Ajánló modellek betanítása
Ez a cikk két példát tartalmaz az Azure Databricks mélytanuláson alapuló javaslatmodelljeire. A hagyományos ajánlási modellekhez képest a mélytanulási modellek jobb minőségű eredményeket érhetnek el, és nagyobb mennyiségű adatra méretezhetők. Mivel ezek a modellek folyamatosan fejlődnek, a Databricks keretrendszert biztosít a nagy léptékű javaslatmodellek hatékony betanításához, amelyek több száz millió felhasználó kezelésére képesek.
Az általános javaslati rendszer tölcsérként tekinthető meg a diagramon látható fázisokkal.
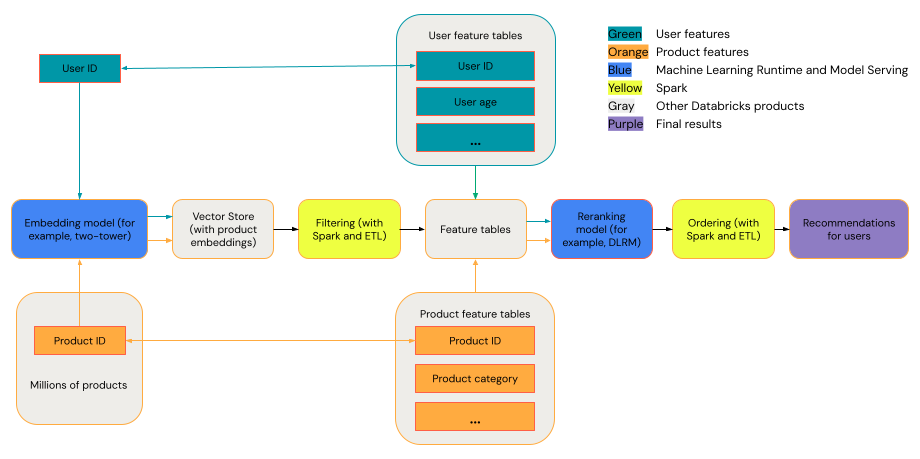
Egyes modellek, például a kéttornyú modell, jobban teljesítnek lekéréses modellekként. Ezek a modellek kisebbek, és hatékonyan működnek több millió adatponton. Más modellek, például a DLRM vagy a DeepFM jobban teljesítenek, mint a modellek újraküldése. Ezek a modellek több adatot tartalmazhatnak, nagyobbak, és részletes javaslatokat nyújthatnak.
Követelmények
Databricks Runtime 14.3 LTS ML
Eszközök
A cikkben szereplő példák a következő eszközöket szemléltetik:
- TorchDistributor: A TorchDistributor egy keretrendszer, amely lehetővé teszi a Nagy méretű PyTorch-modell betanítását a Databricksen. A Sparkot használja a vezényléshez, és a fürtben elérhető gpu-k számára méretezhető.
- Mozaik StreamingDataset: A StreamingDataset javítja a Databricksen található nagy adathalmazok betanításának teljesítményét és méretezhetőségét olyan funkciókkal, mint az előkezelés és az interleaving.
- MLflow: Az Mlflow lehetővé teszi a paraméterek, metrikák és modell ellenőrzőpontok nyomon követését.
- TorchRec: A modern ajánlórendszerek beágyazási keresési táblákat használnak a felhasználók és elemek millióinak kezelésére, hogy kiváló minőségű javaslatokat generáljanak. A nagyobb beágyazási méretek javítják a modell teljesítményét, de jelentős GPU-memóriát és több GPU-beállítást igényelnek. A TorchRec keretrendszert biztosít a javaslatmodellek és keresési táblák több GPU-ra való skálázásához, így ideális a nagy méretű beágyazásokhoz.
Példa: Filmjavaslatok kéttornyú modellarchitektúra használatával
A kéttornyú modell úgy lett kialakítva, hogy nagy léptékű személyre szabási feladatokat kezeljen a felhasználói és elemadatok külön-külön történő feldolgozásával, mielőtt kombinálja őket. Képes hatékonyan létrehozni több száz vagy több ezer tisztességes minőségi ajánlást. A modell általában három bemenetet vár: egy user_id funkciót, egy product_id funkciót és egy bináris címkét, amely meghatározza, hogy a felhasználó, a <termék> interakciója pozitív (a felhasználó megvásárolta a terméket) vagy negatív (a felhasználó egy csillag minősítést adott a terméknek). A modell kimenetei beágyazások mind a felhasználók, mind az elemek számára, amelyeket aztán általában kombinálnak (gyakran pontalapú termék vagy koszinusz hasonlóság használatával) a felhasználói elemek interakcióinak előrejelzéséhez.
Mivel a kéttornyú modell beágyazásokat biztosít mind a felhasználók, mind a termékek számára, ezeket a beágyazásokat elhelyezheti egy vektoradatbázisban, például a Databricks Vector Store-ban, és hasonló keresési műveletet hajthat végre a felhasználókon és az elemeken. Elhelyezheti például az összes elemet egy vektortárolóban, és minden felhasználó esetében lekérdezheti a vektortárolót, hogy megtalálja a felhasználóhoz hasonló beágyazású elemek felső százát.
Az alábbi példajegyzetfüzet a "Learning from Sets of Items" adatkészlettel implementálja a kéttornyú modell betanítását, hogy előre jelezhesse, hogy a felhasználó egy adott film nagy mértékben fog-e értékelni. A Mozaik StreamingDataset az elosztott adatbetöltéshez, a TorchDistributort az elosztott modell betanításához, az Mlflow-t pedig a modellkövetéshez és -naplózáshoz használja.
Kéttornyú ajánló modelljegyzetfüzet
Ez a jegyzetfüzet a Databricks Piactéren is elérhető: Kéttornyú modelljegyzetfüzet
Feljegyzés
- A kéttornyú modell bemenetei leggyakrabban a kategorikus funkciók user_id és product_id. A modell módosítható úgy, hogy több funkcióvektort is támogatjon mind a felhasználók, mind a termékek számára.
- A kéttornyú modell kimenetei általában bináris értékek, amelyek azt jelzik, hogy a felhasználó pozitív vagy negatív interakcióban lesz-e a termékkel. A modell módosítható más alkalmazásokhoz, például regresszióhoz, többosztályos besoroláshoz és több felhasználói művelet valószínűségéhez (például elvetéshez vagy vásárláshoz). Az összetett kimeneteket körültekintően kell megvalósítani, mivel a versengő célkitűzések ronthatják a modell által létrehozott beágyazások minőségét.
Példa: DLRM-architektúra betanítása szintetikus adatkészlet használatával
A DLRM egy korszerű neurális hálózati architektúra, amelyet kifejezetten személyre szabási és javaslati rendszerekhez terveztek. Kategorikus és numerikus bemeneteket kombinál a felhasználói elemek interakcióinak hatékony modellezéséhez és a felhasználói beállítások előrejelzéséhez. A DLRM-ek általában olyan bemeneteket várnak, amelyek tartalmazzák a ritka szolgáltatásokat (például a felhasználói azonosítót, az elemazonosítót, a földrajzi helyet vagy a termékkategóriát) és a sűrű szolgáltatásokat (például a felhasználói életkort vagy az elemárat). A DLRM kimenete általában a felhasználói aktivitás előrejelzése, például az átkattintási arányok vagy a vásárlás valószínűsége.
A DLRM-k egy nagymértékben testre szabható keretrendszert kínálnak, amely képes nagy léptékű adatok kezelésére, így alkalmas a különböző tartományok összetett javaslati feladatainak elvégzésére. Mivel ez egy nagyobb modell, mint a kéttornyú architektúra, ezt a modellt gyakran használják az újraépítési szakaszban.
Az alábbi példajegyzetfüzet egy DLRM-modellt hoz létre a bináris címkék előrejelzéséhez sűrű (numerikus) funkciókkal és ritkán használt (kategorikus) funkciókkal. Szintetikus adatkészletet használ a modell betanításához, a Mozaik StreamingDataset az elosztott adatbetöltéshez, a TorchDistributort az elosztott modell betanításához, valamint a Mlflow-t a modell követéséhez és naplózásához.
DLRM-jegyzetfüzet
Ez a jegyzetfüzet a Databricks Piactéren is elérhető: DLRM-jegyzetfüzet.
Kéttornyú és DLRM-modellek összehasonlítása
A táblázat útmutatást tartalmaz a használni kívánt ajánló modell kiválasztásához.
| Modell típusa | A betanításhoz szükséges adathalmazméret | Modell mérete | Támogatott bemeneti típusok | Támogatott kimeneti típusok | Használati esetek |
|---|---|---|---|---|---|
| Kéttornyú | Kisebb | Kisebb | Általában két funkció (user_id, product_id) | Főként bináris besorolás és beágyazások létrehozása | Több száz vagy több ezer lehetséges javaslat létrehozása |
| DLRM | Nagyobb | Nagyobb | Különböző kategorikus és sűrű funkciók (user_id, nem, geographic_location, product_id, product_category, ...) | Többosztályos besorolás, regresszió, egyéb | Részletes lekérés (több tíz rendkívül fontos elem ajánlása) |
Összefoglalva, a kéttornyú modell a legjobban több ezer jó minőségű javaslat nagyon hatékony létrehozásához használható. Ilyenek lehetnek például a kábelszolgáltatótól származó filmjavaslatok. A DLRM-modell a legjobban a több adaton alapuló, nagyon specifikus javaslatok létrehozásához használható. Ilyen lehet például egy kiskereskedő, aki kisebb számú terméket szeretne bemutatni egy ügyfélnek, amelyet nagy valószínűséggel vásárol.