Jegyzet
Az oldalhoz való hozzáférés engedélyezést igényel. Próbálhatod be jelentkezni vagy könyvtárat váltani.
Az oldalhoz való hozzáférés engedélyezést igényel. Megpróbálhatod a könyvtár váltását.
Ez az oktatóanyag bemutatja, hogyan kezdheti meg a Databricks Connect for Scala használatát az IntelliJ IDEA és a Scala beépülő modul használatával.
Ebben az oktatóanyagban létrehoz egy projektet az IntelliJ IDEA-ban, telepíti a Databricks Connect for Databricks Runtime 13.3 LTS-t vagy újabb verziót, és egyszerű kódot futtat a Databricks-munkaterületen az IntelliJ IDEA-ból.
Jótanács
Ha tudni szeretné, hogyan hozhat létre a Databricks-eszközcsomagokat egy olyan Scala-projekt létrehozásához, amely a kiszolgáló nélküli számításon futtat kódot, olvassa el a Scala JAR databricks-eszközcsomagok használatával történő létrehozását ismertető témakört.
Követelmények
Az oktatóanyag elvégzéséhez meg kell felelnie a következő követelményeknek:
A munkaterület, a helyi környezet és a számítás megfelel a Scalához készült Databricks Connect követelményeinek. Lásd a Databricks Connect használati követelményeit.
Rendelkeznie kell a fürtazonosítóval. A fürtazonosító megtekintéséhez a saját munkaterületén kattintson a Számítás gombra az oldalsávon, majd kattintson a fürt nevére. A webböngésző címsorában másolja a
clustersésconfigurationközött található karaktersorozatot az URL-ből.A fejlesztői gépen telepítve van a Java Development Kit (JDK). A telepíteni kívánt verzióval kapcsolatos információkért tekintse meg a verziótámogatási mátrixot.
Megjegyzés:
Ha nincs telepítve JDK, vagy ha több JDK-telepítés van a fejlesztői gépen, az 1. lépés későbbi részében telepítheti vagy kiválaszthatja az adott JDK-t. Ha olyan JDK-telepítést választ, amely a fürt JDK-verziója alatt vagy felett található, váratlan eredményeket eredményezhet, vagy előfordulhat, hogy a kód egyáltalán nem fut.
Az IntelliJ IDEA telepítve van. Ezt az oktatóanyagot az IntelliJ IDEA Community Edition 2023.3.6-os verziójával teszteltük. Ha az IntelliJ IDEA másik verzióját vagy kiadását használja, az alábbi utasítások eltérhetnek.
Telepítve van az IntelliJ IDEA-hoz a Scala beépülő modul.
1. lépés: Az Azure Databricks-hitelesítés konfigurálása
Ez az oktatóanyag az Azure Databricks OAuth felhasználói (U2M) hitelesítését és egy Azure Databricks-konfigurációs profilt használ az Azure Databricks-munkaterület hitelesítéséhez. Ha ehelyett más hitelesítési típust szeretne használni, olvassa el a Kapcsolat tulajdonságainak konfigurálása című témakört.
Az OAuth U2M-hitelesítés konfigurálásához a Databricks parancssori felületre van szükség az alábbiak szerint:
Telepítse a Databricks parancssori felületét:
Linux, macOS
A Következő két parancs futtatásával telepítse a Databricks parancssori felületet a Homebrew használatával:
brew tap databricks/tap brew install databricksWindows
A Databricks CLI telepítéséhez használhatja a winget, Chocolatey vagy a Linuxos Windows-alrendszer-t (WSL). Ha nem tudja használni a
winget, a Chocolatey-t vagy a WSL-t, akkor hagyja ki ezt az eljárást, és a Parancssor vagy a PowerShell segítségével telepítse a Databricks CLI-t a forrásból helyette.Megjegyzés:
A Databricks CLI és a Chocolatey telepítése kísérleti.
wingetA Databricks parancssori felület telepítéséhez futtassa a következő két parancsot, majd indítsa újra a parancssort:winget search databricks winget install Databricks.DatabricksCLIA Databricks parancssori felület telepítéséhez futtassa a következő parancsot a Chocolatey használatával:
choco install databricks-cliA WSL használata a Databricks parancssori felület telepítéséhez:
Telepítse a
curlészipa WSL-en keresztül. További információkért tekintse meg az operációs rendszer dokumentációját.A következő parancs futtatásával telepítse a Databricks CLI-t a WSL használatával:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Ellenőrizze, hogy a Databricks parancssori felület telepítve van-e a következő parancs futtatásával, amely megjeleníti a telepített Databricks parancssori felület aktuális verzióját. Ennek a verziónak a 0.205.0-s vagy újabb verziónak kell lennie:
databricks -v
OAuth U2M-hitelesítés kezdeményezése az alábbiak szerint:
Az OAuth-jogkivonatok helyi felügyeletének elindításához használja a Databricks parancssori felületét az alábbi parancs futtatásával minden cél-munkaterületen.
Az alábbi parancsban cserélje le a
<workspace-url>elemet az Azure Databricks munkaterületenkénti URL-címére, példáulhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>A Databricks parancssori felülete kéri, hogy mentse az Azure Databricks konfigurációs profiljaként megadott adatokat. Nyomja meg a
Entergombot a javasolt profilnév elfogadásához, vagy írja be egy új vagy meglévő profil nevét. Az azonos nevű meglévő profilokat felülírja a megadott adatokkal. Profilok használatával gyorsan válthat a hitelesítési környezetre több munkaterületen.A meglévő profilok listájának lekéréséhez egy külön terminálban vagy parancssorban futtassa a Databricks parancssori felületét a parancs
databricks auth profilesfuttatásához. Egy adott profil meglévő beállításainak megtekintéséhez futtassa a parancsotdatabricks auth env --profile <profile-name>.A webböngészőben végezze el a képernyőn megjelenő utasításokat az Azure Databricks-munkaterületre való bejelentkezéshez.
A terminálban vagy parancssorban megjelenő elérhető fürtök listájában a felfelé és lefelé mutató nyílbillentyűkkel válassza ki a munkaterületen a cél Azure Databricks-fürtöt, majd nyomja le
Entera billentyűt. Az elérhető fürtök listájának szűréséhez beírhatja a fürt megjelenítésre kerülő nevének bármely részét.A profil aktuális OAuth-tokenértékének és a jogkivonat közelgő lejárati időbélyegének megtekintéséhez futtassa az alábbi parancsok egyikét:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Ha több azonos
--hostértékű profillal rendelkezik, lehet, hogy együtt kell megadnia a--hostés a-pbeállításokat, hogy a Databricks CLI megkeresse a megfelelő OAuth token információkat.
2. lépés: A projekt létrehozása
Indítsa el az IntelliJ IDEA-t.
A főmenüben kattintson a Fájl > Új > Projekt menüpontra.
Adjon egy értelmes nevet a projektnek.
A Hely beállításhoz kattintson a mappa ikonra, és végezze el a képernyőn megjelenő utasításokat az új Scala-projekt elérési útjának megadásához.
A Nyelvként kattintson a Scala lehetőségre.
A Build rendszeresetén kattintson a sbtlehetőségre.
A JDK legördülő listában válassza ki a fejlesztőgépe meglévő JDK telepítését, amely megfelel a fürtön lévő JDK-verziónak, vagy válassza a JDK letöltése lehetőséget, és a képernyőn megjelenő utasításokat követve töltsön le egy JDK-t, amely megegyezik a fürtön lévő JDK-verzióval. Lásd: Követelmények.
Megjegyzés:
Ha olyan JDK-telepítést választ, amely újabb vagy régebbi, mint a fürtön lévő JDK-verzió, az váratlan eredményekhez vezethet, vagy akár a kód teljesen meg sem fut.
Az sbt legördülő listában válassza ki a legújabb verziót.
A Scala legördülő listában válassza ki a Scala azon verzióját, amely megfelel a Scala-verzióhoz a fürtön. Lásd: Követelmények.
Megjegyzés:
Ha olyan Scala-verziót választ, amely a klaszter Scala-verziójánál alacsonyabb vagy magasabb, az váratlan eredményeket eredményezhet, vagy előfordulhat, hogy a kód egyáltalán nem fut.
Győződjön meg arról, hogy a Scala melletti Források letöltése jelölőnégyzet be van jelölve.
Csomagelőtag esetén adjon meg egy csomagelőtag-értéket a projekt forrásaihoz, például
org.example.application.Győződjön meg arról, hogy a Adja hozzá a mintakódot jelölőnégyzet be van jelölve.
Kattintson Létrehozásra.
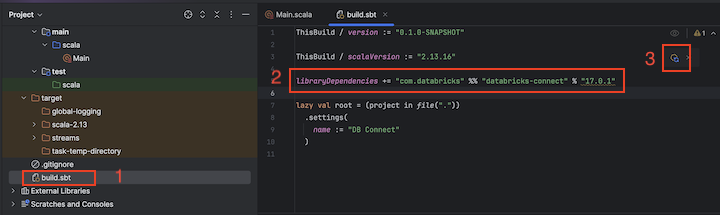
3. lépés: A Databricks Connect csomag hozzáadása
Az új Scala-projekt megnyitása után, a Projekt eszközablakban (Nézet > Eszközablakok > Projekt), nyissa meg a
build.sbtnevű fájlt a projekt-név> célmappában.Adja hozzá a következő kódot a
build.sbtfájl végéhez, amely deklarálja a projekt függőségét a Scalához készült Databricks Connect-kódtár egy adott verziójától, amely kompatibilis a fürt Databricks Runtime-verziójával:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"Cserélje le a
17.3-t a Databricks Connect könyvtár azon verziójára, amely a fürtön lévő Databricks Runtime-verziónak felel meg. A Databricks Connect 17.3.+ például megfelel a Databricks Runtime 17.3 LTS-nek. A Databricks Connect-kódtár verziószámait a Maven központi adattárában találja.Megjegyzés:
A Databricks Connect használata esetén ne tartalmazzon Apache Spark-összetevőket, például
org.apache.spark:spark-corea projektben. Ehelyett fordítson le közvetlenül a Databricks Connect segítségével.Kattintson a Sbt-módosítások betöltése értesítés ikonra a Scala-projekt új erőforrástár helyével és függőségével való frissítéséhez.
Várjon, amíg az IDE alján lévő
sbtállapotjelző eltűnik. Asbtbetöltési folyamat végrehajtása eltarthat néhány percig.
4. lépés: Kód hozzáadása
A Projekt eszközablakban nyissa meg a fájlt, amely a
Main.scalakönyvtárban található.Cserélje le a fájl meglévő kódját a következő kódra, majd mentse a fájlt a konfigurációs profil nevétől függően.
Ha az 1. lépésben megadott konfigurációs profil neve el van nevezve
DEFAULT, cserélje le a fájlban lévő összes meglévő kódot a következő kódra, majd mentse a fájlt:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Ha az 1. lépésben létrehozott konfigurációs profil neve nem az, hogy
DEFAULT, cserélje le a fájlban lévő meglévő kódot az alábbi kóddal. Cserélje le a helyőrzőt<profile-name>a konfigurációs profil nevére az 1. lépésben, majd mentse a fájlt:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
5. lépés: A virtuális gép beállításainak konfigurálása
Importálja az aktuális könyvtárat az IntelliJ-be, ahol
build.sbttalálható.Válassza a Java 17-et az IntelliJ-ben. Menjen a Fájl>Projektstruktúra>SDK-k menübe.
Nyissa meg
src/main/scala/com/examples/Main.scala.Lépjen a Main konfigurációjához a virtuálisgép-beállítások hozzáadásához:
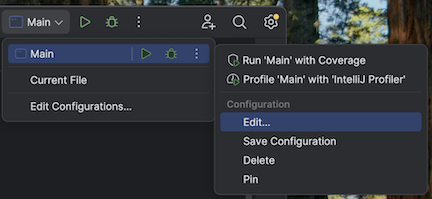
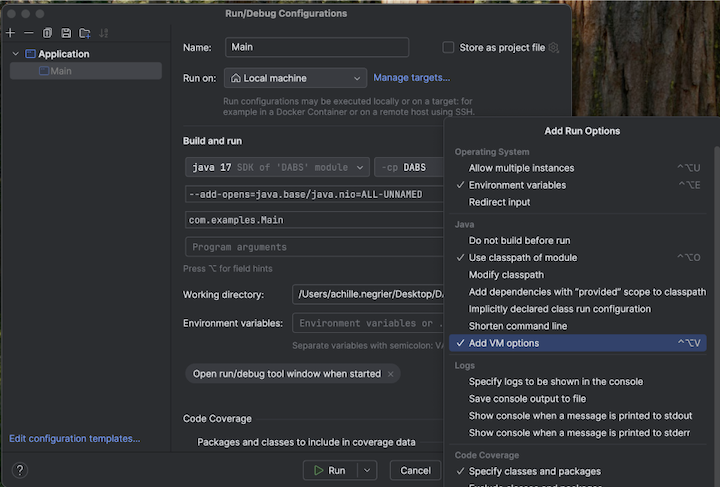
Adja hozzá a következőket a virtuális gép beállításaihoz:
--add-opens=java.base/java.nio=ALL-UNNAMED
Jótanács
Vagy ha a Visual Studio Code-ot használja, adja hozzá a következőket az sbt buildfájlhoz:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Ezután futtassa az alkalmazást a terminálról:
sbt run
6. lépés: A kód futtatása
- Indítsa el a célfürtöt a távoli Azure Databricks-munkaterületen.
- A fürt elindítása után a főmenüben kattintson a Futtatás > Futtatás 'Main' opcióra.
- A Futtatás eszközablakban (Megtekintés > Eszközablakok > Futtatás) a Fő lapon megjelenik a
samples.nyctaxi.tripstáblázat első 5 sora.
7. lépés: A kód hibakeresése
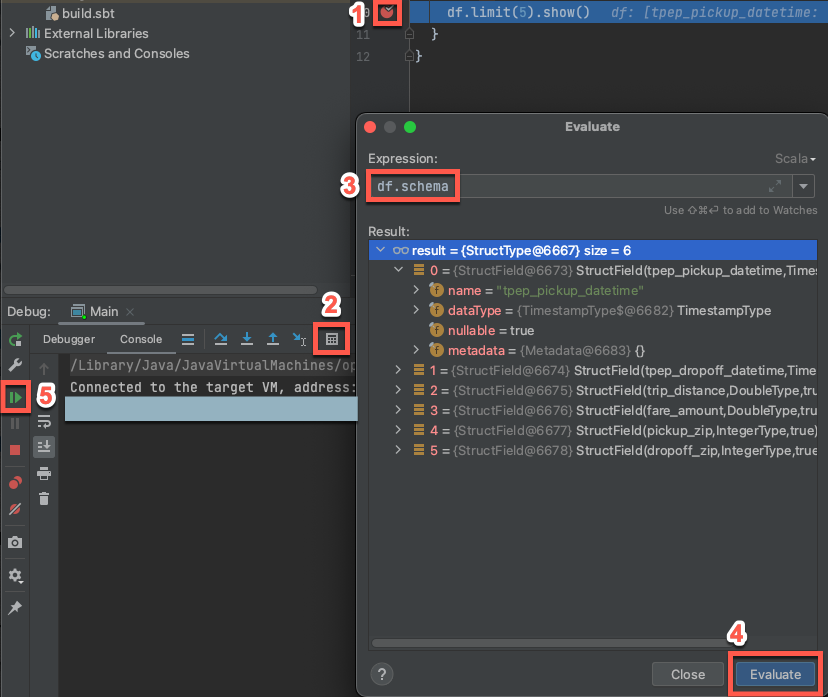
Ha a célfürt továbbra is fut, az előző kódban kattintson a
df.limit(5).show()melletti sávra a töréspont beállításához.A főmenüben kattintson a 'Fő' hibakeresés futtatása > parancsra. A Debug eszközablakban (Megtekintés > Eszközablakok > Debug), a Konzol fülön kattintson a számológép (Kifejezés kiértékelése) ikonra.
Adja meg a kifejezést
df.schema.Kattintson a Kiértékelés gombra a DataFrame sémájának megjelenítéséhez.
A Hibakeresés eszköz ablakának oldalsávján kattintson a zöld nyílra (Program folytatása) ikonra. A táblázat első 5 sora
samples.nyctaxi.tripsmegjelenik a Konzol panelen .