomópontos vagy többcsomópontos számítást.
Medencék
A fürt kezdési idejének csökkentése érdekében csatolhat egy fürtöt egy előre definiált üresjárati példánykészlethez az illesztőprogram és a feldolgozó csomópontok számára. A fürt a készletek példányainak használatával jön létre. Ha egy készlet nem rendelkezik elegendő tétlen erőforrással a kért illesztőprogram- vagy feldolgozó csomópontok létrehozásához, a készlet úgy bővül, hogy új példányokat ad ki a példányszolgáltatótól. Ha egy csatolt fürt leáll, a használt példányok visszakerülnek a készletekbe, és egy másik fürt újra felhasználhatja.
Ha a feldolgozó csomópontok készletét választja ki, de az illesztőprogram-csomóponthoz nem, az illesztőprogram-csomópont örökli a készletet a feldolgozó csomópont konfigurációjából.
Fontos
Ha egy készletet próbál kijelölni az illesztőprogram-csomóponthoz, de a feldolgozó csomópontokhoz nem, hiba történik, és a fürt nem jön létre. Ez a követelmény megakadályozza azt a helyzetet, amikor az illesztőprogram-csomópontnak várnia kell a feldolgozó csomópontok létrehozására, vagy fordítva.
A készletek Azure Databricksben való használatával kapcsolatos további információkért tekintse meg a készletkonfigurációra vonatkozó hivatkozást .
Databricks Runtime
A Databricks-futtatókörnyezetek a fürtökön futó alapvető összetevők. Minden Databricks-futtatókörnyezet tartalmazza az Apache Sparkot, és olyan összetevőket és frissítéseket ad hozzá, amelyek javítják a használhatóságot, a teljesítményt és a biztonságot. További részletekért lásd a Databricks Runtime kibocsátási megjegyzéseinek verzióit és kompatibilitását.
Az Azure Databricks többféle futtatókörnyezetet és több futtatókörnyezettípust is kínál a Databricks Futtatókörnyezet verziója legördülő menüben, amikor létrehoz vagy szerkeszt egy fürtöt.
Fotongyorsítás
A Photon a Databricks Runtime 9.1 LTS-t és újabb verziót futtató fürtökhöz érhető el.
A fotongyorsítás engedélyezéséhez jelölje be a Foton-gyorsítás használata jelölőnégyzetet.
Szükség esetén megadhatja a példánytípust a Feldolgozó típusa és az Illesztőprogram típusa legördülő listában.
A Databricks az alábbi példánytípusokat javasolja az optimális ár és teljesítmény érdekében:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
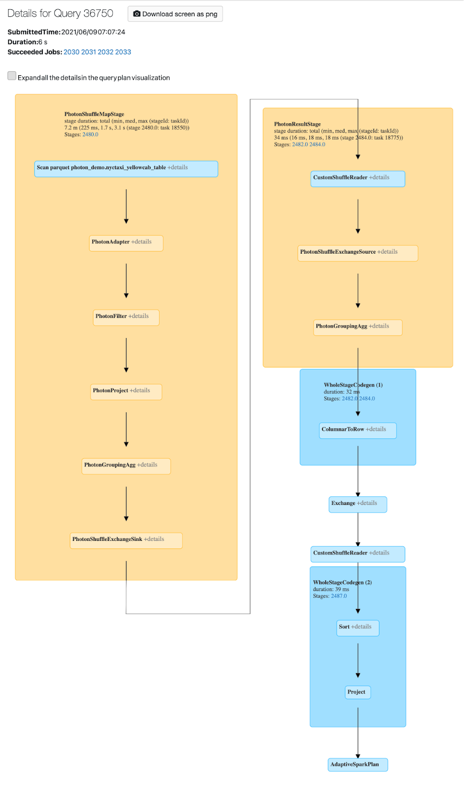
A Photon-tevékenységet a Spark felhasználói felületén tekintheti meg. Az alábbi képernyőképen a lekérdezés részleteinek DAG-jának megjelenítése látható. A FOTON két jelzést mutat a DAG-ban. Először is a Photon operátorok a "Photon" betűvel kezdődnek, PhotonGroupingAggpéldául. Másodszor, a DAG-ban a foton operátorok és a szakaszok őszibarack színűek, míg a nem fotonok kékek.
Docker-képek
Egyes Databricks Runtime-verziókhoz megadhat egy Docker-lemezképet fürt létrehozásakor. Ilyenek például a tár testreszabása, az arany tárolókörnyezet, amely nem változik, és a Docker CI/CD-integrációja.
Docker-rendszerképekkel egyéni mélytanulási környezeteket is létrehozhat GPU-eszközökkel rendelkező fürtökön.
Útmutatásért tekintse meg a Tárolók testreszabása a Databricks Container Service-lel és a Databricks Container Services szolgáltatással GPU-számítással című témakört.
Fürtcsomópont típusa
A fürtök egy illesztőcsomópontból és nulla vagy több feldolgozó csomópontból állnak.
Az illesztőprogram- és feldolgozócsomópontokhoz külön felhőszolgáltatói példánytípusokat választhat, de alapértelmezés szerint az illesztőprogram-csomópont ugyanazt a példánytípust használja, mint a feldolgozó csomópont. A példánytípusok különböző családjai különböző használati eseteket, például memóriaigényes vagy számítási igényű számítási feladatokat illesztenek be.
Feljegyzés
Ha a biztonsági követelmények közé tartozik a számítási elkülönítés, válasszon egy Standard_F72s_V2 példányt feldolgozótípusként. Ezek a példánytípusok azokat az izolált virtuális gépeket jelölik, amelyek a teljes fizikai gazdagépet felhasználják, és biztosítják a szükséges elkülönítési szintet, amely például az EGYESÜLT Államok Védelmi Minisztériumának 5. (IL5) szintű számítási feladatainak támogatásához szükséges.
Illesztőprogram-csomópont
Az illesztőcsomópont őrzi meg a fürthöz csatolt minden jegyzetfüzet állapotinformációját. Az illesztőcsomópont a SparkContext tartalmát is megőrzi, illetve értelmezi a fürtön lévő jegyzetfüzetekből vagy kódtárakból futtatott parancsokat, és futtatja a Spark-végrehajtókkal együttműködő Apache Spark-főkiszolgálót.
Az illesztőcsomópont típusának alapértelmezett értéke megegyezik a munkavégző csomópont típusáéval. Nagyobb, több memóriával rendelkező illesztőprogram-csomóponttípust is választhat, ha a Spark-feldolgozóktól származó adatok nagy részét tervezi elemezni collect() a jegyzetfüzetben.
Tipp.
Mivel az illesztőprogram-csomópont megőrzi a csatolt jegyzetfüzetek összes állapotinformációját, mindenképpen válassza le a nem használt jegyzetfüzeteket az illesztőprogram-csomópontról.
Munkavégző csomópont
Az Azure Databricks munkavégző csomópontjai futtatják a Spark-végrehajtókat és a fürtök megfelelő működéséhez szükséges egyéb szolgáltatásokat. Ha a Sparkkal osztja el a számítási feladatokat, az elosztott feldolgozás teljes egészében a munkavégző csomópontokon történik. Az Azure Databricks feldolgozó csomópontonként egy végrehajtót futtat; ezért a végrehajtó és a feldolgozó kifejezések felcserélhetők az Azure Databricks-architektúra kontextusában.
Tipp.
Spark-feladat futtatásához legalább egy munkavégző csomópontra van szükség. Ha egy fürtben a feldolgozók száma nulla, az illesztőcsomóponton futtathat nem Spark-parancsokat, a Spark-parancsok azonban sikertelenek lesznek.
GPU-példánytípusok
A nagy teljesítményt igénylő számítási feladatokhoz, például a mély tanuláshoz kapcsolódó feladatok esetében az Azure Databricks támogatja a grafikus feldolgozási egységekkel (GPU-kkal) felgyorsított fürtöket. További információ: GPU-kompatibilis számítás.
Kihasználatlan példányok
A költségmegtakarítás érdekében a Kihasználatlan példányok jelölőnégyzet bejelölésével dönthet úgy, hogy kihasználatlan példányokat( más néven Azure Spot virtuális gépeket) használ.

Az első példány mindig igény szerinti lesz (az illesztőprogram-csomópont mindig igény szerint működik), a későbbi példányok pedig kihasználatlan példányok lesznek. Ha a kihasználatlanság miatt a kihasználatlanság miatt a kihasználatlan példányok kiürítése történik, a rendszer igény szerinti példányokat helyez üzembe a kiürített példányok helyére.
Fürtméret és automatikus skálázás
Azure Databricks-fürt létrehozásakor megadhat egy rögzített számú feldolgozót a fürthöz, vagy megadhat egy minimális és maximális számú feldolgozót a fürt számára.
Rögzített méretű fürt megadásakor az Azure Databricks biztosítja, hogy a fürt a megadott számú feldolgozóval rendelkezik. Ha megadja a dolgozók számának tartományát, a Databricks kiválasztja a feladat futtatásához szükséges feldolgozók számát. Ezt automatikus skálázásnak nevezzük.
Az automatikus skálázással az Azure Databricks dinamikusan újratelepíti a dolgozókat, hogy figyelembe vegyék a feladat jellemzőit. Előfordulhat, hogy a folyamat bizonyos részei számításilag nagyobb terhelést igényelnek, mint mások, és a Databricks automatikusan további feldolgozókat ad hozzá a feladat ezen fázisai során (és eltávolítja őket, ha már nincs rájuk szükség).
Az automatikus skálázás segítségével könnyebben érhet el magas fürtkihasználtságot, mert nem kell kiépítenie a fürtöt, hogy megfeleljen a számítási feladatnak. Ez különösen azokra a számítási feladatokra vonatkozik, amelyek követelményei idővel változnak (például egy adathalmaz felfedezése egy nap során), de olyan egyszeri, rövidebb számítási feladatokra is alkalmazható, amelyek kiépítési követelményei ismeretlenek. Az automatikus skálázás így két előnyt kínál:
- A számítási feladatok gyorsabban futhatnak, mint egy állandó méretű, nem kiépített fürt.
- Az automatikus skálázási fürtök a statikus méretű fürtökhöz képest csökkenthetik az általános költségeket.
A fürt és a számítási feladat állandó méretétől függően az automatikus skálázás egyszerre nyújt egy vagy mindkét előnyt. A fürt mérete alacsonyabb lehet a felhőszolgáltató példányainak leállásakor kiválasztott minimális számú feldolgozónál. Ebben az esetben az Azure Databricks folyamatosan újrapróbálkozza a példányok újbóli kiépítését a minimális feldolgozószám fenntartása érdekében.
Feljegyzés
Az automatikus skálázás nem érhető el spark-submit feladatokhoz.
Az automatikus skálázás viselkedése
- 2 lépésben felskálázható a minimálistól a maximumig.
- Leskálázható még akkor is, ha a fürt nem tétlen, ha az shuffle fájl állapotát vizsgálja.
- Az aktuális csomópontok százalékos aránya alapján lefelé skálázható.
- Feladatfürtökön leskálázható, ha a fürt kihasználatlan az elmúlt 40 másodpercben.
- Minden célú fürtön leskálázható, ha a fürt kihasználatlan az elmúlt 150 másodpercben.
- A
spark.databricks.aggressiveWindowDownSSpark konfigurációs tulajdonsága másodpercek alatt megadja, hogy egy fürt milyen gyakran hoz leskálázási döntéseket. Az érték növelésével a fürtök lassabban skálázhatók le. A maximális érték 600.
Automatikus skálázás engedélyezése és konfigurálása
Ahhoz, hogy az Azure Databricks automatikusan átméretezhesse a fürtöt, engedélyezheti a fürt automatikus skálázását, és megadja a minimális és maximális feldolgozói tartományt.
Engedélyezze az automatikus skálázást.
Minden célú fürt – A Fürt létrehozása lapon jelölje be az Automatikus skálázás engedélyezése jelölőnégyzetet az Autopilot beállításai párbeszédpanelen:

Feladatfürt – A Fürt konfigurálása lapon jelölje be az Automatikus skálázás engedélyezése jelölőnégyzetet az Autopilot beállításai párbeszédpanelen:

Konfigurálja a minimális és a maximális feldolgozót.

Amikor a fürt fut, a fürt részletes lapja megjeleníti a lefoglalt feldolgozók számát. Összehasonlíthatja a kiosztott feldolgozók számát a feldolgozó konfigurációjával, és szükség szerint módosíthatja azokat.
Fontos
Példánykészlet használata esetén:
- Győződjön meg arról, hogy a kért fürtméret kisebb vagy egyenlő a készletben lévő üresjárati példányok minimális számával. Ha a fürtméret ennél nagyobb, a fürt indítási ideje ugyanakkora lesz, mint a készletet nem használó fürtöké.
- Győződjön meg arról, hogy a fürt maximális mérete kisebb vagy egyenlő a készlet maximális kapacitásával . Ha a fürtméret ennél nagyobb, a fürt létrehozása sikertelen lesz.
Automatikus skálázási példa
Ha újrakonfigurál egy statikus fürtöt automatikus skálázási fürtként, az Azure Databricks azonnal átméretezi a fürtöt a minimális és maximális korláton belül, majd megkezdi az automatikus skálázást. Az alábbi táblázat például azt mutatja be, hogy mi történik egy bizonyos kezdeti méretű fürttel, ha újrakonfigurál egy fürtöt 5 és 10 csomópont közötti automatikus skálázásra.
| Kezdeti méret | Újrakonfigurálás utáni méret |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Helyi tároló automatikus skálázása
Gyakran nehéz megbecsülni, hogy egy adott feladat mennyi lemezterületet fog igénybe venni. Az Azure Databricks automatikusan engedélyezi a helyi tároló automatikus skálázását az összes Azure Databricks-fürtön, hogy ne kelljen megbecsülnie, hogy hány gigabájtnyi felügyelt lemezt csatoljon a fürthöz a létrehozáskor.
A helyi tároló automatikus skálázásával az Azure Databricks figyeli a fürt Spark-feldolgozóiban rendelkezésre álló szabad lemezterület mennyiségét. Ha egy feldolgozó túl alacsonyan kezd futni a lemezen, a Databricks automatikusan csatol egy új felügyelt lemezt a feldolgozóhoz, mielőtt elfogyna a lemezterület. A lemezek legfeljebb 5 TB lemezterületet csatolnak virtuális gépenként (beleértve a virtuális gép kezdeti helyi tárolóját is).
A virtuális géphez csatlakoztatott felügyelt lemezek csak akkor lesznek leválasztva, ha a virtuális gép visszakerül az Azure-ba. Ez azt jelzi, hogy a felügyelt lemezek soha nem lesznek leválasztva a virtuális gépekről, amíg egy futó fürt része. A felügyelt lemezek használatának leskálázásához az Azure Databricks azt javasolja, hogy ezt a funkciót egy fürtmérettel és automatikus skálázással vagy váratlan leállítással konfigurált fürtben használja.
Helyi lemeztitkosítás
Fontos
Ez a funkció a nyilvános előzetes verzióban érhető el.
A fürtök futtatásához használt példánytípusok némelyike helyileg csatlakoztatott lemezekkel rendelkezhet. Az Azure Databricks ezeket a helyileg csatlakoztatott lemezeken tárolhatja a shuffle adatokat vagy rövid élettartamú adatokat. Annak érdekében, hogy minden inaktív adat titkosítva legyen minden tárolási típushoz, beleértve az ideiglenesen a fürt helyi lemezén tárolt shuffle-adatokat is, engedélyezheti a helyi lemeztitkosítást.
Fontos
A számítási feladatok lassabban futhatnak, mert a titkosított adatok olvasása és írása a helyi kötetekbe és onnan.
Ha engedélyezve van a helyi lemeztitkosítás, az Azure Databricks helyileg létrehoz egy, az egyes fürtcsomópontokra egyedi titkosítási kulcsot, amely a helyi lemezeken tárolt összes adat titkosítására szolgál. A kulcs hatóköre minden fürtcsomóponton helyi, és a fürtcsomóponttal együtt megsemmisül. A kulcs az élettartama során a memóriában található a titkosításhoz és a visszafejtéshez, és titkosítva tárolja a lemezen.
A helyi lemeztitkosítás engedélyezéséhez a Clusters API-t kell használnia. Fürt létrehozása vagy szerkesztése során állítsa be a következőt:
{
"enable_local_disk_encryption": true
}
Tekintse meg a Clusters API-t , hogy miként hívhatja meg ezeket az API-kat.
Íme egy példa egy fürt létrehozási hívására, amely lehetővé teszi a helyi lemeztitkosítást:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Biztonsági mód
Ha a munkaterület egy Unity Catalog-metaadattárhoz van rendelve, a magas egyidejűségi fürtmód helyett biztonsági módot használ a hozzáférés-vezérlés integritásának biztosítása és az erős elkülönítési garanciák érvényesítése érdekében. A Magas egyidejűségi fürtmód nem érhető el a Unity Katalógusban.
A Speciális beállítások területen válasszon a következő fürtbiztonsági módok közül:
- Nincs: Nincs elkülönítés. Nem kényszeríti ki a munkaterület-helyi tábla hozzáférés-vezérlését vagy hitelesítő adatainak átadását. A Unity-katalógus adatai nem érhetők el.
- Egyetlen felhasználó: Csak egyetlen felhasználó használhatja (alapértelmezés szerint a fürtöt létrehozó felhasználó). Más felhasználók nem csatolhatók a fürthöz. Ha egy fürt nézetét egyfelhasználós biztonsági módban éri el, a rendszer a felhasználó engedélyeivel hajtja végre a nézetet. Az egyfelhasználós fürtök python, Scala és R használatával támogatják a számítási feladatokat. Az init-szkriptek, a kódtár telepítése és a DBFS-csatlakoztatások támogatottak az egyfelhasználós fürtökön. Az automatizált feladatoknak egyfelhasználós fürtöket kell használniuk.
- Felhasználóelkülönítés: Több felhasználó is megosztható. Csak AZ SQL-számítási feladatok támogatottak. A kódtár telepítése, az init szkriptek és a DBFS-csatlakoztatások le vannak tiltva, hogy szigorú elkülönítést kényszerítsen ki a fürtfelhasználók között.
- Csak tábla ACL (örökölt): A munkaterület-helyi tábla hozzáférés-vezérlését kényszeríti ki, de nem fér hozzá a Unity Catalog adataihoz.
- Csak átengedés (örökölt):: A munkaterület-helyi hitelesítő adatok átengedése kényszeríti, de nem fér hozzá a Unity Catalog adataihoz.
A Unity Catalog számítási feladatainak egyetlen biztonsági módja az egyfelhasználós és a felhasználóelkülönítés.
További információt az Access módokat ismertető cikkben talál.
Spark-konfiguráció
A Spark-feladatok finomhangolásához egyéni Spark-konfigurációs tulajdonságokat adhat meg egy fürtkonfigurációban.
A fürtkonfigurációs lapon kattintson a Speciális beállítások váltógombra.
Kattintson a Spark fülre.
A Spark-konfigurációban soronként egy kulcs-érték párként adja meg a konfigurációs tulajdonságokat.
Amikor fürtöt konfigurál a Fürt API használatával, állítsa be a Spark-tulajdonságokat az spark_conf Új fürt API létrehozása vagy a Fürtkonfigurációs API frissítése mezőben.
A Databricks nem javasolja a globális init-szkriptek használatát.
Az összes fürt Spark-tulajdonságainak beállításához hozzon létre egy globális init-szkriptet:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Spark-konfigurációs tulajdonság lekérése titkos kódból
A Databricks azt javasolja, hogy az egyszerű szöveg helyett titkos kódban tárolja a bizalmas információkat, például a jelszavakat. Ha egy titkos kódra szeretne hivatkozni a Spark-konfigurációban, használja a következő szintaxist:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Ha például egy Spark-konfigurációs tulajdonságot szeretne beállítani, amely a következőben secrets/acme_app/passwordtárolt titkos kód értékére van meghívvapassword:
spark.password {{secrets/acme-app/password}}
További információt a Spark konfigurációs tulajdonságában vagy környezeti változójában található titkos kódokra vonatkozó szintaxisban talál.
Környezeti változók
Egyéni környezeti változókat konfigurálhat, amelyek a fürtön futó init-szkriptekből érhetők el. A Databricks előre definiált környezeti változókat is biztosít, amelyeket init-szkriptekben használhat. Ezeket az előre definiált környezeti változókat nem lehet felülbírálni.
A fürtkonfigurációs lapon kattintson a Speciális beállítások váltógombra.
Kattintson a Spark fülre.
Állítsa be a környezeti változókat a Környezeti változók mezőben.
A környezeti változókat az új fürt API létrehozása vagy a spark_env_varsfürtkonfigurációs API frissítése mezőben is beállíthatja.
Fürtcímkék
A fürtcímkék lehetővé teszik a szervezet különböző csoportjai által használt felhőerőforrások költségeinek egyszerű monitorozását. A fürtök létrehozásakor kulcs-érték párként adhat meg címkéket, és az Azure Databricks ezeket a címkéket a felhőbeli erőforrásokra, például virtuális gépekre és lemezkötetekre, valamint DBU-használati jelentésekre alkalmazza.
A készletekből indított fürtök esetében az egyéni fürtcímkék csak a DBU használati jelentéseire vonatkoznak, és nem propagálódnak a felhőbeli erőforrásokra.
A készlet- és fürtcímketípusok együttes működéséről további információt a használat figyelése címkékkel című témakörben talál.
A kényelem érdekében az Azure Databricks négy alapértelmezett címkét alkalmaz minden fürtre: Vendor, Creator, ClusterNameés ClusterId.
Emellett a feladatfürtökön az Azure Databricks két alapértelmezett címkét alkalmaz: RunName és JobId.
A Databricks SQL által használt erőforrásokra az Azure Databricks az alapértelmezett címkét SqlWarehouseIdis alkalmazza.
Figyelmeztetés
Ne rendeljen hozzá egyéni címkét a kulccsal Name egy fürthöz. Minden fürt rendelkezik egy címkével Name , amelynek értékét az Azure Databricks állítja be. Ha módosítja a kulccsal Nametársított értéket, a fürtöt az Azure Databricks már nem tudja nyomon követni. Ennek következtében előfordulhat, hogy a fürt tétlenné válás után nem szűnik meg, és továbbra is használati költségekkel jár.
Fürt létrehozásakor egyéni címkéket is hozzáadhat. Fürtcímkék konfigurálása:
A fürtkonfigurációs lapon kattintson a Speciális beállítások váltógombra.
A lap alján kattintson a Címkék fülre.
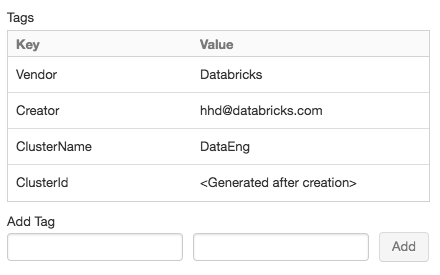
Adjon hozzá kulcs-érték párokat az egyes egyéni címkékhez. Legfeljebb 43 egyéni címkét adhat hozzá.
SSH-hozzáférés fürtökhöz
Biztonsági okokból az Azure Databricksben az SSH-port alapértelmezés szerint bezárul. Ha engedélyezni szeretné az SSH-hozzáférést a Spark-fürtökhöz, forduljon az Azure Databricks ügyfélszolgálatához.
Feljegyzés
Az SSH csak akkor engedélyezhető, ha a munkaterület a saját Azure-beli virtuális hálózatában van üzembe helyezve.
Fürtnapló-kézbesítés
A fürt létrehozásakor megadhat egy helyet a Spark illesztőprogram-csomópontjához, munkavégző csomópontjaihoz és eseményeihez tartozó naplók kézbesítéséhez. A rendszer öt percenként kézbesíti a naplókat a kiválasztott célhelyre. A fürt leállásakor az Azure Databricks garantálja, hogy a fürt leállításáig generált összes naplót kézbesíti.
A naplók célja a fürtazonosítótól függ. Ha a megadott célhely, dbfs:/cluster-log-deliverya fürtnaplók 0630-191345-leap375 a következő helyre lesznek kézbesítve dbfs:/cluster-log-delivery/0630-191345-leap375: .
A naplók kézbesítési helyének konfigurálása:
A fürtkonfigurációs lapon kattintson a Speciális beállítások váltógombra.
Kattintson a Naplózás fülre.
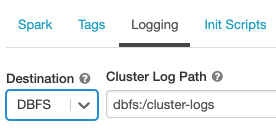
Válasszon egy céltípust.
Adja meg a fürtnapló elérési útját.
Feljegyzés
Ez a funkció a REST API-ban is elérhető. Tekintse meg a Clusters API-t.
Init szkriptek
A fürtcsomópont-inicializálási vagy inicializálási szkriptek olyan rendszerhéjszkriptek, amelyek az egyes fürtcsomópontok indításakor futnak a Spark-illesztőprogram vagy a feldolgozó JVM elindítása előtt . Init-szkriptekkel telepíthet a Databricks-futtatókörnyezetben nem szereplő csomagokat és kódtárakat, módosíthatja a JVM rendszerosztályútját, beállíthatja a JVM által használt rendszertulajdonságokat és környezeti változókat, vagy módosíthatja a Spark konfigurációs paramétereit a többi konfigurációs feladat mellett.
Init-szkripteket csatolhat egy fürthöz a Speciális beállítások szakasz kibontásával, majd az Init Scripts fülre kattintva.
Részletes útmutatásért lásd : Mik azok az init szkriptek?.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: