Mozaik AI-vektorkeresés
Ez a cikk áttekintést nyújt a Databricks vektoradatbázis-megoldásáról, a Mozaik AI Vector Searchről, beleértve annak működését és működését.
Mi az a Mozaik AI Vector Search?
A Mozaik AI Vector Search egy vektoradatbázis, amely a Databricks Adatintelligencia-platformba van beépítve, és integrálva van az irányítási és hatékonyságnövelő eszközeivel. A vektoradatbázis olyan adatbázis, amely beágyazások tárolására és lekérésére van optimalizálva. A beágyazások az adatok szemantikai tartalmának matematikai ábrázolásai, jellemzően szöveges vagy képadatok. A beágyazásokat egy nagy nyelvi modell hozza létre, és számos GenAI-alkalmazás kulcsfontosságú összetevője, amelyek az egymáshoz hasonló dokumentumok vagy képek megtalálásától függenek. Ilyenek például a RAG-rendszerek, az ajánlórendszerek, valamint a kép- és videofelismerés.
A Mozaik AI Vektorkeresés funkcióval vektorkeresési indexet hozhat létre egy Delta-táblából. Az index metaadatokat tartalmazó beágyazott adatokat tartalmaz. Ezután egy REST API-val lekérdezheti az indexet a leginkább hasonló vektorok azonosításához és a kapcsolódó dokumentumok visszaadásához. Az indexet úgy strukturálhatja, hogy automatikusan szinkronizálja az alapul szolgáló Delta-tábla frissítésekor.
A Mozaik AI Vector Search a következőket támogatja:
- Hibrid kulcsszó-hasonlóság keresés.
- Szűrés.
- Hozzáférés-vezérlési listák (ACL-ek) a vektorkeresési végpontok kezeléséhez.
- Csak a kijelölt oszlopok szinkronizálása.
- A létrehozott beágyazások mentése és szinkronizálása.
Hogyan működik a Mozaik AI Vector Search?
A Mozaik AI Vector Search a hierarchikus Navigable Small World (HNSW) algoritmust használja a legközelebbi szomszédkeresésekhez, valamint az L2 távolságmetrikát a beágyazási vektor hasonlóságának méréséhez. Ha koszinusz hasonlóságot szeretne használni, normalizálnia kell a datapoint-beágyazásokat, mielőtt vektorkeresésbe eteti őket. Az adatpontok normalizálása esetén az L2 távolság által előállított rangsor megegyezik a koszinusza hasonlóság által előállított rangsorolással.
A Mozaik AI Vector Search támogatja a hibrid kulcsszó-hasonlósági keresést is, amely a vektoralapú beágyazási keresést a hagyományos kulcsszóalapú keresési technikákkal kombinálja. Ez a megközelítés megfelel a lekérdezés pontos szavainak, miközben vektoralapú hasonlósági keresést is használ a lekérdezés szemantikai kapcsolatainak és kontextusának rögzítéséhez.
E két módszer integrálásával a hibrid kulcsszó-hasonlóság keresés olyan dokumentumokat kér le, amelyek nem csak a pontos kulcsszavakat tartalmazzák, hanem azokat is, amelyek fogalmilag hasonlóak, átfogóbb és relevánsabb keresési eredményeket biztosítva. Ez a módszer különösen hasznos a RAG-alkalmazásokban, ahol a forrásadatok egyedi kulcsszavakkal, például termékváltozatokkal vagy olyan azonosítókkal rendelkeznek, amelyek nem alkalmasak a tiszta hasonlóság keresésére.
Az API-val kapcsolatos részletekért tekintse meg a Python SDK-referencia és a vektorkeresési végpont lekérdezése című témakört.
Hasonlóság keresési számítása
A hasonlósági keresés kiszámítása a következő képletet használja:
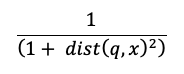
hol dist van a lekérdezés q és az indexbejegyzés xközötti euklideszi távolság:

Kulcsszókeresési algoritmus
A relevanciaértékek kiszámítása Okapi BM25 használatával történik. A rendszer az összes szöveg- vagy sztringoszlopot megkeresi, beleértve a forrásszöveg beágyazását és a metaadatoszlopokat szöveg- vagy sztringformátumban. A tokenizálási függvény a szavak határán oszlik el, eltávolítja az írásjeleket, és az összes szöveget kisbetűssé alakítja.
A hasonlóság keresése és a kulcsszókeresés kombinálva
A hasonlósági keresés és a kulcsszókeresési eredmények a Kölcsönös rangsor fúzió (RRF) függvény használatával vannak kombinálva.
Az RRF a pontszám használatával minden dokumentumot újramagyorsít az egyes metódusokból:

A fenti egyenletben a rangsor 0-nál kezdődik, összegzi az egyes dokumentumok pontszámait, és a legmagasabb pontszámot adja vissza.
rrf_param a magasabb és az alacsonyabb rangsorban lévő dokumentumok relatív jelentőségét. A szakirodalom rrf_param alapján 60-ra van állítva.
A pontszámok normalizálása úgy történik, hogy a legmagasabb pontszám 1, a legalacsonyabb pontszám pedig 0 legyen az alábbi egyenlet használatával:

Vektoros beágyazások biztosításának lehetőségei
Vektoradatbázis Databricksben való létrehozásához először el kell döntenie, hogyan biztosítson vektoros beágyazást. A Databricks három lehetőséget támogat:
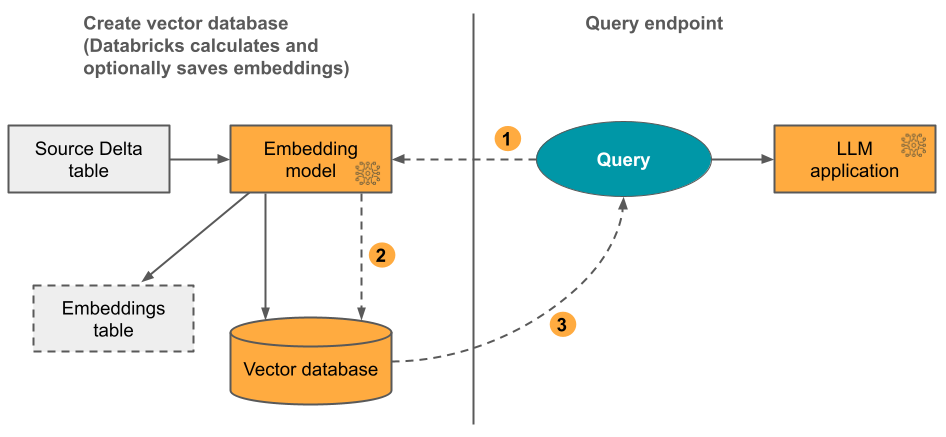
1. lehetőség: A Databricks által kiszámított beágyazásokkal rendelkező deltaszinkronizálási index: Adjon meg egy forrás delta táblát, amely szöveges formátumban tartalmaz adatokat. A Databricks kiszámítja a beágyazásokat egy ön által megadott modellel, és opcionálisan menti a beágyazásokat egy táblába a Unity Catalogban. A Delta-tábla frissítése során az index szinkronizálva marad a Delta táblával.
Az alábbi ábra a folyamatot szemlélteti:
- Lekérdezésbeágyazások kiszámítása. A lekérdezés metaadatszűrőket is tartalmazhat.
- A legtöbb releváns dokumentum azonosításához végezzen hasonlósági keresést.
- Adja vissza a legrelevánsabb dokumentumokat, és fűzze hozzá őket a lekérdezéshez.
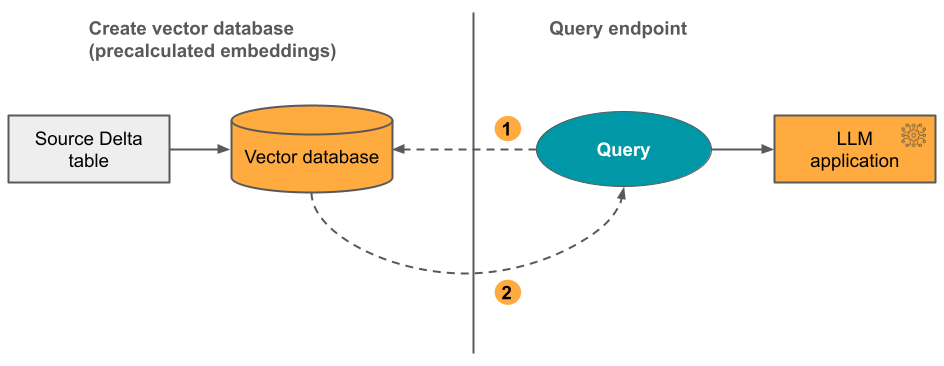
2. lehetőség: Delta Sync Index ön által felügyelt beágyazásokkal : Adjon meg egy forrás Delta-táblát, amely előre kiszámított beágyazásokat tartalmaz. A Delta-tábla frissítése során az index szinkronizálva marad a Delta táblával.
Az alábbi ábra a folyamatot szemlélteti:
- A lekérdezés beágyazásokból áll, és metaadatszűrőket is tartalmazhat.
- A legtöbb releváns dokumentum azonosításához végezzen hasonlósági keresést. Adja vissza a legrelevánsabb dokumentumokat, és fűzze hozzá őket a lekérdezéshez.
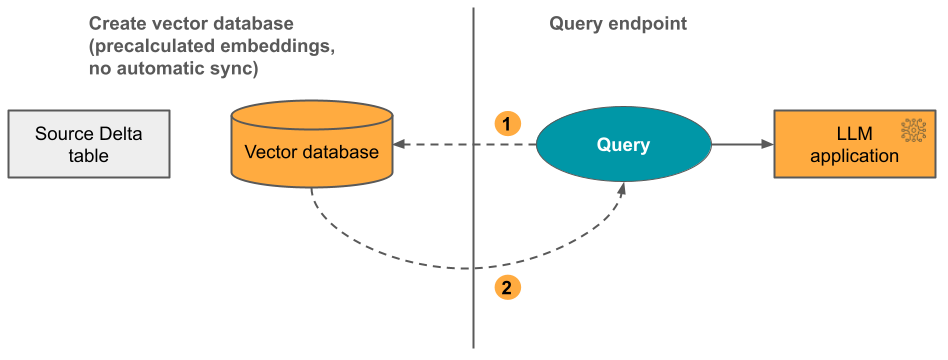
3. lehetőség: Közvetlen vektorelérési index : Manuálisan frissítenie kell az indexet a REST API használatával, amikor a beágyazási táblázat megváltozik.
Az alábbi ábra a folyamatot szemlélteti:
A Mozaik AI-vektorkeresés beállítása
A Mozaik AI Vector Search használatához a következőket kell létrehoznia:
- Vektorkeresési végpont. Ez a végpont a vektorkeresési indexet szolgálja ki. A végpontot a REST API vagy az SDK használatával kérdezheti le és frissítheti. A végpontok automatikusan skálázhatók az index méretének vagy az egyidejű kérések számának támogatásához. Útmutatásért lásd: Vektorkeresési végpont létrehozása.
- Vektorkeresési index. A vektorkeresési index egy Delta-táblából jön létre, és úgy van optimalizálva, hogy valós időben közelítő közelítő szomszédkereséseket biztosítson. A keresés célja a lekérdezéshez hasonló dokumentumok azonosítása. A vektorkeresési indexek a Unity Katalógusban jelennek meg, és azokat szabályozzák. Útmutatásért lásd : Vektorkeresési index létrehozása.
Emellett, ha úgy dönt, hogy a Databricks kiszámítja a beágyazásokat, használhat egy előre konfigurált Foundation Model API-végpontot, vagy létrehozhat egy végpontot kiszolgáló modellt a választott beágyazási modell kiszolgálásához. Útmutatásért lásd: Pay-per-token Foundation Model API-k vagy végpontokat kiszolgáló generatív AI-modell létrehozása.
A végpontot kiszolgáló modell lekérdezéséhez használja a REST API-t vagy a Python SDK-t. A lekérdezés a Delta tábla bármely oszlopa alapján definiálhat szűrőket. További részletekért lásd: Szűrők használata lekérdezéseken, API-referencia vagy Python SDK-referencia.
Követelmények
- Unity Catalog-kompatibilis munkaterület.
- A kiszolgáló nélküli számítás engedélyezve van. Útmutatásért lásd : Csatlakozás kiszolgáló nélküli számításhoz.
- A forrástáblának engedélyezve kell lennie az Adatcsatorna módosítása funkcióval. Útmutatásért lásd: Delta Lake change data feed on Azure Databricks.
- CREATE TABLE privileges on catalog schema(s) to create indexes.
- A személyes hozzáférési jogkivonatok engedélyezve.
A vektorkeresési végpontok létrehozásának és kezelésének engedélyezése hozzáférés-vezérlési listák használatával van konfigurálva. Lásd: Vektorkeresési végpont ACL-ek.
Adatvédelem és hitelesítés
A Databricks az alábbi biztonsági vezérlőket implementálja az adatok védelme érdekében:
- A Mozaik AI Vector Search szolgáltatáshoz érkező minden ügyfélkérés logikailag elkülönített, hitelesített és engedélyezett.
- A Mozaik AI Vector Search titkosítja az összes inaktív adatot (AES-256) és az átvitel alatt (TLS 1.2+).
A Mozaik AI Vector Search két hitelesítési módot támogat:
- Személyes hozzáférési jogkivonat – Személyes hozzáférési jogkivonattal hitelesíthet a Mozaik AI Vector Search szolgáltatással. Tekintse meg a személyes hozzáférési hitelesítési jogkivonatot. Ha az SDK-t jegyzetfüzet-környezetben használja, az automatikusan létrehoz egy PAT-jogkivonatot a hitelesítéshez.
- Szolgáltatásnév jogkivonata – A rendszergazda létrehozhat egy szolgáltatásnév-jogkivonatot, és átadhatja azt az SDK-nak vagy API-nak. Lásd: szolgáltatásnevek használata. Éles használat esetén a Databricks szolgáltatásnév-jogkivonat használatát javasolja.
Az ügyfél által felügyelt kulcsok (CMK) támogatottak a 2024. május 8-án vagy azt követően létrehozott végpontokon.
Használat és költségek figyelése
A számlázható használati rendszer tábla lehetővé teszi a vektorkeresési indexekkel és végpontokkal kapcsolatos használat és költségek monitorozását. Itt láthat egy példalekérdezést:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL
THEN 'ingest'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
SUM(usage_quantity) as dbus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
A számlázási használati tábla tartalmával kapcsolatos részletekért lásd a számlázható használati rendszer táblareferenciáját. A további lekérdezések a következő példajegyzetfüzetben találhatók.
Vektorkeresési rendszertáblák lekérdezései jegyzetfüzet
Erőforrás- és adatméretkorlátok
Az alábbi táblázat a vektorkeresési végpontok és indexek erőforrás- és adatméretkorlátjait foglalja össze:
| Erőforrás | Részletesség | Korlát |
|---|---|---|
| Vektorkeresési végpontok | Munkaterületenként | 100 |
| Beágyazások | Végpontonként | 320,000,000 |
| Beágyazási dimenzió | Indexenként | 4096 |
| Indexek | Végpontonként | 50 |
| Oszlopok | Indexenként | 50 |
| Oszlopok | Támogatott típusok: bájtok, rövid, egész szám, hosszú, lebegőpontos, kettős, logikai, sztring, időbélyeg, dátum | |
| Metaadatmezők | Indexenként | 20 |
| Index neve | Indexenként | 128 karakter |
A vektorkeresési indexek létrehozására és frissítésére az alábbi korlátozások vonatkoznak:
| Erőforrás | Részletesség | Korlát |
|---|---|---|
| A Delta Sync Index sormérete | Indexenként | 100 KB |
| Forrásoszlop méretének beágyazása a Delta Sync-indexhez | Indexenként | 32764 bájt |
| Direct Vector-index tömeges upsert kérésméretkorlátja | Indexenként | 10MB |
| Direct Vector-index tömeges törlési kérésméretkorlátja | Indexenként | 10MB |
A lekérdezési API-ra az alábbi korlátozások vonatkoznak.
| Erőforrás | Részletesség | Korlát |
|---|---|---|
| Szöveghossz lekérdezése | Lekérdezésenként | 32764 |
| Visszaadott eredmények maximális száma | Lekérdezésenként | 10,000. |
Korlátozások
- A sor- és oszlopszintű engedélyek nem támogatottak. A szűrő API használatával azonban saját alkalmazásszintű ACL-eket is implementálhat.