Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben a rövid útmutatóban az Azure Portal használatával hozhat létre Apache Spark-fürtöt az Azure HDInsightban. Ezután létre kell hoznia egy Jupyter-jegyzetfüzetet, és használatával Spark SQL-lekérdezéseket futtathat Apache Hive-táblákon. Az Azure HDInsight egy felügyelt, teljes spektrumú, nyílt forráskódú elemzési szolgáltatás nagyvállalatok számára. Az Apache Spark keretrendszer a HDInsight számára lehetővé teszi a gyors adatelemzést és fürtszámítási technikát memóriában történő feldolgozással. A Jupyter Notebook lehetővé teszi az adatokkal való interakciót, a kód markdown szöveggel való kombinálását és egyszerű vizualizációk használatát.
Az elérhető konfigurációk részletes ismertetését a Fürtök beállítása a HDInsightban című témakörben találja. A portál fürtök létrehozására való használatával kapcsolatos további információkért lásd : Fürtök létrehozása a portálon.
Ha több fürtöt használ együtt, érdemes lehet létrehozni egy virtuális hálózatot; Ha Spark-fürtöt használ, előfordulhat, hogy a Hive Warehouse-összekötőt is használni szeretné. További információ: Az Azure HDInsight virtuális hálózatának megtervezése, valamint az Apache Spark és az Apache Hive integrálása a Hive Warehouse-összekötővel.
Fontos
A HDInsight-fürtök díjszámítása percre történik, függetlenül attól, hogy használják-e őket, vagy sem. Ügyeljen arra, hogy törölje a klasztert, miután befejezte a használatát. További információkért lásd a cikk Az erőforrások eltávolítása című szakaszát.
Előfeltételek
Egy Azure-fiók, aktív előfizetéssel. Fiók létrehozása ingyenes.
Apache Spark-fürt létrehozása a HDInsightban
Az Azure Portal használatával olyan HDInsight-fürtöt hozhat létre, amely fürttárolóként az Azure Storage-blobokat használja. További információ a Data Lake Storage Gen2 használatáról: lásd a Rövid útmutatót a fürtök beállításáról a HDInsightban.
Jelentkezzen be a Azure portalra.
A felső menüsávból válassza az +Erőforrás létrehozása elemet.
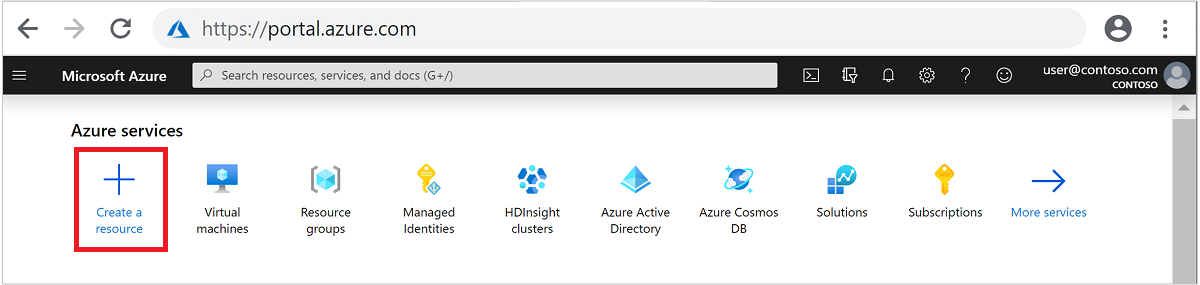
Válassza az Analytics>Azure HDInsight lehetőséget a HDInsight-fürt létrehozása lapra való ugráshoz.
Az Alapok lapon adja meg a következő információkat:
Ingatlan Leírás Előfizetés A legördülő listában válassza ki a klaszterhez használt Azure-előfizetést. Erőforráscsoport A legördülő listából válassza ki a meglévő erőforráscsoportot, vagy válassza az Új létrehozása lehetőséget. Klaszter neve Adjon meg egy globálisan egyedi nevet. Régió A legördülő listában válassza ki azt a régiót, ahol a klaszter létrejön. A rendelkezésre állási zóna Nem kötelező – adjon meg egy rendelkezésre állási zónát, amelyben üzembe kívánja helyezni a fürtöt Klasztertípus A lista megnyitásához válassza ki a fürttípust. A listából válassza a Sparkot. Fürt verziója Ez a mező automatikusan kitölti az alapértelmezett verziót a fürttípus kiválasztása után. Klaszter bejelentkezési felhasználónév Adja meg a klaszter bejelentkezési felhasználónevét. Az alapértelmezett név a rendszergazda. Ezzel a fiókkal jelentkezhet be a Jupyter Notebookba a rövid útmutató későbbi részében. Klaszter bejelentkezési jelszava Írja be a klaszter bejelentkezési jelszavát. Secure Shell- (SSH-) felhasználónév Adja meg az SSH-felhasználónevet. A rövid útmutatóhoz használt SSH-felhasználónév sshuser. Alapértelmezés szerint ez a fiók ugyanazt a jelszót használja, mint a Cluster bejelentkezési felhasználónév fiókja. 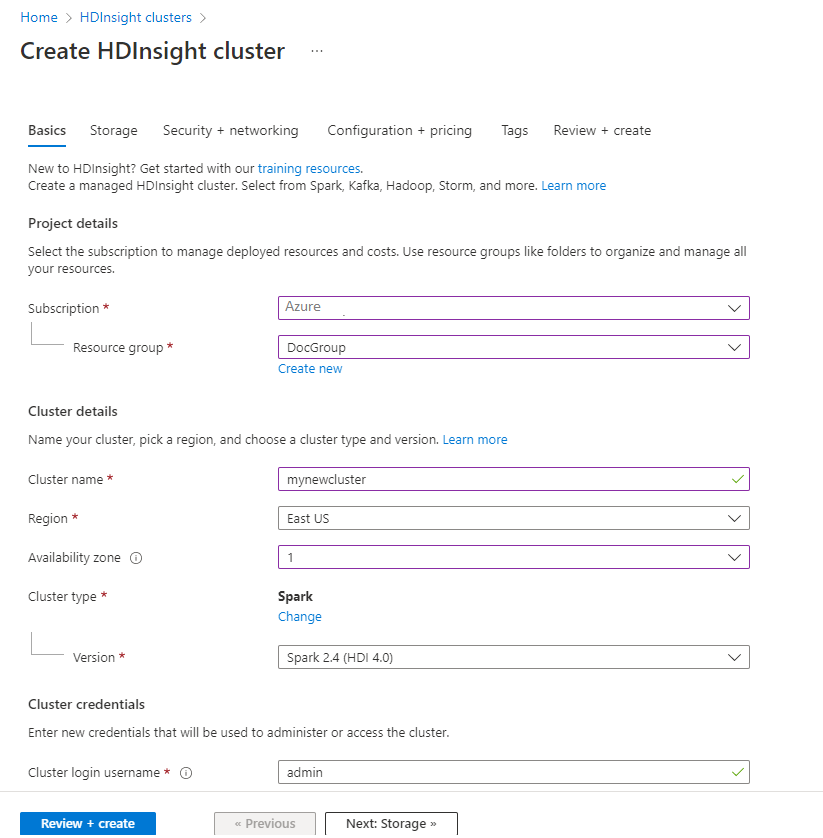
Válassza a Következő: Tárterület>> lehetőséget, a Tárterület lapra való továbblépéshez.
A Storage területen adja meg a következő értékeket:
Ingatlan Leírás Elsődleges tároló típusa Használja az alapértelmezett Azure Storage-értéket. Kiválasztási módszer Használja az alapértelmezett kiválasztási értéket a listából. Az elsődleges tárfiók Használja az automatikusan kitöltött értéket. Konténer Használja az automatikusan kitöltött értéket. 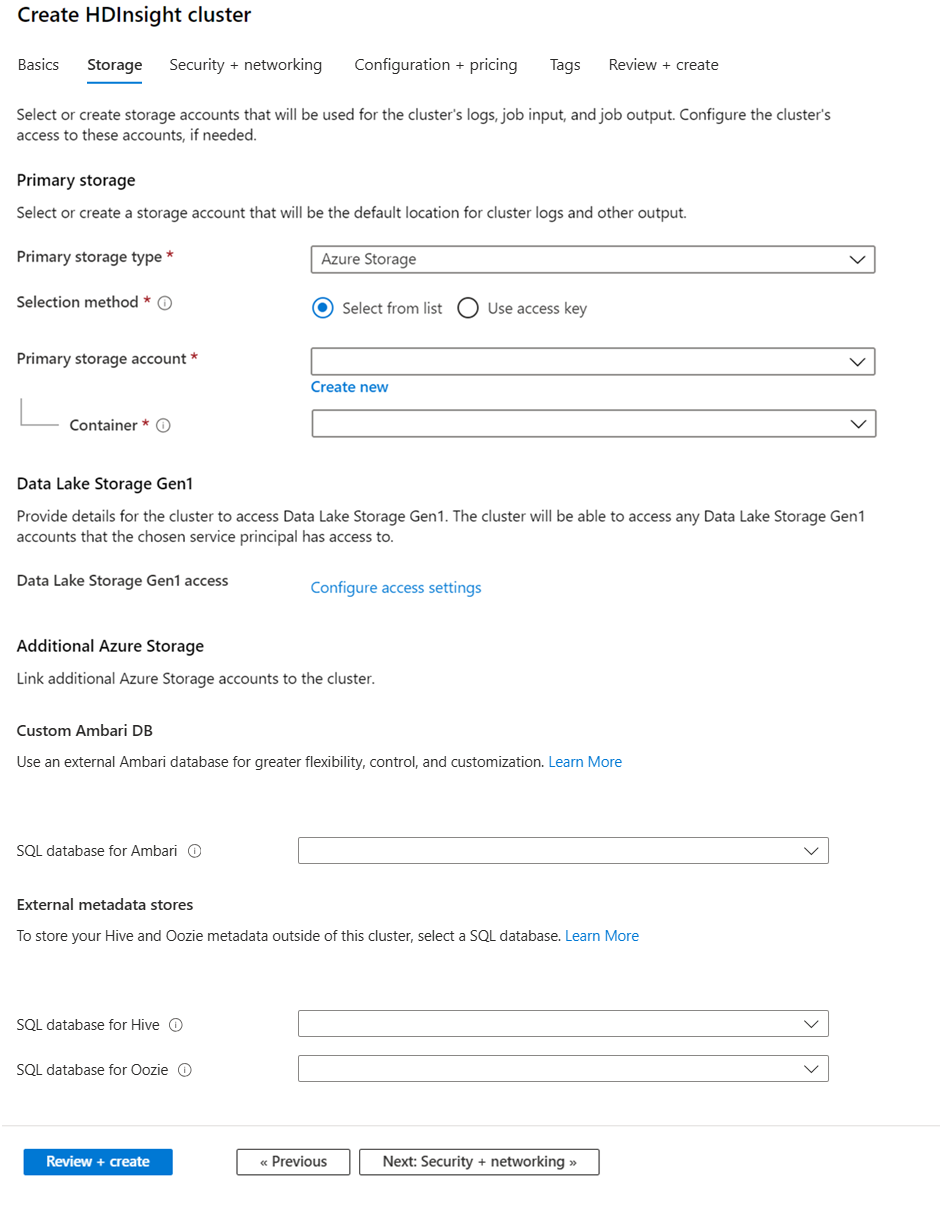
A folytatáshoz válassza a Véleményezés + létrehozás lehetőséget .
A Véleményezés + létrehozás csoportban válassza a Létrehozás lehetőséget. A fürt létrehozása nagyjából 20 percet vesz igénybe. A következő munkamenetre csak a fürt létrehozását követően lehet továbblépni.
Ha problémákba ütközik a HDInsight-fürtök létrehozásakor, lehet, hogy nem rendelkezik a megfelelő engedélyekkel. További információért tekintse meg a hozzáférés-vezérlésre vonatkozó követelményeket.
Jupyter-jegyzetfüzet létrehozása
A Jupyter Notebook egy interaktív notebook-környezet, amely számos programozási nyelvet támogat. A notebook lehetővé teszi az adatai használatát, a kódok és markdown-szövegek egyesítését, valamint egyszerű vizualizációk elvégzését.
Egy webböngészőben lépjen a(z)
https://CLUSTERNAME.azurehdinsight.net/jupytercímre, aholCLUSTERNAMEa fürt neve. Ha szükséges, adja meg a klaszter bejelentkezési hitelesítő adatait.Új notebook létrehozásához válassza a New>PySpark (Új > PySpark) lehetőséget.
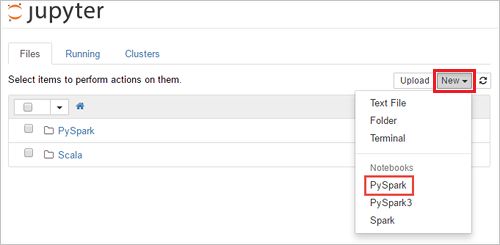
Az új notebook létrejött, és Untitled(Untitled.pynb) néven nyílt meg.
Apache Spark SQL-utasítások futtatása
Az SQL az adatok lekérdezéséhez és meghatározásához leggyakrabban és legszélesebb körben használt nyelv. A Spark SQL az Apache Spark bővítményeként működik a strukturált adatok ismerős SQL-szintaxissal való feldolgozásához.
Ellenőrizze, hogy a kernel készen áll-e. A kernel akkor áll készen, ha a neve mellett a notebookban egy üres kör látható. Az egyszínű kör azt jelzi, hogy a kernel foglalt.

A notebook első indításakor a kernel a háttérben elvégez néhány feladatot. Várja meg, hogy a kernel elkészüljön.
Illessze be a következő kódot egy üres cellába, majd nyomja le a SHIFT + ENTER billentyűkombinációt annak futtatásához. A parancs felsorolja a fürtön található Hive-táblákat:
%%sql SHOW TABLESHa Jupyter-jegyzetfüzetet használ a HDInsight-fürttel, kap egy előre beállított beállítást
sqlContext, amellyel Hive-lekérdezéseket futtathat a Spark SQL használatával. A%%sqlmegadja a Jupyter notebook számára, hogy az előre beállítottsqlContextelemet használja a Hive-lekérdezés futtatásához. A lekérdezés lekérdezi az első 10 sort egy Hive-táblából (hivesampletable), amely alapértelmezés szerint minden HDInsight-fürtben megtalálható. Az eredmények lekérdezése körülbelül 30 másodpercet vesz igénybe. A kimenet a következőképpen néz ki: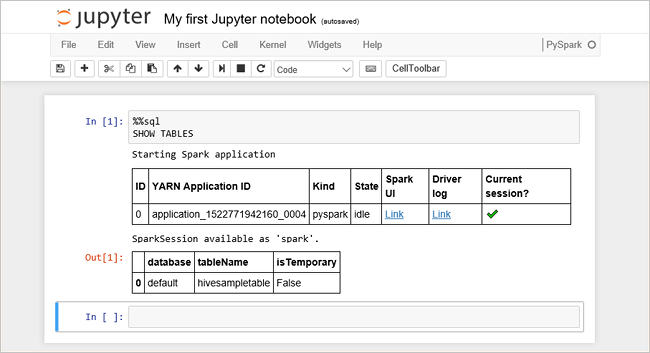 rövid útmutató." border="true":::
rövid útmutató." border="true":::Minden alkalommal, amikor a Jupyterben lekérdezést futtat, a webböngésző ablakának címsorában (Foglalt) állapot jelenik meg a notebook neve mellett. A jobb felső sarokban lévő PySpark szöveg mellett egy teli kör is látható.
Futtasson egy másik lekérdezést a
hivesampletableadatainak megtekintéséhez.%%sql SELECT * FROM hivesampletable LIMIT 10A képernyő frissül, és megjeleníti a lekérdezés kimenetét.
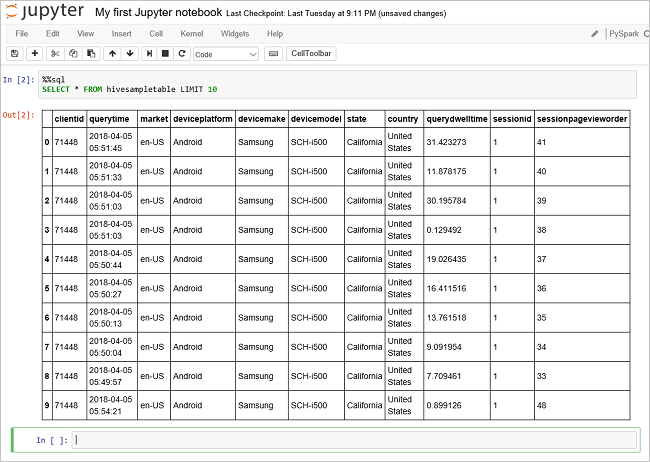 Insight" border="true":::
Insight" border="true":::A notebook File (Fájl) menüjében kattintson a Close and Halt (Bezárás és leállítás) elemre. A notebook leállítása felszabadítja a fürt erőforrásait.
Erőforrások tisztítása
A HDInsight az Azure Storage-ban vagy az Azure Data Lake Storage-ban menti az adatokat, így biztonságosan törölheti a fürtöket, ha nincsenek használatban. Még akkor is díjat számítunk fel a HDInsight-fürtökre, ha nincsenek használatban. Mivel a klaszterek díjai sokszorosan meghaladják a tárolási díjakat, gazdaságilag érdemes törölni a klasztereket, ha nincsenek használatban. Ha azonnal dolgozni szeretne a Következő lépések között felsorolt oktatóanyagon, érdemes lehet megtartania a csoportot.
Lépjen vissza az Azure Portalra és válassza a Törlés lehetőséget.
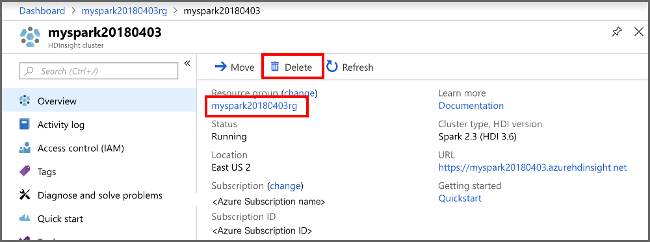 sight cluster" border="true":::
sight cluster" border="true":::
Az erőforráscsoport nevét kiválasztva is megnyílik az erőforráscsoport oldala, ahol kiválaszthatja az Erőforráscsoport törlése elemet. Az erőforráscsoport törlésével törli a HDInsight-fürtöt és az alapértelmezett tárfiókot is.
Következő lépések
Ebben a rövid útmutatóban megismerte, hogyan lehet Apache Spark-fürtöt létrehozni a HDInsightban, és hogyan lehet egy alapszintű Spark SQL-lekérdezést futtatni. Folytassa a következő oktatóanyaggal, hogy megtudja, hogyan használhat egy HDInsight-fürtöt interaktív lekérdezések futtatásához a mintaadatokon.