Többhelyes és többrégiós összevonás
Számos kifinomult megoldás megköveteli, hogy ugyanazokat az eseménystreameket több helyen is elérhetővé lehessen tenni fogyasztásra, vagy az eseménystreameket több helyen kell összegyűjteni, majd egy adott felhasználási helyre kell konszolidálni. Gyakran szükség van az eseménystreamek dúsítására vagy csökkentésére, vagy az eseményformátumok konvertálására, akár egyetlen régión és megoldáson belül is.
Ez gyakorlatilag azt jelenti, hogy a megoldás több Event Hubs-központot fog fenntartani, gyakran különböző régiókban és Event Hubs-névterekben, majd replikálja közöttük az eseményeket. Eseményeket is cserélhet olyan forrásokkal és célokkal, mint az Azure Service Bus, az Azure IoT Hub vagy az Apache Kafka.
Ha több aktív eseményközpontot tart fenn különböző régiókban, az ügyfelek választhatnak és válthatnak közöttük, ha egyesítve vannak a tartalmaik, ami ellenállóbbá teszi az általános rendszert a regionális rendelkezésre állási problémákkal szemben.
Ez az "Összevonás" fejezet bemutatja az összevonási mintákat, és azt, hogyan valósíthatja meg ezeket a mintákat a kiszolgáló nélküli Azure Stream Analytics vagy az Azure Functions-futtatókörnyezetek használatával, azzal a lehetőséggel, hogy saját átalakítást vagy bővítési kódot használhat közvetlenül az eseményfolyamat útvonalán.
Összevonási minták
Számos lehetséges motivációja lehet annak, hogy miért érdemes eseményeket áthelyezni különböző Eseményközpontok vagy más források és célok között, és számba vesszük a jelen szakaszban szereplő legfontosabb mintákat, és az adott mintához kapcsolódó részletesebb útmutatásra is hivatkozunk.
- Rugalmasság a regionális rendelkezésre állási események ellen
- Késés optimalizálása
- Ellenőrzés, csökkentés és bővítés
- Integráció az elemzési szolgáltatásokkal
- Eseménystreamek konszolidálása és normalizálása
- Eseménystreamek felosztása és útválasztása
- Naplóvetítések
Rugalmasság a regionális rendelkezésre állási események ellen
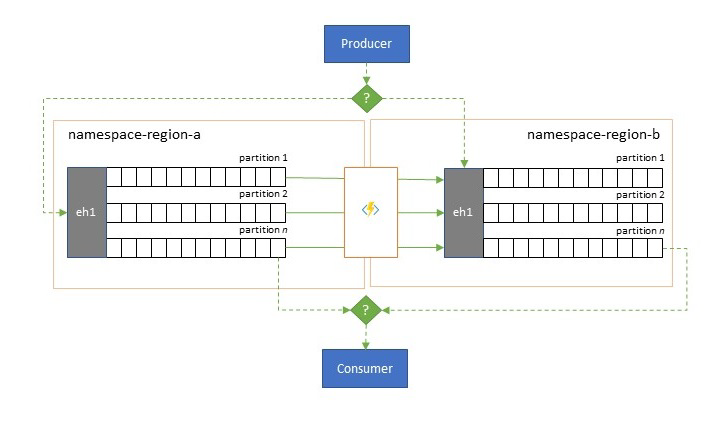
Bár a maximális rendelkezésre állás és a megbízhatóság az Event Hubs legfontosabb üzemeltetési prioritásai közé tartozik, mégis számos módon akadályozható meg, hogy egy gyártó vagy fogyasztó a hálózatkezelési vagy névfeloldási problémák miatt beszéljen a hozzárendelt "elsődleges" eseményközpontokkal, vagy ha az Eseményközpontok átmenetileg nem válaszolnak vagy hibákat adnak vissza.
Az ilyen feltételek nem "katasztrofálisak", ezért teljesen fel kell hagynia a regionális üzembe helyezéssel, mint egy vészhelyreállítási helyzetben, de egyes alkalmazások üzleti forgatókönyvét már befolyásolhatják a néhány percnél vagy akár másodpercnél hosszabb rendelkezésre állási események.
Az ilyen forgatókönyvek kezelésére két alapvető minta létezik:
- A replikációs minta az elsődleges Eseményközpontok tartalmának egy másodlagos Eseményközpontba történő replikálásáról szól, amely szerint az elsődleges Event Hubsot általában az alkalmazás használja az események előállításához és felhasználásához, a másodlagos pedig tartalék megoldásként szolgál arra az esetre, ha az elsődleges Event Hubs elérhetetlenné válik. Mivel a replikáció egyirányú, az elsődlegesről a másodlagosra, a gyártók és a fogyasztók átállítása a nem elérhető elsődlegesről a másodlagosra azt eredményezi, hogy a régi elsődleges nem kap új eseményeket, ezért az már nem lesz aktuális. A tiszta replikáció ezért csak egyirányú feladatátvételi forgatókönyvekhez alkalmas. A feladatátvételt követően a régi elsődleges elem elhagyva lesz, és egy új másodlagos Eseményközpontot kell létrehozni egy másik célrégióban.
- Az egyesítési minta két vagy több Event Hubs tartalmának folyamatos egyesítésével kibővíti a replikációs mintát. A rendszer az eredetileg a sémában szereplő eseményközpontok egyikébe előállított eseményeket replikálja a másik Event Hubsba. Az események replikálása során a rendszer úgy jegyzeteli őket, hogy a replikációs cél replikációs folyamata ezt követően figyelmen kívül hagyja őket. Az egyesítési minta használatának eredménye két vagy több Event Hub, amelyek ugyanazt az eseménykészletet fogják tartalmazni végül konzisztens módon.
Az Event Hubs tartalma mindkét esetben nem lesz azonos. Az egy gyártótól származó és ugyanazon partíciókulcs szerint csoportosított események az eredetileg beküldött relatív sorrendben jelennek meg, de az események abszolút sorrendje eltérhet. Ez különösen igaz azokra a forgatókönyvekre, amelyekben a forrás és a cél Event Hubs partíciószáma eltér, ami az itt ismertetett kiterjesztett minták közül több esetében is kívánatos. Az elválasztó vagy útválasztók egy sokkal nagyobb Event Hubs-szeletet szerezhetnek be több száz partícióval és tölcsérrel egy kisebb Event Hubsba, amely csak néhány partícióval rendelkezik, és alkalmasabb az alhalmaz korlátozott feldolgozási erőforrásokkal való kezelésére. Ezzel szemben az összesítés több kisebb Event Hub adatait egyetlen, nagyobb Event Hubs-ra bonthatja, amely több partícióval rendelkezik az összesített átviteli sebesség és a feldolgozási igények kielégítése érdekében.
Az események együttes megőrzésének feltétele a partíciókulcs, nem pedig az eredeti partícióazonosító. A replikációs minta leírásában további szempontokat ismerhet meg a relatív sorrendről, valamint arról, hogy hogyan hajthat végre feladatátvételt az egyik Event Hubsról a következőre anélkül, hogy a streameltolások hatókörére támaszkodik.
Útmutató:
Késés optimalizálása
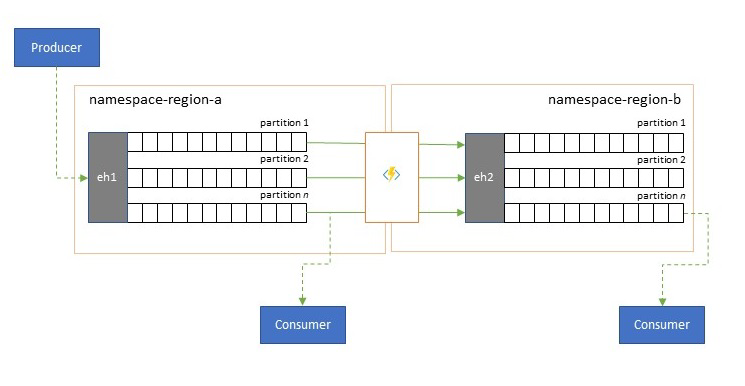
Az eseménystreameket a gyártók egyszer írják, de az eseményfogyasztók tetszőleges számú alkalommal elolvashatják. Olyan forgatókönyvek esetén, amikor egy régió eseménystreamjét több felhasználó is megosztja, és egy másik régióban található elemzési feldolgozás során többször is hozzá kell férni, vagy az egyidejű felhasználókat éhező igények miatt előnyös lehet az eseménystream egy példányát az elemzési processzor közelében elhelyezni a kerekítési késés csökkentése érdekében.
Jó példák arra, amikor a replikációt előnyben kell részesíteni a régiók közötti távoli események fogyasztásával szemben, különösen azok, ahol a régiók rendkívül távol vannak egymástól, például Európa és Ausztrália közel antipodák, földrajzilag és hálózati késések könnyen meghaladhatják a 250 ms-ot minden oda-vissza utazás esetén. Nem gyorsíthatja fel a fénysebességet, de csökkentheti a nagy késésű körúti utak számát az adatok kezeléséhez.
Útmutató:
Ellenőrzés, csökkentés és bővítés
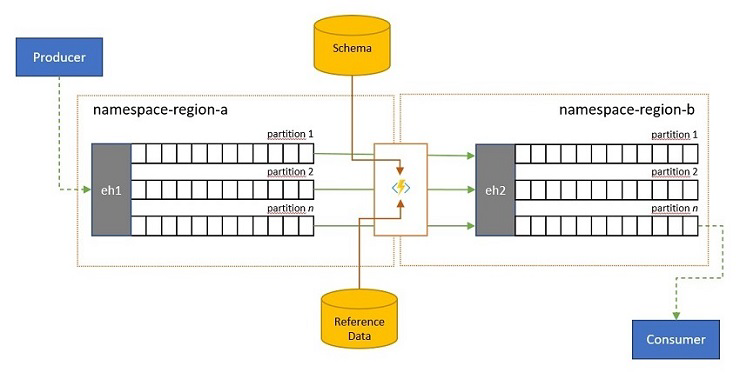
Előfordulhat, hogy az eseménystreameket a saját megoldásán kívüli ügyfelek küldik el az Event Hubsba. Az ilyen eseménystreamek megkövetelhetik, hogy a külsőleg elküldött eseményeket ellenőrizni kell egy adott sémának való megfelelőséget, és hogy a nem megfelelő eseményeket el lehessen-e dobni.
Azokban a forgatókönyvekben, ahol az ügyfelek rendkívül korlátozott sávszélességgel rendelkeznek, mivel ez számos forgalmi díjas "Dolgok internete" forgatókönyv esetében előfordul, vagy ha az eseményeket eredetileg nem IP-hálózatokon, korlátozott csomagmérettel küldik el, előfordulhat, hogy az eseményeket hivatkozási adatokkal kell kiegészíteni, hogy további kontextust adjanak ahhoz, hogy az alsóbb rétegbeli eseményfeldolgozók használhatóvá tegyenek.
Más esetekben, különösen a streamek konszolidálásakor előfordulhat, hogy az eseményadatokat összetettebbé vagy egyszerűbbé kell tenni bizonyos részletek kihagyásával.
Ezen műveletek bármelyike a replikációs, konszolidálási vagy egyesítési folyamatok részeként történhet.
Útmutató:
Integráció az elemzési szolgáltatásokkal
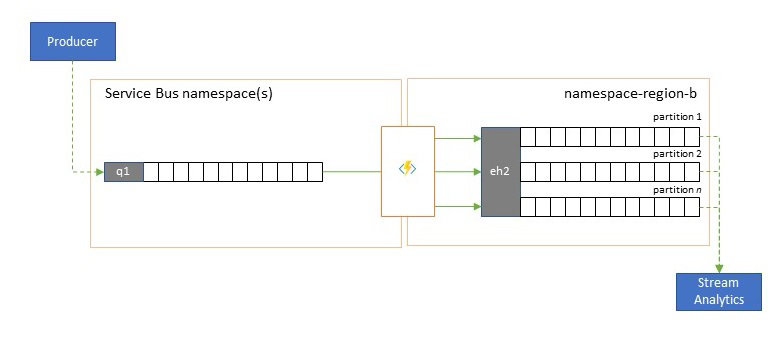
Az Azure több natív felhőbeli elemzési szolgáltatása, például az Azure Stream Analytics vagy az Azure Synapse az Azure Event Hubsból szolgáltatott streamelt vagy előre kötegelt adatokkal működik a legjobban, és az Azure Event Hubs számos nyílt forráskódú elemzési csomaggal is lehetővé teszi az integrációt, például az Apache Samza, az Apache Flink, az Apache Spark és az Apache Storm használatával.
Ha a megoldás elsősorban a Service Bust vagy az Event Gridet használja, ezeket az eseményeket könnyen elérhetővé teheti az ilyen elemzési rendszerek számára, valamint archiválhatja őket az Event Hubs Capture szolgáltatással, ha azokat az Event Hubsba tölcsérrel alakítja. Az Event Grid ezt natív módon is megteheti az Event Hubs-integrációval, a Service Bus esetében a Service Bus replikációs útmutatóját követve.
Az Azure Stream Analytics közvetlenül integrálható az Event Hubs szolgáltatással.
Útmutató:
Eseménystreamek konszolidálása és normalizálása
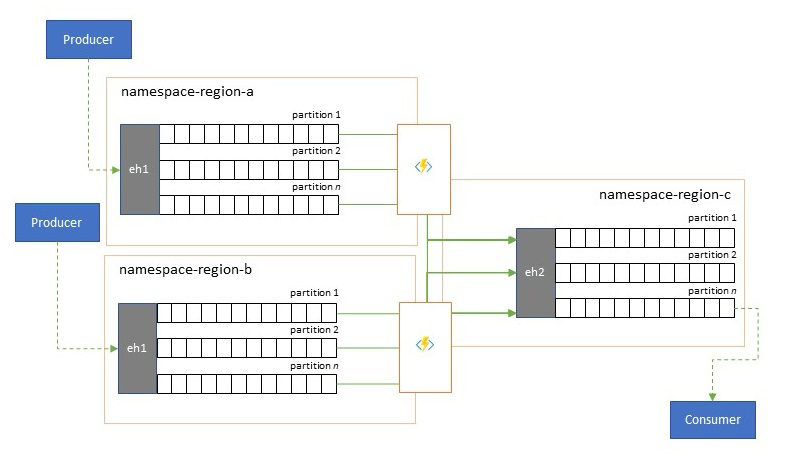
A globális megoldások gyakran olyan regionális lábnyomokból állnak, amelyek nagyrészt függetlenek, beleértve a saját elemzési képességeiket is, de a regionális és globális elemzési perspektívák integrált perspektívát igényelnek, és ezért kell központilag konszolidálni ugyanazokat az eseményfolyamokat, amelyeket a helyi perspektívához tartozó regionális lábnyomokban értékelnek.
A normalizálás az összevonási forgatókönyv egyik íze, amely szerint két vagy több bejövő eseményfolyam ugyanazt az eseménytípust hordozzák, de különböző struktúrákkal vagy különböző kódolásokkal, és a legtöbb esemény átkódolható vagy átalakítható, mielőtt felhasználhatók lennének.
A normalizálás magában foglalhatja a titkosítási munkákat is, például a végpontok közötti titkosított hasznos adatok visszafejtését, valamint a különböző kulcsokkal és algoritmusokkal történő újratitkosítását az alsóbb rétegbeli fogyasztói közönség számára.
Útmutató:
Eseménystreamek felosztása és útválasztása
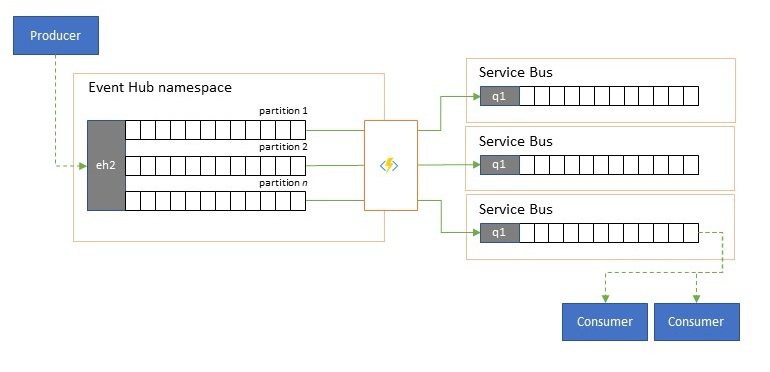
Az Azure Event Hubsot időnként "publish-subscribe" stílusú forgatókönyvekben használják, ahol a betöltött események bejövő torrentje messze meghaladja az Azure Service Bus vagy az Azure Event Grid kapacitását, amelyek mindegyike natív közzétételi-feliratkozási szűrési és terjesztési képességekkel rendelkezik, és előnyben részesítik ezt a mintát.
Míg a valódi "közzététel-feliratkozás" képesség az előfizetőkre bízza a kívánt események kiválasztását, a felosztási minta a produceri leképezési eseményeket egy előre meghatározott terjesztési modell szerint particionálta, a kijelölt felhasználók pedig kizárólag a "saját" partíciójukból kérnek le. Ha az Event Hubs puffereli a teljes forgalmat, egy adott partíció tartalma, amely az eredeti átviteli sebesség egy töredékét képviseli, ezután replikálható egy üzenetsorba a megbízható, tranzakciós, versengő fogyasztói felhasználás érdekében.
Számos esetben, amikor az Event Hubsot elsősorban egy adott régión belüli alkalmazáson belüli események áthelyezésére használják, vannak olyan esetek, amikor a kiválasztott eseményeket , esetleg csak egyetlen partícióból, máshol is elérhetővé kell tenni. Ez a forgatókönyv hasonló a felosztási forgatókönyvhöz, de használhat egy méretezhető útválasztót, amely figyelembe veszi az eseményközpontokban érkező összes üzenetet, és csak néhányat választ a befelé irányuló útválasztáshoz, és megkülönböztetheti az útválasztási célokat az esemény metaadatai vagy tartalma alapján.
Útmutató:
Naplóvetítések
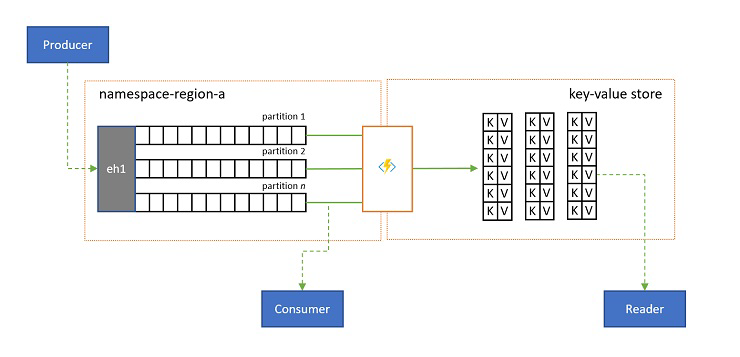
Bizonyos esetekben az esemény bármely alstreamje számára küldött legújabb értékhez szeretne hozzáférni, és általában a partíciókulcs különbözteti meg. Az Apache Kafkában ez gyakran úgy érhető el, hogy engedélyezi a "naplótömörítést" egy témakörben, amely elveti az összeset, de a legújabb eseményt bármilyen egyedi kulccsal címkézve. A naplótömörítési megközelítésnek három összetett hátránya van:
- A tömörítéshez a napló folyamatos átszervezése szükséges, ami rendkívül költséges művelet egy olyan közvetítő számára, amely csak hozzáfűző számítási feladatokhoz van optimalizálva.
- A tömörítés romboló, és nem teszi lehetővé ugyanannak a streamnek a tömörített és nem tömörített perspektíváját.
- A tömörített streamek továbbra is szekvenciális hozzáférési modellel rendelkeznek, ami azt jelenti, hogy a naplóban a kívánt érték megkereséséhez a teljes naplót a legrosszabb esetben kell elolvasni, ami általában az itt bemutatott pontos mintát megvalósító optimalizáláshoz vezet: a napló tartalmának adatbázisba vagy gyorsítótárba való kivetítéséhez.
Végső soron a tömörített naplók kulcs-érték tárolók, és mint ilyen, ez a lehető legrosszabb megvalósítási lehetőség egy ilyen áruház esetében. Sokkal hatékonyabb a keresések és a lekérdezések számára, hogy a napló állandó vetületét létrehozzák és használják egy megfelelő kulcs-érték tárolóra vagy más adatbázisra.
Mivel az események nem módosíthatók, és a sorrend mindig megmarad egy naplóban, a naplók kulcs-érték tárolóba való kivetítése mindig azonos lesz ugyanahhoz az eseménytartományhoz, ami azt jelenti, hogy a folyamatosan frissített előrejelzés mindig mérvadó nézetet biztosít, és soha nincs semmi jó ok arra, hogy újraépítse azt a napló tartalmából a létrehozás után.
Útmutató:
Replikációs alkalmazástechnológiák
A fenti minták implementálásához méretezhető és megbízható végrehajtási környezet szükséges a konfigurálni és futtatni kívánt replikációs feladatokhoz. Az Azure-ban az ilyen feladatokhoz leginkább megfelelő futtatókörnyezetek az állapot nélküli feladatok az Azure Stream Analytics az állapotalapú streamreplikációs feladatokhoz, az Azure Functions pedig az állapot nélküli replikációs feladatokhoz.
Állapotalapú replikációs alkalmazások az Azure Stream Analyticsben
Az olyan állapotalapú replikációs alkalmazások esetében, amelyeknek figyelembe kell venniük az események közötti kapcsolatokat, összetett eseményeket kell létrehozniuk, eseményeket kell gazdagítaniuk vagy eseményeket csökkenteniük, adatösszesítéseket kell létrehozniuk, és át kell alakítaniuk az események hasznos adatait, az Azure Stream Analytics a legjobb megvalósítási lehetőség.
Az Azure Stream Analyticsben olyan feladatokat hozhat létre, amelyek bemeneteket és kimeneteket integrálnak, és a bemenetekből származó adatokat olyan lekérdezésekkel integrálják, amelyek eredményeként a kimenetek elérhetővé válnak.
A lekérdezések az SQL lekérdezési nyelvén alapulnak, és a streamelési adatok egyszerű szűrésére, rendezésére, összesítésére és összekapcsolására használhatók egy adott időszakban. Ezt az SQL-nyelvet a JavaScript és a C# felhasználó által definiált függvényekkel (UDF-ekkel) is bővítheti. Egyszerű nyelvi szerkezetekkel és/vagy konfigurációkkal egyszerűen módosíthatja az eseményrendezési beállításokat és az időablakok időtartamát az összesítési műveletek végrehajtásakor.
Minden feladat egy vagy több kimenettel rendelkezik az átalakított adatokhoz, és szabályozhatja, hogy mi történjen az elemzett információkra válaszul. Lehetőség van például a következőkre:
- Adatokat küldhet olyan szolgáltatásoknak, mint az Azure Functions, a Service Bus-témakörök vagy az üzenetsorok, hogy kommunikációt vagy egyéni munkafolyamatokat aktiváljon az alsóbb rétegben.
- Adatok küldése Power BI-irányítópultra valós idejű irányítópultok létrehozásához.
- Adatok tárolása más Azure Storage-szolgáltatásokban (például Azure Data Lake, Azure Synapse Analytics stb.) kötegelt elemzések elvégzéséhez vagy gépi tanulási modellek betanítása nagyon nagy, indexelt előzményadatok készletei alapján.
- A vetületeket (más néven "materializált nézeteket") adatbázisokban (SQL Database, Azure Cosmos DB) tárolhatja.
Állapot nélküli replikációs alkalmazások az Azure Functionsben
Az olyan állapot nélküli replikációs feladatok esetében, amelyeknél az eseményeket anélkül szeretné továbbítani, hogy figyelembe venné a hasznos adatokat, vagy anélkül dolgozza fel őket, hogy figyelembe kellene vennie az események kapcsolatait (kivéve a relatív sorrendjüket), használhatja az Azure Functionst, amely hatalmas rugalmasságot biztosít.
Az Azure Functions előre összeállított, méretezhető triggerekkel és kimeneti kötésekkel rendelkezik az Azure Event Hubshoz, az Azure IoT Hubhoz, az Azure Service Bushoz, az Azure Event Gridhez és az Azure Queue Storage-hoz, valamint a RabbitMQ és az Apache Kafka egyéni bővítményeivel. A legtöbb eseményindító dinamikusan alkalmazkodik az átviteli sebesség igényeihez az egyidejűleg végrehajtó példányok számának a dokumentált metrikák alapján történő fel- és leskálázásával.
Naplóvetítések készítéséhez az Azure Functions támogatja az Azure Cosmos DB és az Azure Table Storage kimeneti kötéseit.
Az Azure Functions azure-beli felügyelt identitással futtatható, és ezzel a hitelesítő adatok konfigurációs értékeit az Azure Key Vault szigorúan hozzáférés-vezérlésű tárolójában tárolhatja.
Az Azure Functions továbbá lehetővé teszi, hogy a replikációs feladatok közvetlenül integrálhatók az Azure-beli virtuális hálózatokkal és szolgáltatásvégpontokkal az összes Azure-üzenetkezelési szolgáltatás esetében, és könnyen integrálható az Azure Monitorral.
Az Azure Functions használati csomagjával az előre összeállított eseményindítók akár nullára is leskálázhatók, miközben nem érhetők el üzenetek a replikációhoz, ami azt jelenti, hogy a konfiguráció készen áll a biztonsági mentésre; a használati terv használatának fő hátránya az, hogy a replikációs feladatok "ébredés" késése ebből az állapotból jelentősen magasabb, mint azoknál az üzemeltetési terveknél, amelyekben az infrastruktúra fut.
Mindezekkel ellentétben az üzenetkezelés és az eseménykezelés leggyakoribb replikációs motorjai, például az Apache Kafka MirrorMaker megkövetelik, hogy üzemeltetési környezetet biztosítson, és saját maga skálázza a replikációs motort. Ez magában foglalja a biztonsági és hálózati funkciók konfigurálását és integrálását, valamint a monitorozási adatok áramlásának megkönnyítését, és akkor sem lesz lehetősége egyéni replikációs feladatokat injektálni a folyamatba.
Választás az Azure Functions és az Azure Stream Analytics között
Az Azure Stream Analytics (ASA) a legjobb megoldás, ha az események hasznos adatait kell feldolgoznia a replikálásuk során. Az ASA egyesével másolhatja az eseményeket, vagy olyan összesítéseket hozhat létre, amelyek a továbbítás előtt összesítik az eseménystreamek információit. Könnyen támaszkodhat az Azure Blob Storage-ban vagy az Azure SQL Database-ben tárolt referenciaadatok kiegészítésére anélkül, hogy ezeket az adatokat streambe kellene importálnia.
Az ASA segítségével egyszerűen hozhat létre állandó, materializált nézeteket a hiperméretű adatbázisokban lévő streamekről. Ez egy sokkal jobb megközelítés az Apache Kafka klónos "log compaction" modelljéhez és a Kafka adatfolyamok illékony, ügyféloldali táblavetületeihez.
Az ASA könnyen feldolgozhatja a CSV, JSON és Apache Avro formátumú hasznos adatokkal rendelkező eseményeket, és bármilyen más formátumhoz csatlakoztathatja az egyéni deszerializálókat .
Az összes olyan replikációs feladat esetében, ahol az eseménystreameket "aktuális állapotban" szeretné másolni, a hasznos adatok érintése nélkül, vagy ha útválasztót kell implementálnia, kriptográfiai munkát kell végeznie, módosítania kell a hasznos adatok kódolását, vagy ha egyébként teljes mértékben szabályoznia kell az adatfolyam tartalmát, az Azure Functions a legjobb megoldás.
Következő lépések
Ebben a cikkben több összevonási mintát ismertettünk, és ismertettük az Azure Functions esemény- és üzenetreplikációs futtatókörnyezetként betöltött szerepét az Azure-ban.
A következőkben érdemes elolvasnia, hogyan állíthat be replikátoralkalmazásokat az Azure Stream Analytics vagy az Azure Functions használatával, majd hogyan replikálhatja az eseményfolyamatokat az Event Hubs és más eseménykezelő és üzenetkezelő rendszerek között:
- Eseményreplikációs feladatminták
- Adatok feldolgozása az Azure Stream Analytics használatával
- Eseményreplikátor-alkalmazások az Azure Functionsben
- Események replikálása az Event Hubs között
- Események replikálása az Azure Service Busba
- Az Apache Kafka MirrorMaker használata az Event Hubs használatával
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: