Az Apache Hive használata kinyerési, átalakítási és betöltési (ETL) eszközként
A bejövő adatokat általában törölnie és átalakítania kell, mielőtt betöltené őket egy elemzésre alkalmas helyre. A kinyerési, átalakítási és betöltési (ETL) műveletek az adatok előkészítésére és adatcélba való betöltésére szolgálnak. A HDInsighton futó Apache Hive strukturálatlan adatokban olvashat, szükség szerint feldolgozhatja az adatokat, majd betöltheti az adatokat egy relációs adattárházba döntéstámogatási rendszerekhez. Ebben a megközelítésben a rendszer kinyeri az adatokat a forrásból. Ezután adaptálható tárolóban, például Azure Storage-blobokban vagy Azure Data Lake Storage-ban tárolva. Az adatok ezután Hive-lekérdezések sorozatával lesznek átalakítva. Ezt követően a Hive-ben a céladattárba történő tömeges betöltés előkészítésére kerül sor.
Használati eset és modell áttekintése
Az alábbi ábra az ETL-automatizálás használati esetének és modelljének áttekintését mutatja be. A bemeneti adatok a megfelelő kimenet létrehozásához lesznek átalakítva. Az átalakítás során az adatok alakot, adattípust és még nyelvet is módosítanak. Az ETL-folyamatok metriká alakíthatják az imperialt, módosíthatják az időzónákat, és javíthatják a pontosságot, hogy megfelelően igazodjanak a célban lévő meglévő adatokhoz. Az ETL-folyamatok az új adatokat a meglévő adatokkal kombinálva naprakészen tarthatják a jelentéskészítést, vagy további betekintést nyerhetnek a meglévő adatokba. Az olyan alkalmazások, mint a jelentéskészítési eszközök és szolgáltatások ezt követően a kívánt formátumban használhatják fel ezeket az adatokat.
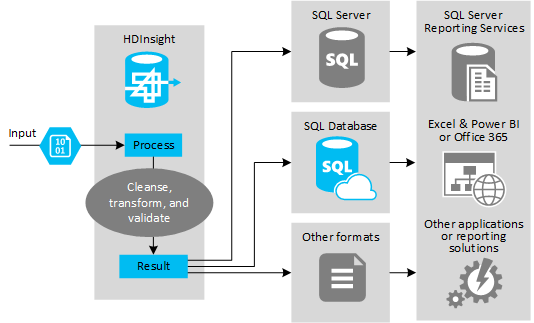
A Hadoopot általában olyan ETL-folyamatokban használják, amelyek nagy mennyiségű szövegfájlt (például CSV-ket) importálnak. Vagy kisebb, de gyakran változó számú szövegfájlt vagy mindkettőt. A Hive nagyszerű eszköz az adatok előkészítésére, mielőtt betöltené őket az adat célhelyére. A Hive lehetővé teszi, hogy sémát hozzon létre a CSV-n keresztül, és SQL-szerű nyelvet használva olyan MapReduce-programokat hozzon létre, amelyek használják az adatokat.
A Hive ETL-hez való használatának tipikus lépései a következők:
Adatok betöltése az Azure Data Lake Storage-ba vagy az Azure Blob Storage-ba.
Hozzon létre egy metaadattár-adatbázist (az Azure SQL Database használatával), amelyet a Hive használ a sémák tárolásához.
Hozzon létre egy HDInsight-fürtöt, és csatlakoztassa az adattárat.
Határozza meg az adattárban lévő adatokra vonatkozó olvasási időben alkalmazandó sémát:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Alakítsa át az adatokat, és töltse be a célhelyre. A Hive többféleképpen is használható az átalakítás és a betöltés során:
- Adatokat kérdezhet le és készíthet elő a Hive használatával, és mentheti CSV-ként az Azure Data Lake Storage-ban vagy az Azure Blob Storage-ban. Ezután használjon egy olyan eszközt, mint az SQL Server Integration Services (SSIS) ezeknek a CSV-knek a beszerzéséhez, és töltse be az adatokat egy cél relációs adatbázisba, például az SQL Serverbe.
- Az adatokat közvetlenül az Excelből vagy a C#-ból kérdezheti le a Hive ODBC-illesztővel.
- Az Apache Sqoop használatával olvassa be az előkészített lapos CSV-fájlokat, és töltse be őket a cél relációs adatbázisba.
Adatforrások
Az adatforrások általában külső adatok, amelyek megfeleltethetők az adattárban lévő meglévő adatoknak, például:
- Közösségimédia-adatok, naplófájlok, érzékelők és adatfájlokat létrehozó alkalmazások.
- Adatszolgáltatóktól beszerzett adathalmazok, például időjárási statisztikák vagy szállítói értékesítési számok.
- Megfelelő eszközzel vagy keretrendszerrel rögzített, szűrt és feldolgozott streamelési adatok.
Kimeneti célok
A Hive használatával különböző típusú célokhoz adhat ki adatokat, például:
- Relációs adatbázis, például SQL Server vagy Azure SQL Database.
- Egy adattárház, például az Azure Synapse Analytics.
- Excel.
- Azure Table and Blob Storage.
- Olyan alkalmazások vagy szolgáltatások, amelyeknél az adatok meghatározott formátumokba vagy adott típusú információstruktúrát tartalmazó fájlokként való feldolgozását igénylik.
- Egy JSON-dokumentumtár, például az Azure Cosmos DB.
Megfontolások
Az ETL-modellt általában a következő esetekben használja:
* Adatok vagy nagy mennyiségű félig strukturált vagy strukturálatlan adat betöltése külső forrásokból egy meglévő adatbázisba vagy információs rendszerbe.
* Az adatok betöltése előtt tisztítsa meg, alakítsa át és ellenőrizze az adatokat, esetleg több átalakítás használatával, amely áthalad a fürtön.
* Rendszeresen frissített jelentések és vizualizációk létrehozása. Ha például a jelentés létrehozása túl sokáig tart a nap folyamán, ütemezheti, hogy a jelentés éjszaka fusson. Hive-lekérdezés automatikus futtatásához használhatja az Azure Logic Appst és a PowerShellt.
Ha az adatok célja nem adatbázis, létrehozhat egy fájlt a lekérdezésen belül a megfelelő formátumban, például egy CSV-t. Ez a fájl ezután importálható az Excelbe vagy a Power BI-ba.
Ha az ETL-folyamat részeként több műveletet kell végrehajtania az adatokon, gondolja át, hogyan kezelheti őket. Ha a műveleteket külső program vezérli, és nem munkafolyamatként a megoldáson belül, döntse el, hogy egyes műveletek párhuzamosan végrehajthatók-e. És észlelni, hogy mikor fejeződik be az egyes feladatok. Egy munkafolyamat-mechanizmus, például az Oozie használata a Hadoopon belül egyszerűbb lehet, mint egy műveletsor vezénylése külső szkriptekkel vagy egyéni programokkal.