Az adathozzáférés konfigurálásának engedélyezése
Ez a cikk az Azure Databricks rendszergazdái által a felhasználói felületet használó összes SQL-raktár adathozzáférési konfigurációit ismerteti.
Megjegyzés:
Ha a munkaterület engedélyezve van a Unity Cataloghoz, akkor nem kell elvégeznie a cikkben szereplő lépéseket. A Unity Catalog alapértelmezés szerint támogatja az SQL-raktárakat.
Ha az összes SQL Warehouse-t a REST API használatával szeretné konfigurálni, tekintse meg az SQL Warehouses API-t.
Fontos
A beállítások módosítása újraindítja az összes futó SQL-raktárat.
Az adatokhoz való hozzáférés engedélyezésének általános áttekintéséhez tekintse meg a Hozzáférés-vezérlés áttekintését.
Megjegyzés:
A Databricks a Unity Catalog-kötetek vagy külső helyek használatát javasolja a felhőobjektum-tárolóhoz való csatlakozáshoz a példányprofilok helyett. A Unity Catalog leegyszerűsíti az adatok biztonságát és szabályozását azáltal, hogy központi helyet biztosít az adatokhoz való hozzáférés felügyeletéhez és naplózásához a fiók több munkaterületén. Lásd: Mi a Unity Catalog? és Javaslatok a külső helyek használatáról.
Előkészületek
- Azure Databricks-munkaterület rendszergazdájának kell lennie az összes SQL-raktár beállításainak konfigurálásához.
Szolgáltatásnév konfigurálása
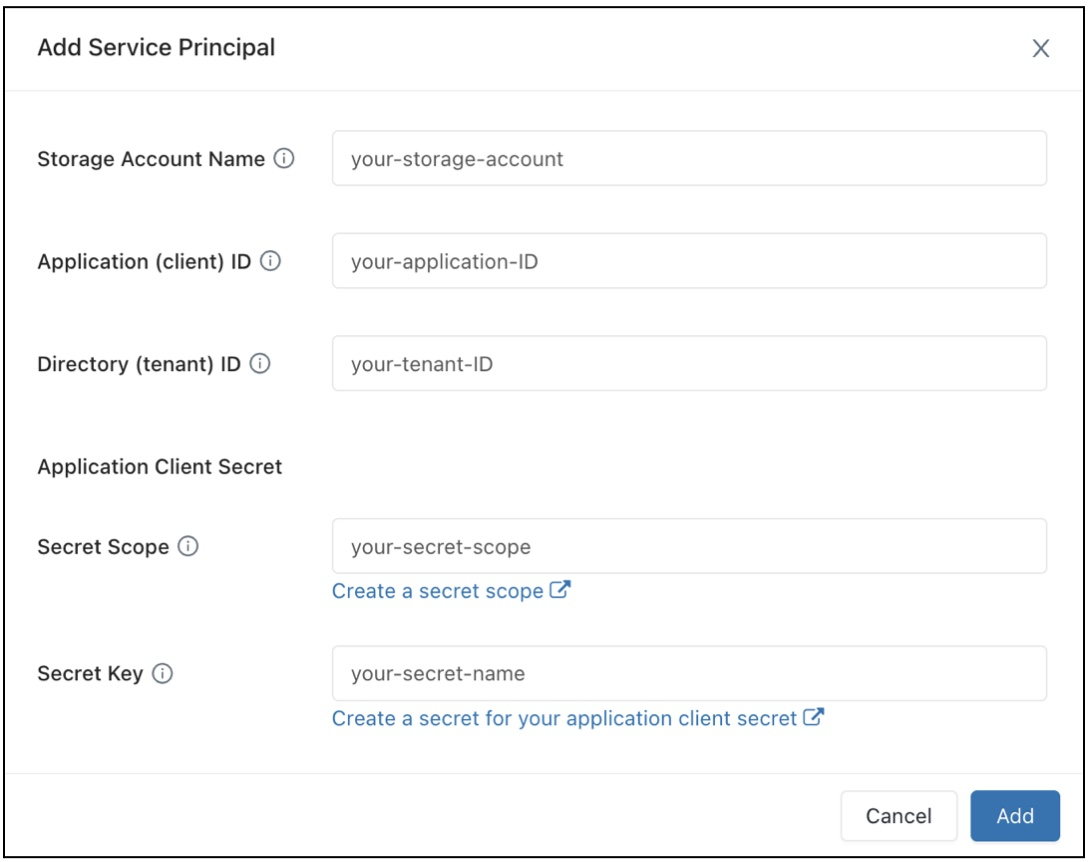
Ha szolgáltatásnevek használatával szeretné konfigurálni az SQL-tárolók hozzáférését egy Azure Data Lake Storage Gen2-tárfiókhoz, kövesse az alábbi lépéseket:
Regisztráljon egy Microsoft Entra ID-alkalmazást , és rögzítse a következő tulajdonságokat:
- Alkalmazás (ügyfél) azonosítója: A Microsoft Entra ID-alkalmazást egyedileg azonosító azonosító azonosító.
- Címtár-(bérlői) azonosító: A Microsoft Entra ID-példányt (az Azure Databricks címtár-(bérlői) azonosítóját egyedileg azonosító azonosító.
- Titkos ügyfélkód: Az alkalmazásregisztrációhoz létrehozott ügyfélkód értéke. Az alkalmazás ezt a titkos sztringet használja személyazonosságának igazolására.
A tárfiókban adjon hozzá egy szerepkör-hozzárendelést az előző lépésben regisztrált alkalmazáshoz, hogy hozzáférést biztosítson a tárfiókhoz.
Hozzon létre egy Azure Key Vault által támogatott titkos hatókört vagy egy Databricks-hatókörű titkos hatókört, és rögzítse a hatókörnév tulajdonság értékét:
- Hatókör neve: A létrehozott titkos kulcs hatókörének neve.
Ha az Azure Key Vaultot használja, lépjen a Titkos kódok szakaszra, és hozzon létre egy új titkos kulcsot egy tetszőleges névvel. Az 1. lépésben beszerzett "ügyféltitkot" használva töltse ki a titkos kód "érték" mezőjét. Jegyezze fel az imént választott titkos nevet.
- Titkos kód neve: A létrehozott Azure Key Vault-titkos kód neve.
Ha Databricks-alapú hatókört használ, hozzon létre egy új titkos kulcsot a Databricks parancssori felületével, és használja az 1. lépésben beszerzett ügyféltitkot. Jegyezze fel az ebben a lépésben megadott titkos kulcsot.
- Titkos kulcs: A létrehozott Databricks által támogatott titkos kód kulcsa.
Megjegyzés:
Szükség esetén létrehozhat egy további titkos kulcsot az 1. lépésben beszerzett ügyfélazonosító tárolásához.
Kattintson a felhasználónevére a munkaterület felső sávjában, és válassza Rendszergazda Gépház a legördülő menüből.
Kattintson az SQL Warehouse beállításai fülre.
Az Adatelérési konfiguráció mezőben kattintson a Szolgáltatásnév hozzáadása gombra.
Konfigurálja az Azure Data Lake Storage Gen2-tárfiók tulajdonságait.
Kattintson a Hozzáadás parancsra.
Látni fogja, hogy új bejegyzések lettek hozzáadva az Adatelérési konfiguráció szövegmezőhöz.
Kattintson a Mentés gombra.
Megjegyzés:
Az Adatelérési konfiguráció szövegmező bejegyzéseit közvetlenül is szerkesztheti.
Fontos
Ha egy konfigurációs tulajdonságot egy titkos kód értékére szeretne állítani anélkül, hogy a titkos értéket a Sparknak adja meg, állítsa az értéket a következőre {{secrets/<secret-scope>/<secret-name>}}: . Cserélje le <secret-scope> a titkos kulcs hatókörére és <secret-name> a titkos kód nevére. Az értéknek {{secrets/ és }} végződéssel kell kezdődnie. Erről a szintaxisról további információt a Spark konfigurációs tulajdonságában vagy környezeti változójában található titkos kódokra vonatkozó szintaxisban talál.
Adatelérési tulajdonságok konfigurálása SQL-raktárakhoz
Az adatelérési tulajdonságokkal rendelkező összes raktár konfigurálása:
Kattintson a felhasználónevére a munkaterület felső sávjában, és válassza Rendszergazda Gépház a legördülő menüből.
Kattintson az SQL Warehouse Gépház fülre.
Az Adatelérési konfiguráció szövegmezőben adja meg a metaadattár tulajdonságait tartalmazó kulcs-érték párokat.
Fontos
Ha egy Spark-konfigurációs tulajdonságot egy titkos kód értékére szeretne állítani anélkül, hogy a titkos értéket a Sparknak felfedi, állítsa az értéket a következőre
{{secrets/<secret-scope>/<secret-name>}}: . Cserélje le<secret-scope>a titkos kulcs hatókörére és<secret-name>a titkos kód nevére. Az értéknek a következővel{{secrets/kell kezdődnie, és azzal kell végződnie}}. Erről a szintaxisról további információt a Spark konfigurációs tulajdonságában vagy környezeti változójában található titkos kódokra vonatkozó szintaxisban talál.Kattintson a Mentés gombra.
Az adatelérési tulajdonságokat a Databricks Terraform szolgáltató és databricks_sql_global_config is konfigurálhatja.
Támogatott tulajdonságok
Az SQL-raktárak esetében az alábbi tulajdonságok támogatottak. Az előtaggal *végződő bejegyzés esetében az előtagon belüli összes tulajdonság támogatott. Például azt jelzi, spark.sql.hive.metastore.* hogy mindkettő spark.sql.hive.metastore.jarsspark.sql.hive.metastore.version támogatott, valamint minden más tulajdonság, amely a következővel spark.sql.hive.metastorekezdődik: .
Bizalmas információkat tartalmazó tulajdonságok esetén a bizalmas adatokat titkos kódban tárolhatja, és a tulajdonság értékét a titkos névre állíthatja az alábbi szintaxis használatával: secrets/<secret-scope>/<secret-name>
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
A tulajdonságok beállításáról további információt a Külső Hive metaadattárban talál.