A C# használata a MapReduce streameléssel az Apache Hadoopon a HDInsightban
Megtudhatja, hogyan hozhat létre MapReduce-megoldást a HDInsighton a C# használatával.
Az Apache Hadoop streamelése lehetővé teszi a MapReduce-feladatok futtatását szkript vagy végrehajtható fájl használatával. Itt a .NET használatával implementáljuk a leképezőt és a redukátort egy szószám-megoldáshoz.
.NET a HDInsighton
A HDInsight-fürtök a Mono (https://mono-project.com).NET-alkalmazások futtatásához) használatával működnek. A 4.2.1-es monoverzió a HDInsight 3.6-os verziója. A HDInsighthoz mellékelt Mono verziójáról további információt a HDInsight-verziókban elérhető Apache Hadoop-összetevőkben talál.
Az .NET-keretrendszer-verziókkal való monokompatibilitásról további információt a Mono kompatibilitás című témakörben talál.
A Hadoop streamelésének működése
A dokumentumban a streameléshez használt alapfolyamat a következő:
- A Hadoop adatokat ad át a leképezőnek (ebben a példában mapper.exe ) az STDIN-en.
- A leképező feldolgozza az adatokat, és tabulátorral tagolt kulcs/érték párokat bocsát ki az STDOUT-nak.
- A kimenetet a Hadoop olvassa be, majd átadja a redukátornak (ebben a példában reducer.exe ) az STDIN-en.
- A redukátor beolvassa a tabulátorral tagolt kulcs/érték párokat, feldolgozza az adatokat, majd tabulátorral tagolt kulcs/érték párokként bocsátja ki az eredményt az STDOUT-on.
- A kimenetet a Hadoop felolvassa, és a kimeneti könyvtárba írja.
További információ a streamelésről: Hadoop Streaming.
Előfeltételek
A Visual Studióval.
A 4.5-ös .NET-keretrendszer megcélozó C#-kód írásának és készítésének ismerete.
A .exe fájlok fürtbe való feltöltésének módja. A dokumentum lépései a Data Lake Tools for Visual Studio használatával töltik fel a fájlokat a fürt elsődleges tárolójára.
A PowerShell használata esetén szüksége lesz az Az modulra.
Apache Hadoop-fürt a HDInsighton. Tekintse meg a HDInsight linuxos használatának első lépéseit.
A fürtök elsődleges tárolójának URI-sémája. Ez a séma az Azure Storage,
abfs://az Azure Data Lake Storage Gen2 vagyadl://az Azure Data Lake Storage Gen1 esetében lennewasb://. Ha az Azure Storage vagy a Data Lake Storage Gen2 esetében engedélyezve van a biztonságos átvitel, az URI vagyabfss://az URI leszwasbs://.
A leképező létrehozása
A Visual Studióban hozzon létre egy új .NET-keretrendszer mapper nevű konzolalkalmazást. Használja a következő kódot az alkalmazáshoz:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Az alkalmazás létrehozása után hozza létre a /bin/Debug/mapper.exe fájlt a projektkönyvtárban.
A redukátor létrehozása
A Visual Studióban hozzon létre egy új .NET-keretrendszer-konzolalkalmazást, melynek neve reducer. Használja a következő kódot az alkalmazáshoz:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Az alkalmazás létrehozása után hozza létre a /bin/Debug/reducer.exe fájlt a projektkönyvtárban.
Feltöltés tárolóba
Ezután fel kell töltenie a mapper és a redukátoralkalmazásokat a HDInsight-tárolóba.
A Visual Studióban válassza a Kiszolgálókezelő megtekintése lehetőséget>.
Kattintson a jobb gombbal az Azure-ra, válassza Csatlakozás a Microsoft Azure-előfizetéshez... és fejezze be a bejelentkezési folyamatot.
Bontsa ki az alkalmazást üzembe helyezni kívánt HDInsight-fürtöt. Megjelenik egy szöveggel (alapértelmezett tárfiók) rendelkező bejegyzés.
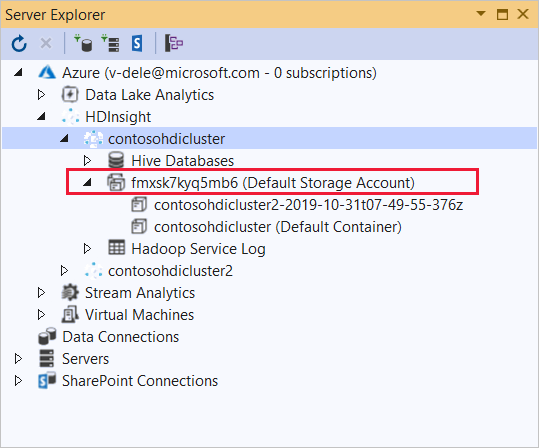
Ha az (alapértelmezett tárfiók) bejegyzés kibontható, akkor egy Azure Storage-fiókot használ a fürt alapértelmezett tárolójaként. A fürt alapértelmezett tárolójának fájljainak megtekintéséhez bontsa ki a bejegyzést, majd kattintson duplán a (Alapértelmezett tároló) elemre.
Ha az (alapértelmezett tárfiók) bejegyzés nem bontható ki, akkor az Azure Data Lake Storage-t használja a fürt alapértelmezett tárolójaként. A fürt alapértelmezett tárolóján lévő fájlok megtekintéséhez kattintson duplán az (Alapértelmezett tárfiók) bejegyzésre.
A .exe fájlok feltöltéséhez használja az alábbi módszerek egyikét:
Ha Azure Storage-fiókot használ, válassza a Blob feltöltése ikont.

Az Új fájl feltöltése párbeszédpanel Fájlnév csoportjában válassza a Tallózás lehetőséget. A Blob feltöltése párbeszédpanelen lépjen a mapper projekt bin\debug mappájába, majd válassza ki a mapper.exe fájlt. Végül válassza a Megnyitás , majd az OK gombot a feltöltés befejezéséhez.
Az Azure Data Lake Storage esetében kattintson a jobb gombbal egy üres területre a fájllistában, majd válassza a Feltöltés lehetőséget. Végül válassza ki a mapper.exe fájlt, majd válassza a Megnyitás lehetőséget.
Ha a mapper.exe feltöltés befejeződött, ismételje meg a reducer.exe fájl feltöltési folyamatát.
Feladat futtatása: SSH-munkamenet használata
Az alábbi eljárás azt ismerteti, hogyan futtathat MapReduce-feladatokat egy SSH-munkamenet használatával:
Az ssh paranccsal csatlakozzon a fürthöz. Szerkessze az alábbi parancsot úgy, hogy lecseréli a CLUSTERNAME nevet a fürt nevére, majd írja be a parancsot:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netA MapReduce-feladat elindításához használja az alábbi parancsok egyikét:
Ha az alapértelmezett tároló az Azure Storage:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutHa az alapértelmezett tároló a Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutHa az alapértelmezett tároló a Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
Az alábbi lista az egyes paraméterek és beállítások jelentését ismerteti:
Paraméter Leírás hadoop-streaming.jar Megadja a streamelési MapReduce funkciót tartalmazó jar-fájlt. -Fájlokat Megadja a feladathoz tartozó mapper.exe és reducer.exe fájlokat. Az wasbs:///egyes fájlok előtti ,adl:///vagyabfs:///protokolldeklaráció a fürt alapértelmezett tárolójának elérési útja.-Mapper Megadja a leképezőt megvalósító fájlt. -Szűkítő Megadja a redukátort megvalósító fájlt. -Bemenet Megadja a bemeneti adatokat. -Kimeneti Megadja a kimeneti könyvtárat. A MapReduce-feladat befejeződése után az alábbi paranccsal tekintheti meg az eredményeket:
hdfs dfs -text /example/wordcountout/part-00000Az alábbi szöveg egy példa a parancs által visszaadott adatokra:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Feladat futtatása: A PowerShell használata
A mapReduce-feladat futtatásához és az eredmények letöltéséhez használja a következő PowerShell-szkriptet.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Ez a szkript kéri a fürt bejelentkezési fiókjának nevét és jelszavát, valamint a HDInsight-fürt nevét. A feladat befejezése után a kimenet egy output.txt nevű fájlba lesz letöltve. Az alábbi szöveg egy példa a output.txt fájlban lévő adatokra:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17
Következő lépések
- Használja a MapReduce-ot a HDInsighton futó Apache Hadoopban.
- Használjon C# felhasználó által definiált függvényt az Apache Hive és az Apache Pig használatával.
- Java MapReduce programok fejlesztése
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: