Jegyzet
Az oldalhoz való hozzáférés engedélyezést igényel. Próbálhatod be jelentkezni vagy könyvtárat váltani.
Az oldalhoz való hozzáférés engedélyezést igényel. Megpróbálhatod a könyvtár váltását.
Megjegyzés:
Ez a cikk az Azure DevOpsot ismerteti, amelyet egy harmadik fél fejleszt. A szolgáltatóval való kapcsolatfelvételhez tekintse meg az Azure DevOps Services ügyfélszolgálatát.
Ez a cikk végigvezeti az Azure DevOps Azure Databricksszel való együttműködésre való konfigurálásával. Pontosabban, konfigurál egy folyamatos integrációs és szállítási (CI/CD) munkafolyamatot, amely kapcsolódik egy Git-adattárhoz, majd az Azure Pipelines segítségével futtatja a szükséges feladatokat egy Python csomag (*.whl) felépítésére és egységtesztelésére, végül pedig üzembe helyezi azt a Databricks-jegyzetfüzetek használatához.
A CI/CD és az Azure Databricks áttekintése: CI/CD az Azure Databricksben. Az ajánlott eljárásokért tekintse meg a Databricks ajánlott eljárásait és ajánlott CI-/CD-munkafolyamatait.
Tudnivalók a példáról
A cikk példája két folyamatot használ egy távoli Git-adattárban tárolt Python-kód- és Python-jegyzetfüzetek gyűjtésére, üzembe helyezésére és futtatására.
Az első, buildelési folyamatként ismert folyamat előkészíti a buildösszetevőket a második folyamathoz, más néven a kiadási folyamathoz. A buildelési folyamatnak a kiadási folyamattól való elkülönítésével anélkül hozhat létre buildösszetevőt, hogy üzembe helyezte volna, vagy egyszerre több buildből is telepíthet összetevőket. A buildelési és kiadási folyamatok létrehozása:
- Hozzon létre egy Azure-beli virtuális gépet a buildelési folyamathoz.
- Másolja a fájlokat a Git-adattárból a virtuális gépre.
- Hozzon létre egy gzip'ed tar fájlt, amely tartalmazza a Python-kódot, a Python-jegyzetfüzeteket és a kapcsolódó buildelési, üzembe helyezési és futtatási beállítások fájljait.
- Másolja a gzip'ed tar fájlt zip-fájlként a kiadási folyamat elérésére szolgáló helyre.
- Hozzon létre egy másik Azure-beli virtuális gépet a kiadási folyamathoz.
- Kérje le a zip-fájlt a buildelési folyamat helyére, majd csomagolja ki a zip-fájlt a Python-kód, a Python-jegyzetfüzetek és a kapcsolódó buildelési, üzembe helyezési és futtatási beállítások fájljainak lekéréséhez.
- Helyezze üzembe a Python-kódot, a Python-jegyzetfüzeteket és a kapcsolódó buildelési, üzembe helyezési és futtatási beállítások fájljait a távoli Azure Databricks-munkaterületen.
- A Python-kerékkönyvtár összetevő kódfájljait építse be egy Python-kerékfájlba.
- A Python-kerékfájl logikájának ellenőrzéséhez futtasson egységteszteket az összetevő kódján.
- Futtassa a Python-jegyzetfüzeteket, amelyek közül az egyik, a Python wheel fájl funkcióit hívja meg.
Mielőtt hozzákezdene
A cikk példájának használatához az alábbiakra van szükség:
- Egy meglévő Azure DevOps-projekt . Ha még nem rendelkezik projektel, hozzon létre egy projektet az Azure DevOpsban.
- Egy meglévő adattár egy Git-szolgáltatóval, amelyet az Azure DevOps támogat. Ehhez az adattárhoz hozzáadja a Python-példakódot, a példa Python-jegyzetfüzetet és a kapcsolódó kiadási beállítások fájljait. Ha még nem rendelkezik tárházzal, hozzon létre egyet a Git-szolgáltató utasításait követve. Ezután csatlakoztassa az Azure DevOps-projektet ehhez az adattárhoz, ha még nem tette meg. Útmutatásért kövesse a támogatott forrástárak hivatkozásait.
- A cikk példája OAuth machine-to-machine (M2M) hitelesítéssel hitelesíti a Microsoft Entra ID szolgáltatásnevet egy Azure Databricks-munkaterületen. Rendelkeznie kell egy Microsoft Entra ID szolgáltatásnévvel, amely rendelkezik egy Azure Databricks OAuth-titkos kóddal az adott szolgáltatásnévhez. Lásd: Az Azure Databrickshez való hozzáférés engedélyezése a szolgáltatásnévi objektum számára az OAuth használatával.
Jótanács
Autentikálhatja az Azure DevOps-t a Databrickshez egy Azure Resource Manager szolgáltatáskapcsolattal vagy Databricks feladat identitás-összevonással. Ezek a lehetőségek nem igénylik a titkos kulcsok kezelését.
1. lépés: A példa fájljainak hozzáadása az adattárhoz
Ebben a lépésben a külső Git-szolgáltató adattárában hozzáadja a jelen cikk összes példafájlját, amelyeket az Azure DevOps-folyamatok létrehoznak, üzembe helyeznek és futtatnak a távoli Azure Databricks-munkaterületen.
1.1. lépés: A Python-kerék összetevőfájljainak hozzáadása
A cikk példájában az Azure DevOps-folyamatok létrehoznak és tesztelnek egy Python-kerekes fájlt. Egy Azure Databricks-jegyzetfüzet ezután meghívja a Python kerék fájl beépített funkcióit.
A jegyzetfüzetek által futtatott Python-kerékfájl logikai és egységtesztjeinek meghatározásához az adattár gyökerében hozzon létre két fájlt, addcol.py és test_addcol.pyadja hozzá őket egy python/dabdemo/dabdemo mappában elnevezett Libraries mappastruktúrához, az alábbiak szerint:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
A addcol.py fájl tartalmaz egy kódtárfüggvényt, amely később egy Python-kerékfájlba van beépítve, majd az Azure Databricks-fürtökre van telepítve. Ez egy egyszerű függvény, amely egy új, konstanssal kitöltött oszlopot ad hozzá egy Apache Spark DataFrame-hez:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
A test_addcol.py fájl olyan teszteket tartalmaz, amelyek egy DataFrame objektumot adnak át a with_status nevű függvénynek, amely a addcol.py-ban van definiálva. Ezt követően a rendszer összehasonlítja az eredményt egy DataFrame-objektummal, amely a várt értékeket tartalmazza. Ha az értékek egyeznek, a teszt a következőn megy át:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Annak érdekében, hogy a Databricks parancssori felülete megfelelően csomagolja be ezt a kódkönyvtárat egy Python-kerékfájlba, hozzon létre két fájlt a következő névvel: __init__.py és __main__.py ugyanabban a mappában, mint az előző két fájl. Emellett hozzon létre egy fájlt setup.py a python/dabdemo mappában, a következőképpen vizualizálva:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
A __init__.py fájl tartalmazza a kódtár verziószámát és szerzőjét. Cserélje le a <my-author-name> elemet a saját nevére:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
A __main__.py fájl tartalmazza a kódtár belépési pontját:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
A setup.py fájl további beállításokat tartalmaz a kódtár Python-kerékfájlba való létrehozásához. Cserélje le <my-url>a , <my-author-name>@<my-organization>és <my-package-description> az érvényes értékeket:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
1.2. lépés: Egységtesztelési jegyzetfüzet hozzáadása a Python-kerékfájlhoz
Később a Databricks parancssori felület egy jegyzetfüzet-feladatot futtat. Ez a feladat egy Python-jegyzetfüzetet futtat a következő fájlnévvel run_unit_tests.py: . Ez a jegyzetfüzet a Python-kerekes kódtár logikájával fut pytest .
A cikk példájához tartozó egységtesztek futtatásához adjon hozzá egy jegyzetfüzetfájlt az adattár gyökeréhez a következő tartalommal:run_unit_tests.py
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
1.3. lépés: A Python-kerékfájlt meghívó jegyzetfüzet hozzáadása
Később a Databricks parancssori felület egy másik jegyzetfüzet-feladatot futtat. Ez a jegyzetfüzet létrehoz egy DataFrame-objektumot, továbbítja azt a Python-kerekes kódtár függvényének with_status , kinyomtatja az eredményt, és jelentést készít a feladat futtatási eredményeiről. Hozza létre az adattár gyökerét a következő tartalommal elnevezett dabdemo_notebook.py jegyzetfüzetfájlban:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
1.4. lépés: A csomagkonfiguráció létrehozása
Ez a cikk a Databricks Asset Bundles használatával határozza meg a Python-kerékfájl, a két jegyzetfüzet és a Python-kódfájl létrehozásának, üzembe helyezésének és futtatásának beállításait és viselkedését. A Databricks Asset Bundles lehetővé teszi a teljes adat-, elemzési és ml-projektek forrásfájlok gyűjteményeként történő kifejezését. Lásd: Mik azok a Databricks-eszközcsomagok?.
A cikk példájához tartozó csomag konfigurálásához hozzon létre az adattár gyökerében egy fájlt, amelynek neve databricks.yml legyen. Ebben a példafájlban databricks.yml cserélje le az alábbi helyőrzőket:
- Cserélje le
<bundle-name>egy egyedi programozási névvel a csomag számára. Például:azure-devops-demo. - Cserélje le
<job-prefix-name>egy sztringre, hogy egyedileg azonosíthassa az Azure Databricks-munkaterületen létrehozott feladatokat ebben a példában. Például:azure-devops-demo. - Cserélje le a
<spark-version-id>-t a feladatfürtök Databricks Runtime verzióazonosítójára, például a13.3.x-scala2.12-re. - Cserélje le a
<cluster-node-type-id>értéket a feladatfürtök fürtcsomópont-típusazonosítójára, például aStandard_DS3_v2értékre. - Figyelje meg, hogy a
devleképezésben atargetsmeghatározza a gazdagépet és a kapcsolódó üzembe helyezési viselkedést. A valós implementációkban a célnak más nevet adhat a saját csomagjaiban.
A példafájl databricks.yml tartalma a következő:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
targets:
dev:
mode: development
A fájl szintaxisáról további információt a databricks.ymlDatabricks Asset Bundle konfigurációjában talál.
2. lépés: A buildelési folyamat meghatározása
Az Azure DevOps egy felhőalapú felhasználói felületet biztosít a CI/CD-folyamat szakaszainak YAML használatával történő meghatározásához. Az Azure DevOpsról és a folyamatokról az Azure DevOps dokumentációjában talál további információt.
Ebben a lépésben YAML-korrektúra használatával határozza meg a buildelési folyamatot, amely üzembehelyezési összetevőt hoz létre. Ha egy Azure Databricks-munkaterületen szeretné üzembe helyezni a kódot, a folyamat buildösszetevőjét adja meg bemenetként egy kiadási folyamatba. Ezt a kiadási folyamatot később definiálhatja.
A buildelési folyamatok futtatásához az Azure DevOps felhőalapú, igény szerinti végrehajtási ügynököket biztosít, amelyek támogatják a Kubernetes, a virtuális gépek, az Azure Functions, az Azure Web Apps és még sok más cél üzembe helyezését. Ebben a példában egy igény szerinti ügynökkel automatizálja a telepítési artefaktum építését.
A cikk példájának építési csővezetékét az alábbiak szerint definiálja:
Jelentkezzen be az Azure DevOpsba, majd kattintson a Bejelentkezési hivatkozásra az Azure DevOps-projekt megnyitásához.
Megjegyzés:
Ha az Azure Portal az Azure DevOps-projekt helyett jelenik meg, kattintson a További szolgáltatásokra > Az Azure DevOps-szervezetek > Saját Azure DevOps-szervezetek , majd nyissa meg az Azure DevOps-projektet.
Az oldalsávon kattintson a Csővezetékek elemre, majd a Csővezetékek menüben kattintson a Csővezetékek lehetőségre.
Kattintson az Új folyamat gombra, és kövesse a képernyőn megjelenő utasításokat. (Ha már rendelkezik folyamatokkal, kattintson a Folyamat létrehozása helyett.) Az utasítások végén megnyílik a folyamatszerkesztő. Itt definiálhatja a buildelési folyamat parancsfájlját a
azure-pipelines.ymlmegjelenő fájlban. Ha a folyamatszerkesztő nem látható az utasítások végén, válassza ki a buildelési folyamat nevét, majd kattintson a Szerkesztés gombra.A Git-ágválasztóval
 testre szabhatja a Git-adattár egyes ágainak buildelési folyamatát. A CI/CD ajánlott eljárása, hogy nem végez éles munkát közvetlenül az adattár ágában
testre szabhatja a Git-adattár egyes ágainak buildelési folyamatát. A CI/CD ajánlott eljárása, hogy nem végez éles munkát közvetlenül az adattár ágában main. Ez a példa feltételezi, hogy egy elnevezettreleaseág létezik az adattárban, amelyet ahelyettmainkell használni.
A
azure-pipelines.ymlbuildelési folyamat szkriptje alapértelmezés szerint a folyamathoz társított távoli Git-adattár gyökerében van tárolva.Írja felül a folyamat fájljának
azure-pipelines.ymlkezdő tartalmát az alábbi definícióval, majd kattintson a Mentés gombra.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
3. lépés: A kiadási folyamat meghatározása
A kiadási folyamat a buildfolyamat által létrehozott build-összetevőket telepíti egy Azure Databricks környezetbe. Ha az ebben a lépésben szereplő kiadási folyamatot elválasztja a buildelési folyamattól az előző lépésekben, lehetővé teszi, hogy üzembe helyezés nélkül hozzon létre egy buildet, vagy egyszerre több buildből telepítsen összetevőket.
Az Azure DevOps-projektben az oldalsáv Pipelines menüjében kattintson a Releases (Kiadások) elemre.
Kattintson az Új > kiadási folyamat létrehozása elemre. (Ha már vannak csővezetékei, kattintson az Új csővezeték gombra.)
A képernyő oldalán a gyakori üzembehelyezési minták kiemelt sablonjainak listája látható. Ebben a példában a kiadási folyamathoz kattintson a gombra
 .
.
A képernyő oldalán lévő Artifacts mezőben kattintson a
 gombra. A Hozzáadás egy elemhez panelen, a Forrás (build pipeline) részhez válassza ki a korábban létrehozott buildfolyamatot. Ezután kattintson az Add (Hozzáadás) gombra.
gombra. A Hozzáadás egy elemhez panelen, a Forrás (build pipeline) részhez válassza ki a korábban létrehozott buildfolyamatot. Ezután kattintson az Add (Hozzáadás) gombra.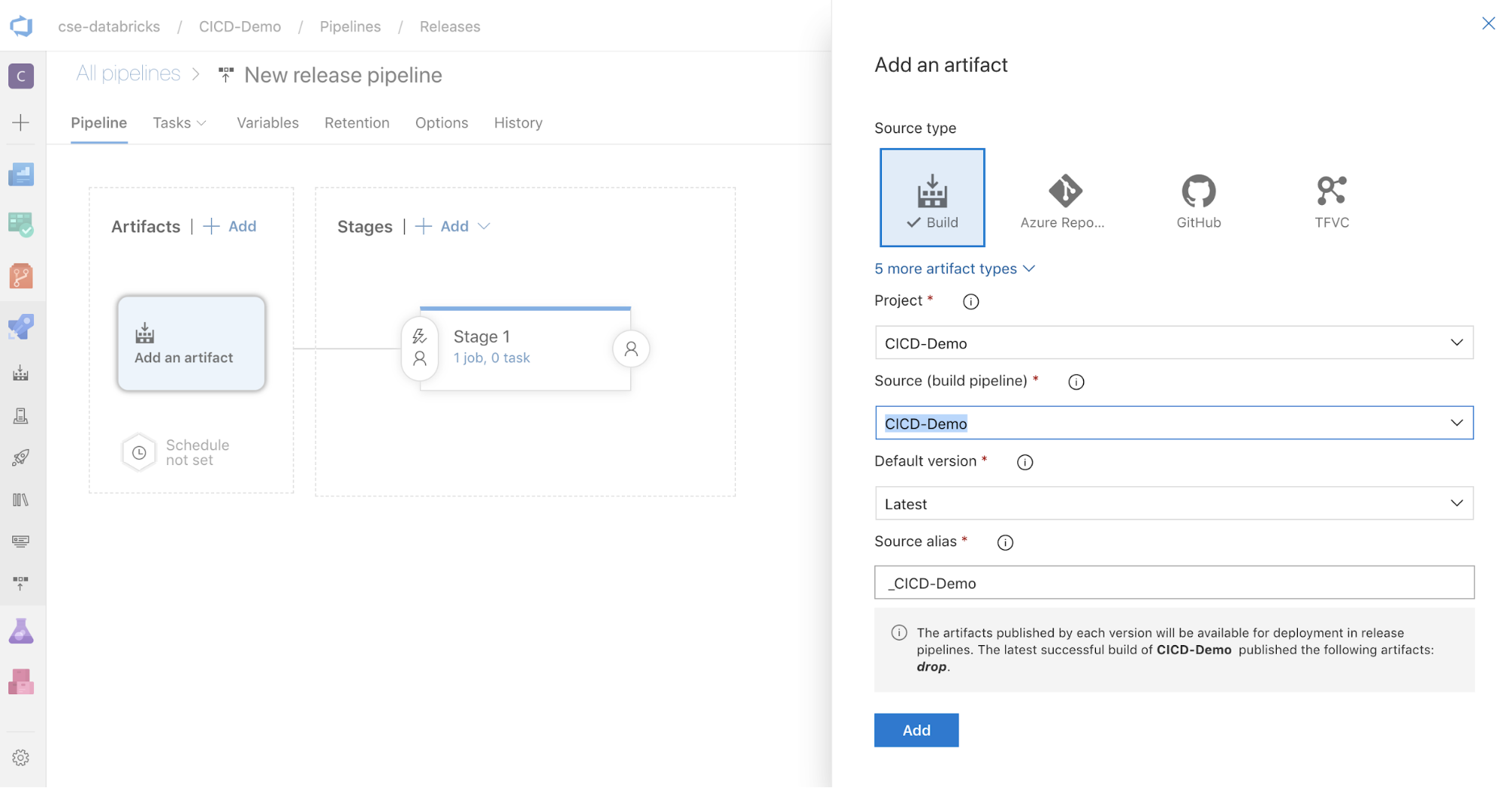
A folyamat aktiválásának módját úgy konfigurálhatja, hogy a
 kattintva a képernyő oldalán megjelenítse az aktiválási beállításokat. Ha azt szeretné, hogy a kiadás automatikusan elinduljon a buildösszetevő rendelkezésre állása vagy egy lekéréses kérelem munkafolyamata alapján, engedélyezze a megfelelő eseményindítót. Ebben a példában egyelőre a cikk utolsó lépésében manuálisan aktiválja a buildelési folyamatot, majd a kiadási folyamatot.
kattintva a képernyő oldalán megjelenítse az aktiválási beállításokat. Ha azt szeretné, hogy a kiadás automatikusan elinduljon a buildösszetevő rendelkezésre állása vagy egy lekéréses kérelem munkafolyamata alapján, engedélyezze a megfelelő eseményindítót. Ebben a példában egyelőre a cikk utolsó lépésében manuálisan aktiválja a buildelési folyamatot, majd a kiadási folyamatot.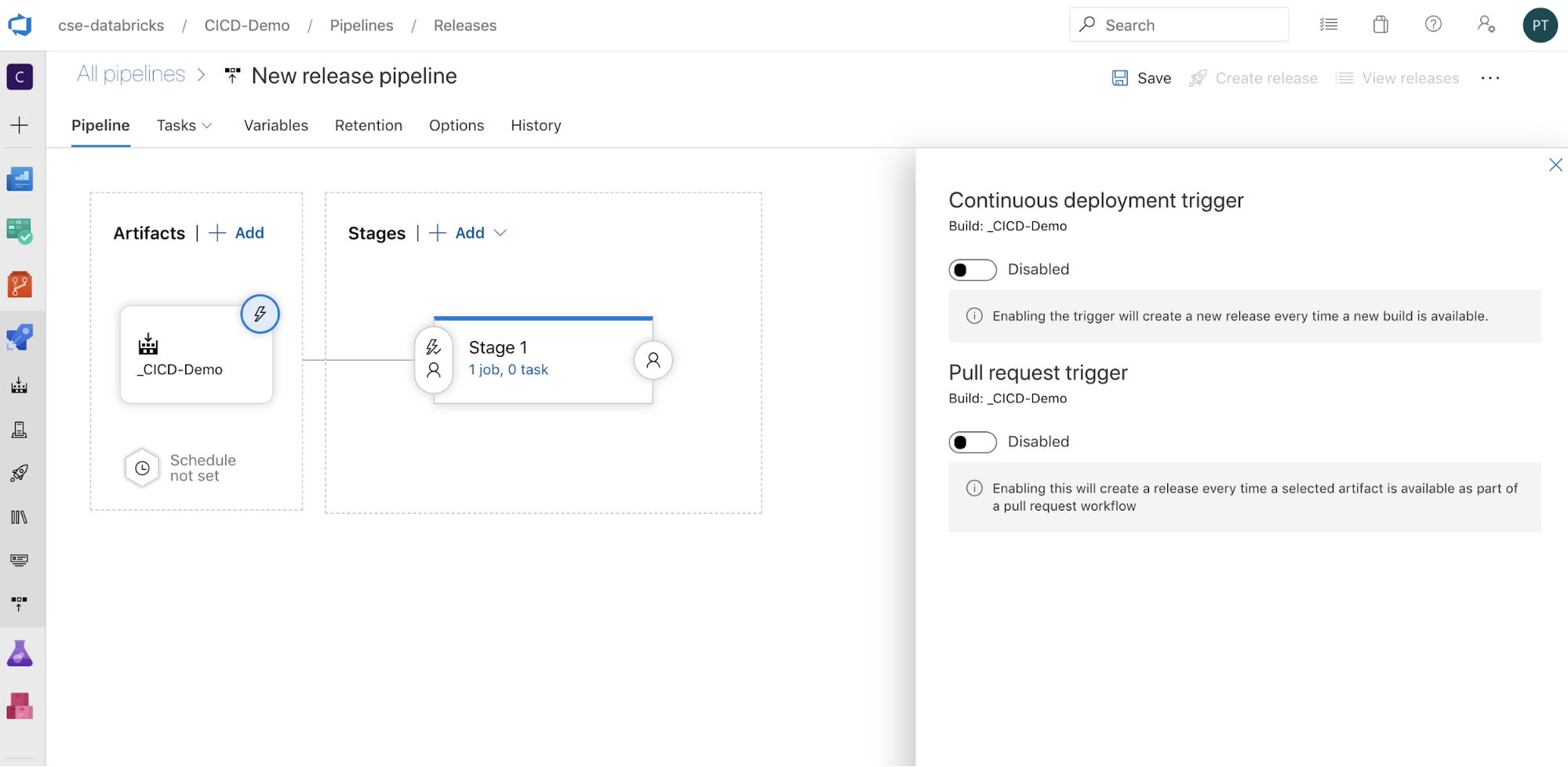
Kattintson a Mentés > OK-ra.
3.1. lépés: Környezeti változók definiálása a kiadási folyamathoz
A példa kiadási folyamata a következő környezeti változókra támaszkodik, amelyeket a Változók lap Folyamatváltozók szakaszában a Hozzáadás gombra kattintva adhat hozzá az 1. fázishatókörével:
-
BUNDLE_TARGET, amelynek meg kell egyeznie atargetdatabricks.ymlfájlban lévő névvel. A cikk példájában ezdev. -
DATABRICKS_HOST, amely az Azure Databricks-munkaterület munkaterületenkénti URL-címét jelöli, kezdve példáulhttps://a következővelhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net: . Ne tartalmazza a záró/elemet a.netután. -
DATABRICKS_CLIENT_ID, amely a Microsoft Entra ID szolgáltatásnév alkalmazásazonosítóját jelöli. -
DATABRICKS_CLIENT_SECRET, amely a Microsoft Entra ID szolgáltatásnév Azure Databricks OAuth-titkos kódját jelöli.
3.2. lépés: A kiadási folyamat kiadási ügynökének konfigurálása
Kattintson az 1. fázis objektumában található 1 feladat, 0 tevékenység hivatkozásra.
A Feladatok lapon kattintson az Ügynöki feladatra.
Az Ügynökválasztás szakaszban az Ügynökkészlet területen válassza az Azure Pipelines lehetőséget.
Az Ügynök specifikációja beállításnál válassza ki ugyanazt az ügynököt, mint korábban a buildügynökhöz, ebben a példában ubuntu-22.04.
Kattintson a Mentés > OK-ra.
3.3. lépés: A kiadási ügynök Python-verziójának beállítása
Kattintson a pluszjelre az Ügynökfeladat szakaszban, amelyet az alábbi ábrán látható piros nyíl jelez. Megjelenik az elérhető tevékenységek kereshető listája. A külső beépülő modulokhoz egy Marketplace-lap is tartozik, amely a szokásos Azure DevOps-feladatok kiegészítésére használható. A következő lépések során több feladatot fog hozzáadni a kiadási ügynökhöz.
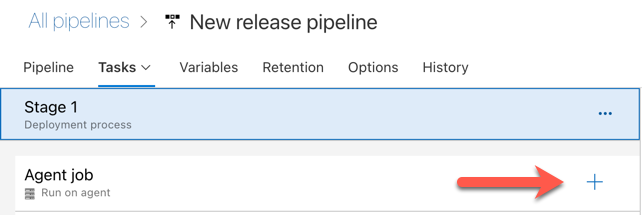
Az első hozzáadott feladat a Python-verzió használata, amely az Eszköz lapon található. Ha nem találja ezt a feladatot, a Keresőmezővel keresse meg. Ha megtalálta, jelölje ki, majd kattintson a Python-verzió használata feladat melletti Hozzáadás gombra.
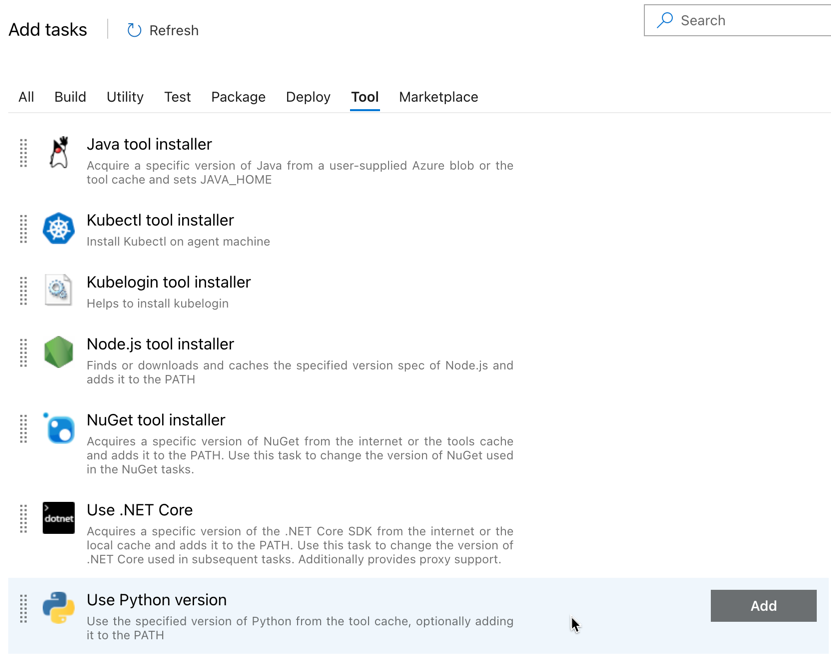
A buildelési folyamathoz hasonlóan meg kell győződnie arról, hogy a Python-verzió kompatibilis a későbbi feladatokban meghívott szkriptekkel. Ebben az esetben kattintson a Python 3.x használata feladatra az Agent job mellett, majd állítsa a Version spec értéket -ra. A Megjelenítendő név beállítását is állítsa be a következőre
Use Python 3.10: Ez a folyamat feltételezi, hogy a Databricks Runtime 13.3 LTS-t használja azon fürtökön, amelyeken telepítve van a Python 3.10.12.
Kattintson a Mentés > OK-ra.
3.4. lépés: A buildösszetevő kicsomagolása a buildelési folyamatból
Ezután a kiadási ügynök kinyerje a Python-kerékfájlt, a kapcsolódó kiadási beállítások fájljait, a jegyzetfüzeteket és a Python-kódfájlt a zip-fájlból a Fájlok kinyerése feladat használatával: kattintson a pluszjelre az Ügynökfeladat szakaszban, válassza ki a Fájlok kinyerése feladatot a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Kattintson az Ügynökfeladat melletti Fájlok kinyerése feladatra, állítsa be az archív fájlmintákat
**/*.zip, és állítsa a Cél mappát a rendszerváltozóra$(Release.PrimaryArtifactSourceAlias)/Databricks. A Megjelenítendő név beállítását is állítsa be a következőreExtract build pipeline artifact:Megjegyzés:
$(Release.PrimaryArtifactSourceAlias)Egy Azure DevOps által létrehozott aliast jelöl, amely azonosítja például a kiadási ügynök_<your-github-alias>.<your-github-repo-name>elsődleges összetevőforrásának helyét. A kiadási folyamat ezt az értéket környezeti változókéntRELEASE_PRIMARYARTIFACTSOURCEALIASállítja be a kiadási ügynök Inicializálási feladat fázisában. Lásd a klasszikus kiadási és összetevő-változókat.Állítsa be a megjelenítési nevet a következőre:
Extract build pipeline artifact.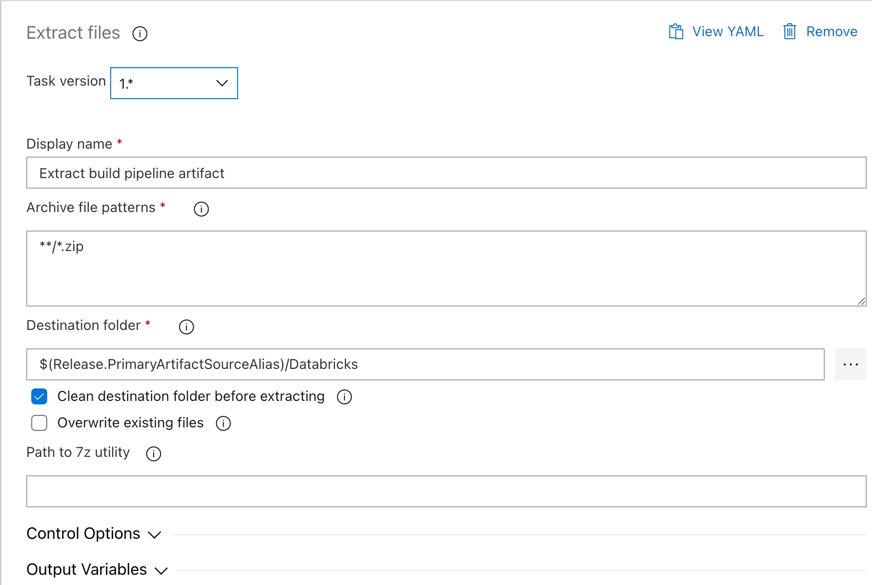
Kattintson a Mentés > OK-ra.
3.5. lépés: A BUNDLE_ROOT környezeti változó beállítása
Ahhoz, hogy a cikk a várt módon működjön, be kell állítania egy, a kiadási folyamatban elnevezett BUNDLE_ROOT környezeti változót. A Databricks Asset Bundles ezzel a környezeti változóval határozza meg a databricks.yml fájl helyét. A környezeti változó beállítása:
Használja a Környezeti változók feladatot: kattintson ismét a pluszjelre az Ügynök feladat szakaszban, válassza ki a Környezeti változók tevékenységet a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Megjegyzés:
Ha a Környezeti változók tevékenység nem látható a Segédprogram lapon, írja be
Environment Variablesa Keresőmezőbe , és a képernyőn megjelenő utasításokat követve adja hozzá a feladatot a Segédprogram laphoz. Ehhez el kell hagynia az Azure DevOpsot, majd vissza kell térnie arra a helyre, ahol abbahagyta.Környezeti változók (vesszővel elválasztva) esetén adja meg a következő definíciót:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Megjegyzés:
$(Agent.ReleaseDirectory)Egy Azure DevOps által létrehozott aliast jelöl, amely azonosítja például a kiadási ügynök/home/vsts/work/r1/akiadási könyvtárának helyét. A kiadási folyamat ezt az értéket környezeti változókéntAGENT_RELEASEDIRECTORYállítja be a kiadási ügynök Inicializálási feladat fázisában. Lásd a klasszikus kiadási és összetevő-változókat. A$(Release.PrimaryArtifactSourceAlias)információkért lásd az előző lépés megjegyzését.Állítsa be a megjelenítési nevet a következőre:
Set BUNDLE_ROOT environment variable.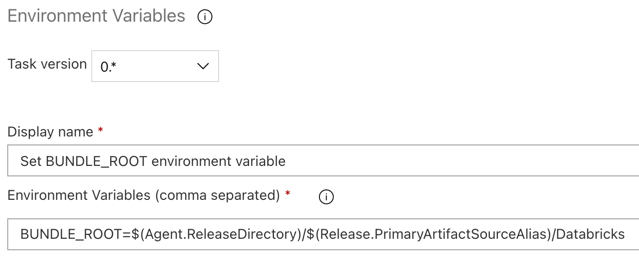
Kattintson a Mentés > OK-ra.
3.6. lépés. A Databricks CLI és a Python keréképítési eszközeinek telepítése
Ezután telepítse a Databricks CLI-t és a Python wheel készítő eszközöket a kiadáskezelő ügynökre. A kiadási ügynök a következő néhány feladatban meghívja a Databricks CLI- és Python-keréképítési eszközöket. Ehhez használja a Bash-feladatot: kattintson ismét a pluszjelre az Ügynökfeladat szakaszban, válassza ki a Bash-feladatot a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Kattintson a Bash-szkript feladatra az Ügynökfeladat mellett.
A Típus beállításnál válassza a Beágyazott elemet.
Cserélje le a Script tartalmát a következő parancsra, amely telepíti a Databricks CLI és a Python keréképítő eszközöket:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelÁllítsa be a megjelenítési nevet a következőre:
Install Databricks CLI and Python wheel build tools.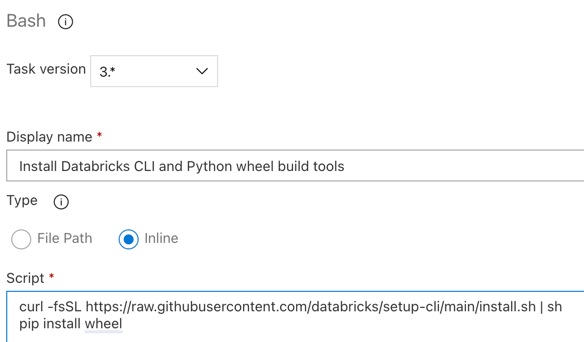
Kattintson a Mentés > OK-ra.
3.7. lépés: A Databricks-eszközcsomag ellenőrzése
Ebben a lépésben győződjön meg arról, hogy a databricks.yml fájl szintaktikailag helyes.
Használja a Bash-feladatot: kattintson ismét a pluszjelre az Ügynökfeladat szakaszban, válassza a Bash-feladatot a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Kattintson a Bash-szkript feladatra az Ügynökfeladat mellett.
A Típus beállításnál válassza a Beágyazott elemet.
Cserélje le a szkript tartalmát a következő parancsra, amely a Databricks parancssori felületével ellenőrzi, hogy a
databricks.ymlfájl szintaktikailag helyes-e:databricks bundle validate -t $(BUNDLE_TARGET)Állítsa be a megjelenítési nevet a következőre:
Validate bundle.Kattintson a Mentés > OK-ra.
3.8. lépés: A csomag üzembe helyezése
Ebben a lépésben létrehozza a Python-kerékfájlt, és üzembe helyezi a beépített Python-kerékfájlt, a két Python-jegyzetfüzetet és a Python-fájlt a kiadási folyamatból az Azure Databricks-munkaterületre.
Használja a Bash-feladatot: kattintson ismét a pluszjelre az Ügynökfeladat szakaszban, válassza a Bash-feladatot a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Kattintson a Bash-szkript feladatra az Ügynökfeladat mellett.
A Típus beállításnál válassza a Beágyazott elemet.
Cserélje le a szkript tartalmát a következő parancsra, amely a Databricks parancssori felületével hozza létre a Python-kerékfájlt, és helyezze üzembe a cikk példafájljait a kiadási folyamatból az Azure Databricks-munkaterületre:
databricks bundle deploy -t $(BUNDLE_TARGET)Állítsa be a megjelenítési nevet a következőre:
Deploy bundle.Kattintson a Mentés > OK-ra.
3.9. lépés: A Python-kerék egységteszt-jegyzetfüzetének futtatása
Ebben a lépésben futtat egy feladatot, amely az egységteszt-jegyzetfüzetet futtatja az Azure Databricks-munkaterületen. Ez a jegyzetfüzet egységteszteket futtat a Python wheel könyvtár logikájával.
Használja a Bash-feladatot: kattintson ismét a pluszjelre az Ügynökfeladat szakaszban, válassza a Bash-feladatot a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Kattintson a Bash-szkript feladatra az Ügynökfeladat mellett.
A Típus beállításnál válassza a Beágyazott elemet.
Cserélje le a szkript tartalmát a következő parancsra, amely a Databricks parancssori felülettel futtatja a feladatot az Azure Databricks-munkaterületen:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsÁllítsa be a megjelenítési nevet a következőre:
Run unit tests.Kattintson a Mentés > OK-ra.
3.10. lépés: A Python-kereket hívó jegyzetfüzet futtatása
Ebben a lépésben egy olyan feladatot futtat, amely egy másik jegyzetfüzetet futtat az Azure Databricks-munkaterületen. Ez a jegyzetfüzet meghívja a Python-kerekes kódtárat.
Használja a Bash-feladatot: kattintson ismét a pluszjelre az Ügynökfeladat szakaszban, válassza a Bash-feladatot a Segédprogram lapon, majd kattintson a Hozzáadás gombra.
Kattintson a Bash-szkript feladatra az Ügynökfeladat mellett.
A Típus beállításnál válassza a Beágyazott elemet.
Cserélje le a szkript tartalmát a következő parancsra, amely a Databricks parancssori felülettel futtatja a feladatot az Azure Databricks-munkaterületen:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookÁllítsa be a megjelenítési nevet a következőre:
Run notebook.Kattintson a Mentés > OK-ra.
Ezzel befejezte a kiadási folyamat konfigurálását. Ennek a következőképpen kell kinéznie:
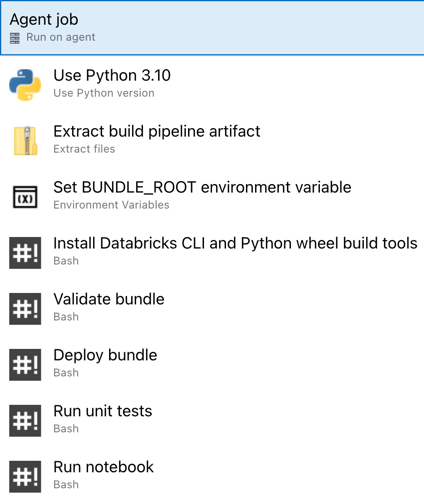
4. lépés: A buildelési és kiadási folyamatok futtatása
Ebben a lépésben manuálisan futtatja a csővezetékeket. A folyamatok automatikus futtatásának módjáról további információt a folyamatokat kiváltó események megadása és a kiadási eseményindítók című témakörben talál.
A buildelési folyamat manuális futtatása:
- Az oldalsáv Folyamatok menüjében kattintson a Folyamatok elemre.
- Kattintson a build folyamat nevére, majd a Pipeline futtatása parancsra.
- Ág/címke esetén válassza ki annak az ágnak a nevét a Git-adattárban, amely tartalmazza az összes hozzáadott forráskódot. Ez a példa feltételezi, hogy ez az
releaseágban van. - Kattintson a Futtatás gombra. Megjelenik a buildelési folyamat futtatási oldala.
- A buildelési folyamat előrehaladásának megtekintéséhez és a kapcsolódó naplók megtekintéséhez kattintson a Feladat melletti forgó ikonra.
- Miután a Feladat ikon zöld pipára vált, futtassa a kiadási folyamatot.
A kiadási folyamat manuális futtatása:
- Miután a buildelési folyamat sikeresen lefutott, az oldalsáv Folyamatok menüjében kattintson a Kiadások elemre.
- Kattintson a kiadási folyamat nevére, majd a Kiadás létrehozása parancsra.
- Kattintson a Létrehozás gombra.
- A kiadási folyamat előrehaladásának megtekintéséhez kattintson a legújabb kiadás nevére a kiadások listájában.
- A Szakaszok mezőben kattintson a Szakasz 1-re, majd kattintson a Naplók elemre.