Feladatok beküldése és kezelése Apache Spark-fürtön™ a HDInsightban az AKS-en
Feljegyzés
2025. január 31-én kivonjuk az Azure HDInsightot az AKS-ből. 2025. január 31-ig át kell telepítenie a számítási feladatokat a Microsoft Fabricbe vagy egy azzal egyenértékű Azure-termékbe, hogy elkerülje a számítási feladatok hirtelen leállítását. Az előfizetés többi fürtje le lesz állítva, és el lesz távolítva a gazdagépről.
Fontos
Ez a szolgáltatás jelenleg előzetes kiadásban elérhető. A Microsoft Azure Előzetes verzió kiegészítő használati feltételei további jogi feltételeket tartalmaznak, amelyek a bétaverzióban, előzetes verzióban vagy egyébként még nem általánosan elérhető Azure-funkciókra vonatkoznak. Erről az adott előzetes verzióról az Azure HDInsight az AKS előzetes verziójában tájékozódhat. Ha kérdése vagy funkciójavaslata van, küldjön egy kérést az AskHDInsightban a részletekkel együtt, és kövessen minket további frissítésekért az Azure HDInsight-közösségről.
A fürt létrehozása után a felhasználó különböző felületeken küldheti el és kezelheti a feladatokat a következővel:
- a Jupyter használata
- a Zeppelin használata
- ssh használata (spark-submit)
A Jupyter használata
Előfeltételek
Apache Spark-fürt™ a HDInsighton az AKS-en. További információ: Apache Spark-fürt létrehozása.
A Jupyter Notebook egy interaktív notebook-környezet, amely számos programozási nyelvet támogat.
Jupyter-notebook létrehozása
Lépjen az Apache Spark-fürt™ lapjára, és nyissa meg az Áttekintés lapot. Kattintson a Jupyterre, és megkéri, hogy hitelesítse és nyissa meg a Jupyter weblapot.

A Jupyter weblapján válassza az Új > PySpark lehetőséget jegyzetfüzet létrehozásához.
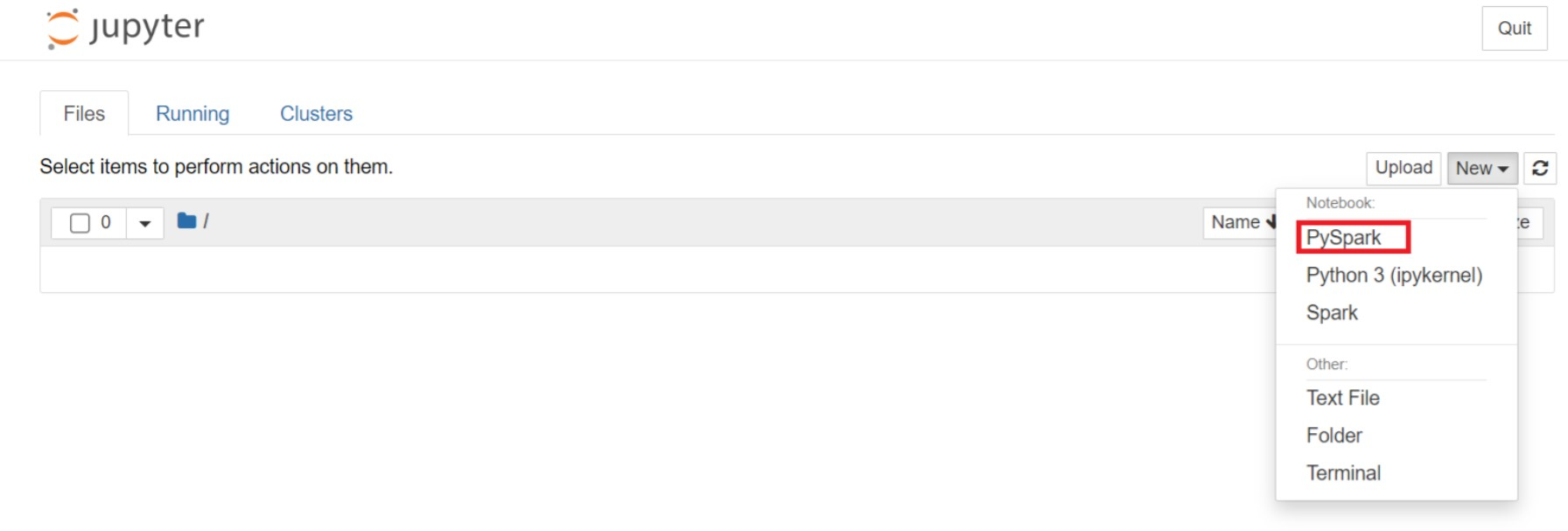
Új jegyzetfüzetet hozott létre és nyitott meg a névvel
Untitled(Untitled.ipynb).Feljegyzés
Ha a PySpark vagy a Python 3 kernel használatával hoz létre egy jegyzetfüzetet, a spark-munkamenet automatikusan létrejön Az első kódcella futtatásakor. A munkamenetet nem szükséges manuálisan létrehoznia.
Illessze be a következő kódot a Jupyter Notebook üres cellájába, majd nyomja le a SHIFT + ENTER billentyűkombinációt a kód futtatásához. A Jupyter további vezérlőiről itt olvashat.
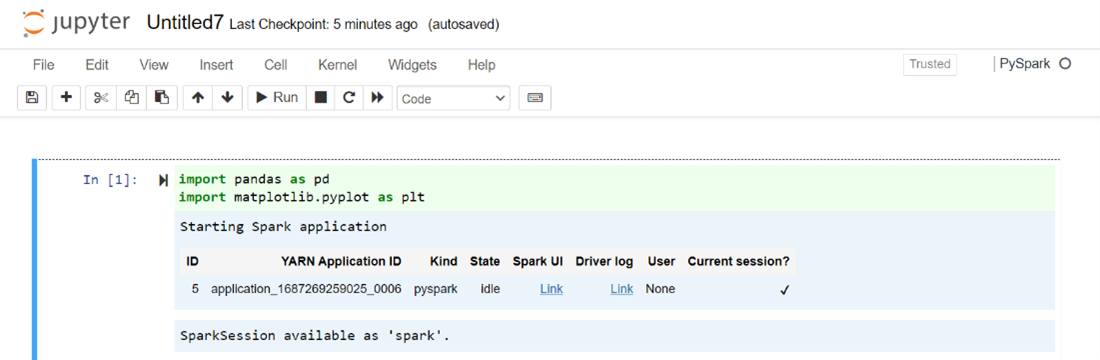
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Diagram ábrázolása fizetéssel és korral X és Y tengelyként
Ugyanabban a jegyzetfüzetben illessze be a következő kódot a Jupyter Notebook egy üres cellájába, majd nyomja le a SHIFT + ENTER billentyűkombinációt a kód futtatásához.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()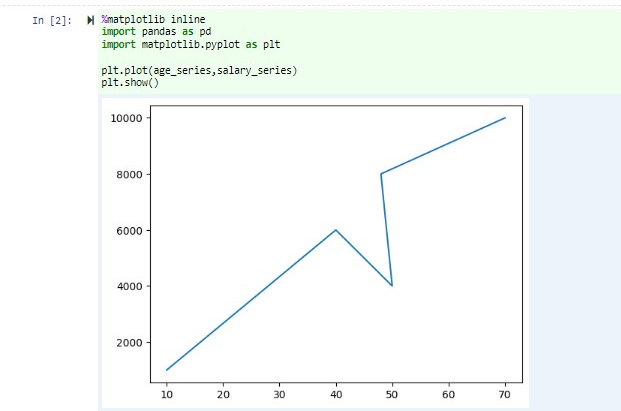




A jegyzetfüzet mentése
A jegyzetfüzet menüsávjában keresse meg a Fájl > mentése és az Ellenőrzőpont lehetőséget.
Állítsa le a jegyzetfüzetet a fürterőforrások felszabadításához: a jegyzetfüzet menüsávjáról lépjen a Fájlbezárás > és a Leállítás elemre. Bármelyik jegyzetfüzetet futtathatja a Példák mappában.


Apache Zeppelin-jegyzetfüzetek használata
Az AKS HDInsightban futó Apache Spark-fürtöi közé tartoznak az Apache Zeppelin-jegyzetfüzetek. Apache Spark-feladatok futtatásához használja a jegyzetfüzeteket. Ebből a cikkből megtudhatja, hogyan használhatja a Zeppelin-jegyzetfüzetet egy HDInsighton az AKS-fürtön.
Előfeltételek
Apache Spark-fürt a HDInsighton az AKS-en. Útmutatásért lásd : Apache Spark-fürt létrehozása.
Apache Zeppelin-jegyzetfüzet indítása
Lépjen az Apache Spark-fürt áttekintési oldalára, és válassza a Zeppelin-jegyzetfüzetet a Fürt irányítópultjai közül. Kéri a Zeppelin-oldal hitelesítését és megnyitását.
Hozzon létre új notebookot. Az élőfej panelen lépjen az Új jegyzet létrehozása jegyzetfüzetbe > . Győződjön meg arról, hogy a jegyzetfüzet fejléce csatlakoztatott állapotot jelenít meg. A jobb felső sarokban egy zöld pont látható.

Futtassa a következő kódot a Zeppelin Notebookban:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])A kódrészlet futtatásához válassza a bekezdés Lejátszás gombját. A bekezdés jobb sarkában lévő állapotnak a KÉSZ, a FÜGGŐBEN, a FUTTATÁStól a KÉSZ állapotig kell haladnia. A kimenet ugyanazon bekezdés alján jelenik meg. A képernyőkép a következő képhez hasonlóan néz ki:

Hozam:





Spark-küldési feladatok használata
Fájl létrehozása a következő "#vim samplefile.py" paranccsal
Ez a parancs megnyitja a vim-fájlt
Illessze be a következő kódot a virtuális gép fájljába
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Mentse a fájlt az alábbi módszerrel.
- Nyomja le az Escape gombot
- Adja meg a parancsot
:wq
Futtassa a következő parancsot a feladat futtatásához.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Lekérdezések monitorozása Apache Spark-fürtön a HDInsightban az AKS-en
Spark-előzmények felhasználói felülete
Kattintson a Spark History Server felhasználói felületére az Áttekintés lapon.

Válassza ki a legutóbbi futtatásokat a felhasználói felületen ugyanazzal az alkalmazásazonosítóval.
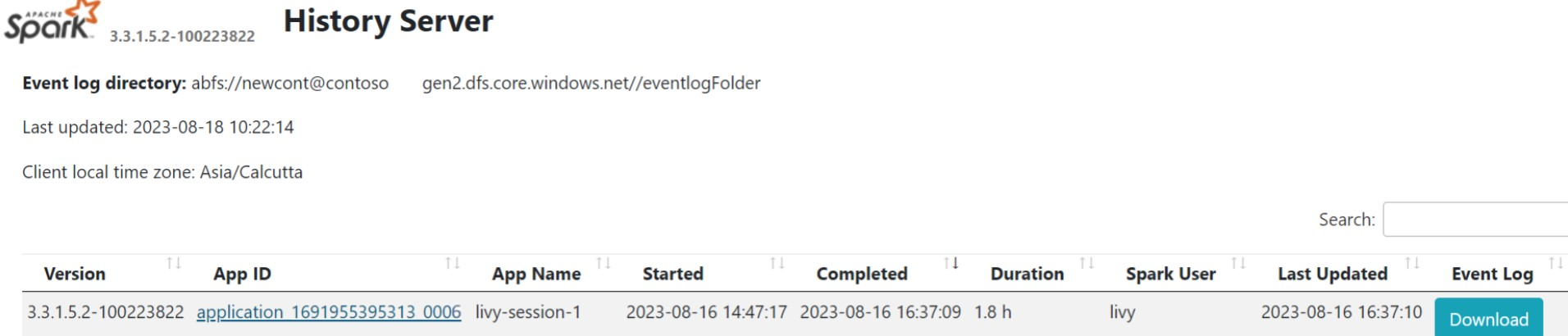
Tekintse meg az Irányított Aciklikus gráf ciklusokat és a feladat szakaszait a Spark-előzmények kiszolgáló felhasználói felületén.




Livy-munkamenet felhasználói felülete
A Livy-munkamenet felhasználói felületének megnyitásához írja be a következő parancsot a böngészőbe
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui
Az illesztőprogram-naplók megtekintéséhez kattintson a naplók alatti illesztőprogram-beállításra.

Yarn felhasználói felület
Az Áttekintés lapon kattintson a Yarn elemre, és nyissa meg a Yarn felhasználói felületét.

Nyomon követheti azt a feladatot, amelyet a közelmúltban ugyanazzal az alkalmazásazonosítóval futtatott.
Kattintson a Yarn alkalmazásazonosítójára a feladat részletes naplóinak megtekintéséhez.



Referencia
- Az Apache, az Apache Spark, a Spark és a társított nyílt forráskód projektnevek az Apache Software Foundation (ASF) védjegyei.