Streamfeldolgozás az Apache Kafka és az Azure Databricks használatával
Ez a cikk azt ismerteti, hogyan használhatja az Apache Kafkát forrásként vagy fogadóként, ha strukturált streamelési számítási feladatokat futtat az Azure Databricksen.
További Kafka-információkért tekintse meg a Kafka dokumentációját.
Adatok olvasása a Kafkából
Az alábbiakban egy példa látható a Kafkából származó streamelési olvasásra:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Az Azure Databricks a Kafka-adatforrások kötegelt olvasási szemantikáját is támogatja, ahogyan az a következő példában is látható:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Növekményes kötegbetöltés esetén a Databricks a Kafka használatát javasolja.Trigger.AvailableNow Lásd a növekményes kötegfeldolgozás konfigurálását.
A Databricks Runtime 13.3 LTS-ben és újabb verziókban az Azure Databricks egy SQL-függvényt biztosít a Kafka-adatok olvasásához. Az SQL-sel való streamelés csak a Delta Live Tablesben vagy a Databricks SQL-ben futó streamtáblákban támogatott. Lásd read_kafka táblaértékű függvényt.
Kafka strukturált streamolvasó konfigurálása
Az Azure Databricks adatformátumként biztosítja a kafka kulcsszót a Kafka 0.10+-kapcsolatok konfigurálásához.
A Kafka leggyakoribb konfigurációi a következők:
Többféleképpen is megadhatja, hogy mely témakörökre szeretne feliratkozni. Csak az egyik paramétert kell megadnia:
| Lehetőség | Érték | Leírás |
|---|---|---|
| feliratkozás | Témakörök vesszővel tagolt listája. | A feliratkozni kívánt témakörlista. |
| subscribePattern | Java regex sztring. | A témakör(ek)re való feliratkozáshoz használt minta. |
| átruház | JSON-sztring {"topicA":[0,1],"topic":[2,4]}. |
Használandó konkrét topicPartitions. |
Egyéb figyelemre méltó konfigurációk:
| Lehetőség | Érték | Alapértelmezett érték | Leírás |
|---|---|---|---|
| kafka.bootstrap.servers | A gazdagép:port vesszővel tagolt listája. | üres | [Kötelező] A Kafka-konfiguráció bootstrap.servers . Ha úgy találja, hogy a Kafka nem tartalmaz adatokat, először ellenőrizze a közvetítő címlistáját. Ha a közvetítő címlistája helytelen, előfordulhat, hogy nem történt hiba. Ennek az az oka, hogy a Kafka-ügyfél feltételezi, hogy a közvetítők végül elérhetővé válnak, és hálózati hibák esetén újra próbálkoznak örökre. |
| failOnDataLoss | true vagy false. |
true |
[Nem kötelező] A lekérdezés meghiúsulása, ha lehetséges, hogy az adatok elvesznek. A lekérdezések számos forgatókönyv, például a törölt témakörök, a témakörök feldolgozása előtti csonkolás stb. miatt a Kafkából végleg nem tudják beolvasni az adatokat. Megpróbáljuk konzervatívan megbecsülni, hogy az adatok esetleg elvesztek-e vagy sem. Néha ez hamis riasztásokat okozhat. Állítsa be ezt a beállítást false , ha nem a várt módon működik, vagy azt szeretné, hogy a lekérdezés az adatvesztés ellenére is feldolgozható legyen. |
| minPartitions | Egész szám >= 0, 0 = letiltva. | 0 (letiltva) | [Nem kötelező] A Kafkából beolvasandó partíciók minimális száma. A Spark konfigurálható úgy, hogy tetszőleges minimális partíciót használjon a Kafkából való olvasáshoz a minPartitions beállítás használatával. A Spark általában a Kafka topicPartitions és a Kafka által fogyasztott Spark-partíciók 1-1 leképezésével rendelkezik. Ha a beállítást a minPartitions Kafka topicPartitions értékénél nagyobb értékre állítja be, a Spark a nagy Kafka-partíciókat kisebb darabokra osztva. Ez a beállítás beállítható csúcsterhelések, adateltérés és a stream elmaradása esetén a feldolgozási sebesség növelése érdekében. Ennek költsége a Kafka-felhasználók inicializálása minden eseményindítónál, ami hatással lehet a teljesítményre, ha SSL-t használ a Kafkához való csatlakozáskor. |
| kafka.group.id | Kafka fogyasztói csoport azonosítója. | nincs beállítva | [Nem kötelező] A Kafkából való olvasáshoz használandó csoportazonosító. Óvatosan használja ezt a műveletet. Alapértelmezés szerint minden lekérdezés egyedi csoportazonosítót hoz létre az adatok olvasásához. Ez biztosítja, hogy minden lekérdezés saját fogyasztói csoportokkal rendelkezik, amelyek nem ütköznek más felhasználók beavatkozásával, és ezért elolvashatják az előfizetett témakörök összes partícióját. Bizonyos esetekben (például Kafka-csoportalapú engedélyezés) érdemes lehet adott engedélyezett csoportazonosítókat használni az adatok olvasásához. Igény szerint beállíthatja a csoportazonosítót. Ezt azonban rendkívül körültekintően végezze el, mivel ez váratlan viselkedést okozhat. * Az azonos csoportazonosítóval rendelkező egyidejűleg futó lekérdezések (kötegelt és streameléses) valószínűleg zavarják egymást, ezért az egyes lekérdezések csak az adatok egy részét olvassák be. * Ez akkor is előfordulhat, ha a lekérdezések gyors egymásutánban indulnak el/indulnak újra. Az ilyen problémák minimalizálása érdekében állítsa a Kafka fogyasztói konfigurációját session.timeout.ms nagyon kicsire. |
| startingOffsets | legkorábbi , legkésőbbi | legújabb | [Nem kötelező] A lekérdezés indításakor a kezdőpont, amely a legkorábbi eltolásokból származik, vagy egy json-sztring, amely az egyes TopicPartition-objektumok kezdő eltolását adja meg. A json-ban a -2 eltolással a legkorábbi, -1 és legkésőbbi értékre hivatkozhat. Megjegyzés: Kötegelt lekérdezések esetén a legújabb (implicit módon vagy a -1 json-ban történő használatával) nem engedélyezett. Streamelési lekérdezések esetén ez csak új lekérdezés indításakor érvényes, és az újrakezdés mindig onnan indul el, ahol a lekérdezés abbahagyta. A lekérdezés során újonnan felfedezett partíciók legkorábban elindulnak. |
További választható konfigurációkért lásd a strukturált streamelési Kafka-integrációs útmutatót .
Kafka-rekordok sémája
A Kafka-rekordok sémája a következő:
| Oszlop | Típus |
|---|---|
| kulcs | bináris |
| Érték | bináris |
| témakör | húr |
| feloszt | egész |
| ellensúlyoz | hosszú |
| időbélyeg | hosszú |
| timestampType | egész |
Az key és a value mindig deszerializált bájttömbök ByteArrayDeserializera . DataFrame-műveletek (például cast("string")) használatával explicit módon deszerializálhatja a kulcsokat és értékeket.
Adatok írása a Kafkába
Az alábbiakban egy példa látható a Kafkába történő streamelésre:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Az Azure Databricks a Kafka-adatgyűjtőkbe történő kötegelt írási szemantikát is támogatja, ahogyan az a következő példában is látható:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Kafka strukturált streamelési író konfigurálása
Fontos
A Databricks Runtime 13.3 LTS és újabb verziója tartalmazza a kódtár újabb verzióját, amely alapértelmezés szerint lehetővé teszi az kafka-clients idempotens írást. Ha egy Kafka-fogadó a 2.8.0-s vagy újabb verziót használja a konfigurált ACL-ekkel, de IDEMPOTENT_WRITE nincs engedélyezve, az írás a hibaüzenettel org.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error statemeghiúsul.
A hiba megoldásához frissítsen a Kafka 2.8.0-s vagy újabb verziójára, vagy állítsa be .option(“kafka.enable.idempotence”, “false”) a strukturált streamelési író konfigurálását.
A DataStreamWriter számára biztosított séma a Kafka-fogadóval kommunikál. A következő mezőket használhatja:
| Oszlop neve | Kötelező vagy választható | Típus |
|---|---|---|
key |
választható | STRING vagy BINARY |
value |
kötelező | STRING vagy BINARY |
headers |
választható | ARRAY |
topic |
nem kötelező (figyelmen kívül hagyva, ha topic íróként van beállítva) |
STRING |
partition |
választható | INT |
A Kafkába való írás során a következő gyakori beállítások vannak beállítva:
| Lehetőség | Érték | Alapértelmezett érték | Leírás |
|---|---|---|---|
kafka.boostrap.servers |
Vesszővel tagolt lista <host:port> |
Nincs | [Kötelező] A Kafka-konfiguráció bootstrap.servers . |
topic |
STRING |
nincs beállítva | [Nem kötelező] Beállítja a témakört az összes megírandó sorhoz. Ez a beállítás felülírja az adatokban található témaköroszlopokat. |
includeHeaders |
BOOLEAN |
false |
[Nem kötelező] A Kafka-fejlécek belefoglalása a sorba. |
További választható konfigurációkért lásd a strukturált streamelési Kafka-integrációs útmutatót .
Kafka-metrikák lekérése
A streamelési lekérdezés által elérhető eltolások átlagos, minimális és maximális számát az összes előfizetett témakör és metrikával rendelkező avgOffsetsBehindLatestmaxOffsetsBehindLatestminOffsetsBehindLatest összes előfizetett témakör esetében lekérheti. Lásd interaktívan a metrikák olvasását.
Feljegyzés
A Databricks Runtime 9.1-ben és újabb verziókban érhető el.
A lekérdezési folyamat által nem felhasznált bájtok becsült teljes számának lekérése a feliratkozott témakörökből a következő érték vizsgálatával estimatedTotalBytesBehindLatest: . Ez a becslés az elmúlt 300 másodpercben feldolgozott kötegeken alapul. A becslés alapjául megadott időkeret módosítható úgy, hogy a beállítást bytesEstimateWindowLength egy másik értékre állítja. Ha például 10 percre szeretné beállítani:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Ha egy jegyzetfüzetben futtatja a streamet, a streamelési lekérdezés folyamatának irányítópultján, a Nyers adatok lapon láthatja ezeket a metrikákat:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Az Azure Databricks és a Kafka csatlakoztatása SSL használatával
A Kafkával létesített SSL-kapcsolatok engedélyezéséhez kövesse a Confluent dokumentációjának titkosítási és hitelesítési ssl-kapcsolattal kapcsolatos utasításait. Megadhatja az ott leírt konfigurációkat, előtaggal kafka., lehetőségként. Megadhatja például a megbízhatósági tár helyét a tulajdonságban kafka.ssl.truststore.location.
A Databricks a következőket javasolja:
- A tanúsítványokat a felhőobjektum-tárolóban tárolhatja. A tanúsítványokhoz való hozzáférést csak olyan fürtökre korlátozhatja, amelyek hozzáférhetnek a Kafkához. Lásd az adatszabályozást a Unity Catalog használatával.
- Titkos kulcsként tárolja a tanúsítványjelszavakat.
Az alábbi példa objektumtárolási helyeket és Databricks-titkos kulcsokat használ az SSL-kapcsolat engedélyezéséhez:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
A Kafka csatlakoztatása a HDInsighton az Azure Databrickshez
HDInsight Kafka-fürt létrehozása.
Útmutatásért lásd : Csatlakozás a HDInsighton futó Kafkához egy Azure-beli virtuális hálózaton keresztül.
Konfigurálja a Kafka-közvetítőket a megfelelő cím meghirdetéséhez.
Kövesse a Kafka IP-hirdetésekhez való konfigurálását ismertető útmutatót. Ha saját maga kezeli a Kafkát az Azure-beli virtuális gépeken, győződjön meg arról, hogy a
advertised.listenersközvetítők konfigurációja a gazdagépek belső IP-címére van állítva.Azure Databricks-fürt létrehozása.
Társviszony-létesítés a Kafka-fürt és az Azure Databricks-fürt között.
Szolgáltatásnév hitelesítése Microsoft Entra-azonosítóval (korábban Azure Active Directory) és Azure Event Hubs
Az Azure Databricks támogatja a Spark-feladatok hitelesítését az Event Hubs-szolgáltatásokkal. Ez a hitelesítés OAuth-on keresztül történik a Microsoft Entra-azonosítóval (korábbi nevén Azure Active Directory).
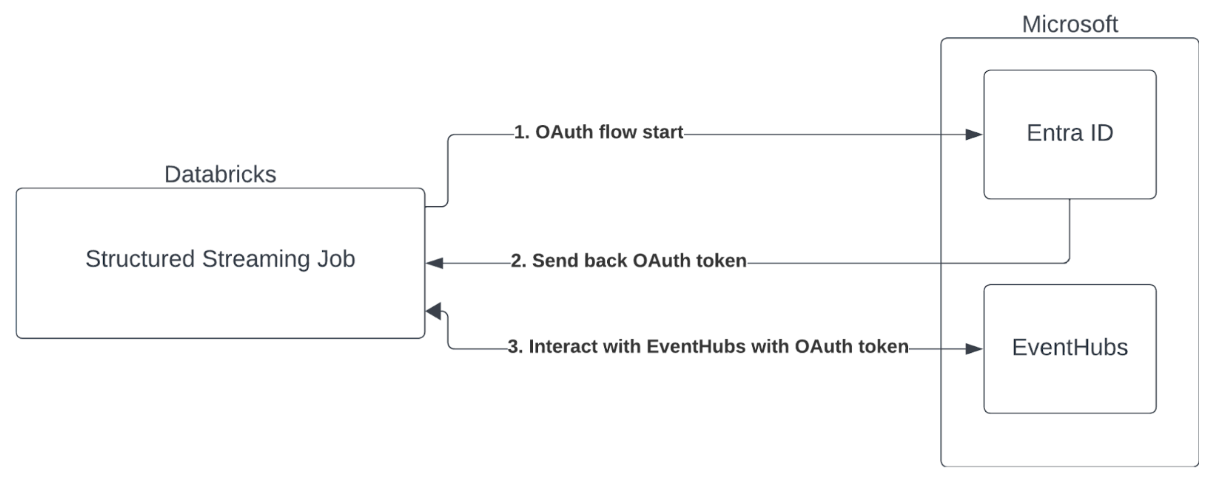
Az Azure Databricks az alábbi számítási környezetekben támogatja a Microsoft Entra ID-hitelesítést ügyfél-azonosítóval és titkos kóddal:
- A Databricks Runtime 12.2 LTS és újabb verziója az egyfelhasználós hozzáférési móddal konfigurált számításon.
- A Databricks Runtime 14.3 LTS és újabb verziója a megosztott hozzáférési móddal konfigurált számításon.
- A Unity Catalog nélkül konfigurált Delta Live Tables-folyamatok.
Az Azure Databricks nem támogatja a Microsoft Entra ID-hitelesítést tanúsítványsal bármely számítási környezetben, vagy a Unity Catalogtal konfigurált Delta Live Tables-folyamatokban.
Ez a hitelesítés nem működik megosztott fürtökön vagy Unity Catalog Delta Élő táblákon.
A strukturált streamelési Kafka-összekötő konfigurálása
A Microsoft Entra-azonosítóval végzett hitelesítéshez a következő értékekre lesz szüksége:
Bérlőazonosító. Ezt a Microsoft Entra ID-szolgáltatások lapján találja.
Ügyfélazonosító (más néven alkalmazásazonosító).
Egy titkos ügyfél. Ezt követően titkos kulcsként kell hozzáadnia a Databricks-munkaterülethez. A titkos kód hozzáadásáról a Titkos kódok kezelése című témakörben olvashat.
EventHubs-témakör. A témakörök listáját az Event Hubs szakaszban, egy adott Event Hubs-névtérlap Entitások szakaszában találja. Több témakör használatához beállíthatja az IAM-szerepkört az Event Hubs szintjén.
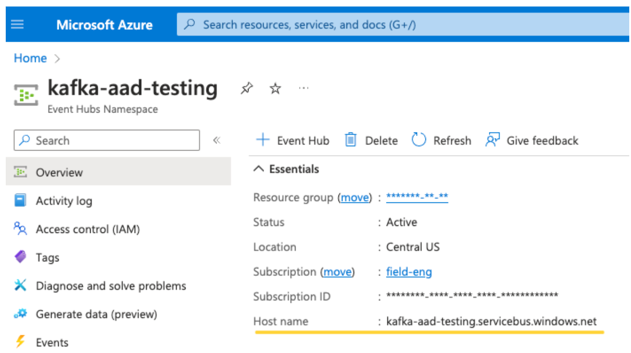
EventHubs-kiszolgáló. Ezt az adott Event Hubs-névtér áttekintési oldalán találja:
Az Entra ID használatához meg kell adnunk a Kafkának, hogy használja az OAuth SASL mechanizmust (a SASL egy általános protokoll, az OAuth pedig a SASL "mechanizmus" típusa):
kafka.security.protocolKellSASL_SSLkafka.sasl.mechanismKellOAUTHBEARERkafka.sasl.login.callback.handler.classA Java-osztály teljes neve legyen az árnyékolt Kafka-osztály bejelentkezési visszahívás-kezelőjénekkafkashadedértékével. A pontos osztályhoz lásd az alábbi példát.
Példa
Következő lépésként tekintsünk meg egy futó példát:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Lehetséges hibák kezelése
A streamelési lehetőségek nem támogatottak.
Ha ezt a hitelesítési mechanizmust egy Unity-katalógussal konfigurált Delta Live Tables-folyamatban próbálja használni, a következő hibaüzenet jelenhet meg:
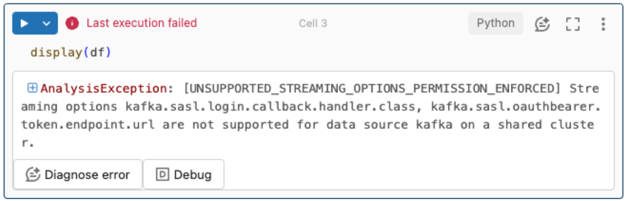
A hiba megoldásához használjon támogatott számítási konfigurációt. Lásd: Szolgáltatásnév-hitelesítés a Microsoft Entra-azonosítóval (korábbi nevén Azure Active Directory) és az Azure Event Hubs-tal.
Nem sikerült újat
KafkaAdminClientlétrehozni.Ez egy belső hiba, amelyet a Kafka jelez, ha az alábbi hitelesítési lehetőségek közül bármelyik helytelen:
- Ügyfélazonosító (más néven alkalmazásazonosító)
- Bérlőazonosító
- EventHubs-kiszolgáló
A hiba megoldásához ellenőrizze, hogy az értékek helyesek-e ezekhez a beállításokhoz.
Emellett ez a hiba akkor is előfordulhat, ha módosítja a példában alapértelmezés szerint megadott konfigurációs beállításokat (amelyeket a rendszer arra kért, hogy ne módosítsa), például
kafka.security.protocol.Nincsenek visszaadott rekordok
Ha megkísérli megjeleníteni vagy feldolgozni a DataFrame-et, de nem kap eredményeket, az alábbiakat fogja látni a felhasználói felületen.
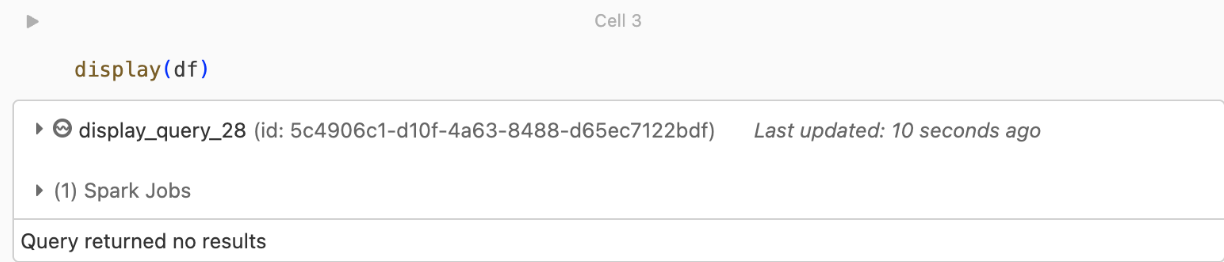
Ez az üzenet azt jelenti, hogy a hitelesítés sikeres volt, de az EventHubs nem adott vissza adatokat. Néhány lehetséges (bár egyáltalán nem teljes) ok:
- Helytelen EventHubs-témakört adott meg.
- Az alapértelmezett Kafka-konfigurációs beállítás
startingOffsetsalatestkövetkező, és jelenleg nem kap adatokat a témakörből.startingOffsetstoearliestBeállíthatja, hogy a Kafka legkorábbi eltolásaitól kezdve kezdje el az adatok olvasását.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: