Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben a rövid útmutatóban egy Azure Resource Manager-sablont (ARM-sablont) használ egy Apache Spark-fürt létrehozásához az Azure HDInsightban. Ezután létre kell hoznia egy Jupyter Notebook-fájlt, és használatával Spark SQL-lekérdezéseket futtathat Apache Hive-táblákon. Az Azure HDInsight egy felügyelt, teljes körű, nyílt forráskódú elemzési szolgáltatás vállalatok részére. A HDInsighthoz készült Apache Spark-keretrendszer lehetővé teszi a gyors adatelemzést és a fürt-számítástechnikát memóriabeli feldolgozással. A Jupyter Notebook lehetővé teszi az adatokkal való interakciót, a kód markdown szöveggel való kombinálását és egyszerű vizualizációk használatát.
Ha több fürtöt használ együtt, létre kell hoznia egy virtuális hálózatot, és Ha Spark-fürtöt használ, akkor a Hive Warehouse-összekötőt is használnia kell. További információ: Az Azure HDInsight virtuális hálózatának megtervezése, valamint az Apache Spark és az Apache Hive integrálása a Hive Warehouse-összekötővel.
Az Azure Resource Manager-sablon egy JavaScript Object Notation (JSON) fájl, amely meghatározza a projekt infrastruktúráját és konfigurációját. A sablon deklaratív szintaxist használ. Az üzembe helyezés létrehozásához szükséges programozási parancsok sorozatának megírása nélkül írhatja le a tervezett üzembe helyezést.
Ha a környezet megfelel az előfeltételeknek, és már ismeri az ARM-sablonokat, kattintson az Üzembe helyezés az Azure-ban gombra. A sablon az Azure Portalon fog megnyílni.

Előfeltételek
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
A sablon áttekintése
Az ebben a gyorsútmutatóban használt sablon az Azure-gyorssablonok közül származik.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
A sablonban két Azure-erőforrás van definiálva:
- Microsoft.Storage/storageAccounts: Hozzon létre egy Azure Storage-fiókot.
- Microsoft.HDInsight/fürt: hozzon létre egy HDInsight-fürtöt.
A sablon üzembe helyezése
Az alábbi Üzembe helyezés az Azure-ban gomb kiválasztásával jelentkezzen be az Azure-ba, és nyissa meg az ARM-sablont.
Adja meg vagy válassza ki a következő értékeket:
Tulajdonság Leírás Előfizetés A legördülő listában válassza ki a fürthöz használt Azure-előfizetést. Erőforráscsoport A legördülő listából válassza ki a meglévő erőforráscsoportot, vagy válassza az Új létrehozása lehetőséget. Hely Ezt az értéket a rendszer automatikusan kitölti az erőforráscsoporthoz használt hellyel. Fürt neve Adjon meg egy globálisan egyedi nevet. Ehhez a sablonhoz csak kisbetűket és számokat használjon. Fürt bejelentkezési felhasználóneve Adja meg a felhasználónevet, az alapértelmezett érték a . adminFürt bejelentkezési jelszava Adjon meg egy jelszót. A jelszónak legalább 10 karakter hosszúságúnak kell lennie, és tartalmaznia kell legalább egy számjegyet, egy nagybetűt és egy kisbetűt, egy nem alfanumerikus karaktert (a karakterek ' ` "kivételével).SSH-felhasználónév Adja meg a felhasználónevet, az alapértelmezett érték a . sshuserSSH-jelszó Adja meg a jelszót. 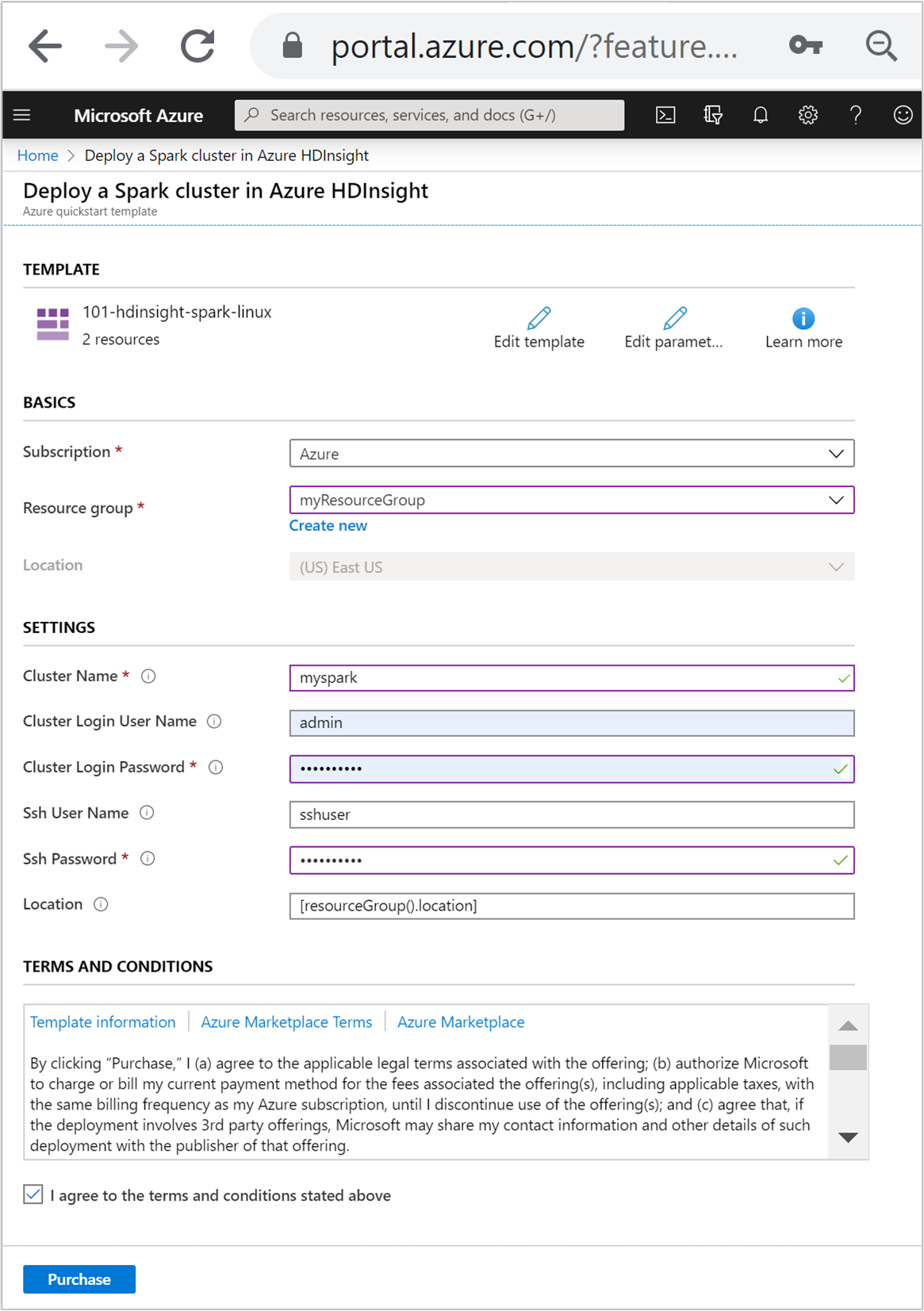
Tekintse át a HASZNÁLATI FELTÉTELEKET. Ezután válassza az Elfogadom a fenti feltételeket, majd a Vásárlás lehetőséget. Értesítést kap arról, hogy az üzembe helyezés folyamatban van. Egy fürt létrehozása nagyjából 20 percet vesz igénybe.
Ha HDInsight-fürtök létrehozásával kapcsolatos problémába ütközik, előfordulhat, hogy nem rendelkezik a megfelelő engedélyekkel. További információért tekintse meg a hozzáférés-vezérlésre vonatkozó követelményeket.
Üzembe helyezett erőforrások áttekintése
A fürt létrehozása után egy sikeres üzembe helyezési értesítést fog kapni egy Ugrás az erőforrásra hivatkozással. Az Erőforráscsoport lapon megjelenik az új HDInsight-fürt és a fürthöz társított alapértelmezett tároló. Minden fürt rendelkezik Azure Storage-tárhellyel vagy függőségsel Azure Data Lake Storage Gen2 . Ez az alapértelmezett tárfiók. A HDInsight-fürtöt és alapértelmezett tárfiókját ugyanabban az Azure-régióban kell áthelyezni. A fürtök törlése nem törli a tárfiók függőségét. Ez az alapértelmezett tárfiók. A HDInsight-fürtöt és annak alapértelmezett tárfiókját ugyanabban az Azure-régióban kell áthelyezni. A fürtök törlése nem törli a tárfiókot.
Jupyter Notebook-fájl létrehozása
A Jupyter Notebook egy interaktív jegyzetfüzet-környezet, amely különböző programozási nyelveket támogat. Jupyter Notebook-fájlokkal kezelheti az adatokat, kódot kombinálhat Markdown-szöveggel, és egyszerű vizualizációkat hajthat végre.
Nyissa meg az Azure Portalt.
Válassza a HDInsight-fürtök lehetőséget, majd a létrehozott fürtöt.
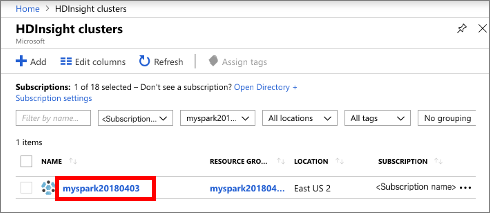
A portál Fürt irányítópultok szakaszában válassza a Jupyter Notebook lehetőséget. Ha a rendszer kéri, adja meg a fürthöz tartozó bejelentkezési hitelesítő adatokat.
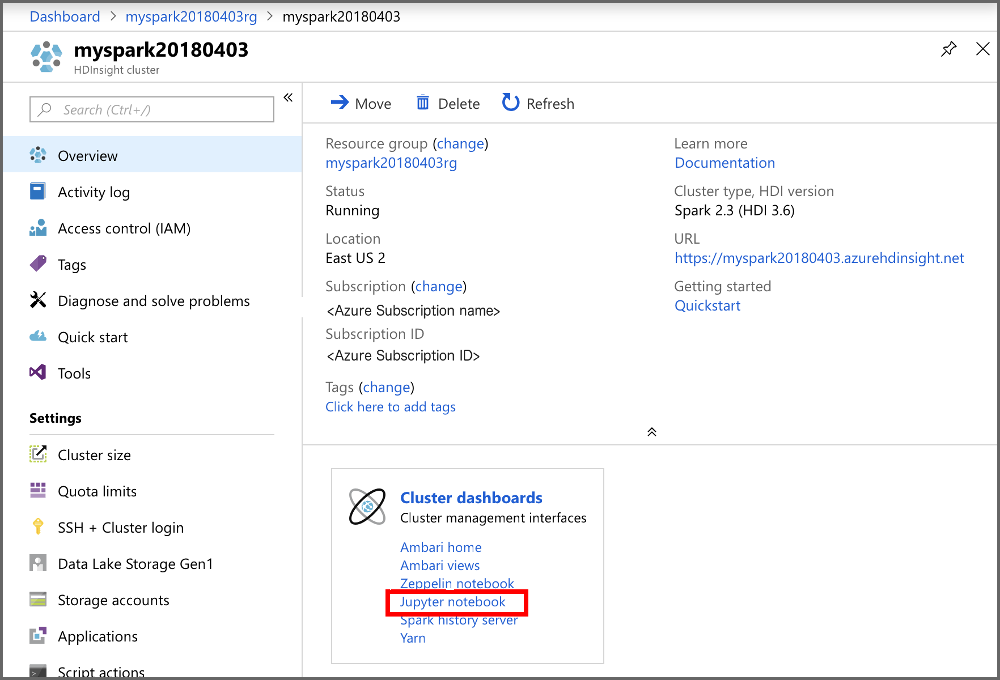
Új notebook létrehozásához válassza a New>PySpark (Új > PySpark) lehetőséget.
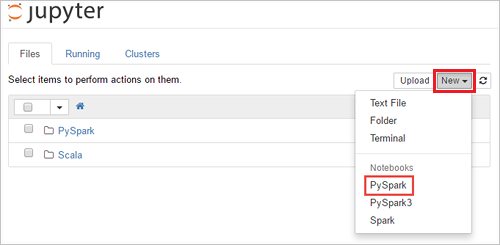
Az új notebook létrejött, és Untitled(Untitled.pynb) néven nyílt meg.
Apache Spark SQL-utasítások futtatása
Az SQL az adatok lekérdezésére és átalakítására leggyakrabban és legszélesebb körben használt nyelv. A Spark SQL az Apache Spark bővítményeként működik a strukturált adatok ismerős SQL-szintaxissal való feldolgozásához.
Ellenőrizze, hogy a kernel készen áll-e. A kernel akkor áll készen, ha a neve mellett a notebookban egy üres kör látható. A teli kör azt jelenti, hogy a kernel foglalt.
 alt-text="Kernel állapota." border="true":::
alt-text="Kernel állapota." border="true":::A notebook első indításakor a kernel a háttérben elvégez néhány feladatot. Várja meg, hogy a kernel elkészüljön.
Illessze be a következő kódot egy üres cellába, majd nyomja le a SHIFT + ENTER billentyűkombinációt annak futtatásához. A parancs felsorolja a fürtön található Hive-táblákat:
%%sql SHOW TABLESHa Jupyter Notebook-fájlt használ a HDInsight-fürttel, egy előre beállított
sparkmunkamenetet kap, amellyel Hive-lekérdezéseket futtathat a Spark SQL használatával. A%%sqlmegadja a Jupyter-notebook számára, hogy az előre beállítottspark-munkamenetet használja a Hive-lekérdezés futtatásához. A lekérdezés lekérdezi az első 10 sort egy Hive-táblából (hivesampletable), amely alapértelmezés szerint minden HDInsight-fürtben megtalálható. A lekérdezés első elküldésekor a Jupyter létrehoz egy Spark-alkalmazást a jegyzetfüzethez. Ez körülbelül 30 másodpercet vesz igénybe. Ha a Spark-alkalmazás készen áll, a lekérdezés körülbelül egy másodperc múlva lesz végrehajtva, és létrehozza az eredményeket. A kimenet a következőképpen fog kinézni: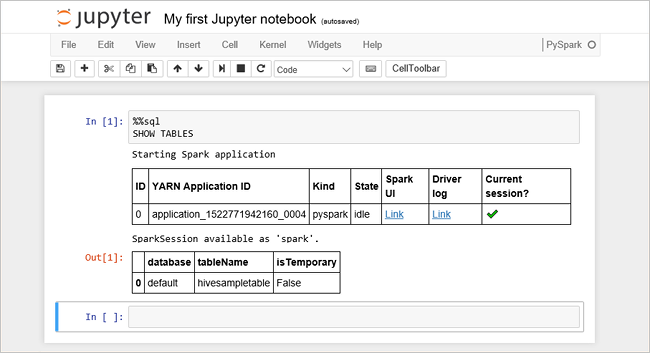 y in HDInsight" border="true":::
y in HDInsight" border="true":::Minden alkalommal, amikor a Jupyterben lekérdezést futtat, a webböngésző ablakának címsorában (Foglalt) állapot jelenik meg a notebook neve mellett. A jobb felső sarokban lévő PySpark felirat mellett ekkor egy teli kör is megjelenik.
Futtasson egy másik lekérdezést a
hivesampletableadatainak megtekintéséhez.%%sql SELECT * FROM hivesampletable LIMIT 10A képernyő frissül, és megjeleníti a lekérdezés kimenetét.
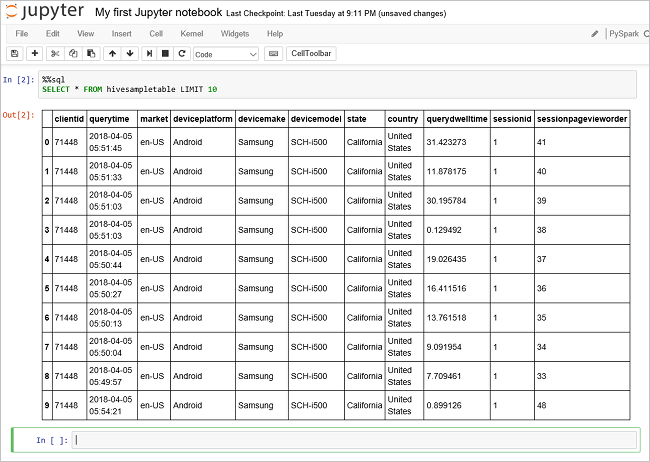 Insight" border="true":::
Insight" border="true":::A notebook File (Fájl) menüjében kattintson a Close and Halt (Bezárás és leállítás) elemre. A jegyzetfüzet leállítása felszabadítja a fürt erőforrásait, beleértve a Spark-alkalmazást is.
Az erőforrások eltávolítása
A rövid útmutató elvégzése után érdemes lehet törölni a fürtöt. A HDInsight használatával az adatok az Azure Storage-ban lesznek tárolva, így biztonságosan törölheti a fürtöt, ha nincs használatban. A HDInsight-fürtökért is díjat számítunk fel, még akkor is, ha nincs használatban. Mivel a fürt díjai sokszor nagyobbak, mint a tárolási díjak, érdemes törölni a fürtöket, ha nincsenek használatban.
Az Azure Portalon lépjen a fürtre, és válassza a Törlés lehetőséget.
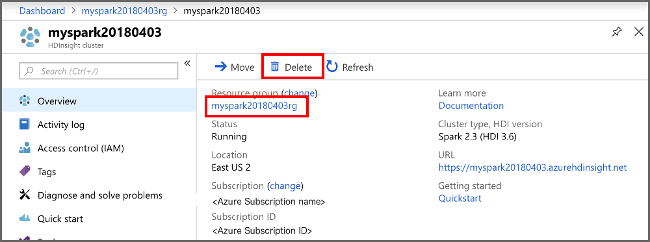 sight cluster" border="true":::
sight cluster" border="true":::
Az erőforráscsoport nevét kiválasztva is megnyílik az erőforráscsoport oldala, ahol kiválaszthatja az Erőforráscsoport törlése elemet. Az erőforráscsoport törlésével törli a HDInsight-fürtöt és az alapértelmezett tárfiókot is.
Következő lépések
Ebben a rövid útmutatóban megtanulta, hogyan hozhat létre Apache Spark-fürtöt a HDInsightban, és hogyan futtathat egy alapszintű Spark SQL-lekérdezést. Folytassa a következő oktatóanyagkal, amelyből megtudhatja, hogyan futtathat interaktív lekérdezéseket a mintaadatokon a HDInsight-fürtök használatával.