Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Apache Kafka egy nyílt forráskódú elosztott streamelési platform streamadatfolyamatok és -alkalmazások létrehozásához. A Kafka az üzenetsorokhoz hasonló üzenetközvetítő funkciót is biztosít, amellyel adatstreameket tehet közzé, illetve feliratkozhat rájuk.
A HDInsight-alapú Kafka jellegzetességei:
Ez egy felügyelt szolgáltatás, amely egyszerűsített konfigurációs folyamatot biztosít. Ennek eredménye egy, a Microsoft által tesztelt és támogatott konfiguráció.
A Microsoft 99,9%-os szolgáltatói szerződést (SLA) nyújt a Kafka üzemidejével kapcsolatban. További információkért lásd a HDInsight szolgáltatói szerződésével kapcsolatos információkat ismertető dokumentumot.
A Kafka az Azure Managed Disks szolgáltatást használja háttértárként. A Managed Disks akár 16 TB tárhelyet biztosíthat Kafka-közvetítőnként. A felügyelt lemezek HDInsighton futó Kafkával való konfigurálásáról további információt az Apache Kafka skálázhatóságának növelése a HDInsighton című témakörben talál.
További tudnivalók a felügyelt lemezekről: Azure Managed Disks.
A Kafkát egy egydimenziós keret nézettel tervezték. Az Azure egy állványt két dimenzióra bont: a frissítési tartományokra (UD) és a hiba tartományokra (FD). A Microsoft biztosítja azokat az eszközöket, amelyek kiegyensúlyozhatják a Kafka-partíciókat és -replikákat a frissítési és tartalék tartományok között.
További információ: Magas rendelkezésre állás az Apache Kafkával a HDInsighton.
A HDInsight lehetővé teszi a feldolgozó csomópontok (amelyeken a Kafka-közvetítő fut) számának a fürt létrehozását követő módosítását. A vertikális skálázás az Azure Portalról, az Azure PowerShellből és más Azure felügyeleti felületekről végezhető el. A Kafka esetében érdemes kiegyenlíteni a partíciók replikáit a méretezési műveleteket követően. A partíciók átrendezése lehetővé teszi, hogy a Kafka kihasználja az új számú feldolgozó csomópontokat.
A HDInsight Kafka nem támogatja a fürtön belüli közvetítők számának lefelé skálázását vagy csökkentését. Ha kísérletet tesznek a csomópontok számának csökkentésére,
InvalidKafkaScaleDownRequestErrorCodea rendszer hibát ad vissza.További információ: Magas rendelkezésre állás az Apache Kafkával a HDInsighton.
Az Azure Monitor-naplók a Kafka HDInsighton való monitorozására használhatók. Az Azure Monitor naplói virtuálisgép-szintű információkat, például lemez- és hálózati adapter-metrikákat, valamint JMX-metrikákat jelenít meg a Kafkából.
További információ: Apache Kafka naplóinak elemzése a HDInsighton.
Apache Kafka az HDInsight architektúrán
Az alábbi ábra egy tipikus Kafka-konfigurációt mutat be, amely felhasználói csoportok, particionálás és replikálás használatával biztosítja az események párhuzamos olvasását hibatűréssel:
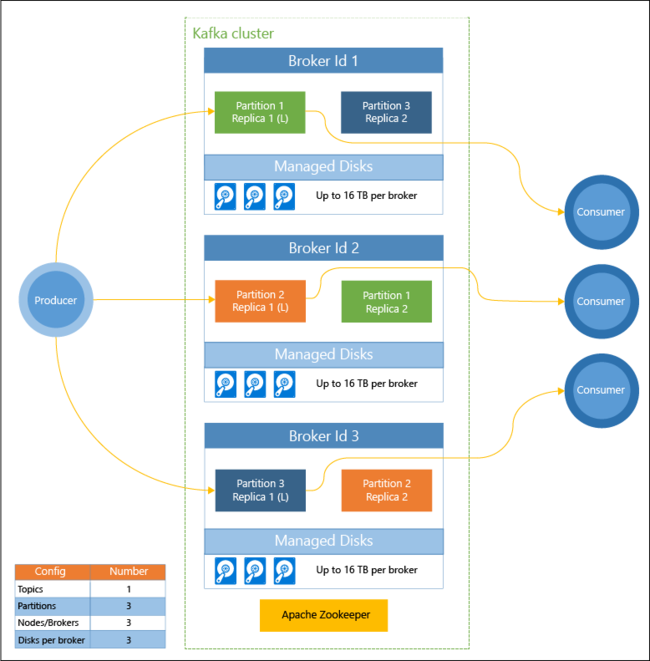
A Kafka-fürt állapotát az Apache ZooKeeper felügyeli. A ZooKeeper egyidejű, rugalmas és kis késleltetésű tranzakciókhoz készült.
A Kafka a rekordokat (adatokat) témakörökben tárolja. A rekordokat előállítók hozzák létre, és fogyasztók használják fel. Az előállítók Kafka-közvetítőknek adják tovább a rekordokat. A HDInsight-fürt mindegyik feldolgozó csomópontja egy Kafka-közvetítő.
A témakörök particionálják a rekordokat a közvetítők között. A rekordok felhasználásakor partíciónként legfeljebb egy fogyasztó használható, az adatok párhuzamos feldolgozása érdekében.
A partíciók csomópontok közötti duplikálásához a rendszer replikációt alkalmaz, amely védelmet nyújt a csomópontok (közvetítők) leállásával szemben. Az ábrán (L) jelöléssel rendelkező partíció az adott partíció vezetője. Az előállítói forgalmat a csomópontok vezetőjéhez irányítja a rendszer a ZooKeeper által kezelt állapot segítségével.
Miért érdemes az Apache Kafka-t használni a HDInsighton?
Néhány gyakori feladat és minta, amelyek a HDInsight-alapú Kafkával elvégezhetők:
| Használat | Leírás |
|---|---|
| Apache Kafka-adatok replikálása | A Kafka biztosítja a MirrorMaker segédprogramot, amely replikálja az adatokat a Kafka-fürtök között. A MirrorMaker használatával kapcsolatos információkért lásd : Apache Kafka-témakörök replikálás az Apache Kafkával a HDInsighton. |
| Közzétételi-feliratkozási üzenetkezelési minta | A Kafka egy Producer API-t biztosít a rekordok Kafka-témakörökben való közzétételéhez. A fogyasztói API-ra a témakörökre való feliratkozáskor van szükség. További információ: Start with Apache Kafka on HDInsight. |
| Streamfeldolgozás | A Kafkát gyakran használják a Sparkban valós idejű streamfeldolgozáshoz. A Kafka 2.1.1 és 2.4.1 (HDInsight 4.0-s és 5.0-s verzió) támogatja a streamelési API-kat, amelyek lehetővé teszik streamelési megoldások létrehozását Spark nélkül. További információ: Start with Apache Kafka on HDInsight. |
| Horizontális skálázhatóság | A Kafka elosztja a streameket a HDInsight-fürt csomópontjai között. A fogyasztói folyamatok társíthatók az egyes partíciókkal, így biztosítható a terheléselosztás a rekordok használatakor. További információ: Start with Apache Kafka on HDInsight. |
| Megrendelésben történő kézbesítés | Az egyes partíciókon belül a rekordok a streamben a beérkezés sorrendjében vannak tárolva. Partíciónként egy fogyasztói folyamat társításával garantálhatja, hogy a rekordok feldolgozása érkezési sorrendben történjen. További információ: Start with Apache Kafka on HDInsight. |
| Üzenetkezelés | Mivel támogatja a közzétételi-feliratkozási üzenetmintát, a Kafkát gyakran használják üzenetközvetítőként. |
| Tevékenységkövetés | Mivel a Kafka a rekordok sorrendben történő naplózását biztosítja, a tevékenységek nyomon követésére és újbóli létrehozására használható. Ilyen tevékenységek például a felhasználók műveletei egy webhelyen vagy egy alkalmazásban. |
| Összesítés | A streamfeldolgozással a különböző adatfolyamokból származó információkat összesítheti, hogy az információkat operatív adatokká egyesítse és központosítsa. |
| Átalakítás | A streamfeldolgozással több bemeneti témakör adatait kombinálhatja és bővítheti egy vagy több kimeneti témakörbe. |
Következő lépések
A HDInsighton futó Apache Kafka használatának megismeréséhez tekintse meg a következő hivatkozásokat: