Databricks Autologging
Ez a lap bemutatja, hogyan szabhatja testre a Databricks autologgingt, amely automatikusan rögzíti a modellparamétereket, metrikákat, fájlokat és életútadatokat, amikor modelleket tanít be számos népszerű gépi tanulási kódtárból. A betanítási munkamenetek MLflow-nyomkövetési futtatásokként vannak rögzítve. A modellfájlokat is nyomon követi a rendszer, így könnyen naplózhatja őket az MLflow modellregisztrációs adatbázisában.
Feljegyzés
A generatív AI-számítási feladatok nyomkövetési naplózásának engedélyezéséhez az MLflow támogatja az OpenAI automatikus naplózását.
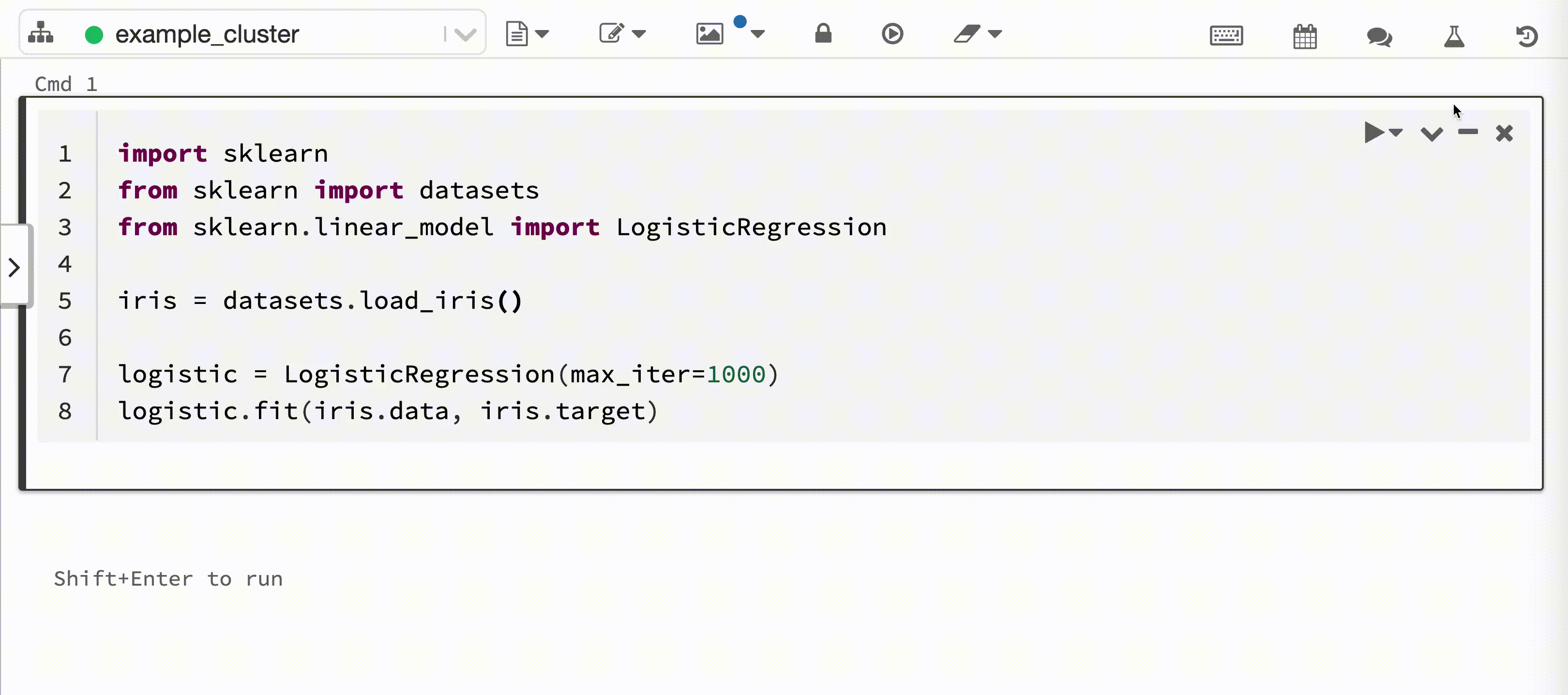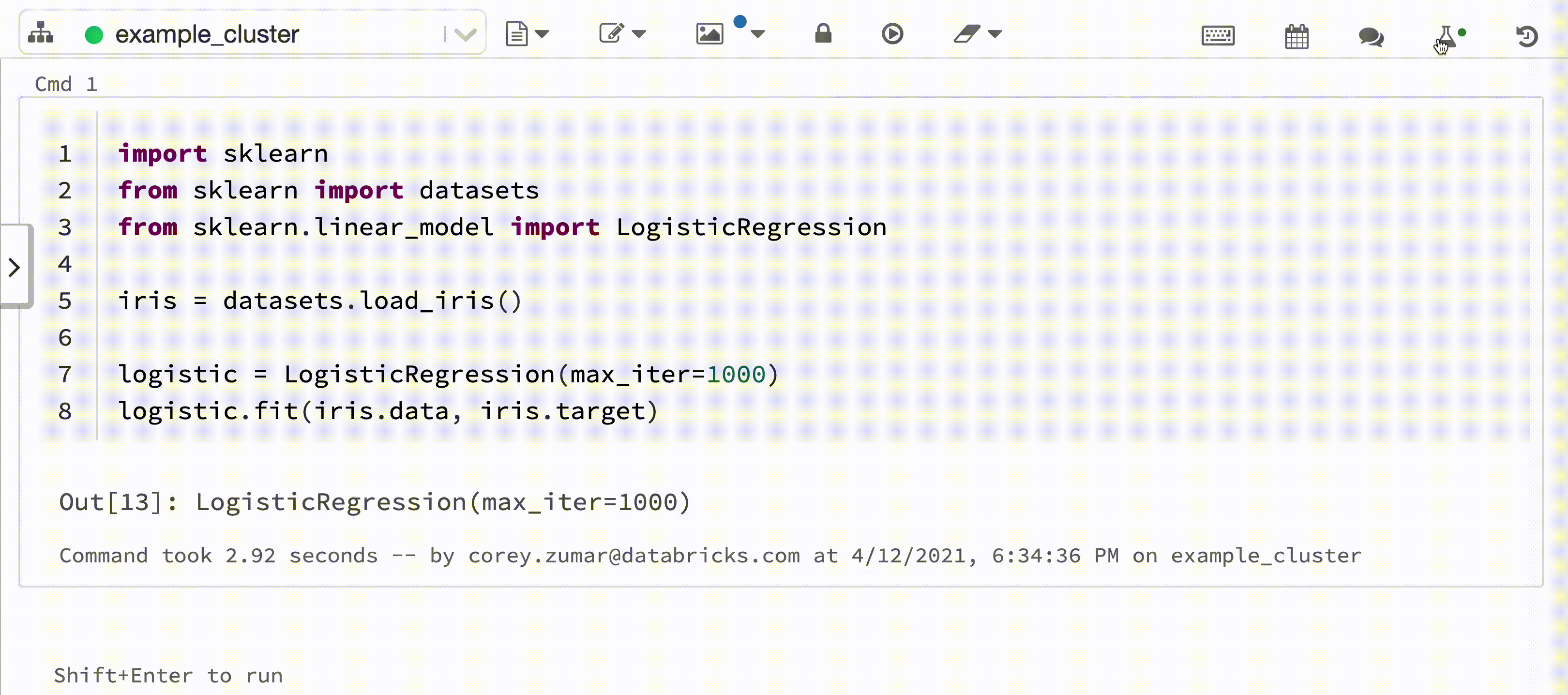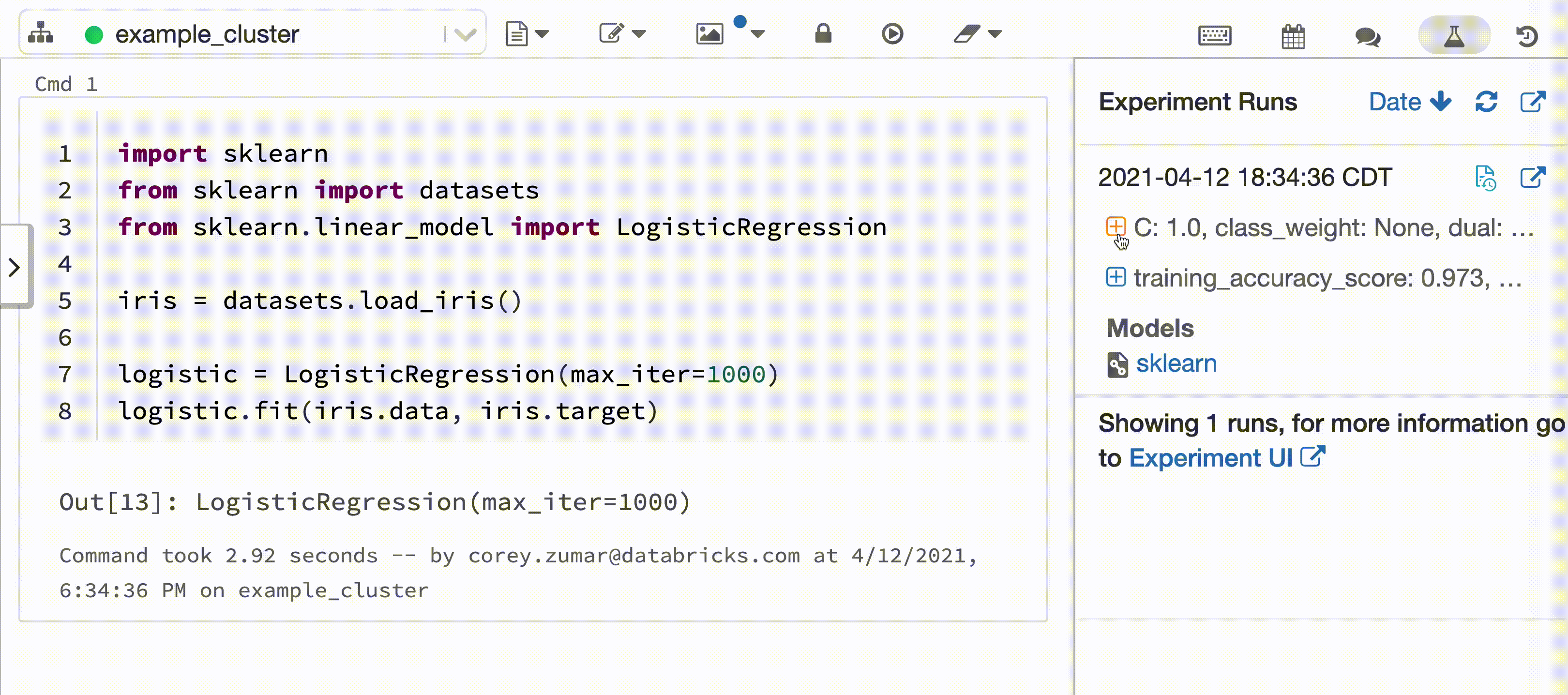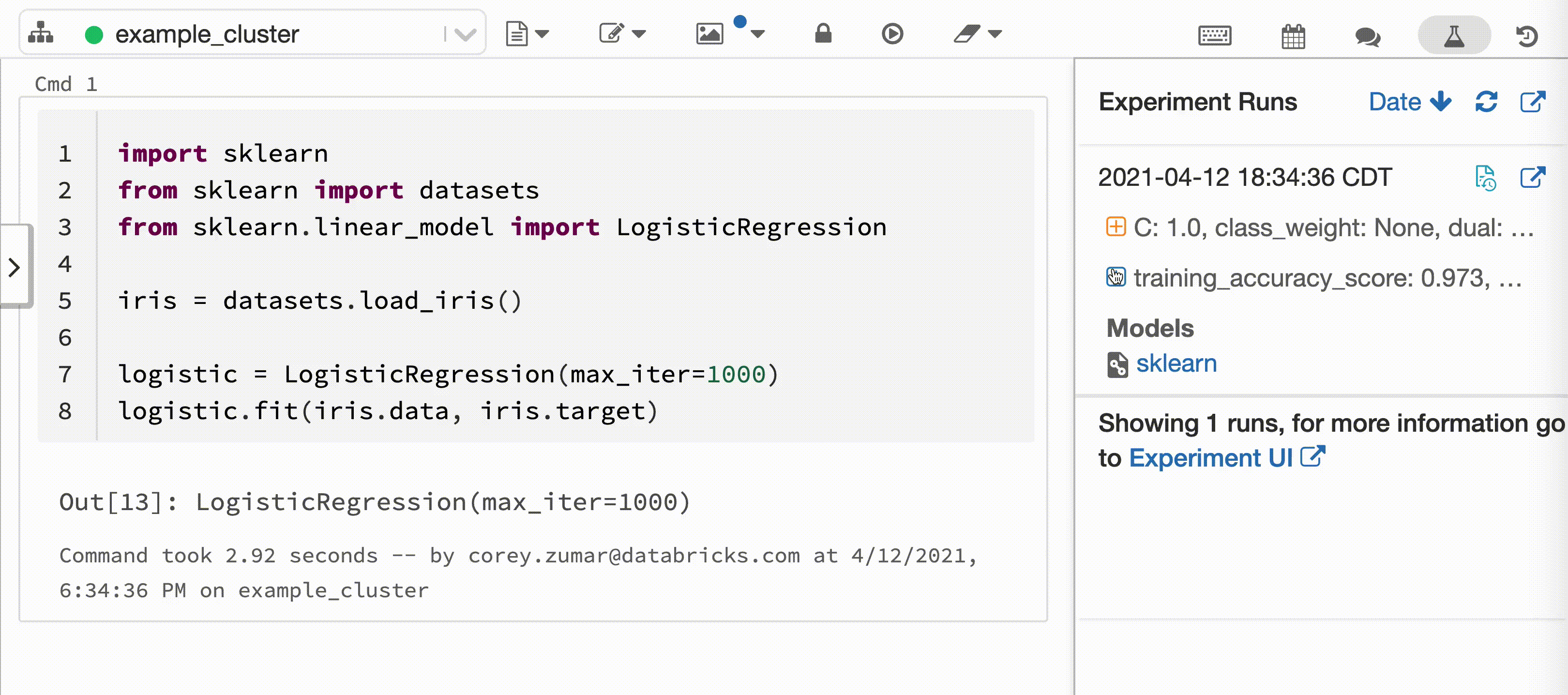
Az alábbi videó a Databricks autologging funkcióját mutatja be egy scikit-learn modell betanítási munkamenetével egy interaktív Python-jegyzetfüzetben. A rendszer automatikusan rögzíti és megjeleníti a követési adatokat a Kísérletfuttatások oldalsávon és az MLflow felhasználói felületén.
Követelmények
- A Databricks Autologging általában minden olyan régióban elérhető, ahol a Databricks Runtime 10.4 LTS ML vagy újabb verziójú.
- A Databricks Autologging a Databricks Runtime 9.1 LTS ML vagy újabb verziójú előzetes verziójú régiókban érhető el.
Hogyan működik?
Amikor interaktív Python-jegyzetfüzetet csatol egy Azure Databricks-fürthöz, a Databricks autologging meghívja az mlflow.autolog() parancsot, hogy beállítsa a modell betanítási munkameneteinek nyomon követését. Amikor modelleket tanít be a jegyzetfüzetben, a modell betanítási információi automatikusan nyomon lesznek követve az MLflow Tracking használatával. A modell betanítási adatainak védelméről és kezeléséről további információt a Biztonság és adatkezelés című témakörben talál.
A mlflow.autolog() hívás alapértelmezett konfigurációja a következő:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Testre szabhatja az automatikus kitöltési konfigurációt.
Használat
A Databricks Autologging használatához betanítsa a gépi tanulási modellt egy támogatott keretrendszerbe egy interaktív Azure Databricks Python-jegyzetfüzet használatával. A Databricks autologging automatikusan rögzíti a modell leállásadatait, paramétereit és metrikáit az MLflow Trackingbe. Testre is szabhatja a Databricks automatikus keresésének viselkedését.
Feljegyzés
A Databricks autologging nincs alkalmazva az MLflow fluent API-val mlflow.start_run()létrehozott futtatásokra. Ezekben az esetekben meg kell hívnia mlflow.autolog() , hogy mentse az automatikusan létrehozott tartalmat az MLflow-futtatásra. Lásd: További tartalom nyomon követése.
Naplózási viselkedés testreszabása
A naplózás testreszabásához használja a mlflow.autolog() parancsot.
Ez a függvény konfigurációs paramétereket biztosít a modellnaplózás (log_models), a naplóadatkészletek (log_datasets), a bemeneti példák (log_input_examples), a naplómodell-aláírások (log_model_signatures), a figyelmeztetések konfigurálásához (silentstb.) való engedélyezéséhez.
További tartalom nyomon követése
Ha további metrikákat, paramétereket, fájlokat és metaadatokat szeretne nyomon követni a Databricks Autologging által létrehozott MLflow-futtatásokkal, kövesse az alábbi lépéseket egy Azure Databricks interaktív Python-jegyzetfüzetben:
- Hívja meg a mlflow.autolog() függvényt a
exclusive=False. - MLflow-futtatás indítása mlflow.start_run() használatával.
Ezt a hívást
with mlflow.start_run()becsomagolhatja; ha ezt teszi, a futtatás automatikusan befejeződik a befejezés után. - A betanítás előtti tartalmak nyomon követéséhez MLflow-követési módszereket (például mlflow.log_param()) használjon.
- Egy vagy több gépi tanulási modell betanítása a Databricks Autologging által támogatott keretrendszerben.
- A betanítás utáni tartalmak nyomon követéséhez MLflow-követési módszereket (például mlflow.log_metric()) használjon.
- Ha nem használta
with mlflow.start_run()a 2. lépésben, fejezd be az MLflow futtatását a mlflow.end_run() használatával.
Példa:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
A Databricks automatikus naplózásának letiltása
Ha le szeretné tiltani a Databricks automatikus naplózását egy Azure Databricks interaktív Python-jegyzetfüzetben, hívja a mlflow.autolog() függvényt a következővel disable=True:
import mlflow
mlflow.autolog(disable=True)
A rendszergazdák letilthatják a Databricks automatikus naplózását a munkaterület összes fürtjéhez a Rendszergazdai beállítások lap Speciális lapján. A módosítás érvénybe lépéséhez újra kell indítani a fürtöket.
Támogatott környezetek és keretrendszerek
A Databricks Autologging interaktív Python-jegyzetfüzetekben támogatott, és a következő ML-keretrendszerekhez érhető el:
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluon
- Fast.ai
- statsmodels
- PaddlePaddle
- OpenAI
- LangChain
Az egyes támogatott keretrendszerekről további információt az MLflow automatikus naplózásában talál.
MLflow-nyomkövetés engedélyezése
Az MLflow Tracing a autolog megfelelő modell-keretrendszer-integrációkon belüli funkciót használja a nyomkövetési támogatás engedélyezésének vagy letiltásának szabályozására a nyomkövetést támogató integrációk esetében.
Ha például egy LlamaIndex-modell használatakor szeretné engedélyezni a nyomkövetést, használja a mlflow.llama_index.autolog() függvényt a következővel log_traces=True:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
Az autolog-implementációkban nyomkövetési engedélyező funkcióval rendelkező támogatott integrációk a következők:
Biztonság és adatkezelés
A Databricks autologging szolgáltatással nyomon követett modellbetanítási információk az MLflow Trackingben tárolódnak, és MLflow Kísérlet engedélyekkel védettek. Az MLflow Tracking API vagy a felhasználói felület használatával megoszthatja, módosíthatja vagy törölheti a modell betanítási adatait.
Felügyelet
A rendszergazdák engedélyezhetik vagy letilthatják a Databricks automatikus naplózását a munkaterület összes interaktív jegyzetfüzet-munkamenetéhez a Rendszergazdai beállítások lap Speciális lapján. A módosítások csak a fürt újraindítása után lépnek érvénybe.
Korlátozások
- A Databricks automatikus naplózása nem támogatott az Azure Databricks-feladatokban. A feladatok automatikus kitöltésének használatához explicit módon meghívhatja az mlflow.autolog()-t.
- A Databricks automatikus naplózása csak az Azure Databricks-fürt illesztőprogram-csomópontján engedélyezett. Ha a munkavégző csomópontokról szeretne automatikusan csatlakozni, az mlflow.autolog() parancsot explicit módon kell meghívnia az egyes feldolgozókon végrehajtó kódból.
- Az XGBoost scikit-learn integráció nem támogatott.
Apache Spark MLlib, Hyperopt és automatizált MLflow-nyomkövetés
A Databricks autologging nem változtatja meg az Apache Spark MLlib és a Hyperopt meglévő automatizált MLflow-követési integrációinak viselkedését.
Feljegyzés
A Databricks Runtime 10.1 ML-ben az Apache Spark MLlib CrossValidator és TrainValidationSplit a modellek automatizált MLflow-nyomkövetési integrációjának letiltása az összes Apache Spark MLlib-modellhez letiltja a Databricks autologging funkciót is.