Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az első AI-ügynök létrehozása és üzembe helyezése Databricks Apps-sablonok használatával. Ebben az oktatóanyagban a következőket fogja elvégezni:
- Ügynök létrehozása és üzembe helyezése a Databricks Apps felhasználói felületéről.
- Csevegjen az ügynökkel egy előre elkészített csevegőfelület használatával.
Előfeltételek
Engedélyezze a Databricks-alkalmazásokat a munkaterületen. Lásd : Databricks Apps-munkaterület és fejlesztési környezet beállítása.
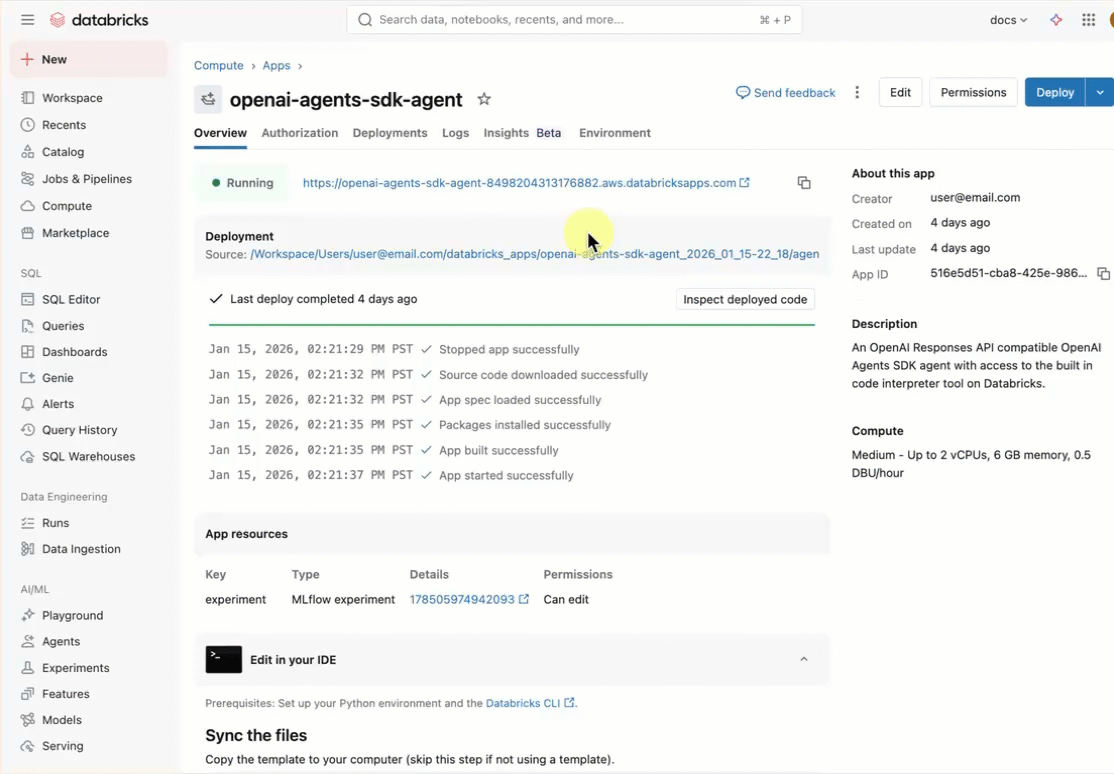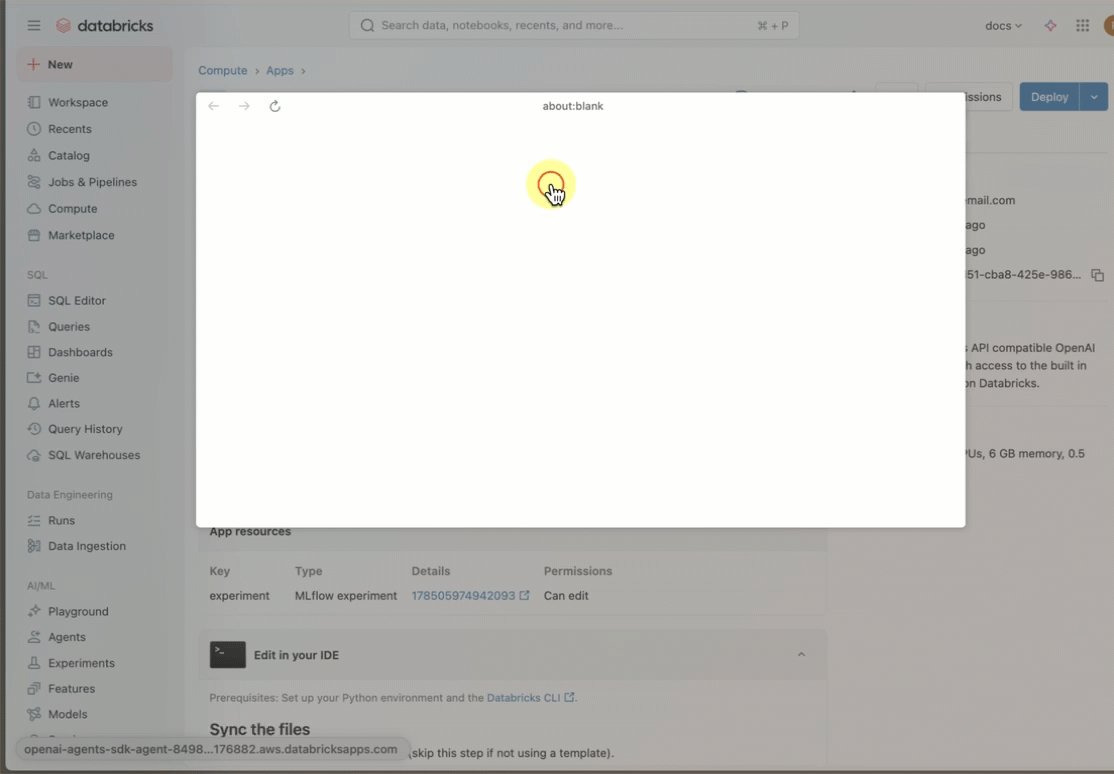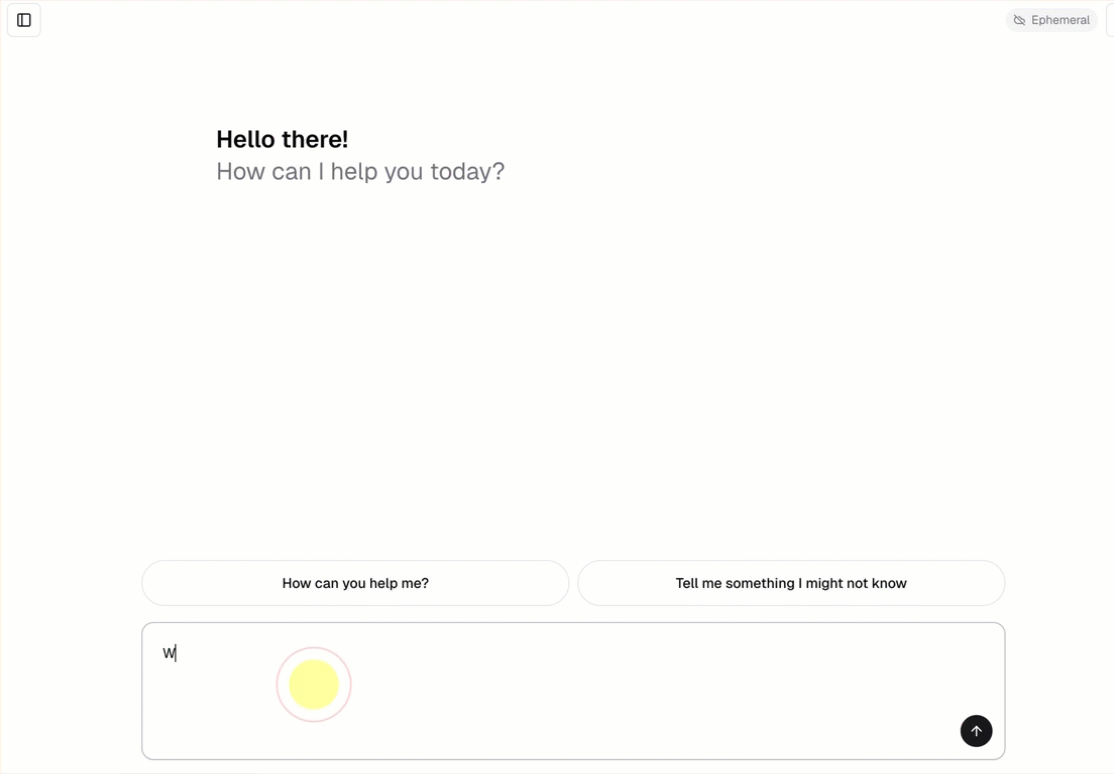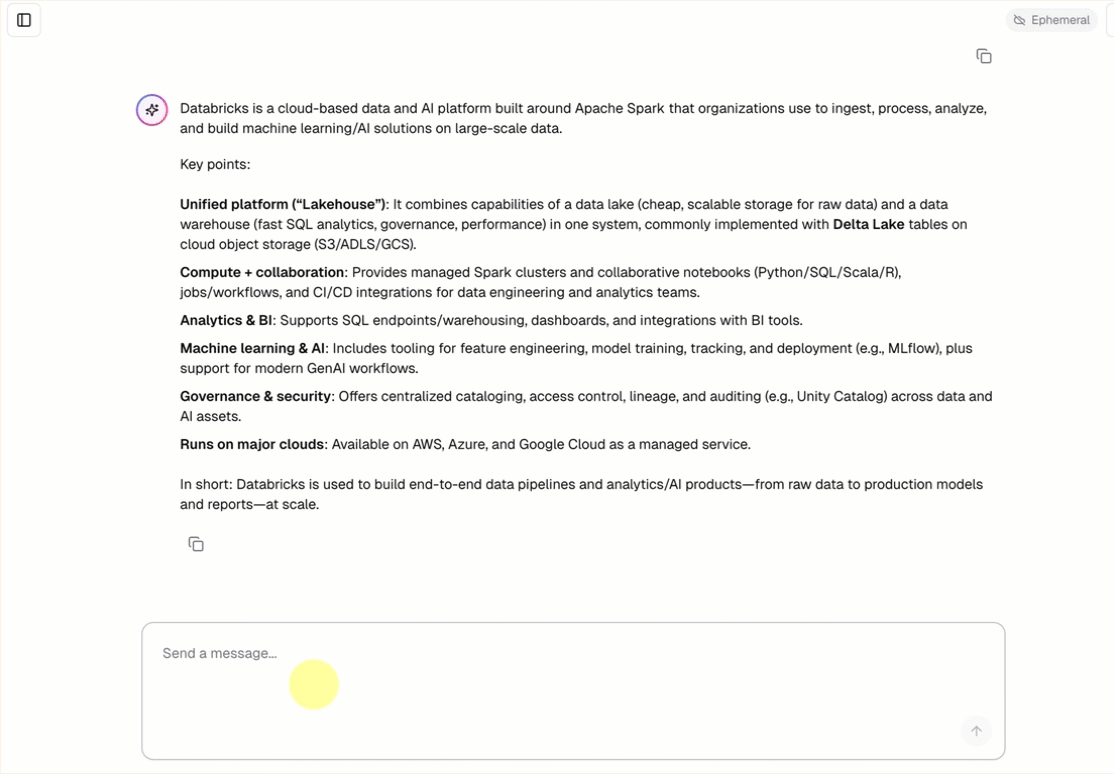
Az ügynöksablon üzembe helyezése
Első lépések a Databricks-alkalmazássablonok adattárából származó előre elkészített ügynöksablon használatával.
Ez az oktatóanyag a sablont agent-openai-agents-sdk használja, amely a következőket tartalmazza:
- OpenAI Agent SDK használatával létrehozott ügynök
- Kezdőkód egy ügynökalkalmazáshoz egy beszélgetési REST API-val és egy interaktív csevegési felhasználói felülettel
- Az ügynök MLflow használatával történő kiértékelésére vonatkozó kód
Telepítse az alkalmazássablont a Munkaterület felhasználói felületén. Ez telepíti az alkalmazást, és üzembe helyezi azt egy számítási erőforráson a munkaterületen.
A Databricks-munkaterületen kattintson az + Új>alkalmazás elemre.
Kattintson az Ügynökök>Ügynök - OpenAI Ügynökök SDK elemre.
Hozzon létre egy új MLflow-kísérletet a(z)
openai-agents-templatenévvel, és fejezze be a sablon telepítéséhez szükséges beállításokat.Az alkalmazás létrehozása után kattintson az alkalmazás URL-címére a csevegés felhasználói felületének megnyitásához.
Az ügynökalkalmazás ismertetése
Az ügynöksablon egy éles üzemre kész architektúrát mutat be az alábbi fő összetevőkkel:
MLflow AgentServer: Aszinkron FastAPI-kiszolgáló, amely beépített nyomkövetéssel és megfigyelhetőséggel kezeli az ügynökkéréseket. Az AgentServer biztosítja az /invocations ügynök lekérdezésének végpontját, és automatikusan kezeli a kérések útválasztását, naplózását és hibakezelését.
OpenAI-ügynökök SDK: A sablon az OpenAI-ügynökök SDK-t használja az ügynök-keretrendszerként a beszélgetések kezeléséhez és az eszközök vezénylésére. Az ügynököket bármilyen keretrendszer használatával létrehozhatja. A kulcs az ügynök MLflow-felülettel ResponsesAgent való megburkolása.
ResponsesAgent interfész: Ez az interfész biztosítja, hogy az ügynök különböző keretrendszerekben működjön, és integrálható legyen a Databricks-eszközökkel. Hozza létre ügynökét az OpenAI SDK, a LangGraph, a LangChain vagy tiszta Python használatával, majd csomagolja be ResponsesAgent-vel, hogy automatikusan kompatibilissé váljon az AI Playground, Agent Evaluation és Databricks Apps üzembe helyezésével.
MCP (Model Context Protocol) kiszolgálók: A sablon a Databricks MCP-kiszolgálókhoz csatlakozik, hogy hozzáférjen az ügynökökhöz az eszközökhöz és adatforrásokhoz. Lásd a Databricks modellkörnyezeti protokollját (MCP).
Az App ügynök egyszerű diagramja
Következő lépések
Ismerje meg, hogyan lehet egyéni ügynököt létrehozni:AI-ügynök létrehozása és üzembe helyezése a Databricks Appsben