Az Apache Hive optimalizálása az Apache Ambarival az Azure HDInsightban
Az Apache Ambari egy webes felület a HDInsight-fürtök kezeléséhez és monitorozásához. Az Ambari webes felhasználói felületének bemutatása: HDInsight-fürtök kezelése az Apache Ambari webes felhasználói felületének használatával.
A következő szakaszok az Apache Hive általános teljesítményének optimalizálására szolgáló konfigurációs lehetőségeket ismertetik.
- A Hive konfigurációs paramétereinek módosításához válassza a Hive lehetőséget a Szolgáltatások oldalsávon.
- Lépjen a Konfigurációk lapra.
A Hive végrehajtási motorjának beállítása
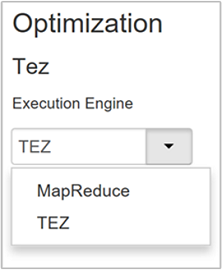
A Hive két végrehajtási motort biztosít: az Apache Hadoop MapReduce-t és az Apache TEZ-t. Tez gyorsabb, mint a MapReduce. A HDInsight Linux-fürtök alapértelmezett végrehajtási motorja a Tez. A végrehajtási motor módosítása:
A Hive Configs lapon írja be a végrehajtási motort a szűrőmezőbe.
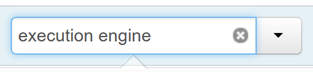
Az Optimalizálási tulajdonság alapértelmezett értéke a Tez.
Leképezők hangolása
A Hadoop egyetlen fájlt próbál felosztani (leképezni) több fájlra, és párhuzamosan feldolgozni az eredményül kapott fájlokat. A leképezők száma a felosztások számától függ. A következő két konfigurációs paraméter hajtja végre a Tez végrehajtási motor felosztásainak számát:
tez.grouping.min-size: Kisebb korlát egy csoportosított felosztás méretére vonatkozóan, amelynek alapértelmezett értéke 16 MB (16 777 216 bájt).tez.grouping.max-size: Egy csoportosított felosztás méretének felső korlátja, amelynek alapértelmezett értéke 1 GB (1 073 741 824 bájt).
Teljesítmény-útmutatóként csökkentse mindkét paramétert a késés javítása érdekében, és növelje az átviteli sebességet.
Ha például négy leképezési feladatot szeretne beállítani egy 128 MB-os adatmérethez, mindkét paramétert egyenként 32 MB-ra (33 554 432 bájt) állíthatja be.
A korlátparaméterek módosításához lépjen a Tez szolgáltatás Konfigurációk lapjára. Bontsa ki az Általános panelt, és keresse meg a paramétereket és
tez.grouping.min-sizeatez.grouping.max-sizeparamétereket.Mindkét paraméter beállítása 33 554 432 bájtra (32 MB).

Ezek a módosítások a kiszolgáló összes Tez-feladatára hatással vannak. Az optimális eredmény eléréséhez válassza ki a megfelelő paraméterértékeket.
Redukálók hangolása
Az Apache ORC és a Snappy is nagy teljesítményt nyújt. Előfordulhat azonban, hogy a Hive alapértelmezés szerint túl kevés redukálóval rendelkezik, ami szűk keresztmetszeteket okoz.
Tegyük fel például, hogy 50 GB bemeneti adatmérettel rendelkezik. Az orc formátumú, Snappy-tömörítéssel rendelkező adatok 1 GB-osak. A Hive a következők szerint becsüli meg a szükséges redukálók számát: (a mappers / hive.exec.reducers.bytes.per.reducer) által bevitt bájtok száma).
Az alapértelmezett beállításokkal ez a példa négy redukáló.
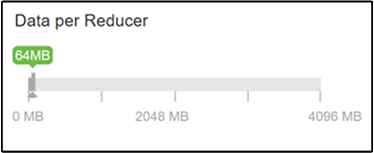
A hive.exec.reducers.bytes.per.reducer paraméter a redukátoronként feldolgozott bájtok számát adja meg. Az alapértelmezett érték 64 MB. Az érték lefelé hangolása növeli a párhuzamosságot, és javíthatja a teljesítményt. A túl alacsony hangolás túl sok redukálót is eredményezhet, ami hátrányosan befolyásolhatja a teljesítményt. Ez a paraméter az adott adatkövetelményeken, tömörítési beállításokon és egyéb környezeti tényezőkön alapul.
A paraméter módosításához lépjen a Hive Configs lapra, és keresse meg a Csökkentő paraméterenkénti adatokat a Gépház lapon.
A Szerkesztés gombra kattintva módosítsa az értéket 128 MB-ra (134 217 728 bájt), majd mentse az Enter billentyűt.
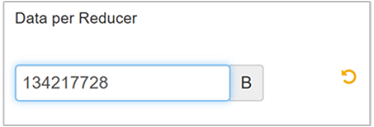
Mivel a bemeneti mérete 1024 MB, és 128 MB adat/csökkentő, nyolc redukáló (1024/128).
Az Adatmennyiség-csökkentő paraméter helytelen értéke nagy számú redukálót eredményezhet, ami hátrányosan befolyásolhatja a lekérdezés teljesítményét. A redukálók maximális számának korlátozásához állítsa be
hive.exec.reducers.maxa megfelelő értéket. Az alapértelmezett érték 1009.
Párhuzamos végrehajtás engedélyezése
A Hive-lekérdezések végrehajtása egy vagy több szakaszban történik. Ha a független szakaszok párhuzamosan futtathatók, az növeli a lekérdezési teljesítményt.
A párhuzamos lekérdezés végrehajtásának engedélyezéséhez lépjen a Hive Config lapra, és keresse meg a tulajdonságot
hive.exec.parallel. Az alapértelmezett érték: hamis. Módosítsa az értéket igaz értékre, majd az Enter billentyűt lenyomva mentse az értéket.A párhuzamosan futtatandó feladatok számának korlátozásához módosítsa a tulajdonságot
hive.exec.parallel.thread.number. Az alapértelmezett érték 8.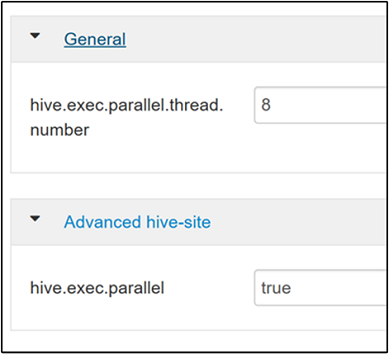
Vektorizálás engedélyezése
A Hive sorról sorra dolgozza fel az adatsorokat. A vektorizálás arra utasítja a Hive-t, hogy 1024 sorból álló blokkokban dolgozza fel az adatokat, és ne egyszerre egy sorban. A vektorizálás csak az ORC fájlformátumra vonatkozik.
Vektorizált lekérdezés végrehajtásának engedélyezéséhez lépjen a Hive Configs lapra, és keresse meg a paramétert
hive.vectorized.execution.enabled. Az alapértelmezett érték igaz a Hive 0.13.0-s vagy újabb verziójára.Ha engedélyezni szeretné a vektoros végrehajtást a lekérdezés csökkentési oldalán, állítsa a
hive.vectorized.execution.reduce.enabledparamétert igaz értékre. Az alapértelmezett érték: hamis.
Költségalapú optimalizálás engedélyezése (CBO)
A Hive alapértelmezés szerint egy optimális lekérdezés-végrehajtási terv megkereséséhez követ egy szabálykészletet. A költségalapú optimalizálás (CBO) több tervet értékel ki egy lekérdezés végrehajtásához. És minden tervhez hozzárendel egy költséget, majd meghatározza a lekérdezés végrehajtásához a legolcsóbb tervet.
A CBO engedélyezéséhez keresse meg a Hive>konfigurációkat> Gépház és keresse meg a Költségalapú optimalizáló engedélyezése lehetőséget, majd állítsa a kapcsológombot Be értékre.

A következő további konfigurációs paraméterek növelik a Hive-lekérdezés teljesítményét, ha a CBO engedélyezve van:
hive.compute.query.using.statsHa igaz értékre van állítva, a Hive a metaadattárában tárolt statisztikákat használja az olyan egyszerű lekérdezések megválaszolásához, mint a
count(*).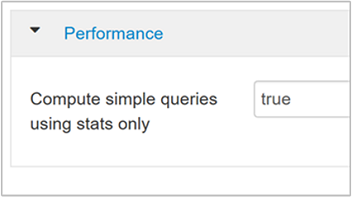
hive.stats.fetch.column.statsAz oszlopstatisztikák akkor jönnek létre, ha a CBO engedélyezve van. A Hive a metaadattárban tárolt oszlopstatisztikákat használja a lekérdezések optimalizálásához. Az egyes oszlopok oszlopstatisztikáinak lekérése hosszabb időt vesz igénybe, ha az oszlopok száma magas. Ha hamis értékre van állítva, ez a beállítás letiltja az oszlopstatisztikák beolvasását a metaadattárból.
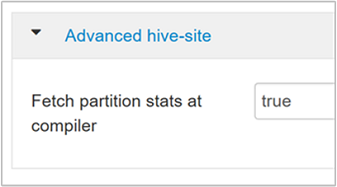
hive.stats.fetch.partition.statsAz alapszintű partícióstatisztikákat, például a sorok számát, az adatméretet és a fájlméretet a metaadattár tárolja. Ha igaz értékre van állítva, a rendszer lekéri a partícióstatisztikákat a metaadattárból. Ha hamis, a rendszer lekéri a fájlméretet a fájlrendszerből. A sorséma beolvassa a sorok számát.
További információért tekintse meg a Hive költségalapú optimalizálási blogbejegyzését az Azure-blog elemzésében
Köztes tömörítés engedélyezése
A leképezési feladatok köztes fájlokat hoznak létre, amelyeket a csökkentési feladatok használnak. A köztes tömörítés csökkenti a köztes fájl méretét.
A Hadoop-feladatok általában szűk keresztmetszetet jelentenek az I/O-nak. Az adatok tömörítése felgyorsíthatja az I/O és az általános hálózati átvitelt.
A rendelkezésre álló tömörítési típusok a következők:
| Formátum | Eszköz | Algoritmus | Fájlkiterjesztés | Felosztható? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
Nem |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Igen |
| LZO | Lzop |
LZO | .lzo |
Igen, ha indexelt |
| Snappy | n/a | Snappy | Snappy | Nem |
Általános szabály, hogy a tömörítési módszer felosztása fontos, különben kevés mapper jön létre. Ha a bemeneti adatok szövegesek, bzip2 akkor a legjobb választás. ORC formátum esetén a Snappy a leggyorsabb tömörítési lehetőség.
A köztes tömörítés engedélyezéséhez lépjen a Hive Configs lapra, majd állítsa a
hive.exec.compress.intermediateparamétert igaz értékre. Az alapértelmezett érték: hamis.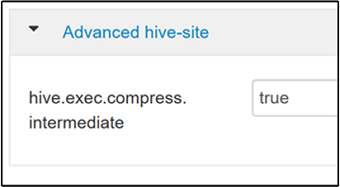
Feljegyzés
Köztes fájlok tömörítéséhez válasszon alacsonyabb cpu-költségű tömörítési kodeket, még akkor is, ha a kodek nem rendelkezik nagy tömörítési kimenettel.
A köztes tömörítési kodek beállításához adja hozzá az egyéni tulajdonságot
mapred.map.output.compression.codecahive-site.xmlfájlhoz.mapred-site.xmlEgyéni beállítás hozzáadása:
a. Lépjen a Hive>Configs>Advanced>Custom hive-site webhelyre.
b. Válassza a Tulajdonság hozzáadása... lehetőséget az Egyéni hive-hely panel alján.
c. A Tulajdonság hozzáadása ablakban adja meg
mapred.map.output.compression.codeckulcsként ésorg.apache.hadoop.io.compress.SnappyCodecértékként.d. Válassza a Hozzáadás lehetőséget.
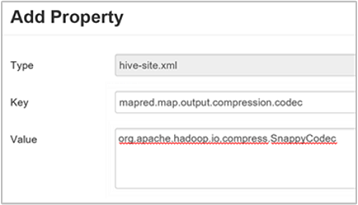
Ez a beállítás snappy-tömörítéssel tömöríti a köztes fájlt. A tulajdonság hozzáadása után megjelenik az Egyéni hive-hely panelen.
Feljegyzés
Ez az eljárás módosítja a
$HADOOP_HOME/conf/hive-site.xmlfájlt.
Végső kimenet tömörítése
A végleges Hive-kimenet is tömöríthető.
A végleges Hive-kimenet tömörítéséhez lépjen a Hive Configs lapra, és állítsa a
hive.exec.compress.outputparamétert igaz értékre. Az alapértelmezett érték: hamis.A kimeneti tömörítési kodek kiválasztásához adja hozzá az
mapred.output.compression.codecegyéni tulajdonságot az Egyéni hive-hely panelhez az előző szakasz 3. lépésében leírtak szerint.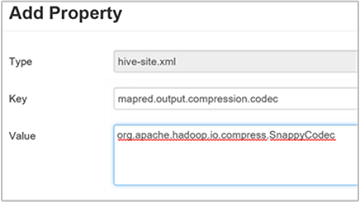
Spekulatív végrehajtás engedélyezése
A spekulatív végrehajtás bizonyos számú ismétlődő tevékenységet indít el, amelyek észlelik és elutasítják a lassan futó tevékenységkövető listáját. Miközben az egyes tevékenységek eredményeinek optimalizálásával javítja az általános feladatvégzést.
A spekulatív végrehajtást nem szabad bekapcsolni a nagy mennyiségű bemenettel rendelkező, hosszan futó MapReduce-feladatok esetében.
A spekulatív végrehajtás engedélyezéséhez lépjen a Hive Configs lapra, majd állítsa a
hive.mapred.reduce.tasks.speculative.executionparamétert igaz értékre. Az alapértelmezett érték: hamis.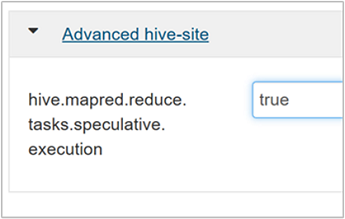
Dinamikus partíciók hangolása
A Hive lehetővé teszi dinamikus partíciók létrehozását rekordok táblázatba való beszúrásakor anélkül, hogy minden partíciót előre meghatároz. Ez a képesség hatékony funkció. Bár ez nagy számú partíció létrehozását eredményezheti. És sok fájl minden partícióhoz.
Ahhoz, hogy a Hive dinamikus partíciókat hajt végre, a
hive.exec.dynamic.partitionparaméter értékének igaznak (alapértelmezettnek) kell lennie.Módosítsa a dinamikus partíciós módot szigorúra. Szigorú módban legalább egy partíciónak statikusnak kell lennie. Ez a beállítás megakadályozza a WHERE záradék partíciószűrő nélküli lekérdezéseit, azaz szigorúan megakadályozza az összes partíciót beolvasó lekérdezéseket. Lépjen a Hive Configs lapra, majd állítsa be
hive.exec.dynamic.partition.modea szigorú értéket. Az alapértelmezett érték nem bonyolult.A létrehozandó dinamikus partíciók számának korlátozásához módosítsa a paramétert
hive.exec.max.dynamic.partitions. Az alapértelmezett érték 5000.A csomópontonkénti dinamikus partíciók teljes számának korlátozásához módosítsa a módosítást
hive.exec.max.dynamic.partitions.pernode. Az alapértelmezett érték 2000.
Helyi mód engedélyezése
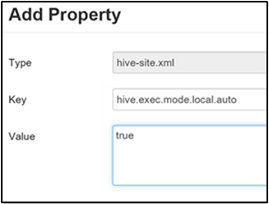
A helyi mód lehetővé teszi, hogy a Hive egyetlen gépen végezze el a feladatok összes feladatát. Vagy néha egyetlen folyamatban. Ez a beállítás javítja a lekérdezés teljesítményét, ha a bemeneti adatok kicsik. A feladatok lekérdezésekhez való elindításának többletterhelése pedig a lekérdezések teljes végrehajtásának jelentős hányadát használja fel.
A helyi mód engedélyezéséhez adja hozzá a hive.exec.mode.local.auto paramétert az Egyéni hive-hely panelhez, a köztes tömörítés engedélyezése szakasz 3. lépésében leírtak szerint.
Egyetlen MapReduce MultiGROUP BY beállítása
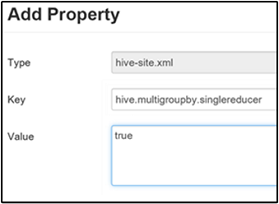
Ha ez a tulajdonság igaz értékre van állítva, egy többcsoportos BY lekérdezés közös csoportosítási kulcsokkal egyetlen MapReduce-feladatot hoz létre.
Ennek a viselkedésnek az engedélyezéséhez adja hozzá a hive.multigroupby.singlereducer paramétert az Egyéni hive-hely panelhez, a köztes tömörítés engedélyezése szakasz 3. lépésében leírtak szerint.
További Hive-optimalizálások
A következő szakaszok további, Hive-hez kapcsolódó optimalizálási lehetőségeket ismertetnek.
Csatlakozásoptimalizálások
A Hive alapértelmezett illesztéstípusa egy shuffle join. A Hive-ben a speciális leképezők felolvassák a bemenetet, és kibocsátanak egy illesztési kulcsot/értékpárt egy köztes fájlba. Hadoop rendezi és egyesíti ezeket a párokat egy egyesítési szakaszban. Ez a shuffle szakasz drága. Az adatok alapján a megfelelő illesztés kiválasztása jelentősen javíthatja a teljesítményt.
| Illesztés típusa | Mikor | Hogyan | Hive-beállítások | Megjegyzések |
|---|---|---|---|---|
| Illesztés shuffle |
|
|
Nincs szükség jelentős Hive-beállításra | Minden alkalommal működik |
| Csatlakozás leképezése |
|
|
hive.auto.confvert.join=true |
Gyors, de korlátozott |
| Egyesítési gyűjtő rendezése | Ha mindkét tábla a következő:
|
Minden folyamat:
|
hive.auto.convert.sortmerge.join=true |
Hatékony |
Végrehajtási motor optimalizálása
További ajánlások a Hive végrehajtási motor optimalizálására:
| Beállítás | Ajánlott | HDInsight Alapértelmezett |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = biztonságosabb, lassabb; false = gyorsabb | false |
tez.am.resource.memory.mb |
4 GB-os felső határ a legtöbb | Automatikusan hangolt |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |