Az Azure HDInsight magas rendelkezésre állású megoldásarchitektúra-esettanulmánya
Az Azure HDInsight replikációs mechanizmusai integrálhatók egy magas rendelkezésre állású megoldásarchitektúrába. Ebben a cikkben egy fiktív esettanulmányt használunk a Contoso Retail számára a lehetséges magas rendelkezésre állású vészhelyreállítási megközelítések, a költségek szempontjai és azok megfelelő terveinek magyarázatára.
A magas rendelkezésre állású vészhelyreállítási javaslatok számos variációval és kombinációval rendelkezhetnek. Ezeket a megoldásokat az egyes lehetőségek előnyeinek és hátrányainak mérlegelése után kell meghozni. Ez a cikk csak egy lehetséges megoldást tárgyal.
Ügyfélarchitektúra
Az alábbi képen a Contoso Retail elsődleges architektúrája látható. Az architektúra streamelési számítási feladatokból, kötegelt számítási feladatokból, kiszolgálói rétegből, használati rétegből, tárolási rétegből és verziókövetésből áll.
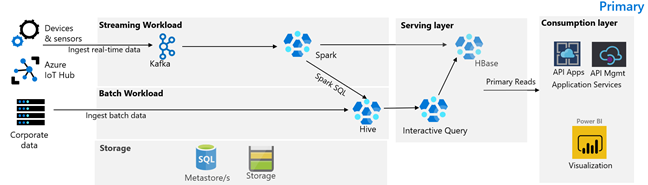
Streamelési számítási feladat
Az eszközök és érzékelők adatokat hoznak létre a HDInsight Kafkának, amely az üzenetkezelési keretrendszert képezi. Egy HDInsight Spark-felhasználó olvas a Kafka-témakörökből. A Spark átalakítja a bejövő üzeneteket, és egy HDInsight HBase-fürtbe írja a kiszolgálórétegen.
Batch-számítási feladat
A Hive-t és a MapReduce-t futtató HDInsight Hadoop-fürt adatokat dolgoz fel helyszíni tranzakciós rendszerekből. A Hive és a MapReduce által átalakított nyers adatok Hive-táblákban vannak tárolva az Azure Data Lake Storage Gen2 által támogatott data lake logikai partícióján. A Hive-táblákban tárolt adatok a Spark SQL számára is elérhetővé válnak, ami kötegelt átalakításokat végez, mielőtt a válogatott adatokat a HBase-ben tárolná a szolgáltatáshoz.
Kiszolgáló réteg
Az Apache Phoenixet használó HDInsight HBase-fürt adatokat szolgál ki webalkalmazások és vizualizációs irányítópultok számára. A HDInsight LLAP-fürtök a belső jelentéskészítési követelmények teljesítésére szolgálnak.
Használati réteg
Az Azure API Apps és az API Management réteg egy nyilvános elérésű weblapot hoz létre. A belső jelentéskészítési követelményeket a Power BI teljesíti.
Tárolási réteg
A logikailag particionált Azure Data Lake Storage Gen2 vállalati adattóként használatos. A HDInsight-metaadattárakról az Azure SQL DB készít biztonsági másolatot.
Verziókövetési rendszer
Egy Azure Pipelinesba integrált verziókövetési rendszer, amely az Azure-on kívül van üzemeltetve.
Ügyfél üzletmenet-folytonossági követelményei
Fontos meghatározni, hogy milyen minimális üzleti funkciókra lesz szüksége katasztrófa esetén.
A Contoso Retail üzletmenet-folytonossági követelményei
- Meg kell védenünk magunkat egy regionális hiba vagy regionális szolgáltatásállapot-probléma ellen.
- Az ügyfeleimnek soha nem szabad 404-et látniuk. A nyilvános tartalmat mindig kézbesíteni kell. (RTO = 0)
- Az év nagy részében 5 órával elavult nyilvános tartalmakat jeleníthetünk meg. (RPO = 5 óra)
- Az ünnepi időszakban a nyilvános tartalmaknak mindig naprakésznek kell lenniük. (RPO = 0)
- A belső jelentéskészítési követelményeim nem tekinthetők kritikus fontosságúnak az üzletmenet folytonossága szempontjából.
- Üzletmenet-folytonossági költségek optimalizálása.
Javasolt megoldás
Az alábbi képen a Contoso Retail magas rendelkezésre állású vészhelyreállítási architektúrája látható.
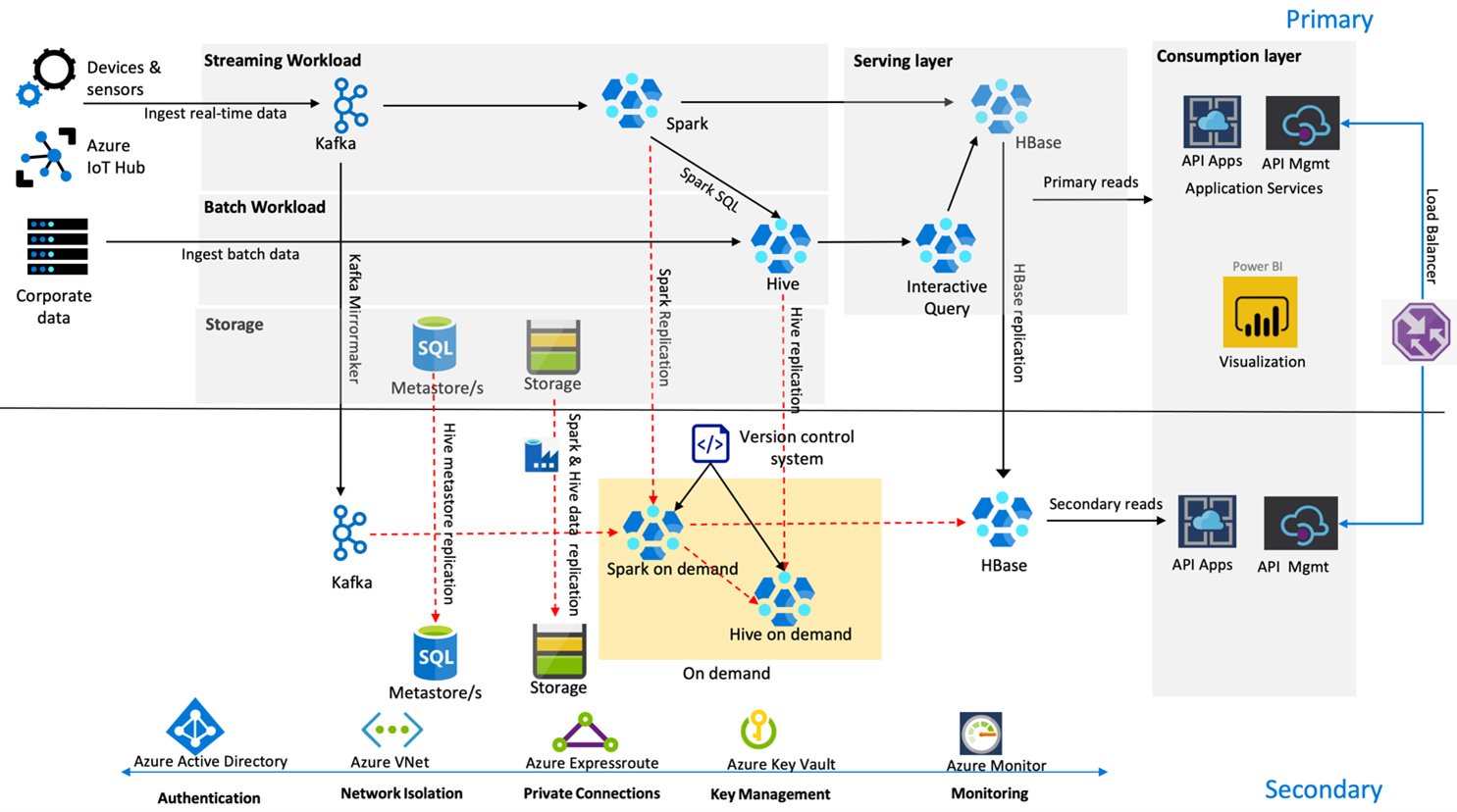
A Kafka aktív – passzív replikációt használ a Kafka-témakörök tükrözéséhez az elsődleges régióból a másodlagos régióba. A Kafka-replikáció alternatívája lehet a Kafka mindkét régióban történő előállítása.
A Hive és a Spark az aktív elsődleges – igény szerinti másodlagos replikációs modelleket használja a normál időkben. A Hive-replikációs folyamat rendszeresen fut, és a Hive Azure SQL-metaadattár és a Hive-tárfiók replikációjának kísérője. A Spark-tárfiók rendszeres replikálása az ADF DistCP használatával történik. A fürtök átmeneti jellege segít a költségek optimalizálásában. A replikációk 4 óránként vannak ütemezve, hogy egy olyan RPO-hoz érkezzenek, amely megfelel az ötórás követelménynek.
A HBase-replikáció a Leader – Követő modellt használja a normál időkben annak biztosítására, hogy az adatok mindig a régiótól függetlenül legyenek kiszolgálva, és az RPO nagyon alacsony legyen.
Ha az elsődleges régióban regionális hiba történik, a weblap és a háttértartalom 5 órán keresztül, bizonyos fokú elavultság mellett a másodlagos régióból lesz kiszolgálva. Ha az Azure service Health irányítópultja nem jelez helyreállítási ETA-t az öt órás ablakban, a Contoso Retail létrehozza a Hive és a Spark transzformációs réteget a másodlagos régióban, majd az összes felsőbb rétegbeli adatforrást a másodlagos régióra irányítja. Ha a másodlagos régió írhatóvá válik, az olyan feladat-visszavételi folyamatot eredményez, amely az elsődlegesre történő replikációt foglalja magában.
A vásárlási csúcsidőszakban a teljes másodlagos folyamat mindig aktív és fut. A Kafka-gyártók mindkét régióban termelnek, és a HBase replikációja Leader-Követőről Leader-Leaderre változna, hogy a nyilvános tartalmak mindig naprakészek legyenek.
A feladatátvételi megoldást nem kell belső jelentéskészítésre tervezni, mivel ez nem kritikus fontosságú az üzletmenet folytonossága szempontjából.
Következő lépések
A cikkben tárgyalt elemekről a következő témakörben olvashat bővebben: