Nagy léptékű kinyerés, átalakítás és betöltés (ETL)
A kinyerés, átalakítás és betöltés (ETL) az a folyamat, amellyel különböző forrásokból szereznek be adatokat. Az adatok gyűjtése szabványos helyen történik, megtisztítva és feldolgozva. Végül az adatok betöltve lesznek egy olyan adattárba, amelyből lekérdezhető. Az örökölt ETL feldolgozza az importálási adatokat, megtisztítja a helyén, majd egy relációs adatmotorban tárolja. Az Azure HDInsight segítségével az Apache Hadoop környezeti összetevők széles köre támogatja az ETL-t nagy méretekben.
A HDInsight ETL-folyamatban való használatát ez a folyamat foglalja össze:
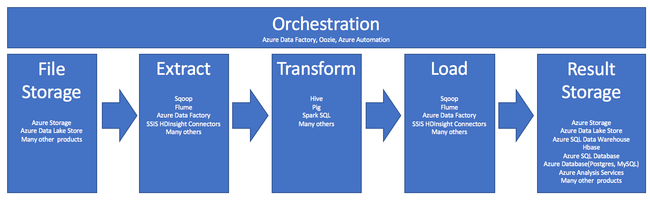
Az alábbi szakaszok az ETL-fázisokat és azok kapcsolódó összetevőit ismertetik.
Vezénylés
A vezénylés az ETL-folyamat minden fázisára kiterjed. A HDInsight ETL-feladatai gyakran több különböző terméket is magukban foglalnak, amelyek egymással együttműködve működnek. Példa:
- Az Apache Hive használatával megtisztíthatja az adatok egy részét, az Apache Pig pedig egy másik részt.
- Az Azure Data Factory használatával adatokat tölthet be az Azure SQL Database-be az Azure Data Lake Store-ból.
A megfelelő feladat megfelelő időben történő futtatásához vezénylésre van szükség.
Apache Oozie
Az Apache Oozie egy munkafolyamat-koordinációs rendszer, amely a Hadoop-feladatokat kezeli. Az Oozie egy HDInsight-fürtben fut, és a Hadoop-verembe van integrálva. Az Oozie támogatja az Apache Hadoop MapReduce, Pig, Hive és Sqoop Hadoop-feladatokat. Az Oozie használatával ütemezheti a rendszerre jellemző feladatokat, például Java-programokat vagy rendszerhéjszkripteket.
További információ: Az Apache Oozie és az Apache Hadoop használata munkafolyamat definiálásához és futtatásához a HDInsighton. Lásd még: Az adatfolyam üzembe helyezése.
Azure Data Factory
Az Azure Data Factory szolgáltatásként nyújtott platform (PaaS) formájában nyújt vezénylési képességeket. Az Azure Data Factory egy felhőalapú integrációs szolgáltatás. Lehetővé teszi adatvezérelt munkafolyamatok létrehozását az adatáthelyezés és adatátalakítás vezényléséhez és automatizálásához.
Az Azure Data Factory használata:
- Adatvezérelt munkafolyamatok létrehozása és ütemezése. Ezek a folyamatok különböző adattárakból betöltik az adatokat.
- Feldolgozhatja és átalakíthatja az adatokat olyan számítási szolgáltatások használatával, mint a HDInsight vagy a Hadoop. Ehhez a lépéshez a Spark, az Azure Data Lake Analytics, az Azure Batch vagy az Azure Machine Tanulás is használható.
- Közzéteheti a kimeneti adatokat az adattárakban, például az Azure Synapse Analyticsben, a felhasznált BI-alkalmazások számára.
Az Azure Data Factoryről további információt a dokumentációban talál.
Fájltároló és eredménytároló betöltése
A forrásadatfájlok általában az Azure Storage vagy az Azure Data Lake Storage egy helyére töltődnek be. A fájlok általában egyformák, például CSV formátumban vannak. De bármilyen formátumban lehetnek.
Azure Storage
Az Azure Storage speciális alkalmazkodóképességi célokkal rendelkezik. További információkért tekintse meg a Blob Storage méretezhetőségi és teljesítménycéljait. A legtöbb elemzési csomópont esetében az Azure Storage skálázható a legjobban, ha sok kisebb fájlt kezel. Mindaddig, amíg a fiók korlátain belül van, az Azure Storage ugyanazt a teljesítményt garantálja, függetlenül attól, hogy a fájlok mekkora méretűek. Több terabájtnyi adatot tárolhat, és továbbra is konzisztens teljesítményt érhet el. Ez az állítás igaz, akár egy részhalmazt, akár az összes adatot használja.
Az Azure Storage többféle blobtípussal rendelkezik. A hozzáfűző blobok nagyszerű lehetőséget biztosítanak webes naplók vagy érzékelőadatok tárolására.
Több blob is elosztható több kiszolgálón a hozzájuk való hozzáférés skálázásához. Egyetlen blobot azonban csak egyetlen kiszolgáló szolgál ki. Bár a blobok logikailag blobtárolókba csoportosíthatók, ennek a csoportosításnak nincsenek particionálási következményei.
Az Azure Storage webHDFS API-réteggel rendelkezik a blobtárolóhoz. Minden HDInsight-szolgáltatás hozzáférhet az Azure Blob Storage fájljaihoz az adattisztításhoz és az adatfeldolgozáshoz. Ez hasonló ahhoz, ahogyan ezek a szolgáltatások a Hadoop Elosztott fájlrendszert (HDFS) használnák.
Az adatok általában a PowerShell, az Azure Storage SDK vagy az AzCopy használatával kerülnek az Azure Storage-ba.
Azure Data Lake Storage
Az Azure Data Lake Storage egy felügyelt, rugalmas skálázású adattár az elemzési adatokhoz. Kompatibilis és a HDFS-hez hasonló tervezési paradigmát használ. A Data Lake Storage korlátlan alkalmazkodóképességet biztosít a teljes kapacitáshoz és az egyes fájlok méretéhez. Nagy méretű fájlok használatakor jó választás, mert több csomóponton is tárolhatók. A Data Lake Storage-ban az adatok particionálása a színfalak mögött történik. Kiemelkedő átviteli sebességet biztosít a több ezer párhuzamos végrehajtóval rendelkező elemzési feladatok futtatásához, amelyekben a több száz terabájt adat olvasása és írása hatékonyan történik.
Az adatok általában az Azure Data Factoryn keresztül kerülnek a Data Lake Storage-ba. Használhatja a Data Lake Storage SDK-t, az AdlCopy szolgáltatást, az Apache DistCp-t vagy az Apache Sqoopot is. A választott szolgáltatás attól függ, hogy hol találhatók az adatok. Ha egy meglévő Hadoop-fürtben található, használhatja az Apache DistCp-et, az AdlCopy szolgáltatást vagy az Azure Data Factoryt. Az Azure Blob Storage-ban tárolt adatokhoz használhatja az Azure Data Lake Storage .NET SDK-t, az Azure PowerShellt vagy az Azure Data Factoryt.
A Data Lake Storage az Azure Event Hubson keresztüli eseménybetöltésre van optimalizálva.
Mindkét tárolási lehetőség szempontjai
A terabájttartományban lévő adathalmazok feltöltése esetén a hálózati késés jelentős problémát jelenthet. Ez különösen igaz, ha az adatok helyszíni helyről származnak. Ilyen esetekben az alábbi lehetőségeket használhatja:
Azure ExpressRoute: Privát kapcsolatok létrehozása az Azure-adatközpontok és a helyszíni infrastruktúra között. Ezek a kapcsolatok megbízható lehetőséget biztosítanak nagy mennyiségű adat átviteléhez. További információkért tekintse meg az Azure ExpressRoute dokumentációját.
Adatfeltöltés merevlemez-meghajtókról: Az Azure Import/Export szolgáltatással merevlemezeket szállíthat az adataival egy Azure-adatközpontba. Az adatok először fel lesznek töltve az Azure Blob Storage-ba. Ezután az Azure Data Factory vagy az AdlCopy eszközzel adatokat másolhat az Azure Blob Storage-ból a Data Lake Storage-ba.
Azure Synapse Analytics
Az Azure Synapse Analytics megfelelő választás az előkészített eredmények tárolására. Ezeket a szolgáltatásokat az Azure HDInsight használatával hajthatja végre az Azure Synapse Analyticshez.
Az Azure Synapse Analytics egy elemzési számítási feladatokhoz optimalizált relációsadatbázis-tároló. Particionált táblák alapján skáláz. A táblák több csomóponton is particionálhatók. A csomópontok a létrehozáskor vannak kiválasztva. A tény után skálázhatók, de ez egy aktív folyamat, amely adatáthelyezést igényelhet. További információ: Számítás kezelése az Azure Synapse Analyticsben.
Apache HBase
Az Apache HBase az Azure HDInsightban elérhető kulcs-/értéktár. Ez egy nyílt forráskódú, NoSQL-adatbázis, amely a Hadoopra épül, és a Google BigTable után modellezhető. A HBase nagy mennyiségű strukturálatlan és félig strukturált adathoz biztosít nagy mennyiségű véletlenszerű hozzáférést és erős konzisztenciát.
Mivel a HBase séma nélküli adatbázis, használat előtt nem kell oszlopokat és adattípusokat definiálnia. Az adatok egy tábla soraiban lesznek tárolva, és oszlopcsaládok szerint csoportosítva lesznek.
A nyílt forráskód lineáris módon méreteződik át a több ezer csomópontnyi adat petabájtjainak kezelése érdekében. A HBase az adatredundanciára, a kötegelt feldolgozásra és az elosztott alkalmazások által a Hadoop-környezetben biztosított egyéb funkciókra támaszkodik.
A HBase jó cél az érzékelő- és naplóadatokhoz a jövőbeni elemzéshez.
A HBase alkalmazkodóképessége a HDInsight-fürt csomópontjainak számától függ.
Azure SQL-adatbázisok
Az Azure három PaaS-relációs adatbázist kínál:
- Az Azure SQL Database a Microsoft SQL Server implementációja. A teljesítményről további információt az Azure SQL Database teljesítményhangolása című témakörben talál.
- Az Azure Database for MySQL az Oracle MySQL implementációja.
- Az Azure Database for PostgreSQL a PostgreSQL implementációja.
A termékek felskálázásához adjon hozzá több processzort és memóriát. Dönthet úgy is, hogy prémium lemezeket használ a termékekkel a jobb I/O-teljesítmény érdekében.
Azure Analysis Services
Az Azure Analysis Services egy elemzési adatmotor, amelyet a döntéstámogatáshoz és az üzleti elemzéshez használnak. Elemzési adatokat biztosít üzleti jelentésekhez és ügyfélalkalmazásokhoz, például a Power BI-hoz. Az elemzési adatok az Excel, az SQL Server Reporting Services jelentéseivel és más adatvizualizációs eszközökkel is működnek.
Az elemzési kockák méretezése az egyes kockák szintjeinek módosításával. További információkért tekintse meg az Azure Analysis Services díjszabását.
Kinyerés és betöltés
Miután az adatok már léteznek az Azure-ban, számos szolgáltatás használatával kinyerheti és betöltheti őket más termékekbe. A HDInsight támogatja a Sqoopot és a Flume-ot.
Apache Sqoop
Az Apache Sqoop egy olyan eszköz, amely hatékonyan továbbít adatokat strukturált, félig strukturált és strukturálatlan adatforrások között.
A Sqoop a MapReduce használatával importálja és exportálja az adatokat, így párhuzamos működést és hibatűrést biztosít.
Apache Flume
Az Apache Flume egy elosztott, megbízható és elérhető szolgáltatás, amely nagy mennyiségű naplóadat hatékony gyűjtésére, összesítésére és áthelyezésére szolgál. Rugalmas architektúrája streamelési adatfolyamokon alapul. A Flume robusztus és hibatűrő, a megbízhatósági mechanizmusokkal együtt. Számos feladatátvételi és helyreállítási mechanizmussal rendelkezik. A Flume egy egyszerű bővíthető adatmodellt használ, amely lehetővé teszi az online, elemzési alkalmazások használatát.
Az Apache Flume nem használható az Azure HDInsighttal. A helyszíni Hadoop-telepítések azonban a Flume használatával adatokat küldhetnek az Azure Blob Storage-ba vagy az Azure Data Lake Storage-ba. További információ: Az Apache Flume használata a HDInsighttal.
Átalakítás
Miután az adatok a kiválasztott helyen léteznek, meg kell tisztítania, össze kell egyesítenie, vagy elő kell készítenie egy adott használati mintára. A Hive, a Pig és a Spark SQL mind jó választás ehhez a munkához. Mindegyik támogatott a HDInsightban.
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: