Az Azure HDInsight üzletmenet-folytonossági architektúrái
Ez a cikk néhány példát mutat be az Azure HDInsight üzletmenet-folytonossági architektúráira. A csökkentett funkciókra vonatkozó tolerancia katasztrófa esetén olyan üzleti döntés, amely az egyik alkalmazástól a másikig eltérő. Előfordulhat, hogy egyes alkalmazások nem érhetők el, vagy részlegesen elérhetők lesznek csökkentett funkcionalitással vagy késleltetett feldolgozással egy ideig. Más alkalmazások esetében a csökkentett funkciók elfogadhatatlanok lehetnek.
Feljegyzés
A cikkben bemutatott architektúrák egyáltalán nem teljesek. A várt üzletmenet-folytonosság, a működési összetettség és a tulajdonosi költségek objektív meghatározása után érdemes megterveznie saját egyedi architektúráit.
Apache Hive és interaktív lekérdezés
A Hive Replication V2 használata ajánlott a HDInsight Hive- és interaktív lekérdezésfürtök üzletmenet-folytonosságához. A replikálni kívánt önálló Hive-fürt állandó szakaszai a Storage Layer és a Hive metaadattár. A többfelhasználós, nagyvállalati biztonsági csomaggal rendelkező hive-fürtöknek a Microsoft Entra Domain Servicesre és a Ranger Metastore-ra van szükségük.
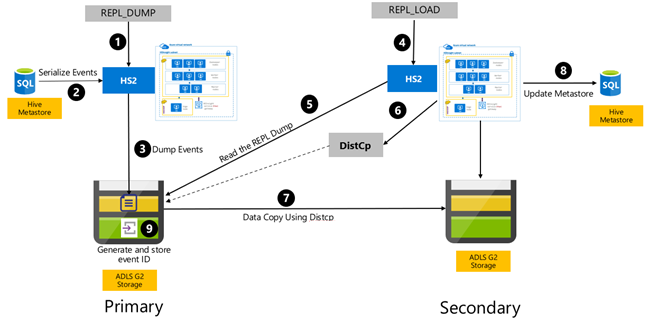
A Hive eseményalapú replikációja az elsődleges és a másodlagos fürtök között van konfigurálva. Ez két különböző fázisból áll, a rendszerindításból és a növekményes futtatásokból:
A bootstrapping replikálja a teljes Hive-raktárat, beleértve a Hive metaadattár adatait az elsődlegesről a másodlagosra.
A növekményes futtatások automatizáltak az elsődleges fürtön, és a növekményes futtatások során létrehozott események vissza lesznek játszva a másodlagos fürtön. A másodlagos fürt utoléri az elsődleges fürtből létrehozott eseményeket, biztosítva, hogy a másodlagos fürt összhangban legyen az elsődleges fürt eseményeivel a replikáció futtatása után.
A másodlagos fürtre csak a replikáció időpontjában van szükség az elosztott másolás futtatásához, DistCpde a tárolónak és a metaadattárnak állandónak kell lennie. Dönthet úgy, hogy igény szerint elindít egy szkriptelt másodlagos fürtöt a replikáció előtt, futtatja rajta a replikációs szkriptet, majd a sikeres replikáció után bontja le.
A másodlagos fürt általában írásvédett. A másodlagos fürt írásvédetté alakítható, de ez további összetettséghez ad hozzá, amely magában foglalja a másodlagos fürt módosításainak replikálását az elsődleges fürtre.
Hive eseményalapú replikációs RPO > RTO
RPO: Az adatvesztés az utolsó sikeres növekményes replikációs eseményre korlátozódik az elsődlegestől a másodlagosig.
RTO: A hiba és a másodlagossal végzett felső és alsóbb rétegbeli tranzakciók újrakezdése közötti idő.
Apache Hive- és interaktív lekérdezési architektúrák
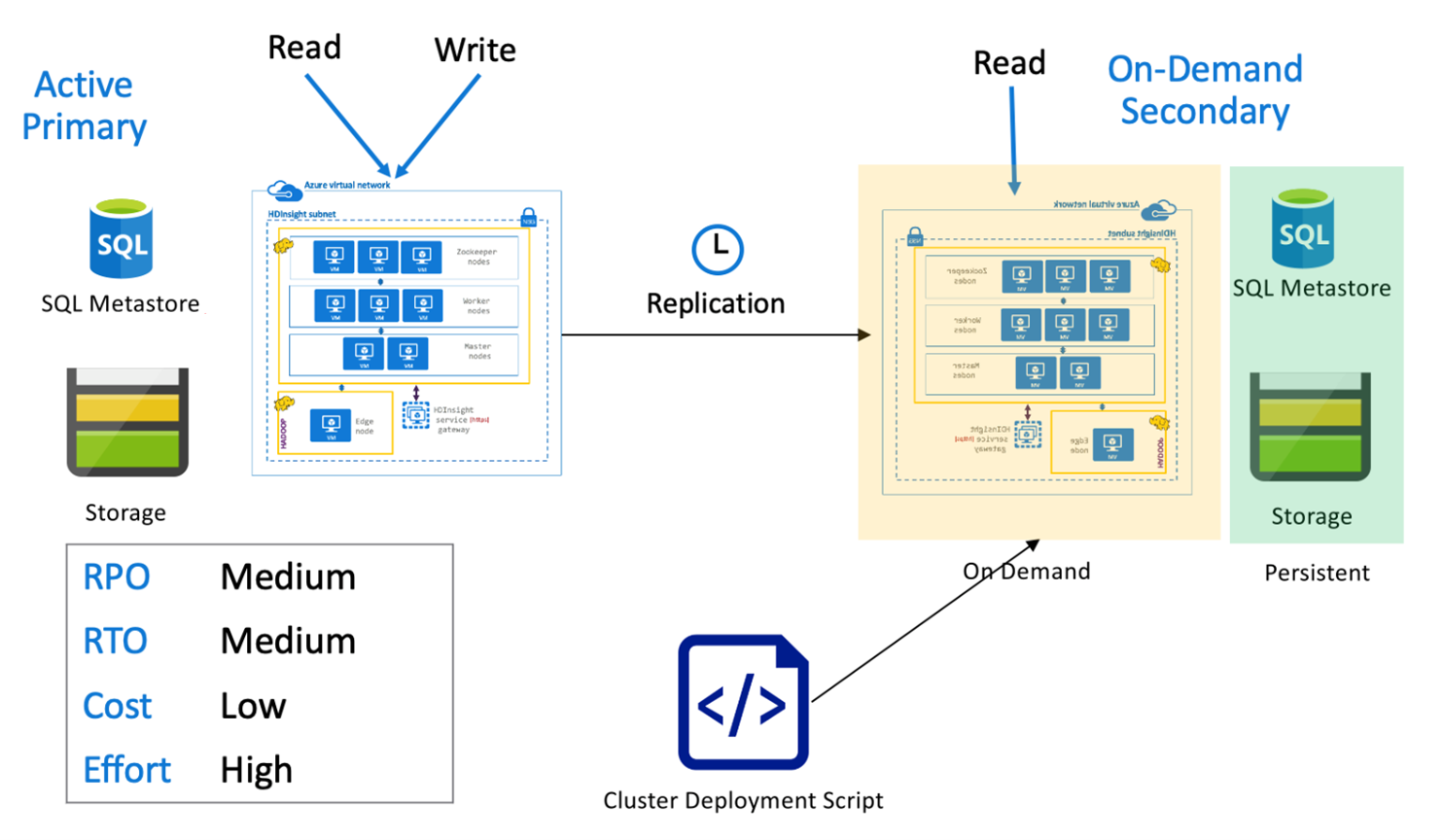
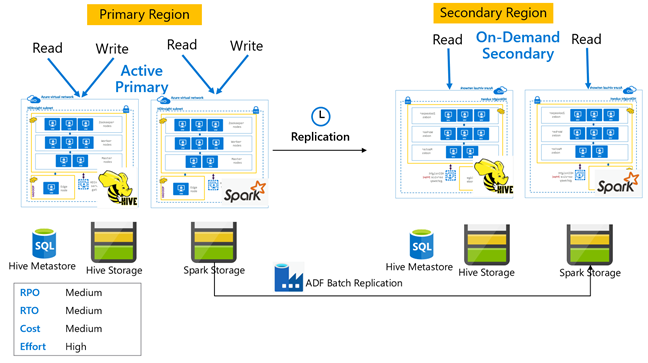
Aktív elsődleges hive igény szerinti másodlagossal
Az igény szerinti másodlagos architektúrával rendelkező aktív elsődleges környezetben az alkalmazások az aktív elsődleges régióba írnak, míg a másodlagos régióban a normál műveletek során nincs fürt kiépítve. Az SQL Metastore és a Storage a másodlagos régióban állandó, míg a HDInsight-fürt szkriptje és telepítése igény szerint történik, csak az ütemezett Hive-replikáció futtatása előtt.
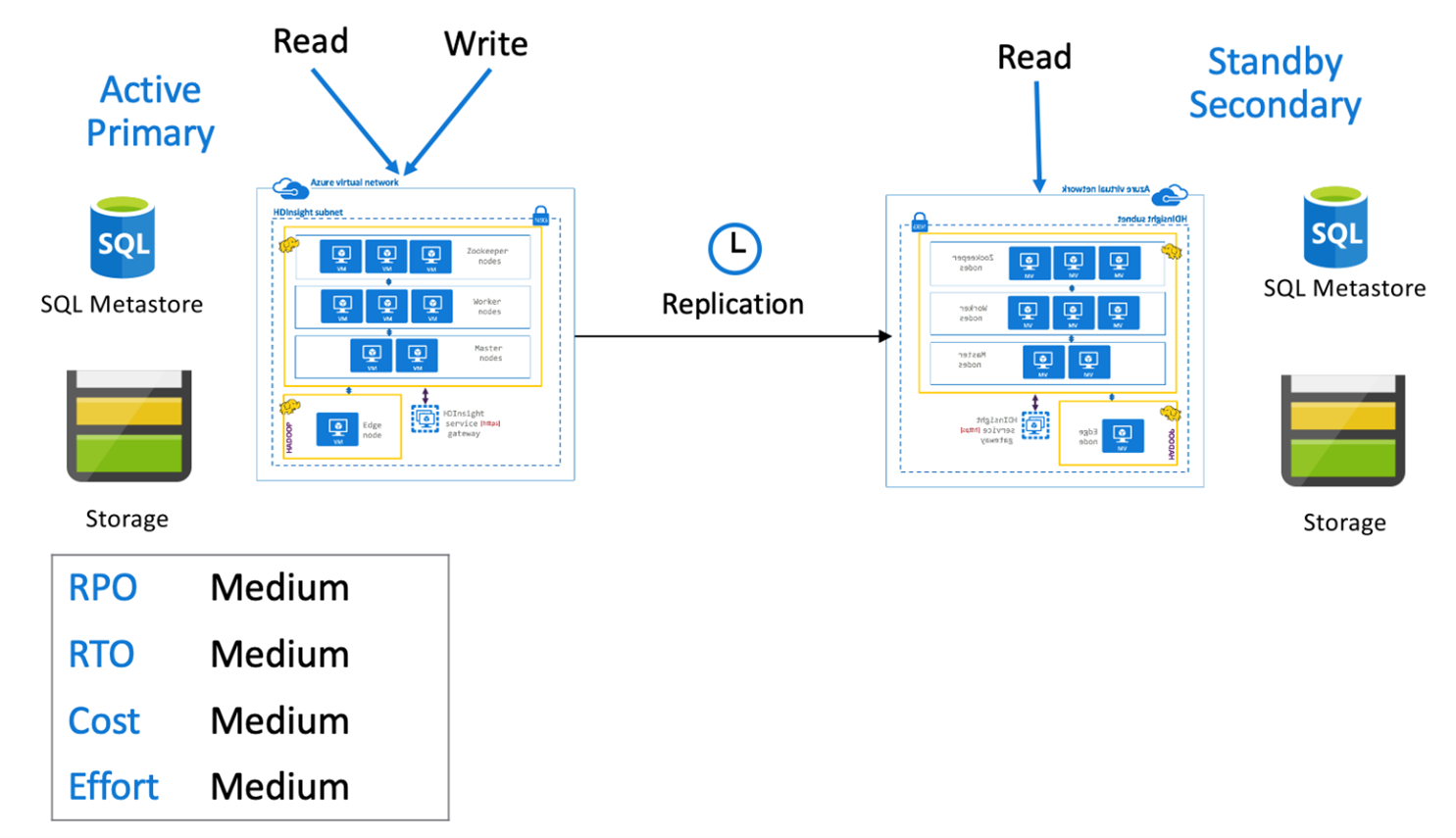
Aktív elsődleges hive másodlagos készenléti állapottal
Egy másodlagos készenléti állapotú aktív elsődleges területen az alkalmazások az aktív elsődleges régióba írnak, míg a készenléti skálázott másodlagos fürt írásvédett módban fut a normál műveletek során. A normál műveletek során dönthet úgy, hogy a régióspecifikus olvasási műveleteket másodlagosra irányítja ki.
A Hive-replikációról és a kódmintákról további információt az Apache Hive replikációja az Azure HDInsight-fürtökben talál
Apache Spark
A Spark számítási feladatai hive-összetevőt tartalmazhatnak vagy nem. Annak érdekében, hogy a Spark SQL számítási feladatai adatokat olvashassanak és írjanak a Hive-ből, a HDInsight Spark-fürtök a Hive/Interaktív lekérdezésfürtökből származó Hive-egyéni metaadattárakat osztanak meg ugyanabban a régióban. Ilyen esetekben a Spark-számítási feladatok régiók közötti replikációjának a Hive-metaadattárak és -tárolók replikációját is kísérnie kell. Az ebben a szakaszban szereplő feladatátvételi forgatókönyvek az alábbiakra vonatkoznak:
- Spark SQL ACID-táblákon a Hive Warehouse Csatlakozás or (HWC) beállításával EGY HDInsight Interaktív lekérdezési fürt használatával.
- Spark SQL-számítási feladat nem ACID-táblákon HDInsight Hadoop-fürt használatával.
Azokban a forgatókönyvekben, ahol a Spark önálló módban működik, a válogatott adatokat és a tárolt Spark Jarokat (Livy-feladatokhoz) rendszeresen replikálni kell az elsődleges régióból a másodlagos régióba az Azure Data Factory DistCPhasználatával.
Javasoljuk, hogy verziókövetési rendszerekkel tárolja a Spark-jegyzetfüzeteket és -tárakat, amelyek könnyen üzembe helyezhetők elsődleges vagy másodlagos fürtökön. Győződjön meg arról, hogy a jegyzetfüzetalapú és a nem jegyzetfüzetalapú megoldások készen állnak a megfelelő adatcsatlakozások betöltésére az elsődleges vagy a másodlagos munkaterületen.
Ha vannak olyan ügyfélspecifikus kódtárak, amelyek túlmutatnak a HDInsight natív szolgáltatásán, nyomon kell követni őket, és rendszeresen be kell tölteni őket a készenléti másodlagos fürtbe.
Apache Spark replikációs RPO > RTO
RPO: Az adatvesztés az utolsó sikeres növekményes replikációra (Spark és Hive) korlátozódik elsődlegesről másodlagosra.
RTO: A hiba és a másodlagossal végzett felső és alsóbb rétegbeli tranzakciók újrakezdése közötti idő.
Apache Spark-architektúrák
Aktív elsődleges spark igény szerinti másodlagossal
Az alkalmazások olvasása és írása a Spark- és Hive-fürtökbe az elsődleges régióban, míg a másodlagos régióban nincsenek kiépítve fürtök a normál műveletek során. Az SQL Metastore, a Hive Storage és a Spark Storage állandó a másodlagos régióban. A Spark- és Hive-fürtök igény szerint vannak szkriptelve és üzembe helyezve. A Hive-replikáció a Hive Storage- és Hive-metaadattárak replikálására szolgál, míg az DistCP Azure Data Factory önálló Spark-tároló másolására használható. A Hive-fürtöket a függőségi DistCp számítás miatt minden Hive-replikáció futtatása előtt telepíteni kell.
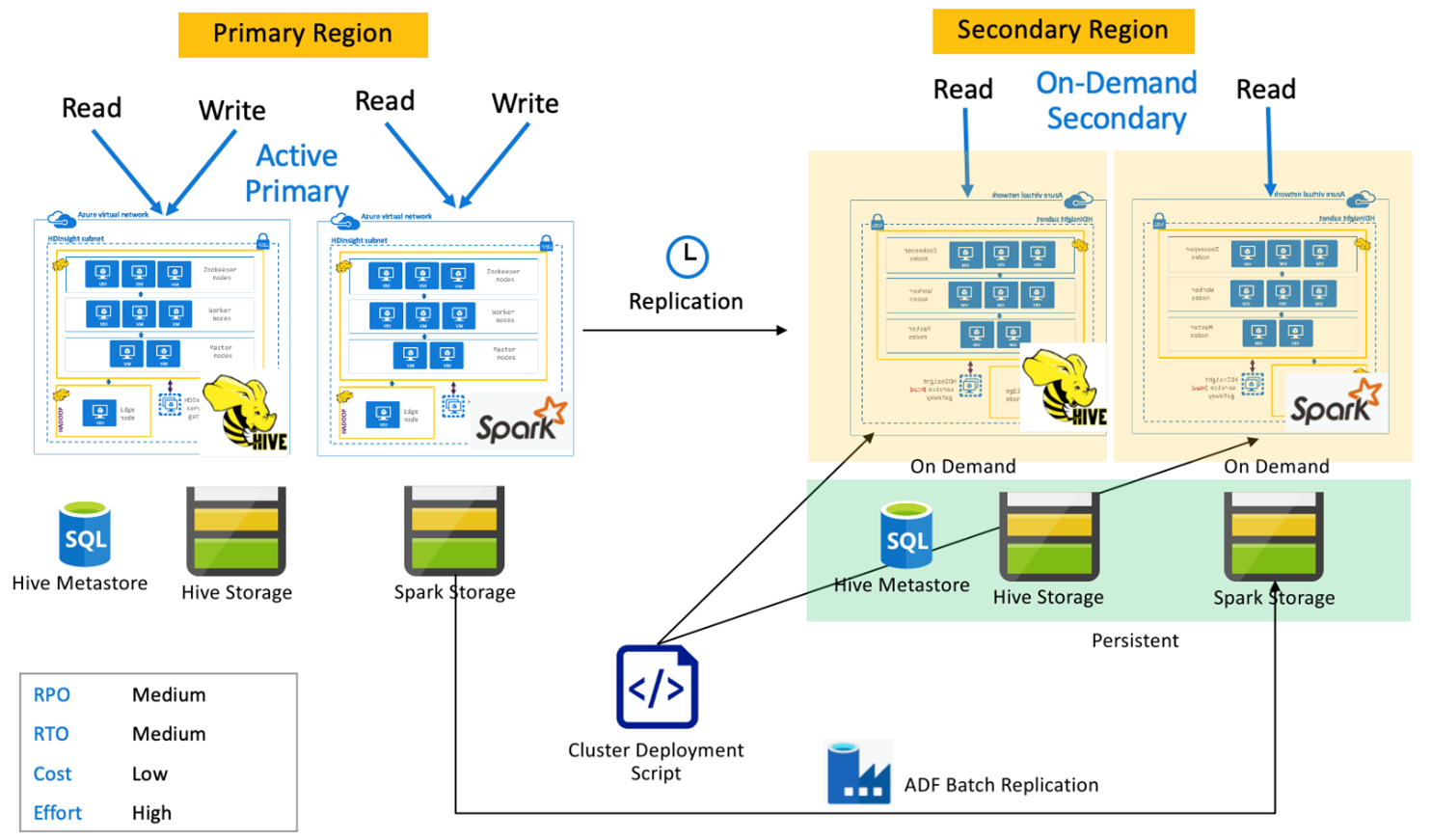
Aktív elsődleges spark másodlagos készenléti állapottal
Az alkalmazások az elsődleges régióban lévő Spark- és Hive-fürtökbe olvasnak és írnak, míg a készenléti skálázott Hive- és Spark-fürtök írásvédett módban a másodlagos régióban futnak a normál műveletek során. A normál műveletek során dönthet úgy, hogy a régióspecifikus Hive- és Spark-olvasási műveleteket másodlagosra irányítja ki.
Apache HBase
A HBase-exportálás és a HBase-replikáció a HDInsight HBase-fürtök közötti üzletmenet-folytonosság engedélyezésének gyakori módjai.
A HBase Export egy kötegreplikációs folyamat, amely a HBase Export Segédprogram használatával exportál táblákat az elsődleges HBase-fürtből a mögöttes Azure Data Lake Storage Gen 2-tárolóba. Az exportált adatok ezután elérhetők a másodlagos HBase-fürtből, és olyan táblákba importálhatók, amelyeknek a másodlagos helyen már meg kell létezniük. Bár a HBase Export táblaszintű részletességet kínál, növekményes frissítési helyzetekben az exportálási automatizálási motor szabályozza az egyes futtatásban belefoglalandó növekményes sorok tartományát. További információ: HDInsight HBase biztonsági mentés és replikáció.
A HBase-replikáció közel valós idejű replikációt használ a HBase-fürtök között teljesen automatizált módon. A replikáció a tábla szintjén történik. Az összes tábla vagy adott tábla megcélzható a replikációhoz. A HBase-replikáció végül konzisztens, ami azt jelenti, hogy az elsődleges régióban lévő táblák legutóbbi szerkesztései nem feltétlenül érhetők el azonnal az összes másodpéldány számára. A másodfokok garantáltan konzisztensek lesznek az elsődlegessel. A HBase-replikáció két vagy több HDInsight HBase-fürt között állítható be, ha:
- Az elsődleges és a másodlagos ugyanahhoz a virtuális hálózathoz tartoznak.
- Az elsődleges és a másodlagos társhálózatok ugyanabban a régióban különböző társhálózatokban találhatók.
- Az elsődleges és a másodlagos különböző társhálózatokban található különböző régiókban.
További információ: Apache HBase-fürtreplikálás beállítása Azure-beli virtuális hálózatokban.
A HBase-fürtök biztonsági mentésének más módjai is vannak, például a hbase mappa másolása, a táblázatok és a pillanatképek másolása.
HBase RPO & RTO
HBase-exportálás
- RPO: Az adatvesztés az elsődlegesből származó másodlagos köteg utolsó sikeres növekményes importálására korlátozódik.
- RTO: Az elsődleges és a másodlagos I/O-műveletek újraindítása közötti idő.
HBase-replikáció
- RPO: Az adatvesztés a másodlagos helyen kapott utolsó WalEdit-szállítmányra korlátozódik.
- RTO: Az elsődleges és a másodlagos I/O-műveletek újraindítása közötti idő.
HBase-architektúrák
A HBase-replikáció három módban állítható be: Leader-Follower, Leader-Leader és Ciklikus.
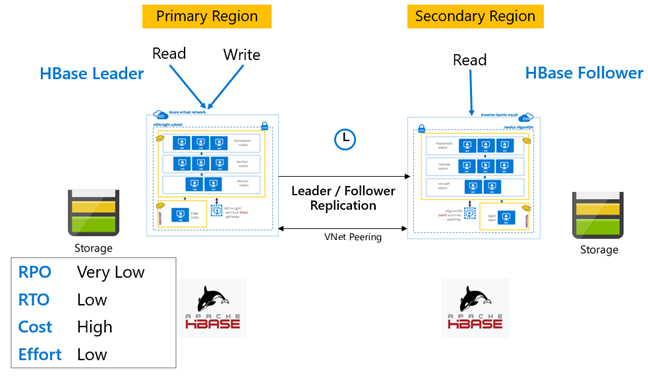
HBase-replikáció: Vezető – Követő modell
Ebben a régióközi beállításban a replikáció egyirányú az elsődleges régiótól a másodlagos régióig. Az elsődlegesen lévő összes tábla vagy adott tábla azonosítható egyirányú replikációhoz. A normál műveletek során a másodlagos fürt használható olvasási kérelmek kiszolgálására a saját régiójában.
A másodlagos fürt normál HBase-fürtként működik, amely képes saját táblákat üzemeltetni, és képes a regionális alkalmazásokból származó olvasási és írási műveletek kiszolgálására. A replikált táblákra vagy a másodlagosra natív táblákra írt írások azonban nem lesznek visszareplikáltak az elsődlegesre.
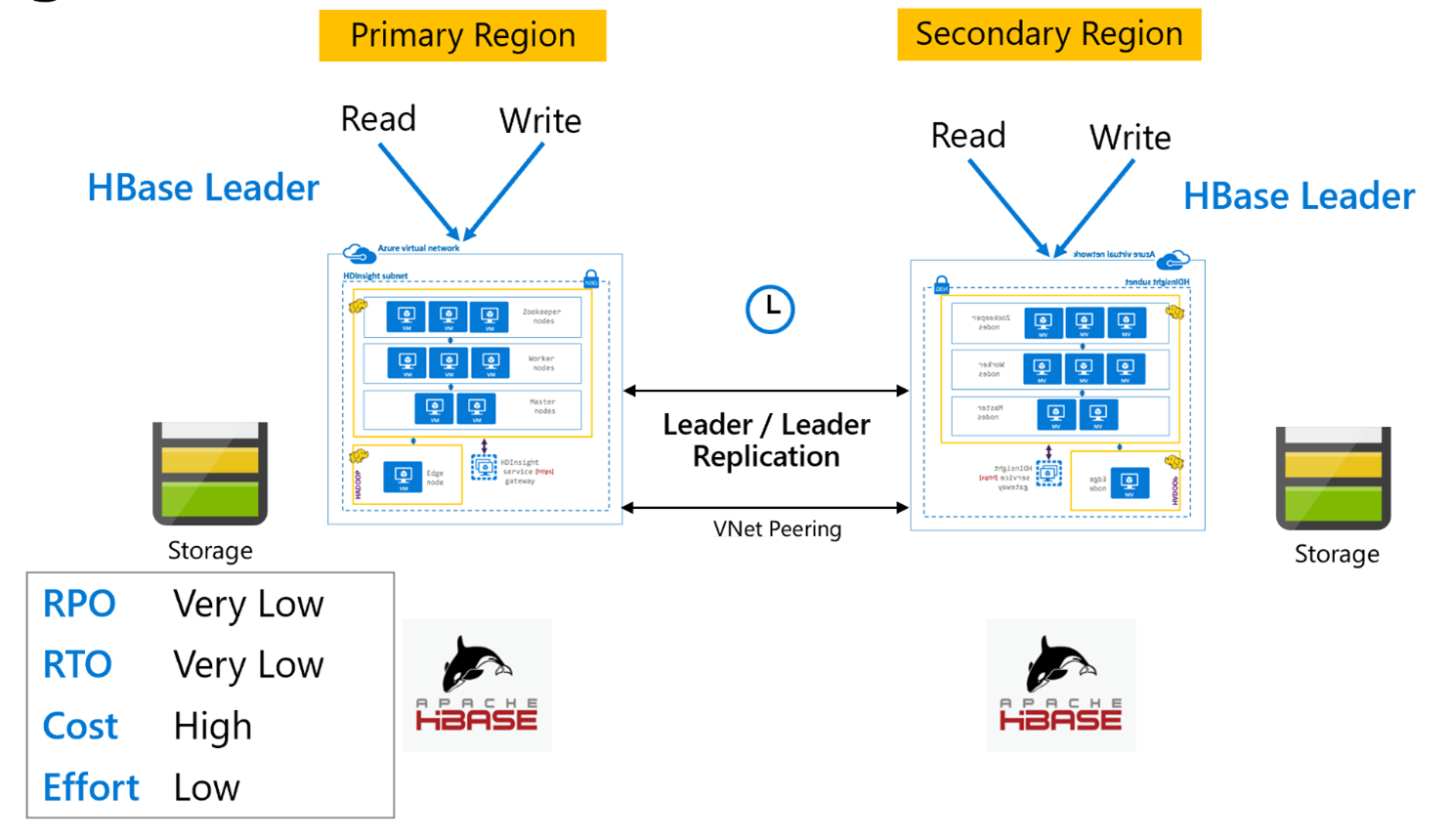
HBase-replikáció: Vezető – Vezető modell
Ez a régiók közötti beállítás nagyon hasonlít az egyirányú beállításhoz, azzal a különbségtel, hogy a replikáció kétirányúan történik az elsődleges régió és a másodlagos régió között. Az alkalmazások mindkét fürtöt olvasási-írási módban használhatják, és a frissítések aszinkron módon cserélődnek közöttük.
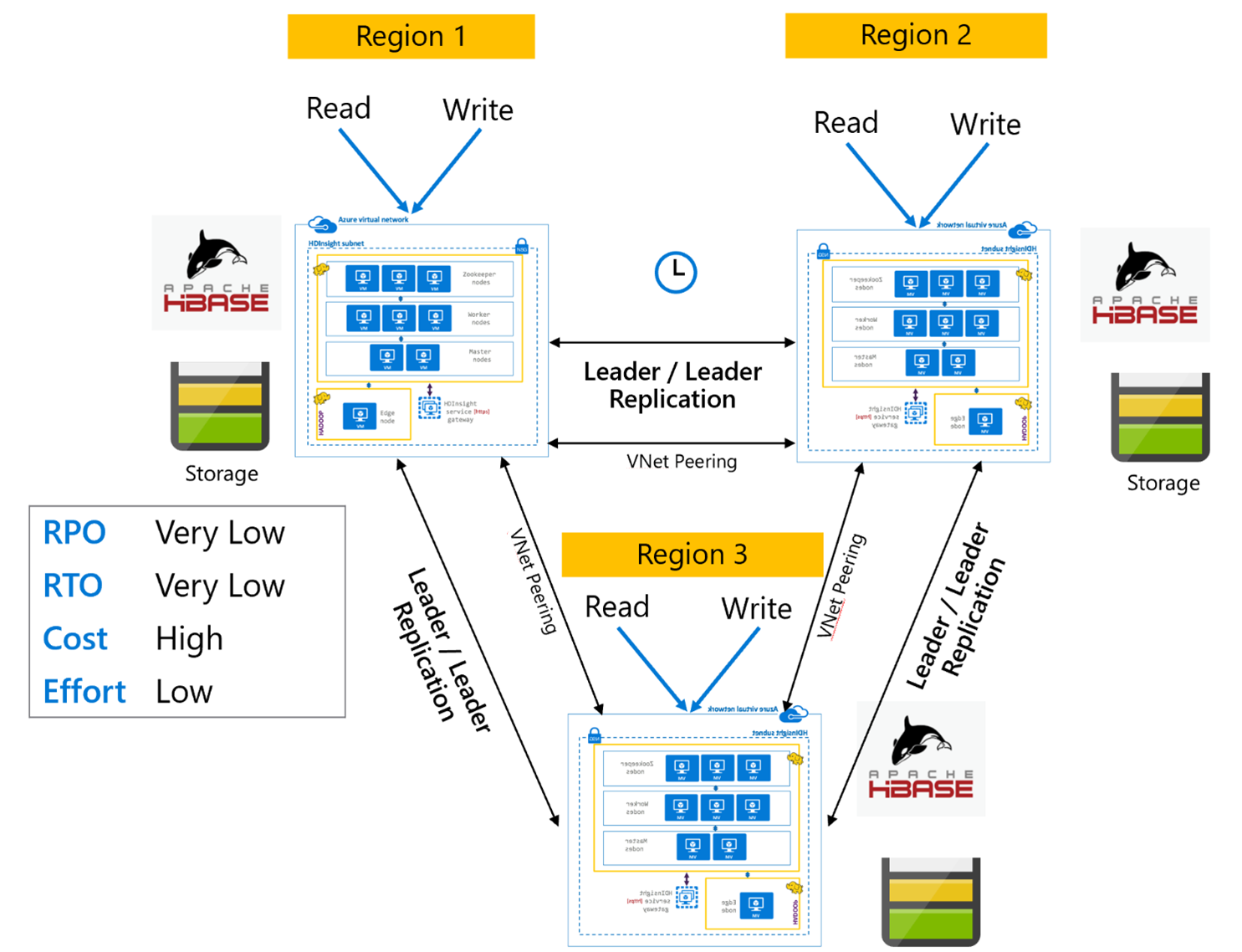
HBase-replikáció: többrégiós vagy ciklikus
A többrégiós/ciklikus replikációs modell a HBase-replikáció kiterjesztése, és egy globálisan redundáns HBase-architektúra létrehozásához használható több olyan alkalmazással, amelyek régióspecifikus HBase-fürtökbe írnak és olvasnak. A fürtök a Vezető/Vezető vagy a Vezető/Követő különböző kombinációiban állíthatók be az üzleti követelményektől függően.
Apache Kafka
A régiók közötti rendelkezésre állás engedélyezéséhez a HDInsight 4.0 támogatja a Kafka MirrorMakert, amely az elsődleges Kafka-fürt másodlagos replikája egy másik régióban való fenntartására használható. A MirrorMaker magas szintű fogyasztó-előállító párként működik, az elsődleges fürt egy adott témaköréből fogyaszt, és egy másodlagos névvel rendelkező témakörbe állítja elő. A magas rendelkezésre állású vészhelyreállítás fürtközi replikációja a MirrorMaker használatával azzal a feltételezéssel jár, hogy a gyártóknak és a fogyasztóknak át kell adniuk a feladatokat a replikafürtnek. További információ: Apache Kafka-témakörök replikálásának használata a HdInsighton futó Kafkával a MirrorMaker használatával
A replikáció indításakor a témakör élettartamától függően a MirrorMaker-témakör replikációja eltérő eltolódásokat eredményezhet a forrás- és replika témakörök között. A HDInsight Kafka-fürtök támogatják a témakör partícióreplikálását is, amely egy magas rendelkezésre állású funkció az egyes fürtök szintjén.
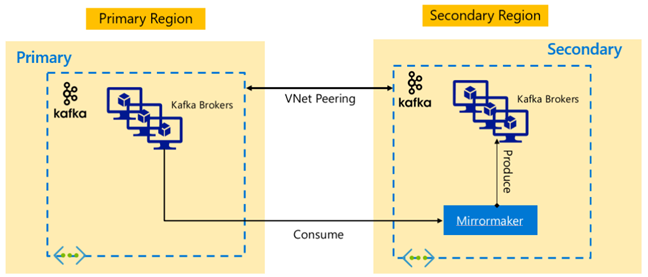
Apache Kafka-architektúrák
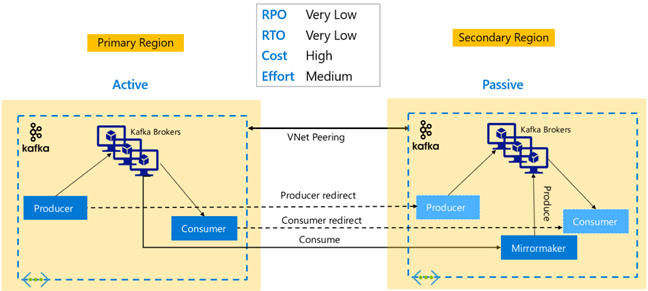
Kafka-replikáció: Aktív – Passzív
Az aktív-passzív beállítás lehetővé teszi az aszinkron egyirányú tükrözést aktívról passzívra. A termelőknek és a fogyasztóknak tisztában kell lenniük egy aktív és passzív fürt létezéséről, és készen kell állniuk arra, hogy az Aktív sikertelensége esetén átvezhetik a feladatokat a Passzív felé. Az alábbiakban bemutatjuk az Aktív-Passzív beállítás néhány előnyét és hátrányait.
Előnyök:
- A fürtök közötti hálózati késés nem befolyásolja az aktív fürt teljesítményét.
- Az egyirányú replikáció egyszerűsége.
Hátrányok:
- Előfordulhat, hogy a passzív fürt kihasználatlan marad.
- Összetettség kialakítása a feladatátvételi tudatosság alkalmazáskészítőkben és -fogyasztókban való beépítése során.
- Lehetséges adatvesztés az aktív fürt meghibásodása során.
- Az aktív és passzív fürtök közötti témakörök végleges konzisztenciája.
- Az elsődleges feladat-visszavételek üzenetkonzisztencia-inkonzisztencia kialakulásához vezethetnek a témakörökben.
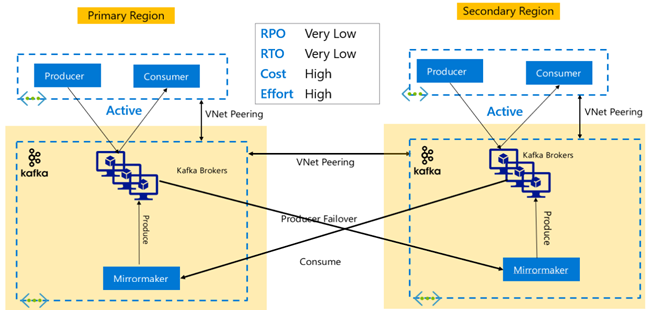
Kafka-replikáció: Aktív – Aktív
Az aktív-aktív beállítás két, regionálisan elkülönített, virtuális hálózattal társviszonyban lévő HDInsight Kafka-fürtöt tartalmaz, amelyek kétirányú aszinkron replikációt használnak a MirrorMakerrel. Ebben a kialakításban az elsődleges fogyasztók által felhasznált üzenetek másodlagosan és fordítva is elérhetővé válnak a fogyasztók számára. Az alábbiakban bemutatjuk az Active-Active beállítás néhány előnyét és hátrányait.
Előnyök:
- Duplikált állapotuk miatt a feladatátvételek és a feladat-visszavételek egyszerűbben végrehajthatók.
Hátrányok:
- A beállítás, a felügyelet és a figyelés összetettebb, mint az Active-Passive.
- A körkörös replikáció problémáját meg kell oldani.
- A kétirányú replikáció magasabb regionális adatforgalom-költségeket eredményez.
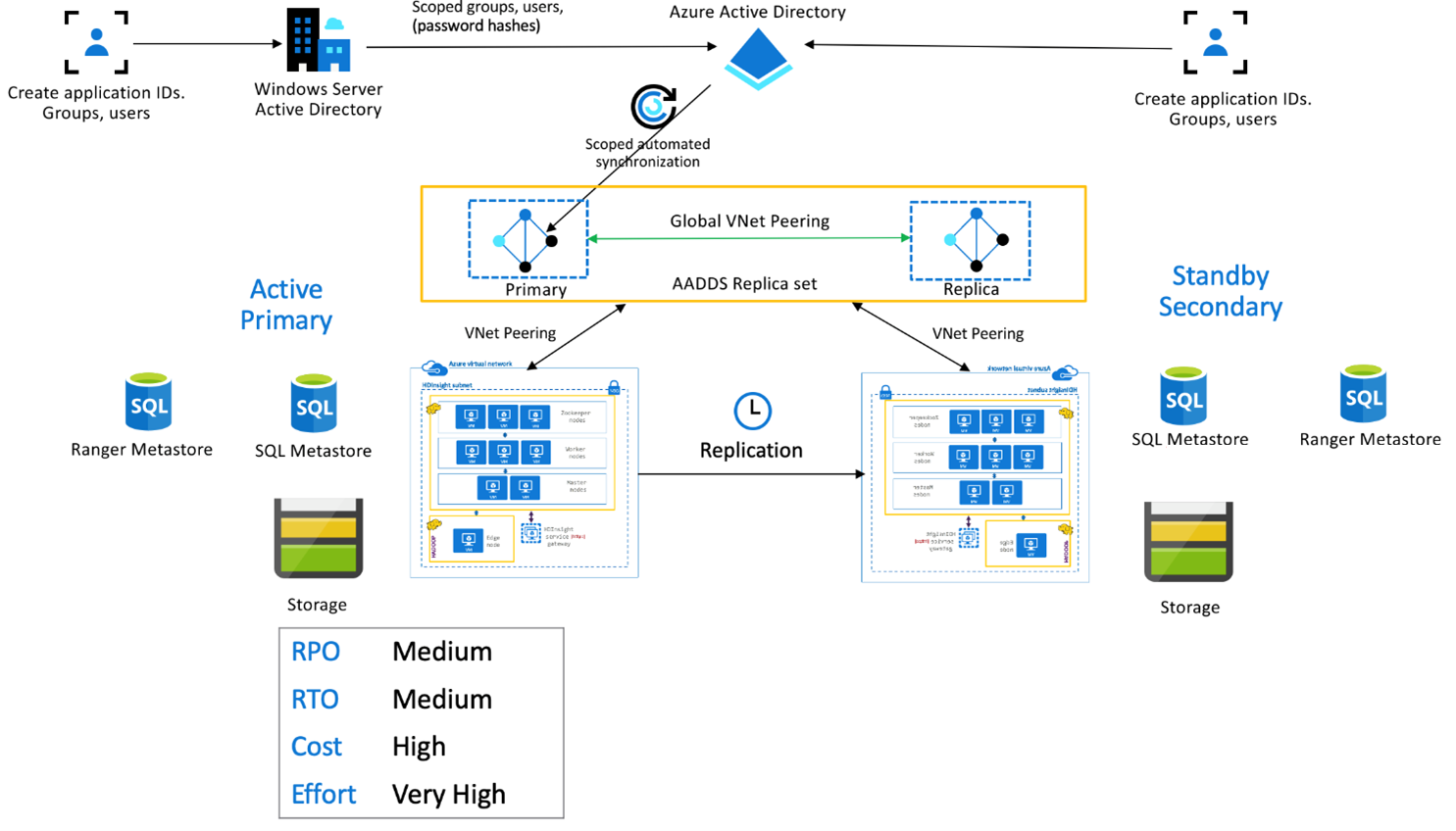
HDInsight Enterprise biztonsági csomag
Ez a beállítás az elsődleges és a másodlagos, valamint a Microsoft Entra Domain Services replikakészletek többfelhasználós funkcióinak engedélyezésére szolgál, hogy a felhasználók mindkét fürtön hitelesíthessék magukat. A normál műveletek során a Ranger-szabályzatokat a másodlagos helyen kell beállítani, hogy a felhasználók csak olvasási műveletekre legyenek korlátozva. Az alábbi architektúra bemutatja, hogyan nézhet ki egy ESP-kompatibilis Hive Active Primary – Készenléti másodlagos beállítás.
Ranger metaadattár replikációja:
A Ranger Metastore a Ranger-szabályzatok állandó tárolására és kiszolgálására szolgál az adatok engedélyezésének szabályozásához. Javasoljuk, hogy független Ranger-házirendeket tartson fenn az elsődleges és a másodlagos helyen, és tartsa fenn a másodlagost olvasási replikaként.
Ha a követelmény az, hogy a Ranger-szabályzatok szinkronban maradjanak az elsődleges és a másodlagos között, a Ranger Import/Export használatával rendszeresen biztonsági másolatot készít és importál a Ranger-házirendeket az elsődlegesről a másodlagosra.
A Ranger-szabályzatok elsődleges és másodlagos közötti replikálása írásvédetté teheti a másodlagost, ami véletlen írást eredményezhet a másodlagoson, ami adatkonzisztenciákhoz vezethet.
Következő lépések
A cikkben tárgyalt elemekről a következő témakörben olvashat bővebben: