CI/CD és Jenkins az Azure Databricksen
Feljegyzés
Ez a cikk a Jenkinst ismerteti, amelyet a Databricks nem biztosít és nem támogat. A szolgáltatóval való kapcsolatfelvételhez tekintse meg a Jenkins súgóját.
A CI/CD-folyamatok kezeléséhez és futtatásához számos CI/CD-eszköz használható. Ez a cikk bemutatja, hogyan használható a Jenkins automation-kiszolgáló. A CI/CD egy tervezési minta, ezért a cikkben ismertetett lépéseknek és szakaszoknak az egyes eszközök folyamatdefiníciós nyelvére kell átvinni néhány módosítást. A példában szereplő kód nagy része szabványos Python-kódot futtat, amelyet más eszközökben is meghívhat. Az Azure Databricks ci/CD-jének áttekintéséért lásd : Mi az a CI/CD az Azure Databricksben?.
Az Azure DevOps és az Azure Databricks használatával történő használatáról további információt az Azure Databricks folyamatos integrációja és kézbesítése az Azure DevOps használatával című témakörben talál.
CI/CD fejlesztési munkafolyamat
A Databricks a következő munkafolyamatot javasolja a CI/CD-fejlesztéshez a Jenkinsszel:
- Hozzon létre egy adattárat, vagy használjon egy meglévő adattárat a külső Git-szolgáltatóval.
- Csatlakoztassa a helyi fejlesztőgépet ugyanahhoz a külső adattárhoz. Útmutatásért tekintse meg a külső Git-szolgáltató dokumentációját.
- Lekérheti a meglévő frissített összetevőket (például jegyzetfüzeteket, kódfájlokat és buildszkripteket) a külső adattárból a helyi fejlesztői gépre.
- Igény szerint hozzon létre, frissítse és tesztelje az összetevőket a helyi fejlesztőgépen. Ezután leküldheti az új és módosított összetevőket a helyi fejlesztőgépről a külső adattárba. Útmutatásért tekintse meg a külső Git-szolgáltató documens szolgáltatását.
- Szükség szerint ismételje meg a 3. és a 4. lépést.
- A Jenkins rendszeres használatával integrált megközelítésként automatikusan leküldheti az összetevőket a külső adattárból a helyi fejlesztői gépre vagy az Azure Databricks-munkaterületre; kód létrehozása, tesztelése és futtatása a helyi fejlesztőgépen vagy az Azure Databricks-munkaterületen; és jelentéskészítési teszt és futtatási eredmények. Bár manuálisan is futtathatja a Jenkinst, a valós implementációkban arra utasítaná a külső Git-szolgáltatót, hogy minden alkalommal futtassa a Jenkinst, amikor egy adott esemény történik, például egy adattár lekéréses kérése.
A cikk további része egy példaprojektet használ az előző CI/CD-fejlesztési munkafolyamat implementálásához használt Jenkins egyik módjának leírására.
További információ az Azure DevOps Jenkins helyett való használatáról: Folyamatos integráció és teljesítés az Azure Databricksen az Azure DevOps használatával.
Helyi fejlesztőgép beállítása
A cikk példája a Jenkins használatával utasítja a Databricks parancssori felületét és a Databricks-eszközcsomagokat a következők végrehajtására:
- Hozzon létre egy Python-kerekes fájlt a helyi fejlesztőgépen.
- Helyezze üzembe a beépített Python-kerekes fájlt, valamint további Python-fájlokat és Python-jegyzetfüzeteket a helyi fejlesztőgépről egy Azure Databricks-munkaterületre.
- Tesztelje és futtassa a feltöltött Python-kerékfájlokat és jegyzetfüzeteket a munkaterületen.
Ha úgy szeretné beállítani a helyi fejlesztőgépet, hogy utasítsa az Azure Databricks-munkaterületet a példa buildelési és feltöltési fázisainak végrehajtására, tegye a következőket a helyi fejlesztőgépen:
1. lépés: A szükséges eszközök telepítése
Ebben a lépésben telepíti a Databricks CLI, a Jenkins jqés a Python-kerék buildelési eszközeit a helyi fejlesztőgépre. A példa futtatásához ezekre az eszközökre van szükség.
Ha még nem tette meg, telepítse a Databricks CLI 0.205-ös vagy újabb verzióját. A Jenkins a Databricks parancssori felületével továbbítja a példa tesztjét, és utasításokat futtat a munkaterületen. Lásd: A Databricks parancssori felület telepítése vagy frissítése.
Ha még nem tette meg, telepítse és indítsa el a Jenkinst. Lásd: A Jenkins telepítése Linuxhoz, macOS-hez vagy Windowshoz.
Telepítse a jq-t. Ez a példa néhány JSON-formátumú parancs kimenetének elemzésére használ
jq.A
pipPython-kerék buildelési eszközeinek telepítéséhez használja a következő parancsot (egyes rendszereknél a következők helyett használhatjapipapip3következőket):pip install --upgrade wheel
2. lépés: Jenkins-folyamat létrehozása
Ebben a lépésben a Jenkins használatával hoz létre egy Jenkins-folyamatot a cikk példájához. A Jenkins néhány különböző projekttípust biztosít a CI/CD-folyamatok létrehozásához. A Jenkins Pipelines felületet biztosít a Jenkins-folyamat szakaszainak meghatározásához a Jenkins-beépülő modulok meghívásához és konfigurálásához Groovy-kód használatával.
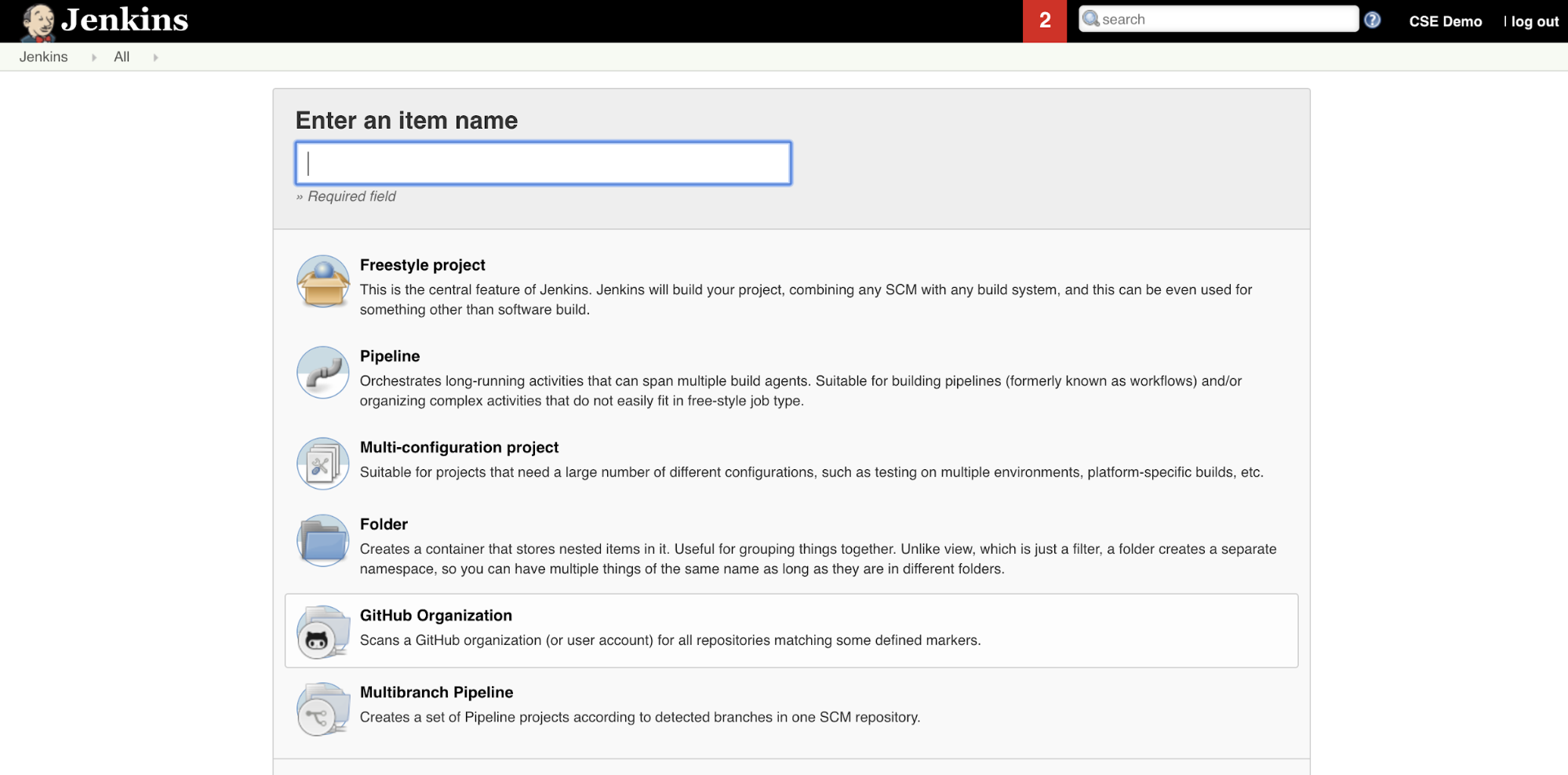
A Jenkins-folyamat létrehozása a Jenkinsben:
- A Jenkins indítása után a Jenkins-irányítópulton kattintson az Új elem elemre.
- Az Elemnév megadása mezőbe írja be például
jenkins-demoa Jenkins-folyamat nevét. - Kattintson a Folyamat projekttípus ikonra.
- Kattintson az OK gombra. Megjelenik a Jenkins-folyamat Konfigurálás lapja.
- A Folyamat területen, a Defintion legördülő listában válassza a Pipeline script from SCM (Folyamatszkript az SCM-ből) lehetőséget.
- Az SCM legördülő listában válassza a Git lehetőséget.
- Adattár URL-címeként írja be a harmadik részes Git-szolgáltató által üzemeltetett adattár URL-címét.
- A Branch Specifier mezőbe írja be
*/<branch-name>, hogy hol<branch-name>található például a használni*/mainkívánt ág neve az adattárban. - A Szkript elérési útja mezőbe írja be
Jenkinsfile, ha még nincs beállítva. A cikk későbbi részét ön hozza létreJenkinsfile. - Törölje a jelölést az Egyszerűsített kivétel jelölőnégyzetből, ha már be van jelölve.
- Kattintson a Mentés gombra.
3. lépés: Globális környezeti változók hozzáadása a Jenkinshez
Ebben a lépésben három globális környezeti változót ad hozzá a Jenkinshez. A Jenkins átadja ezeket a környezeti változókat a Databricks parancssori felületének. A Databricks cli-nek szüksége van a környezeti változók értékeire az Azure Databricks-munkaterületen való hitelesítéshez. Ez a példa OAuth machine-to-machine (M2M) hitelesítést használ egy szolgáltatásnévhez (bár más hitelesítési típusok is elérhetők). Ha OAuth M2M-hitelesítést szeretne beállítani az Azure Databricks-munkaterülethez, olvassa el az Azure Databrickshez való hozzáférés hitelesítése szolgáltatásnévvel az OAuth (OAuth M2M) használatával című témakört.
A példában szereplő három globális környezeti változó a következő:
DATABRICKS_HOST, állítsa be az Azure Databricks-munkaterület URL-címét, kezdve a következővelhttps://: . Lásd: Munkaterület-példányok nevei, URL-címei és azonosítói.DATABRICKS_CLIENT_ID, állítsa be a szolgáltatásnév ügyfél-azonosítójára, más néven az alkalmazásazonosítójára.DATABRICKS_CLIENT_SECRET, állítsa be a szolgáltatásnév Azure Databricks OAuth-titkos kódjára.
Globális környezeti változók Jenkinsben való beállításához a Jenkins-irányítópulton:
- Az oldalsávon kattintson a Jenkins kezelése elemre.
- A Rendszerkonfiguráció szakaszban kattintson a Rendszer elemre.
- A Globális tulajdonságok szakaszban jelölje be a csempézett környezeti változók jelölőnégyzetét.
- Kattintson a Hozzáadás gombra, majd adja meg a környezeti változó nevét és értékét. Ismételje meg ezt minden további környezeti változó esetében.
- Ha befejezte a környezeti változók hozzáadását, a Mentés gombra kattintva visszatérhet a Jenkins-irányítópultra.
A Jenkins-folyamat tervezése
A Jenkins néhány különböző projekttípust biztosít a CI/CD-folyamatok létrehozásához. Ez a példa egy Jenkins-folyamatot implementál. A Jenkins Pipelines felületet biztosít a Jenkins-folyamat szakaszainak meghatározásához a Jenkins-beépülő modulok meghívásához és konfigurálásához Groovy-kód használatával.
Jenkins-folyamatdefiníciót ír egy Jenkinsfile nevű szövegfájlba, amely viszont be van jelölve egy projekt forrásvezérlő adattárába. További információ: Jenkins Pipeline. Íme a jenkinsi folyamat a cikk példájához. Ebben a példában Jenkinsfilecserélje le a következő helyőrzőket:
- Cserélje le és
<repo-name>írja be<user-name>a harmadik részes Git-szolgáltató által üzemeltetett felhasználónevét és adattárnevét. Ez a cikk egy GitHub-URL-címet használ példaként. - Cserélje le
<release-branch-name>a kiadási ág nevére az adattárban. Ez lehetmainpéldául . - Cserélje le
<databricks-cli-installation-path>azt az elérési utat a helyi fejlesztőgépen, amelyen telepítve van a Databricks parancssori felület. Például macOS rendszeren ez lehet/usr/local/bin. - Cserélje le
<jq-installation-path>a helyi fejlesztőgép elérési útjára, aholjqtelepítve van. Például macOS rendszeren ez lehet/usr/local/bin. - Cserélje le
<job-prefix-name>egy sztringre, hogy egyedileg azonosíthassa a példához a munkaterületen létrehozott Azure Databricks-feladatokat. Ez lehetjenkins-demopéldául . - Figyelje meg, hogy
BUNDLETARGETadevdatabricks asset bundle cél neve, amely a jelen cikk későbbi részében van definiálva. A valós implementációkban ezt a saját csomagcél nevére változtatná. A csomagcélokról a cikk későbbi részében olvashat bővebben.
A következőt Jenkinsfilekell hozzáadnia az adattár gyökeréhez:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
A cikk további része ismerteti a Jenkins-folyamat egyes szakaszait, valamint azt, hogy miként állíthatja be a Jenkinshez tartozó összetevőket és parancsokat az adott szakaszban való futtatáshoz.
A legújabb összetevők lekérése a külső adattárból
A Jenkins-folyamat első szakasza, a Checkout fázis a következőképpen van definiálva:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Ez a szakasz gondoskodik arról, hogy a Jenkins által a helyi fejlesztőgépen használt munkakönyvtár a külső Git-adattár legújabb összetevőit használja. A Jenkins ezt a munkakönyvtárat általában a következőre <your-user-home-directory>/.jenkins/workspace/<pipeline-name>állítja be: . Ez lehetővé teszi, hogy ugyanazon a helyi fejlesztőgépen a fejlesztés alatt álló összetevők saját másolatát elkülönítse a Jenkins által a külső Git-adattártól használt összetevőktől.
A Databricks-eszközcsomag ellenőrzése
A Jenkins-folyamat második szakasza, a Validate Bundle fázis a következőképpen van definiálva:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Ez a szakasz biztosítja, hogy az összetevők teszteléséhez és futtatásához szükséges munkafolyamatokat meghatározó Databricks-eszközcsomag szintaktikailag helyes legyen. A Databricks Asset Bundles, más néven kötegek lehetővé teszik a teljes adatok, elemzések és ml-projektek forrásfájlok gyűjteményeként való kifejezését. Lásd: Mik azok a Databricks-eszközcsomagok?.
A cikk kötegének meghatározásához hozzon létre egy fájlt databricks.yml a helyi számítógépen a klónozott adattár gyökerében. Ebben a példafájlban databricks.yml cserélje le a következő helyőrzőket:
- Cserélje le
<bundle-name>a köteg egyedi programozott nevére. Ez lehetjenkins-demopéldául . - Cserélje le
<job-prefix-name>egy sztringre, hogy egyedileg azonosíthassa a példához a munkaterületen létrehozott Azure Databricks-feladatokat. Ez lehetjenkins-demopéldául . Ennek meg kell egyeznie aJOBPREFIXJenkinsfile értékével. - Cserélje le
<spark-version-id>például a Feladatfürtök13.3.x-scala2.12Databricks Runtime verzióazonosítóját. - Cserélje le
<cluster-node-type-id>például a feladatfürtökStandard_DS3_v2csomóponttípus-azonosítóját. - Figyelje meg, hogy
devatargetsleképezésben ugyanaz található, mint aBUNDLETARGETJenkinsfile-ban. A csomagcél határozza meg a gazdagépet és a kapcsolódó üzembe helyezési viselkedést.
Itt látható a databricks.yml fájl, amelyet hozzá kell adni az adattár gyökeréhez, hogy a példa megfelelően működjön:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
A fájlról további információt a databricks.yml Databricks Eszközcsomag konfigurációja című témakörben talál.
A csomag üzembe helyezése a munkaterületen
A Jenkins-folyamat harmadik szakasza a következőképpen van definiálva Deploy Bundle:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Ez a szakasz két dolgot tesz:
- Mivel a
artifactdatabricks.ymlfájl leképezése be van állítvawhl, ez arra utasítja a Databricks parancssori felületét, hogy hozza létre a Python-kerékfájlt asetup.pymegadott helyen található fájl használatával. - Miután a Python-kerékfájl a helyi fejlesztőgépre épült, a Databricks CLI üzembe helyezi a beépített Python-kerekfájlt a megadott Python-fájlokkal és jegyzetfüzetekkel együtt az Azure Databricks-munkaterületen. Alapértelmezés szerint a Databricks Asset Bundles üzembe helyezi a Python-kerékfájlt és más fájlokat.
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>
Ha engedélyezni szeretné a Python-kerékfájl létrehozását a databricks.yml fájlban megadott módon, hozza létre a következő mappákat és fájlokat a klónozott adattár gyökerében a helyi gépen.
A jegyzetfüzet által futtatandó Python-kerékfájl logikájának és egységtesztjeinek meghatározásához hozzon létre két fájlt, addcol.py és test_addcol.pyadja hozzá őket az adattár mappájában Libraries elnevezett python/dabdemo/dabdemo mappastruktúrához az alábbiak szerint (a három pont a kihagyott mappákat jelzi az adattárban, a rövidítés érdekében):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
A addcol.py fájl tartalmaz egy kódtárfüggvényt, amely később egy Python-kerékfájlba van beépítve, majd egy Azure Databricks-fürtre van telepítve. Ez egy egyszerű függvény, amely egy új, konstanssal kitöltött oszlopot ad hozzá egy Apache Spark DataFrame-hez:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
A test_addcol.py fájl olyan teszteket tartalmaz, hogy átadjon egy dataFrame-objektumot a függvénynek, amely a with_status következőben van definiálva addcol.py: . Ezt követően a rendszer összehasonlítja az eredményt egy DataFrame-objektummal, amely a várt értékeket tartalmazza. Ha az értékek egyeznek, ami ebben az esetben történik, a teszt a következőt hajtja végre:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Ha engedélyezni szeretné a Databricks parancssori felületének, hogy megfelelően csomagolja be ezt a kódtárkódot egy Python-kerékfájlba, hozzon létre két fájlt __init__.py , amelyek neve és __main__.py ugyanabban a mappában van, mint az előző két fájl. Emellett hozzon létre egy fájlt setup.py a python/dabdemo mappában, a következőképpen vizualizálva (a három pont a kihagyott mappákat jelöli a rövidítéshez):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
A __init__.py fájl tartalmazza a kódtár verziószámát és szerzőjét. Cserélje le <my-author-name> a nevét:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
A __main__.py fájl tartalmazza a kódtár belépési pontját:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
A setup.py fájl további beállításokat tartalmaz a kódtár Python-kerékfájlba való létrehozásához. Cserélje le <my-url>a , <my-author-name>@<my-organization>és <my-package-description> a hasznos értékeket:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
A Python-kerék összetevőlogikája tesztelése
A Run Unit Tests Jenkins-folyamat negyedik szakasza a kódtár logikájának tesztelésével ellenőrzi, pytest hogy a folyamat megfelelően működik-e. Ez a szakasz a következőképpen van definiálva:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Ez a szakasz a Databricks parancssori felületét használja egy jegyzetfüzet-feladat futtatásához. Ez a feladat a Python-jegyzetfüzetet a következő fájlnévvel futtatja run-unit-test.py: . Ez a jegyzetfüzet a kódtár logikájával fut pytest .
A példához tartozó egységtesztek futtatásához adjon hozzá egy Python-jegyzetfüzetfájlt run_unit_tests.py a következő tartalommal a klónozott adattár gyökeréhez a helyi gépen:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
A beépített Python-kerék használata
Ennek a Jenkins-folyamatnak az ötödik szakasza egy Python-jegyzetfüzetet futtat, Run Notebookamely meghívja a logikát a beépített Python-kerékfájlban az alábbiak szerint:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Ez a szakasz a Databricks parancssori felületét futtatja, amely viszont arra utasítja a munkaterületet, hogy futtasson egy jegyzetfüzet-feladatot. Ez a jegyzetfüzet létrehoz egy DataFrame-objektumot, továbbítja azt a tár függvényének with_status , kinyomtatja az eredményt, és jelentést készít a feladat futtatási eredményeiről. Hozza létre a jegyzetfüzetet úgy, hogy hozzáad egy Python-jegyzetfüzetfájlt, amelynek neve a következő tartalommal van elnevezve dabdaddemo_notebook.py a klónozott adattár gyökerében a helyi fejlesztőgépen:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Jegyzetfüzet-feladat futtatási eredményeinek kiértékelése
A Evaluate Notebook Runs Jenkins-folyamat hatodik szakasza kiértékeli az előző jegyzetfüzet-feladatfuttatás eredményeit. Ez a szakasz a következőképpen van definiálva:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Ez a szakasz a Databricks parancssori felületét futtatja, amely viszont arra utasítja a munkaterületet, hogy futtasson egy Python-fájlfeladatot. Ez a Python-fájl határozza meg a jegyzetfüzet-feladat futtatásának sikertelenségét és sikerességi feltételeit, és jelenti ezt a hibát vagy sikert. Hozzon létre egy fájlt evaluate_notebook_runs.py a következő tartalommal a klónozott adattár gyökerében a helyi fejlesztőgépen:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Teszteredmények importálása és jelentése
Ennek a Jenkins-folyamatnak a hetedik szakasza a Import Test ResultsDatabricks parancssori felülettel küldi el a teszteredményeket a munkaterületről a helyi fejlesztői gépre. A nyolcadik és egyben utolsó szakasz a Publish Test ResultsJenkins beépülő modullal teszi közzé a teszteredményeket a junit Jenkinsben. Ez lehetővé teszi a teszteredmények állapotával kapcsolatos jelentések és irányítópultok vizualizációját. Ezek a szakaszok a következőképpen vannak definiálva:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Az összes kódmódosítás leküldése a külső adattárba
Most le kell küldenie a klónozott adattár tartalmát a helyi fejlesztőgépen a külső adattárba. A leküldés előtt először adja hozzá a következő bejegyzéseket a .gitignore klónozott adattárban lévő fájlhoz, mivel valószínűleg nem szabad belső Databricks Asset Bundle munkafájlokat, érvényesítési jelentéseket, Python-buildfájlokat és Python-gyorsítótárakat leküldnie a külső adattárba. Az Azure Databricks-munkaterületen általában az új érvényesítési jelentéseket és a legutóbbi Python-kerekes buildeket szeretné újragenerálni ahelyett, hogy esetleg elavult érvényesítési jelentéseket és Python-kerekeket használna:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
A Jenkins-folyamat futtatása
Most már készen áll a Jenkins-folyamat manuális futtatására. Ehhez használja a Jenkins-irányítópultot:
- Kattintson a Jenkins-folyamat nevére.
- Az oldalsávon kattintson a Build Now gombra.
- Az eredmények megtekintéséhez kattintson a legújabb folyamatfuttatásra (például
#1), majd a Konzolkimenet parancsra.
Ezen a ponton a CI/CD-folyamat egy integrációs és üzembe helyezési ciklust hajtott végre. A folyamat automatizálásával biztosíthatja, hogy a kódot egy hatékony, konzisztens és megismételhető folyamat tesztelje és üzembe helyezte. Ha arra szeretné utasítani a külső Git-szolgáltatót, hogy minden alkalommal futtassa a Jenkinst, amikor egy adott esemény történik, például egy adattárbeli lekéréses kérelem, tekintse meg a külső Git-szolgáltató dokumentációját.