Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk az egyéni modellek, azaz a hagyományos ML-modell üzembe helyezésének és lekérdezésének alapvető lépéseit ismerteti a Mozaik AI-modell-szolgáltatás használatával. A modellt regisztrálni kell a Unity Katalógusban vagy a munkaterület-modell beállításjegyzékében.
A generatív AI-modellek kiszolgálásáról és üzembe helyezéséről az alábbi cikkekben olvashat:
1. lépés: A modell naplózása
Különböző módokon naplózhatja a modellt a kiszolgálás érdekében.
| Naplózási technika | Leírás |
|---|---|
| Automatikus naplózás | Ez automatikusan be van kapcsolva, amikor a Databricks Runtime-ot gépi tanuláshoz használja. Ez a legegyszerűbb módszer, de kevesebb irányítást biztosít. |
| Naplózás az MLflow beépített funkcióival | Manuálisan naplózhatja a modellt az MLflow beépített modell-ízváltozataival. |
Egyéni naplózás a pyfunc |
Ezt akkor használja, ha egyéni modellel rendelkezik, vagy ha további lépésekre van szüksége a következtetés előtt vagy után. |
Az alábbi példa bemutatja, hogyan naplózhatja az MLflow-modellt a transformer íz használatával, és hogyan adhatja meg a modellhez szükséges paramétereket.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
A modell naplózása után ellenőrizze, hogy regisztrálva van-e a Unity Catalog-ban vagy az MLflow Model Registry-ban.
2. lépés: Végpont létrehozása a kiszolgálói felhasználói felületen
Miután a regisztrált modell naplózása megtörtént, és készen áll a kiszolgálásra, létrehozhat egy kiszolgáló végpontot a kiszolgáló felhasználói felület használatával.
Kattintson az oldalsávon a Szolgáltatás lehetőségre a Szolgáltatás felhasználói felületének megjelenítéséhez.
Kattintson a Kiszolgálóvégpont létrehozása elemre.
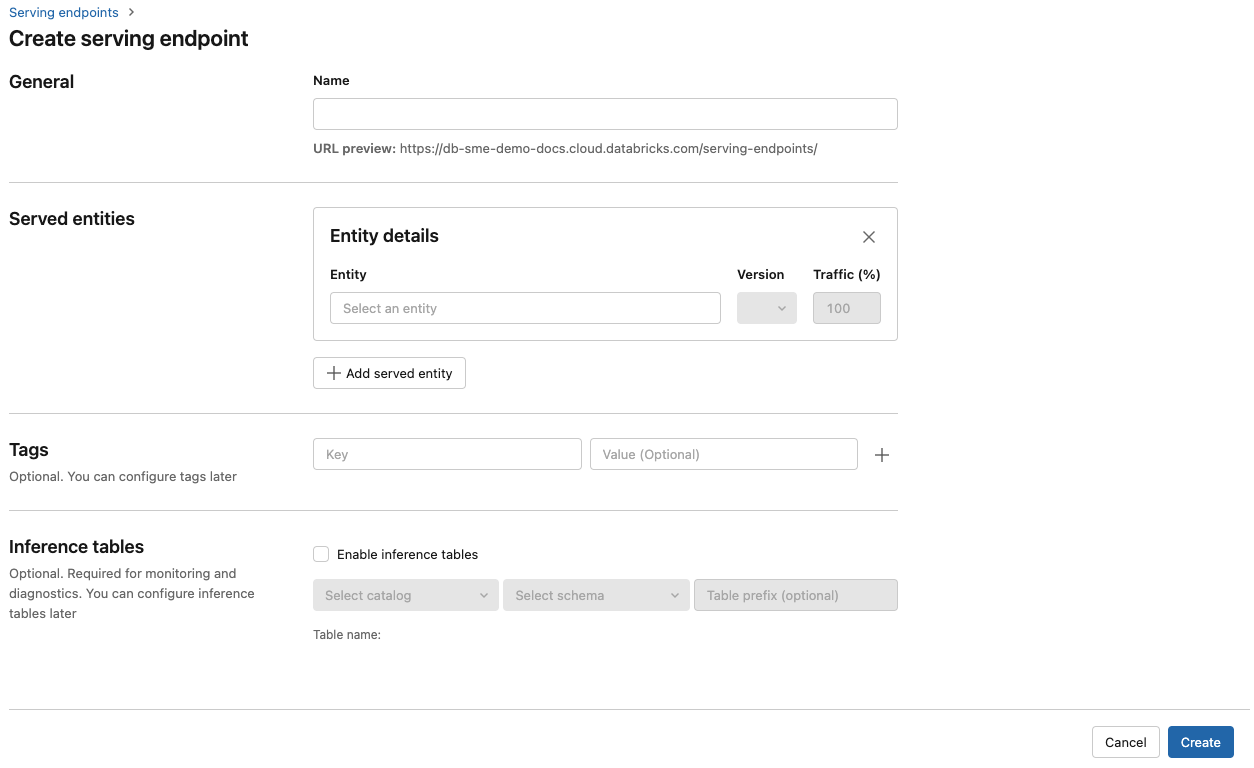
A Név mezőben adja meg a végpont nevét.
A Kiszolgált entitások szakaszban
- Kattintson a Entitás mezőbe a Kiszolgált entitás kiválasztása űrlap megnyitásához.
- Válassza ki a kiszolgálni kívánt modell típusát. Az űrlap a kijelölés alapján dinamikusan frissül.
- Válassza ki a kiszolgálni kívánt modellt és modellverziót.
- Válassza ki a kiszolgált modellhez irányítandó forgalom százalékos arányát.
- Válassza ki, hogy milyen méretű számítási erőforrást használjon.
- A Számítási felskálázásiterületen válassza ki a számítási felskálázás méretét, amely megfelel azon kérések számának, amelyeket a kiszolgált modell egyszerre tud feldolgozni. Ennek a számnak nagyjából egyenlőnek kell lennie a QPS x modell végrehajtási időpontjával.
- Az elérhető méretek kicsik 0-4, közepes 8-16, 16-64 kérés esetén pedig nagy méretűek.
- Adja meg, hogy a végpont nullára legyen-e skálázva, ha nincs használatban.
Kattintson a Létrehozás gombra. A Végpontok kiszolgálása lap úgy jelenik meg , hogy a kiszolgálóvégpont állapota nem áll készen.
Ha programozott módon szeretne végpontot létrehozni a Databricks Serving API-val, tekintse meg az egyéni modell végpontjait kiszolgáló egyéni modell létrehozását.
3. lépés: A végpont lekérdezése
A legegyszerűbb és leggyorsabb módja a pontszámkérések tesztelésének és elküldésének a kiszolgált modellhez a Serving felhasználói felület használata.
A Szolgáltatási végpont lapon válassza a Lekérdezés végpontlehetőséget.
Szúrja be a modell bemeneti adatait JSON formátumban, és kattintson Kérelem küldésegombra. Ha a modellt egy bemeneti példával naplózták, a példa betöltéséhez kattintson a Példa megjelenítése gombra.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Pontozási kérések küldéséhez hozzon létre egy JSON-t a támogatott kulcsok egyikével és a bemeneti formátumnak megfelelő JSON-objektummal. A lekérdezési végpontok egyéni modellekhez támogatott formátumairól és az API-val történő pontozási kérések küldésére vonatkozó útmutatásról.
Ha az Azure Databricks kiszolgálói felhasználói felületén kívül szeretné elérni a kiszolgáló végpontot, szüksége lesz egy DATABRICKS_API_TOKEN.
Fontos
A Databricks ajánlott biztonsági gyakorlatként javasolja az éles környezetekben a gép-gép közötti OAuth-jogkivonatok használatát a hitelesítéshez.
Teszteléshez és fejlesztéshez a Databricks a munkaterület felhasználói helyett a szolgáltatásnevekhez tartozó személyes hozzáférési jogkivonat használatát javasolja. A szolgáltatás-helyettesek jogkivonatainak létrehozásához tekintse meg a Szolgáltatás-helyettes jogkivonatok kezelése című témakört.
Példajegyzetfüzetek
Az MLflow-modell transformers Modellkiszolgálóval való kiszolgálásához tekintse meg az alábbi jegyzetfüzetet.
Hugging Face transformers modell notebook telepítése
Az MLflow-modell pyfunc Modellkiszolgálóval való kiszolgálásához tekintse meg az alábbi jegyzetfüzetet. A modelltelepítések testreszabásával kapcsolatos további részletekért lásd : Python-kód üzembe helyezése a Modellkiszolgálóval.