Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez az oktatóanyag bemutatja, hogyan hozhat létre gépi tanulási besorolási modellt az scikit-learn Azure Databricks könyvtárával.
A cél egy besorolási modell létrehozása annak előrejelzésére, hogy egy bor "kiváló minőségűnek" minősül-e. Az adathalmaz 11 különböző bort (például alkoholtartalmat, savasságot és reziduális cukrot) és 1–10 közötti minőségi rangsort tartalmaz.
Ez a példa azt is szemlélteti , hogy az MLflow használatával nyomon követheti a modellfejlesztési folyamatot, a Hyperopt pedig automatizálja a hiperparaméterek finomhangolását.
Az adatkészlet az UCI Machine Learning-adattárból származik, amely a fizikokémiai tulajdonságokból származó adatbányászat által a bor preferenciáinak modellezésében található [Cortez et al., 2009].
Mielőtt elkezdené
- A Unity Catalog használatához a munkaterületet engedélyezni kell. Tekintse meg a Unity Catalog használatának első lépéseit.
- Rendelkeznie kell engedéllyel ahhoz, hogy létrehozhasson egy számítási erőforrást, vagy hozzáféréssel kell rendelkeznie egy olyan számítási erőforráshoz, amely a Databricks Runtime for Machine Learninget használja.
- Önnél kell legyen a USE CATALOG jogosultság egy katalógushoz.
- Ebben a katalógusban a következő jogosultságokkal kell rendelkeznie egy sémán: USE SCHEMA, CREATE TABLEés CREATE MODEL.
Tipp.
A cikkben szereplő összes kód elérhető egy jegyzetfüzetben, amelyet közvetlenül a munkaterületre importálhat. Lásd: Példajegyzetfüzet: Besorolási modell létrehozása.
1. lépés: Databricks-jegyzetfüzet létrehozása
Ha jegyzetfüzetet szeretne létrehozni a munkaterületen, kattintson ![]() az Oldalsáv Új gombjára, majd a Jegyzetfüzet elemre. Megnyílik egy üres jegyzetfüzet a munkaterületen.
az Oldalsáv Új gombjára, majd a Jegyzetfüzet elemre. Megnyílik egy üres jegyzetfüzet a munkaterületen.
A jegyzetfüzetek létrehozásáról és kezeléséről további információt a Jegyzetfüzetek kezelése című témakörben talál.
2. lépés: Csatlakozás számítási erőforrásokhoz
A feltáró adatelemzéshez és az adatmérnökséghez hozzáférése kell hogy legyen a számításhoz. A cikkben ismertetett lépésekhez a Databricks Runtime for Machine Learning szükséges. A Databricks Runtime ml-verziójának kiválasztásával kapcsolatos további információkért és utasításokért lásd : Databricks Runtime for Machine Learning.
A jegyzetfüzetben kattintson a jobb felső sarokban található Csatlakozás legördülő menüre. Ha rendelkezik hozzáféréssel egy olyan meglévő erőforráshoz, amely a Databricks Runtime for Machine Learning alkalmazást használja, válassza ki az erőforrást a menüből. Ellenkező esetben kattintson az Új erőforrás létrehozása... elemre egy új számítási erőforrás konfigurálásához.
3. lépés: Modellregisztrációs adatbázis, katalógus és séma beállítása
Első lépésként két fontos lépésre van szükség. Először konfigurálnia kell az MLflow-ügyfelet a Unity Catalog modellregisztrációs adatbázisként való használatára. Írja be a következő kódot egy új cellába a jegyzetfüzetben.
import mlflow
mlflow.set_registry_uri("databricks-uc")
Azt a katalógust és sémát is be kell állítania, ahol a modell regisztrálva lesz. Rendelkeznie kell USE CATALOG jogosultsággal a katalógusban, és USE SCHEMA, CREATE TABLE, és CREATE MODEL jogosultságokkal a sémában.
További információ a Unity Catalog használatáról: Mi a Unity Catalog?.
Írja be a következő kódot egy új cellába a jegyzetfüzetben.
# If necessary, replace "main" and "default" with a catalog and schema for which you have the required permissions.
CATALOG_NAME = "main"
SCHEMA_NAME = "default"
4. lépés: Adatok betöltése és Unity-katalógustáblák létrehozása
Ez a példa két CSV-fájlt használ, amelyek a következő helyen databricks-datasetsérhetők el: A saját adatok betöltésének módjáról a Lakeflow Connect Standard összekötői című témakörben olvashat.
Írja be a következő kódot egy új cellába a jegyzetfüzetben. Ez a kód a következőket teszi:
- Adatok olvasása
winequality-white.csvéswinequality-red.csvelemekből a Spark DataFrame-ekbe. - Törölje az adatokat úgy, hogy az oszlopnevek szóközeit aláhúzásjelekre cseréli.
- Írja a DataFrame-eket a
white_wineés ared_winetáblákba a Unity Katalógusban. Az adatok Unity Catalogba való mentése megőrzi az adatokat, és lehetővé teszi az adatok megosztásának szabályozását másokkal.
white_wine = spark.read.csv("/databricks-datasets/wine-quality/winequality-white.csv", sep=';', header=True)
red_wine = spark.read.csv("/databricks-datasets/wine-quality/winequality-red.csv", sep=';', header=True)
# Remove the spaces from the column names
for c in white_wine.columns:
white_wine = white_wine.withColumnRenamed(c, c.replace(" ", "_"))
for c in red_wine.columns:
red_wine = red_wine.withColumnRenamed(c, c.replace(" ", "_"))
# Define table names
red_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine"
white_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine"
# Write to tables in Unity Catalog
spark.sql(f"DROP TABLE IF EXISTS {red_wine_table}")
spark.sql(f"DROP TABLE IF EXISTS {white_wine_table}")
white_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine")
red_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine")
5. lépés Az adatok előfeldolgozása és felosztása
Ebben a lépésben betölti az adatokat a 4. lépésben létrehozott Unity Catalog-táblákból a Pandas DataFramesbe, és előre feldolgozza az adatokat. Az ebben a szakaszban található kód a következőket teszi:
- Pandas DataFrame-ként tölti be az adatokat.
- Logikai oszlopot ad hozzá az egyes DataFrame-ekhez a vörös és fehér borok megkülönböztetéséhez, majd egyesíti a DataFrame-eket egy új DataFrame-fájlban,
data_df. - Az adathalmaz egy
qualityoszlopot tartalmaz, amely 1 és 10 közötti borokat sorol fel, 10 pedig a legmagasabb minőséget jelzi. A kód ezt az oszlopot két besorolási értékre alakítja: "True" (Igaz) a kiváló minőségű bor (quality>= 7) és a "False" (Hamis) jelzésére, amely nem jó minőségű bort jelöl (quality< 7). - Az adattáblát külön edzés és teszt adathalmazokra osztja fel.
Először importálja a szükséges kódtárakat:
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble
import matplotlib.pyplot as plt
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
Most töltse be és dolgozza fel előre az adatokat:
# Load data from Unity Catalog as Pandas dataframes
white_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine").toPandas()
red_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine").toPandas()
# Add Boolean fields for red and white wine
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# Define classification labels based on the wine quality
data_labels = data_df['quality'].astype('int') >= 7
data_df = data_df.drop(['quality'], axis=1)
# Split 80/20 train-test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
6. lépés A besorolási modell betanítása
Ez a lépés betanít egy színátmenet-növelő osztályozót az alapértelmezett algoritmusbeállítások használatával. Ezután alkalmazza az eredményként kapott modellt a tesztadatkészletre, kiszámítja, naplózza és megjeleníti a fogadó működési görbéje alatti területet a modell teljesítményének kiértékeléséhez.
Először engedélyezze az MLflow automatikus naplózását.
mlflow.autolog()
Most indítsa el a modell betanítási futtatását:
with mlflow.start_run(run_name='gradient_boost') as run:
model = sklearn.ensemble.GradientBoostingClassifier(random_state=0)
# Models, parameters, and training metrics are tracked automatically
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
roc_curve = sklearn.metrics.RocCurveDisplay.from_estimator(model, X_test, y_test)
# Save the ROC curve plot to a file
roc_curve.figure_.savefig("roc_curve.png")
# The AUC score on test data is not automatically logged, so log it manually
mlflow.log_metric("test_auc", roc_auc)
# Log the ROC curve image file as an artifact
mlflow.log_artifact("roc_curve.png")
print("Test AUC of: {}".format(roc_auc))
A cellaeredmények a görbe alatti számított területet és a ROC-görbe diagramját mutatják:
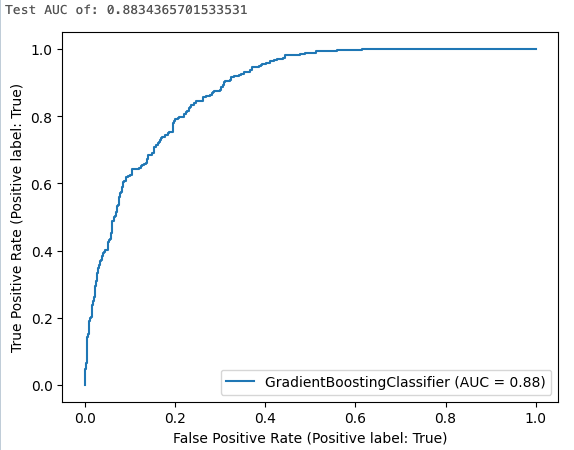
7. lépés Kísérletfuttatások megtekintése az MLflow-ban
Az MLflow-kísérletkövetés segít nyomon követni a modellfejlesztést kód és eredmények naplózásával, miközben iteratív módon fejleszt modelleket.
Az imént végrehajtott betanítási futtatás naplózott eredményeinek megtekintéséhez kattintson a cellakimenetben lévő hivatkozásra, ahogyan az az alábbi képen is látható.
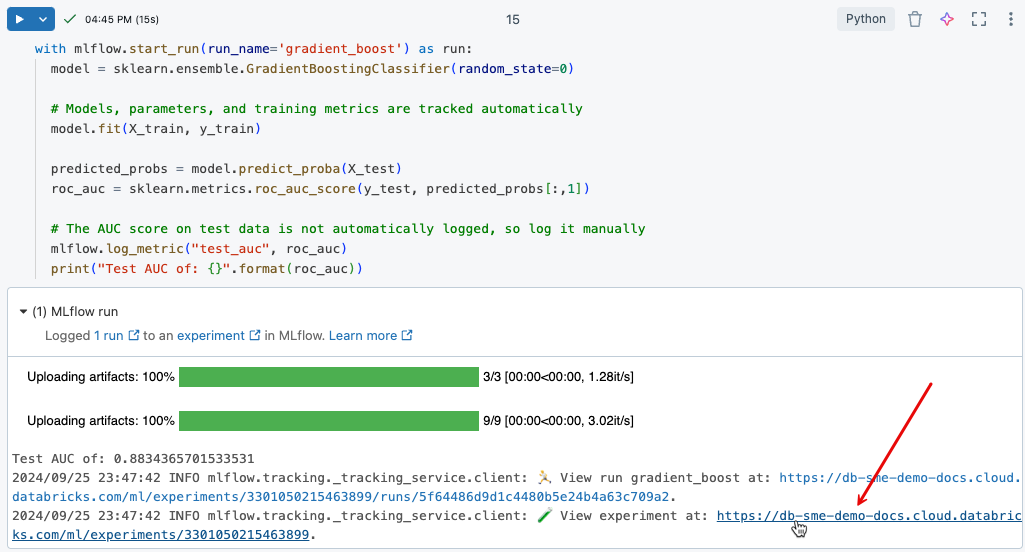
A kísérletoldalon összehasonlíthatja a futtatásokat, és megtekintheti az egyes futtatások részleteit. A futtatás nevére kattintva megtekintheti az adott futtatás paramétereit és metrikáit. Lásd az MLflow-kísérlet nyomon követését.
A jegyzetfüzet kísérletfuttatásait a jegyzetfüzet jobb felső sarkában található Kísérlet ikon ![]() kattintva is megtekintheti. Ekkor megnyílik a kísérlet oldalsávja, amely a jegyzetfüzet-eperimenthez társított összes futtatás összegzését jeleníti meg, beleértve a futtatási paramétereket és a metrikákat. Ha szükséges, kattintson a frissítés ikonra a legújabb futtatások lekéréséhez és figyeléséhez.
kattintva is megtekintheti. Ekkor megnyílik a kísérlet oldalsávja, amely a jegyzetfüzet-eperimenthez társított összes futtatás összegzését jeleníti meg, beleértve a futtatási paramétereket és a metrikákat. Ha szükséges, kattintson a frissítés ikonra a legújabb futtatások lekéréséhez és figyeléséhez.
![]()
8. lépés Hyperopt használata hiperparaméter-finomhangoláshoz
Az ML-modellek fejlesztésének fontos lépése a modell pontosságának optimalizálása az algoritmust vezérlő paraméterek, az úgynevezett hiperparaméterek finomhangolásával.
A Databricks Runtime ML a Hyperoptot, egy Python-kódtárat tartalmaz a hiperparaméterek finomhangolásához. A Hyperopt használatával hiperparaméter kereséseket futtathat, és több modellt is betaníthat párhuzamosan, csökkentve a modell optimalizálásához szükséges időt. Az MLflow-nyomkövetés integrálva van a Hyperopttal a modellek és paraméterek automatikus naplózásához. További információ a Hyperopt Databricksben való használatáról: Hyperparameter tuning.
Az alábbi kód egy példát mutat a Hyperopt használatára.
# Define the search space to explore
search_space = {
'n_estimators': scope.int(hp.quniform('n_estimators', 20, 1000, 1)),
'learning_rate': hp.loguniform('learning_rate', -3, 0),
'max_depth': scope.int(hp.quniform('max_depth', 2, 5, 1)),
}
def train_model(params):
# Enable autologging on each worker
mlflow.autolog()
with mlflow.start_run(nested=True):
model_hp = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
**params
)
model_hp.fit(X_train, y_train)
predicted_probs = model_hp.predict_proba(X_test)
# Tune based on the test AUC
# In production, you could use a separate validation set instead
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric('test_auc', roc_auc)
# Set the loss to -1*auc_score so fmin maximizes the auc_score
return {'status': STATUS_OK, 'loss': -1*roc_auc}
# SparkTrials distributes the tuning using Spark workers
# Greater parallelism speeds processing, but each hyperparameter trial has less information from other trials
# On smaller clusters try setting parallelism=2
spark_trials = SparkTrials(
parallelism=1
)
with mlflow.start_run(run_name='gb_hyperopt') as run:
# Use hyperopt to find the parameters yielding the highest AUC
best_params = fmin(
fn=train_model,
space=search_space,
algo=tpe.suggest,
max_evals=32,
trials=spark_trials)
9. lépés Keresse meg a legjobb modellt, és regisztrálja a Unity Catalogban
A következő kód azonosítja azt a futtatást, amely a legjobb eredményt hozta, a ROC-görbe alatti terület alapján mérve:
# Sort runs by their test auc. In case of ties, use the most recent run.
best_run = mlflow.search_runs(
order_by=['metrics.test_auc DESC', 'start_time DESC'],
max_results=10,
).iloc[0]
print('Best Run')
print('AUC: {}'.format(best_run["metrics.test_auc"]))
print('Num Estimators: {}'.format(best_run["params.n_estimators"]))
print('Max Depth: {}'.format(best_run["params.max_depth"]))
print('Learning Rate: {}'.format(best_run["params.learning_rate"]))
Az általad a legjobb modellhez azonosított run_id-t a következő kód regisztrálja a Unity Catalogba.
model_uri = 'runs:/{run_id}/model'.format(
run_id=best_run.run_id
)
mlflow.register_model(model_uri, f"{CATALOG_NAME}.{SCHEMA_NAME}.wine_quality_model")
10. lépés. Helyezd üzembe a modellt éles környezetben
Ha készen áll a modellek kiszolgálására és üzembe helyezésére, ezt az Azure Databricks-munkaterület kiszolgáló felhasználói felületével teheti meg.
- Lásd: Végpontokat kiszolgáló egyéni modell létrehozása.
- Lásd: Az egyéni modellek végpontjait kiszolgáló lekérdezés.
Példajegyzetfüzet: Besorolási modell létrehozása
A cikk lépéseinek végrehajtásához használja az alábbi jegyzetfüzetet. A jegyzetfüzet Azure Databricks-munkaterületre való importálásával kapcsolatos utasításokért lásd : Jegyzetfüzet importálása.
Az első gépi tanulási modell létrehozása a Databricks használatával
További információ
A Databricks egyetlen platformot biztosít, amely az ml-fejlesztés és az üzembe helyezés minden lépését kiszolgálja, a nyers adatoktól a következtetési táblákig, amelyek minden kérést és választ mentenek egy kiszolgált modellhez. Az adattudósok, az adatmérnökök, az ml-mérnökök és a DevOps ugyanazokkal az eszközökkel és egyetlen igazságforrással végezhetik a munkájukat.
További információ:
- Gépi tanulási és AI-oktatóanyagok
- A Databricks gépi tanulásának és AI-jának áttekintése
- Gépi tanulás és AI-modellek betanításának áttekintése a Databricksen
- MLflow a Databricksen