HorovodRunner: elosztott mély tanulás a Horovoddal
Fontos
A Horovod és a HorovodRunner elavult. A 15.4 LTS ML-t követő kiadások esetében ez a csomag nem lesz előre telepítve. Elosztott mélytanulás esetén a Databricks azt javasolja, hogy a TorchDistributort használja elosztott betanításhoz a PyTorch-tal, vagy az API-t a tf.distribute.Strategy TensorFlow-tal való elosztott betanításhoz.
Megtudhatja, hogyan végezhet elosztott gépi tanulási modellek betanítását a HorovodRunnerrel a Horovod betanítási feladatok Spark-feladatokként való elindításához az Azure Databricksben.
Mi az a HorovodRunner?
A HorovodRunner egy általános API, amely elosztott mélytanulási számítási feladatokat futtat az Azure Databricksen a Horovod-keretrendszer használatával. A Horovod és a Spark akadálymentes üzemmódjának integrálásával az Azure Databricks nagyobb stabilitást biztosít a Sparkon futó, hosszan futó mélytanulási betanítási feladatokhoz. A HorovodRunner egy Python-metódust használ, amely Horovod-horogokkal rendelkező mélytanulási betanítási kódot tartalmaz. A HorovodRunner felveszi a módszert a vezetőn, és elosztja a Spark-feldolgozók között. A Horovod MPI-feladatok Spark-feladatként vannak beágyazva az akadályvégrehajtási mód használatával. Az első végrehajtó összegyűjti az összes feladat-végrehajtó IP-címét, BarrierTaskContext és elindít egy Horovod-feladatot a használatával mpirun. Minden Python MPI-folyamat betölti a pácolt felhasználói programot, deszerializálja és futtatja.
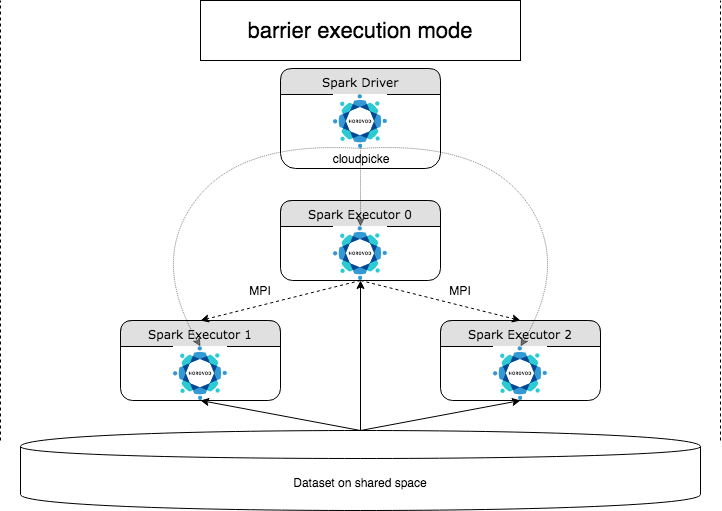
Elosztott betanítás a HorovodRunnerrel
A HorovodRunner lehetővé teszi, hogy Spark-feladatokként elindítsa a Horovod betanítási feladatait. A HorovodRunner API támogatja a táblázatban látható metódusokat. További részletekért tekintse meg a HorovodRunner API dokumentációját.
| Metódus és aláírás | Leírás |
|---|---|
init(self, np) |
Hozzon létre egy HorovodRunner-példányt. |
run(self, main, **kwargs) |
Horovod-betanítási main(**kwargs)feladat futtatása . A fő függvény és a kulcsszóargumentumok a cloudpickle használatával szerializálódnak, és a fürtmunkások között vannak elosztva. |
Az elosztott képzési program HorovodRunner használatával történő fejlesztésének általános megközelítése a következő:
- Hozzon létre egy
HorovodRunnercsomópontok számával inicializált példányt. - Definiáljon egy Horovod betanítási módszert a Horovod-használatban leírt módszerek szerint, és ügyeljen arra, hogy minden importálási utasítást adjon hozzá a metódushoz.
- Adja át a betanítási módszert a
HorovodRunnerpéldánynak.
Példa:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Ha a HorovodRunnert csak alfolyamatokkal n szeretné futtatni az illesztőn, használja a következőt hr = HorovodRunner(np=-n): . Ha például 4 GPU található az illesztőcsomóponton, a következőt választhatja n : 4. A paraméter nprészleteiért tekintse meg a HorovodRunner API dokumentációját. A GPU-k alfolyamatonkénti rögzítéséről további információt a Horovod használati útmutatójában talál.
Gyakori hiba, hogy a TensorFlow-objektumok nem találhatók vagy nem válogathatók. Ez akkor fordul elő, ha az erőforrástár importálási utasításai nem lesznek elosztva más végrehajtók között. A probléma elkerülése érdekében adja meg az összes importálási utasítást (például import tensorflow as tf) a Horovod betanítási módszer tetején, valamint a Horovod betanítási metódusban hívott többi felhasználó által definiált függvénybe.
Horovod-betanítás rögzítése a Horovod Timeline használatával
A Horovod képes rögzíteni tevékenységének idővonalát, az úgynevezett Horovod Timeline-t.
Fontos
A Horovod Timeline jelentős hatással van a teljesítményre. Az Inception3 átviteli sebessége ~40%-kal csökkenhet, ha a Horovod Timeline engedélyezve van. A HorovodRunner-feladatok felgyorsításához ne használja a Horovod Timelineot.
A Horovod-idővonal nem tekinthető meg, amíg a betanítás folyamatban van.
Horovod-ütemterv rögzítéséhez állítsa a HOROVOD_TIMELINE környezeti változót arra a helyre, ahová menteni szeretné az ütemtervfájlt. A Databricks azt javasolja, hogy használjon egy helyet a megosztott tárterületen, hogy az idővonalfájl könnyen lekérhető legyen. Használhatja például a DBFS helyi fájl API-jait az alábbi módon:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Ezután adja hozzá az idővonal-specifikus kódot a betanítási függvény elejéhez és végéhez. Az alábbi példajegyzetfüzet példakódot tartalmaz, amelyet kerülő megoldásként használhat a betanítási folyamat megtekintéséhez.
Horovod idővonal példajegyzetfüzete
Az idővonalfájl letöltéséhez használja a Databricks parancssori felületet, majd a Chrome böngésző eszközét chrome://tracing használva tekintse meg. Példa:
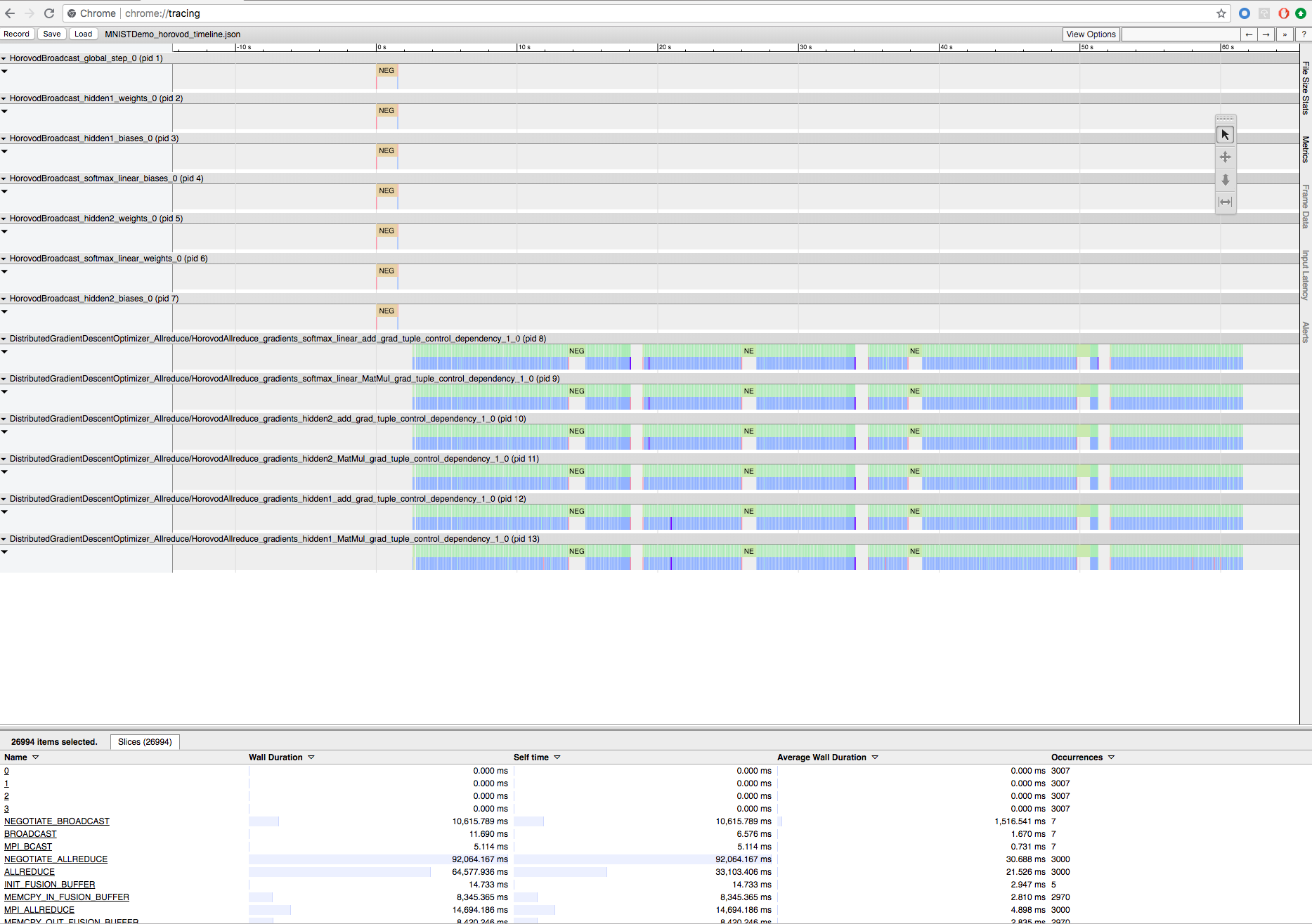
Fejlesztési munkafolyamat
Ezek az egycsomópontos mélytanulási kód elosztott betanításba való migrálásának általános lépései. A példák: Migrálás elosztott mély tanulásba a HorovodRunnerrel ebben a szakaszban ezeket a lépéseket szemlélteti.
- Egyetlen csomópont kódjának előkészítése: Az egyetlen csomópont kódjának előkészítése és tesztelése a TensorFlow, a Keras vagy a PyTorch használatával.
- Migrálás Horovodba: A Horovod-használat utasításait követve migrálja a kódot a Horovodtal, és tesztelje azt az illesztőprogramon:
- Hozzáadás
hvd.init()a Horovod inicializálásához. - A folyamat által használandó kiszolgálói GPU rögzítése a következő használatával
config.gpu_options.visible_device_list: . A folyamatonkénti egy GPU tipikus beállításával ez helyi rangra állítható be. Ebben az esetben a kiszolgálón az első folyamat lesz lefoglalva az első GPU, a második folyamat a második GPU lesz lefoglalva, és így tovább. - Adja meg az adathalmaz egy szegmensét. Ez az adathalmaz-operátor nagyon hasznos az elosztott betanítások futtatásakor, mivel lehetővé teszi, hogy minden feldolgozó egy egyedi részhalmazt olvasson.
- A tanulási arány skálázása a dolgozók száma szerint. A szinkron elosztott betanítás tényleges kötegméretét a feldolgozók száma skálázza. A tanulási sebesség növelése kompenzálja a megnövekedett kötegméretet.
- Az optimalizáló körbefuttatása a következőbe
hvd.DistributedOptimizer: . Az elosztott optimalizáló a színátmenetes számítást az eredeti optimalizálónak delegálja, az allreduce vagy az allgather használatával átlagozza a színátmeneteket, majd alkalmazza az átlagolt színátmeneteket. - Adja hozzá
hvd.BroadcastGlobalVariablesHook(0)a kezdeti változóállapotokat a 0. rangsortól az összes többi folyamatig. Erre azért van szükség, hogy az összes dolgozó konzisztens inicializálását biztosítsa, amikor a betanítás véletlenszerű súlyokkal kezdődik, vagy egy ellenőrzőpontról visszaállítják. Ha nem használjaMonitoredTrainingSession, a globális változók inicializálása után is végrehajthatja ahvd.broadcast_global_variablesműveletet. - Módosítsa a kódot úgy, hogy csak a 0. feldolgozóra mentse az ellenőrzőpontokat, hogy más dolgozók ne sérüljenek meg.
- Hozzáadás
- Migrálás a HorovodRunnerbe: A HorovodRunner egy Python-függvény meghívásával futtatja a Horovod-betanítási feladatot. A fő betanítási eljárást egyetlen Python-függvénybe kell csomagolnia. Ezután helyi és elosztott módban tesztelheti a HorovodRunnert.
A mélytanulási kódtárak frissítése
A TensorFlow, a Keras vagy a PyTorch frissítéséhez vagy visszalépéséhez újra kell telepítenie a Horovodot, hogy az az újonnan telepített kódtárra legyen lefordítva. Ha például frissíteni szeretné a TensorFlow-t, a Databricks azt javasolja, hogy használja a TensorFlow telepítési utasításaiból származó init szkriptet, és fűzze hozzá a következő TensorFlow-specifikus Horovod telepítési kódot a végéhez. A Horovod telepítési útmutatója különböző kombinációkkal, például a PyTorch és más kódtárak frissítésével vagy visszaminősítésével foglalkozik.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Példák: Migrálás elosztott mélytanulásba a HorovodRunnerrel
Az alábbi példák az MNIST-adatkészlet alapján bemutatják, hogyan migrálhatók egy egycsomópontos mélytanulási programok a HorovodRunnerrel való elosztott mélytanulásba.
- Mély tanulás a TensorFlow használatával az MNIST-hez készült HorovodRunnerrel
- Egycsomópontos PyTorch adaptálása elosztott mélytanuláshoz
Korlátozások
- Munkaterületfájlok használatakor a HorovodRunner nem működik, ha
np1-nél nagyobb értékre van beállítva, és a jegyzetfüzet más relatív fájlokból importálódik. Fontolja meg a horovod.spark használatát ahelyettHorovodRunner, hogy . - Ha olyan hibákba ütközik, mint például
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer, ez a fürt csomópontjai közötti hálózati kommunikációval kapcsolatos problémát jelez. A hiba megoldásához adja hozzá a következő kódrészletet a betanítási kódhoz az elsődleges hálózati adapter használatához.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"