Delta-táblastreamelés olvasása és írása
A Delta Lake mélyen integrálva van a Spark strukturált streameléssel readStream és writeStreama . A Delta Lake leküzdi a streamelési rendszerekhez és fájlokhoz általában kapcsolódó számos korlátozást, többek között a következőket:
- Kis késésű betöltéssel létrehozott kis fájlok szenesítése.
- A "pontosan egyszer" feldolgozás fenntartása egynél több streammel (vagy egyidejű kötegelt feladatokkal).
- Hatékonyan felderítheti, hogy mely fájlok újak, amikor fájlokat használ a stream forrásaként.
Feljegyzés
Ez a cikk a Delta Lake-táblák streamforrásként és fogadóként való használatát ismerteti. Ha tudni szeretné, hogyan tölthet be adatokat streamelő táblákkal a Databricks SQL-ben, olvassa el az Adatok betöltése streamtáblák használatával a Databricks SQL-ben című témakört.
A Delta Lake-hez való stream-statikus illesztésekről további információt a Stream-statikus illesztések című témakörben talál.
Delta-tábla forrásként
A strukturált streamelés növekményesen olvassa be a Delta-táblákat. Bár a streamelési lekérdezés aktív egy Delta-táblán, a rendszer idempotens módon dolgozza fel az új rekordokat a forrástábla új táblaverzióinak véglegesítéseként.
Az alábbi példakód egy streamelési olvasás konfigurálását mutatja be a táblanév vagy a fájl elérési útja alapján.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Fontos
Ha egy Delta-tábla sémája megváltozik, miután streamelési olvasás kezdődött a táblával, a lekérdezés meghiúsul. A legtöbb sémamódosítás esetén újraindíthatja a streamet a sémaeltérés feloldásához és a feldolgozás folytatásához.
A Databricks Runtime 12.2 LTS-ben és alatta nem streamelhet olyan Delta-táblából, amelyen engedélyezve van az oszlopleképezés, amely nem additív sémafejlődésen ment keresztül, például oszlopok átnevezése vagy elvetése. Részletekért lásd: Streamelés oszlopleképezéssel és sémamódosításokkal.
Bemeneti sebesség korlátozása
A mikro kötegek szabályozásához a következő lehetőségek állnak rendelkezésre:
maxFilesPerTrigger: Hány új fájlt kell figyelembe venni minden mikrokötegben. Az alapértelmezett érték 1000.maxBytesPerTrigger: Mennyi adat lesz feldolgozva az egyes mikrokötegekben. Ez a beállítás "soft max" értéket állít be, ami azt jelenti, hogy egy köteg körülbelül ennyi adatot dolgoz fel, és a korlátnál többet is feldolgozhat annak érdekében, hogy a streamlekérdezés előrehaladjon olyan esetekben, amikor a legkisebb bemeneti egység nagyobb ennél a korlátnál. Ez alapértelmezés szerint nincs beállítva.
Ha együtt maxFilesPerTriggerhasználjamaxBytesPerTrigger, a mikroköteg addig dolgozza fel az adatokat, amíg el nem éri a maxFilesPerTrigger korlátot.maxBytesPerTrigger
Feljegyzés
Ha a forrástábla tranzakciói a konfiguráció miatt logRetentionDuration törlődnek, és a streamelési lekérdezés megpróbálja feldolgozni ezeket a verziókat, a lekérdezés alapértelmezés szerint nem tudja elkerülni az adatvesztést. Beállíthatja, hogy false figyelmen kívül hagyja az failOnDataLoss elveszett adatokat, és folytassa a feldolgozást.
Delta Lake change data capture (CDC) hírcsatorna streamelése
A Delta Lake módosítja az adatcsatorna változásait egy Delta-táblában, beleértve a frissítéseket és a törléseket is. Ha engedélyezve van, streamelhet a változásadatcsatornából és az írási logikából a beszúrások, frissítések és törlések feldolgozásához alsóbb rétegbeli táblákba. Bár a változási adatcsatorna adatkimenete kissé eltér az általa leírt Delta-táblától, ez megoldást nyújt a növekményes változások propagálására az alsóbb rétegbeli táblákra a medallion architektúrában.
Fontos
A Databricks Runtime 12.2 LTS-ben és alatta nem streamelhet a változásadatcsatornából olyan Delta-tábla esetében, amelynek oszlopleképezése engedélyezve van, és amely nem additív sémafejlődésen ment keresztül, például oszlopok átnevezése vagy elvetése. Lásd: Streamelés oszlopleképezéssel és sémamódosításokkal.
Frissítések és törlések mellőzése
A strukturált streamelés nem kezeli a nem hozzáfűző bemeneteket, és kivételt okoz, ha bármilyen módosítás történik a forrásként használt táblán. Az alsóbb rétegben nem automatikusan propagált változások kezelésére két fő stratégia létezik:
- Törölheti a kimenetet és az ellenőrzőpontot, és az elejétől újraindíthatja a streamet.
- A következő két lehetőség közül választhat:
ignoreDeletes: figyelmen kívül hagyja azokat a tranzakciókat, amelyek adatokat törölnek a partícióhatárokon.skipChangeCommits: hagyja figyelmen kívül a meglévő rekordokat törlő vagy módosító tranzakciókat.skipChangeCommitsalösszegekignoreDeletes.
Feljegyzés
A Databricks Runtime 12.2 LTS-ben és újabb skipChangeCommits verziókban elavult az előző beállítás ignoreChanges. A Databricks Runtime 11.3 LTS-ben és az alacsonyabb ignoreChanges verzióban ez az egyetlen támogatott lehetőség.
A szemantikája ignoreChanges jelentősen eltér a skipChangeCommits. Ha ignoreChanges engedélyezve van, a forrástáblában lévő újraírt adatfájlok újra ki lesznek bocsátva egy adatmódosítási művelet után, például UPDATE: , MERGE INTODELETE (partíciókon belül) vagy OVERWRITE. A változatlan sorokat gyakran új sorok mellett bocsátják ki, így az alsóbb rétegbeli fogyasztóknak képesnek kell lenniük az ismétlődések kezelésére. A rendszer nem propagálja a törléseket az alsóbb rétegben. ignoreChanges alösszegek ignoreDeletes.
skipChangeCommits teljes mértékben figyelmen kívül hagyja a fájlmódosítási műveleteket. Azok az adatfájlok, amelyeket a forrástáblában az adatmódosítási művelet ( például UPDATEa , MERGE INTO, ) DELETEmiatt írnak át, és OVERWRITE teljes mértékben figyelmen kívül hagyják. A felsőbb rétegbeli forrástáblák változásainak tükrözéséhez külön logikát kell implementálnia a módosítások propagálásához.
A konfigurált számítási feladatok továbbra is ismert szemantikával ignoreChanges működnek, de a Databricks az összes új számítási feladat használatát skipChangeCommits javasolja. A számítási feladatok ignoreChanges migrálása újrabontási logikát skipChangeCommits igényel.
Példa
Tegyük fel például, hogy van egy táblája dateuser_events , user_emailés action az oszlopokat particionáltadate. A táblázatból user_events streamelhet, és a GDPR miatt törölnie kell belőle az adatokat.
Ha partícióhatárokon töröl (vagyis WHERE egy partícióoszlopon van), a fájlok már érték szerint vannak szegmentálva, így a törlés egyszerűen eltávolítja ezeket a fájlokat a metaadatokból. Ha egy teljes adatpartíciót töröl, az alábbiakat használhatja:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Ha több partícióban töröl adatokat (ebben a példában a szűrésre user_email), használja a következő szintaxist:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Ha módosít egy utasítást user_email UPDATE , a szóban forgó fájlt tartalmazó user_email fájl újra lesz írva. A módosított adatfájlok figyelmen kívül hagyása skipChangeCommits .
Kezdeti pozíció megadása
Az alábbi beállítások segítségével a Delta Lake streamelési forrásának kiindulópontját a teljes tábla feldolgozása nélkül adhatja meg.
startingVersion: A Delta Lake-verzió, amelyből kiindulni szeretne. A Databricks azt javasolja, hogy a legtöbb számítási feladat esetében kihagyja ezt a lehetőséget. Ha nincs beállítva, a stream a legújabb elérhető verziótól indul, beleértve az adott pillanatban a táblázat teljes pillanatképét.Ha meg van adva, a stream beolvassa a Delta-tábla minden módosítását a megadott verziótól kezdve (a teljes verziót is beleértve). Ha a megadott verzió már nem érhető el, a stream nem indul el. A véglegesítési verziókat a
versionDESCRIBE HISTORY parancs kimenetének oszlopából szerezheti be.Ha csak a legújabb módosításokat szeretné visszaadni, adja meg a következőt
latest: .startingTimestamp: A kezdéshez megadott időbélyeg. Az időbélyegen vagy után véglegesített összes táblamódosítást (beleértve) a streamolvasó felolvassa. Ha a megadott időbélyeg megelőzi az összes tábla véglegesítését, a streamelési olvasás a legkorábbi elérhető időbélyeggel kezdődik. Az alábbiak egyike:- Időbélyeg-sztring. Például:
"2019-01-01T00:00:00.000Z". - Dátumsztring. Például:
"2019-01-01".
- Időbélyeg-sztring. Például:
A két beállítás egyszerre nem állítható be. Ezek csak új streamelési lekérdezés indításakor lépnek érvénybe. Ha egy streamlekérdezés elindult, és a folyamat az ellenőrzőponton lett rögzítve, a rendszer figyelmen kívül hagyja ezeket a beállításokat.
Fontos
Bár a streamforrást elindíthatja egy megadott verzióról vagy időbélyegről, a streamforrás sémája mindig a Delta-tábla legújabb sémája. Győződjön meg arról, hogy a megadott verzió vagy időbélyeg után nem történt inkompatibilis sémamódosítás a Delta táblában. Ellenkező esetben előfordulhat, hogy a streamforrás helytelen eredményeket ad vissza, amikor helytelen sémával olvassa be az adatokat.
Példa
Tegyük fel például, hogy van egy táblája user_events. Ha az 5. verzió óta szeretné elolvasni a módosításokat, használja a következőt:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Ha 2018-10-18 óta szeretné elolvasni a módosításokat, használja a következőt:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Kezdeti pillanatkép feldolgozása adatok elvetés nélkül
Feljegyzés
Ez a funkció a Databricks Runtime 11.3 LTS-en és újabb verziókban érhető el. Ez a funkció a nyilvános előzetes verzióban érhető el.
Ha deltatáblát használ streamforrásként, a lekérdezés először feldolgozza a táblában található összes adatot. Az ebben a verzióban található Delta-táblát kezdeti pillanatképnek nevezzük. Alapértelmezés szerint a Delta-tábla adatfájljai a legutóbb módosított fájl alapján lesznek feldolgozva. Az utolsó módosítási idő azonban nem feltétlenül a rekord eseményidejének sorrendjét jelöli.
Egy meghatározott vízjelet tartalmazó állapotalapú streamlekérdezésben a fájlok módosítási idő szerinti feldolgozása azt eredményezheti, hogy a rekordok feldolgozása helytelen sorrendben történik. Ez azt eredményezheti, hogy a rekordok a vízjel késői eseményeiként csökkennek.
Az adatcseppek problémáját az alábbi beállítás engedélyezésével kerülheti el:
- withEventTimeOrder: Azt jelzi, hogy a kezdeti pillanatképet eseményidőrenddel kell-e feldolgozni.
Ha az esemény időrendje engedélyezve van, a kezdeti pillanatképadatok eseményideje időgyűjtőkre van osztva. Minden mikro köteg feldolgoz egy gyűjtőt az időtartományon belüli adatok szűrésével. A maxFilesPerTrigger és a maxBytesPerTrigger konfigurációs beállítások továbbra is alkalmazhatók a mikrobatch méretének szabályozására, de csak hozzávetőlegesen a feldolgozás jellege miatt.
Az alábbi ábrán ez a folyamat látható:
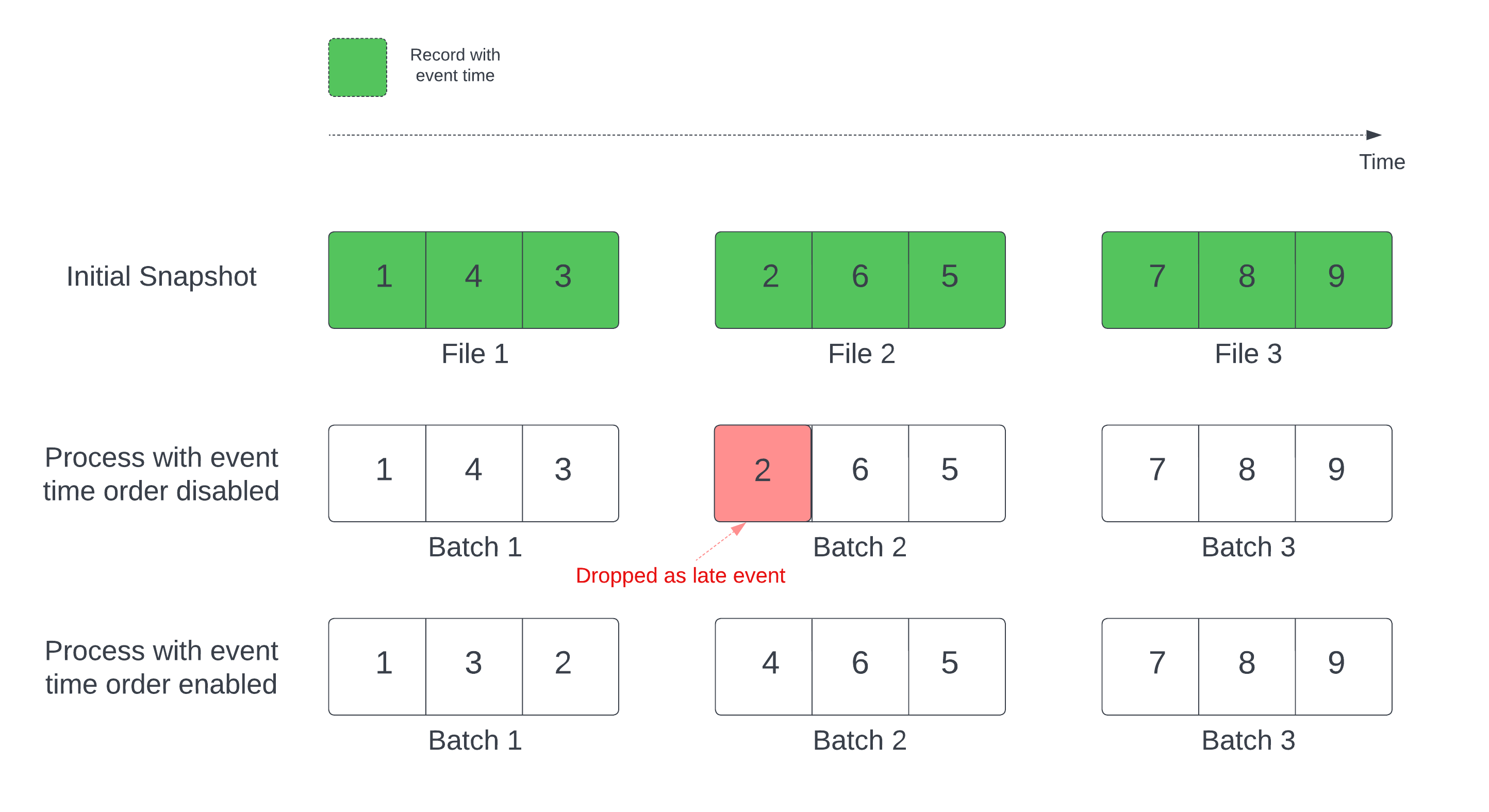
A funkcióval kapcsolatos jelentős információk:
- Az adatcsepp-probléma csak akkor fordul elő, ha egy állapotalapú streamelési lekérdezés kezdeti Delta-pillanatképe az alapértelmezett sorrendben van feldolgozva.
- A stream lekérdezés elindítása után nem módosítható
withEventTimeOrdera kezdeti pillanatkép feldolgozása. Ha módosítani szeretné azwithEventTimeOrderújraindítást, törölnie kell az ellenőrzőpontot. - Ha olyan stream-lekérdezést futtat, amelyen engedélyezve van az EventTimeOrder, nem állíthatja vissza olyan DBR-verzióra, amely nem támogatja ezt a funkciót, amíg a kezdeti pillanatkép-feldolgozás be nem fejeződik. Ha vissza kell állítania, megvárhatja a kezdeti pillanatkép befejezését, vagy törölheti az ellenőrzőpontot, és újraindíthatja a lekérdezést.
- Ez a funkció nem támogatott a következő gyakori forgatókönyvekben:
- Az eseményidő oszlop egy generált oszlop, és nem vetületi átalakítások vannak a Delta-forrás és a vízjel között.
- Van egy vízjel, amely több Delta-forrással rendelkezik a stream lekérdezésben.
- Ha az esemény időrendje engedélyezve van, a Delta kezdeti pillanatképének feldolgozása lassabb lehet.
- Minden mikro köteg megvizsgálja a kezdeti pillanatképet, hogy a megfelelő eseményidőtartományon belül szűrje az adatokat. A gyorsabb szűrőművelet érdekében érdemes delta forrásoszlopot használni eseményidőként, hogy az adatok kihagyása alkalmazható legyen (ellenőrizze , hogy a Delta Lake mikor hagyja ki az adatokat). Emellett a tábla particionálása az eseményidő oszlop mentén tovább felgyorsíthatja a feldolgozást. A Spark felhasználói felületén ellenőrizheti, hogy egy adott mikro köteg hány deltafájlt vizsgál.
Példa
Tegyük fel, hogy van egy oszlopot tartalmazó event_time táblázatauser_events. A streamelési lekérdezés egy összesítő lekérdezés. Ha biztosítani szeretné, hogy a pillanatképek kezdeti feldolgozása során ne csökkenjen az adat, a következőt használhatja:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Feljegyzés
Ezt a fürt Spark-konfigurációjával is engedélyezheti, amely az összes streamelési lekérdezésre vonatkozik: spark.databricks.delta.withEventTimeOrder.enabled true
Delta-tábla fogadóként
A Strukturált streamelés használatával adatokat is írhat a Delta-táblába. A tranzakciónapló lehetővé teszi, hogy a Delta Lake pontosan egyszeri feldolgozást garantáljon, még akkor is, ha más streamek vagy kötegelt lekérdezések futnak párhuzamosan a táblán.
Feljegyzés
A Delta Lake VACUUM függvény eltávolítja a Delta Lake által nem kezelt összes fájlt, de kihagyja a _kezdőkönyvtárakat. A Delta-táblákhoz tartozó egyéb adatokkal és metaadatokkal együtt biztonságosan tárolhat ellenőrzőpontokat egy olyan könyvtárstruktúra használatával, mint például <table-name>/_checkpointsa .
Mérőszámok
Megtudhatja, hogy hány bájtot és hány fájlt kell még feldolgozni egy streamelési lekérdezési folyamatban, mint a numBytesOutstanding metrikákat.numFilesOutstanding További metrikák:
numNewListedFiles: Azon Delta Lake-fájlok száma, amelyek a köteg hátralékának kiszámításához lettek felsorolva.backlogEndOffset: A hátralék kiszámításához használt táblaverzió.
Ha egy jegyzetfüzetben futtatja a streamet, a streamelési lekérdezés folyamatának irányítópultján, a Nyers adatok lapon láthatja ezeket a metrikákat:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Hozzáfűzési mód
Alapértelmezés szerint a streamek hozzáfűzési módban futnak, amely új rekordokat ad hozzá a táblához.
Használja a metódust toTable táblákba való streameléskor, ahogyan az alábbi példában is látható:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Kész mód
A strukturált streamelés használatával a teljes táblázatot lecserélheti minden kötegre. Az egyik példahasználati eset egy összegzés kiszámítása összesítéssel:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Az előző példa folyamatosan frissít egy táblát, amely az ügyfelek által összesített események számát tartalmazza.
Az enyhébb késési követelményekkel rendelkező alkalmazások esetében egyszeri eseményindítókkal mentheti a számítási erőforrásokat. Ezekkel frissítheti az összefoglaló aggregációs táblákat egy adott ütemezés szerint, és csak az utolsó frissítés óta érkezett új adatokat dolgozza fel.
Upsert a streamelési lekérdezésekből a következő használatával: foreachBatch
Összetett upsertek kombinációját és írását használhatja merge foreachBatch egy streamelési lekérdezésből egy Delta-táblába. Lásd: A foreachBatch használata tetszőleges adatelnyelőkbe való íráshoz című témakört.
Ez a minta számos alkalmazást tartalmaz, köztük a következőket:
- Stream-aggregátumok írása frissítési módban: Ez sokkal hatékonyabb, mint a teljes mód.
- Adatbázisváltozások adatfolyamának írása Delta-táblába: A változásadatok írására szolgáló egyesítési lekérdezés használatával
foreachBatchfolyamatosan alkalmazhatja a változásfolyamot egy Delta-táblára. - Adatstream írása Delta-táblába deduplikációval: A deduplikációra vonatkozó csak beszúrási egyesítési lekérdezés használatával
foreachBatchfolyamatosan írhat adatokat (duplikációkkal) egy Delta-táblába automatikus deduplikációval.
Feljegyzés
- Győződjön meg arról, hogy a
mergebelsőforeachBatchutasítás idempotens, mivel a streamelési lekérdezés újraindításai többször is alkalmazhatják a műveletet ugyanazon az adatkötegen. - Amikor
mergehasználatbanforeachBatchvan, a streamelési lekérdezés bemeneti adatsebessége (a notebook sebességi grafikonján keresztülStreamingQueryProgressjelentve és látható) a forrásnál az adatok létrehozásának tényleges sebességének többszöröseként jelenhet meg. Ennek az az oka, hogymergetöbbször olvassa be a bemeneti adatokat, ami a bemeneti metrikák szorzását okozza. Ha szűk keresztmetszetről van szó, gyorsítótárazhatja a kötegelt DataFrame-et a(z)mergeelőtt , majdmergeután törölheti.
Az alábbi példa bemutatja, hogyan használhatja az SQL-t foreachBatch a feladat végrehajtásához:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
A Delta Lake API-k használatával streamelési upserts-eket is végrehajthat, ahogyan az alábbi példában is látható:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Idempotens tábla írása foreachBatch
Feljegyzés
A Databricks azt javasolja, hogy minden frissíteni kívánt fogadóhoz külön streamelési írást konfiguráljon. Ha foreachBatch több táblába szeretne írni, szerializálja az írásokat, ami csökkenti a párhuzamosságokat, és növeli az általános késést.
A Delta-táblák az alábbi DataFrameWriter lehetőségeket támogatják, hogy idempotensen belül foreachBatch több táblába is írjanak:
txnAppId: Egyedi sztring, amelyet az egyes DataFrame-írások továbbíthatnak. Használhatja például a StreamingQuery azonosítóttxnAppId.txnVersion: Egy monoton módon növekvő szám, amely tranzakciós verzióként működik.
A Delta Lake az ismétlődő írások kombinációját txnAppId és txnVersion azonosítását használja, és figyelmen kívül hagyja őket.
Ha egy kötegírás meghiúsul, a köteg újrafuttatása ugyanazzal az alkalmazással és kötegazonosítóval segíti a futtatókörnyezetet az ismétlődő írások helyes azonosításában és figyelmen kívül hagyásában. Az alkalmazásazonosító (txnAppId) bármely felhasználó által létrehozott egyedi sztring lehet, és nem kell kapcsolódnia a streamazonosítóhoz. Lásd: A foreachBatch használata tetszőleges adatelnyelőkbe való íráshoz című témakört.
Figyelmeztetés
Ha törli a streamelési ellenőrzőpontot, és egy új ellenőrzőponttal újraindítja a lekérdezést, egy másikat txnAppIdkell megadnia. Az új ellenőrzőpontok a kötegazonosítóval kezdődnek 0. A Delta Lake a kötegazonosítót használja txnAppId egyedi kulcsként, és kihagyja a már látott értékeket tartalmazó kötegeket.
Az alábbi példakód ezt a mintát mutatja be:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}