Jegyzet
Az oldalhoz való hozzáférés engedélyezést igényel. Próbálhatod be jelentkezni vagy könyvtárat váltani.
Az oldalhoz való hozzáférés engedélyezést igényel. Megpróbálhatod a könyvtár váltását.
A kiszolgáló nélküli GPU Python API-val több GPU-n is elindíthat elosztott számítási feladatokat – akár egyetlen csomóponton belül, akár több csomóponton belül. Az API egy egyszerű, egységes felületet biztosít, amely elvonja a GPU kiépítésének, a környezet beállításának és a számítási feladatok elosztásának részleteit. Minimális kódmódosításokkal zökkenőmentesen áttérhet az egy GPU-betanításról a távoli GPU-k közötti elosztott végrehajtásra ugyanabból a jegyzetfüzetből.
Gyors kezdés
Az elosztott betanítás kiszolgáló nélküli GPU API-ja előre telepítve van a Databricks-notebookok kiszolgáló nélküli GPU-számítási környezeteiben. A 4- és újabb GPU-környezetet javasoljuk. Ha elosztott betanításhoz szeretné használni, importálja és használja a distributed dekorátort a betanítási függvény terjesztéséhez.
Az alábbi kódrészlet bemutatja a @distributed alapszintű használatát.
# Import the distributed decorator
from serverless_gpu import distributed
# Decorate your training function with @distributed and specify the number of GPUs, the GPU type,
# and whether or not the GPUs are remote
@distributed(gpus=8, gpu_type='A10', remote=True)
def run_train():
...
Az alábbiakban egy teljes példa látható, amely egy többrétegű perceptron (MLP) modellt tanít be 8 A10 GPU-csomóponton egy jegyzetfüzetből:
Állítsa be a modellt, és definiálja a segédprogramfüggvényeket.
# Define the model import os import torch import torch.distributed as dist import torch.nn as nn def setup(): dist.init_process_group("nccl") torch.cuda.set_device(int(os.environ["LOCAL_RANK"])) def cleanup(): dist.destroy_process_group() class SimpleMLP(nn.Module): def __init__(self, input_dim=10, hidden_dim=64, output_dim=1): super().__init__() self.net = nn.Sequential( nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, output_dim) ) def forward(self, x): return self.net(x)Importálja a serverless_gpu kódtárat és az elosztott modult .
import serverless_gpu from serverless_gpu import distributedCsomagolja be a modell betanítási kódját egy függvénybe, és díszítse a függvényt a
@distributeddekorátorsal.@distributed(gpus=8, gpu_type='A10', remote=True) def run_train(num_epochs: int, batch_size: int) -> None: import mlflow import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data import DataLoader, DistributedSampler, TensorDataset # 1. Set up multi node environment setup() device = torch.device(f"cuda:{int(os.environ['LOCAL_RANK'])}") # 2. Apply the Torch distributed data parallel (DDP) library for data-parellel training. model = SimpleMLP().to(device) model = DDP(model, device_ids=[device]) # 3. Create and load dataset. x = torch.randn(5000, 10) y = torch.randn(5000, 1) dataset = TensorDataset(x, y) sampler = DistributedSampler(dataset) dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size) # 4. Define the training loop. optimizer = optim.Adam(model.parameters(), lr=0.001) loss_fn = nn.MSELoss() for epoch in range(num_epochs): sampler.set_epoch(epoch) model.train() total_loss = 0.0 for step, (xb, yb) in enumerate(dataloader): xb, yb = xb.to(device), yb.to(device) optimizer.zero_grad() loss = loss_fn(model(xb), yb) # Log loss to MLflow metric mlflow.log_metric("loss", loss.item(), step=step) loss.backward() optimizer.step() total_loss += loss.item() * xb.size(0) mlflow.log_metric("total_loss", total_loss) print(f"Total loss for epoch {epoch}: {total_loss}") cleanup()Az elosztott betanítás végrehajtásához hívja meg az elosztott függvényt felhasználó által megadott argumentumokkal.
run_train.distributed(num_epochs=3, batch_size=1)A végrehajtáskor egy MLflow-futtatási hivatkozás jön létre a jegyzetfüzetcella kimenetében. Kattintson az MLflow futtatási hivatkozására, vagy keresse meg a Kísérlet panelen a futtatási eredmények megtekintéséhez.
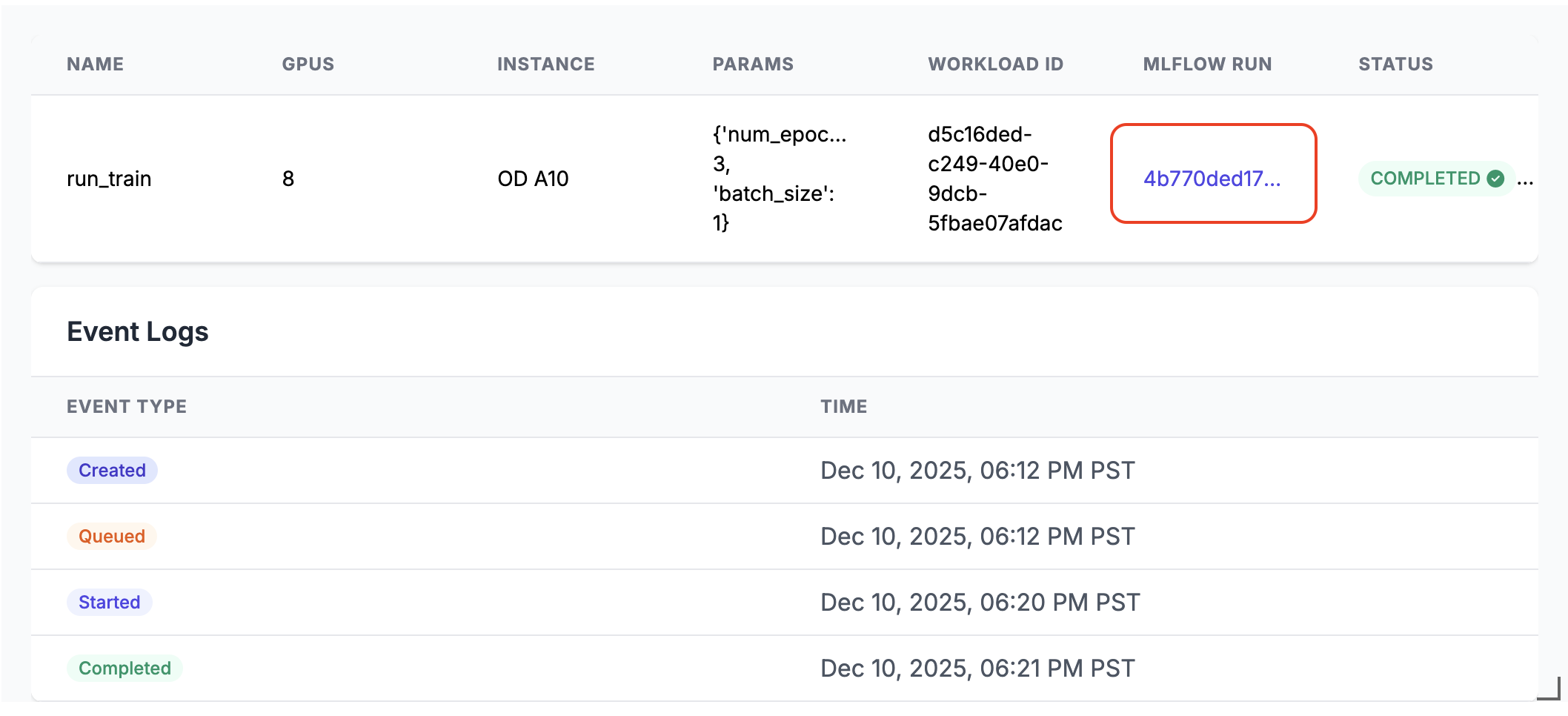
Elosztott végrehajtás részletei
A kiszolgáló nélküli GPU API több fő összetevőből áll:
- Compute Manager: Kezeli az erőforrások elosztását és kezelését
- Futtatókörnyezet: Python-környezetek és -függőségek kezelése
- Launcher: A feladatok végrehajtásának és figyelésének vezénylése
Elosztott módban való futtatás esetén:
- A függvény szerializálva van és elosztva a megadott számú GPU-ban
- Minden GPU ugyanazokkal a paraméterekkel futtatja a függvény egy példányát
- A környezet minden csomóponton szinkronizálva van
- A rendszer összegyűjti és visszaadja az eredményeket az összes GPU-ból
Ha remote be van állítva True, a számítási feladat a távoli GPU-kon lesz elosztva. Ha remote be van állítva False, a számítási feladat az aktuális jegyzetfüzethez csatlakoztatott egyetlen GPU-csomóponton fut. Ha a csomópont több GPU-chippel rendelkezik, mindegyik használatban lesz.
Az API támogatja az olyan népszerű párhuzamos betanítási kódtárakat, mint az Elosztott Adatpárhuzamos (DDP), Teljesen Megosztott Adatpárhuzamos (FSDP), DeepSpeed és Ray.
A jegyzetfüzet-példákban szereplő különböző kódtárak használatával valósabb elosztott betanítási forgatókönyveket találhat.
Indítás Ray használatával
A serverless GPU API támogatja az elosztott tanítás indítását Ray használatával, a @ray_launch dekorátoron keresztül, amely @distributed fölé rétegezhető.
Minden ray_launch feladat először elindít egy "torch-distributed rendezvous"-t, hogy meghatározza a Ray fő feldolgozót, és összegyűjtse az IP-címeket. A rank-zero elindul ray start --head (ha a metrikák exportálása engedélyezve van), beállítja RAY_ADDRESS, és Ray-illesztőként futtatja a dekorált függvényt. Más csomópontok ray start --address-on keresztül csatlakoznak és várjanak, amíg az illesztőprogram befejező jelölőt ír.
További konfigurációs részletek:
- Ha engedélyezni szeretné a Ray rendszermetrikák gyűjteményét az egyes csomópontokon, használja
RayMetricsMonitora következővelremote=True: . - A Ray futtatókörnyezeti opcióit (színészek, adathalmazok, elhelyezési csoportok és ütemezés) definiálja a díszített függvényben a standard Ray API-k használatával.
- A dekorátorargumentumokban vagy notebookkörnyezetben a függvényen kívüli fürtszintű vezérlők (GPU-szám és típus, távoli vs. helyi mód, aszinkron viselkedés és Databricks-készlet környezeti változói) kezelése.
Az alábbi példa a használat @ray_launchmódját mutatja be:
from serverless_gpu.ray import ray_launch
@ray_launch(gpus=16, remote=True, gpu_type='A10')
def foo():
import os
import ray
print(ray.state.available_resources_per_node())
return 1
foo.distributed()
Egy teljes példáért tekintse meg ezt a jegyzetfüzetet, amely elindítja a Rayt egy Resnet18 neurális hálózat betanításához több A10 GPU-n.
Ezzel az API-val meghívhatja a Ray Data-t, az AI-számítási feladatok skálázható adatfeldolgozási kódtárát is, hogy elosztott kötegkövetkeztetést futtasson az LLM-eken. Lásd a vllm és a szglang példákat.
FAQs
Hol kell elhelyezni az adatbetöltési kódot?
Ha kiszolgáló nélküli GPU API-t használ az elosztott betanításhoz, helyezze át az adatbetöltési kódot a @distributed dekorátorba. Az adathalmaz mérete meghaladhatja a pickle által megengedett maximális méretet, ezért javasoljuk, hogy az adathalmazt a dekorátoron belül hozza létre, az alábbiak szerint:
from serverless_gpu import distributed
# this may cause pickle error
dataset = get_dataset(file_path)
@distributed(gpus=8, remote=True)
def run_train():
# good practice
dataset = get_dataset(file_path)
....
Használhatok fenntartott GPU-készleteket?
Ha a munkaterületen elérhető egy fenntartott GPU-készlet (egyeztessen a rendszergazdával), és a remote dekorátorban True-tól @distributed-ig ad meg, a számítási feladat alapértelmezés szerint a fenntartott GPU-készletben indul el. Ha az igény szerinti GPU-készletet szeretné használni, az elosztott függvény meghívása előtt állítsa be a környezeti változót DATABRICKS_USE_RESERVED_GPU_POOLFalse az alábbi módon:
import os
os.environ['DATABRICKS_USE_RESERVED_GPU_POOL'] = 'False'
@distributed(gpus=8, remote=True)
def run_train():
...
Tudj meg többet
Az API-referenciaért tekintse meg a Kiszolgáló nélküli GPU Python API dokumentációját.