Gépi tanulási alkalmazás létrehozása és adathalmaz elemzése az Apache Spark MLlib használatával
Megtudhatja, hogyan hozhat létre gépi tanulási alkalmazást az Apache Spark MLlib használatával. Az alkalmazás prediktív elemzést végez egy nyitott adathalmazon. A Spark beépített gépi tanulási kódtáraiból ez a példa logisztikai regresszión keresztüli besorolást használ.
Az MLlib egy alapvető Spark-kódtár, amely számos hasznos segédprogramot biztosít a gépi tanulási feladatokhoz, például:
- Osztályozás
- Regresszió
- Fürtözés
- Modellezés
- Szingular value decomposition (SVD) és a fő összetevő elemzése (PCA)
- Hipotézistesztelés és mintastatisztikák kiszámítása
A besorolás és a logisztikai regresszió ismertetése
A népszerű gépi tanulási feladat, a besorolás a bemeneti adatok kategóriákba rendezésének folyamata. A besorolási algoritmus feladata, hogy kitalálja, hogyan rendelhet "címkéket" a megadott bemeneti adatokhoz. Gondolhat például egy gépi tanulási algoritmusra, amely bemenetként fogadja el a készletinformációkat. Ezután két kategóriába osztja az állományt: azokat a részvényeket, amelyeket el kell adni, és amelyeket meg kell tartania.
A logisztikai regresszió a besoroláshoz használt algoritmus. A Spark logisztikai regressziós API-ja bináris besoroláshoz vagy a bemeneti adatok két csoport egyikébe való besorolásához hasznos. A logisztikai regressziókról további információt a Wikipédiában talál.
Összefoglalva, a logisztikai regresszió folyamata logisztikai függvényt hoz létre. A függvény használatával előrejelezheti annak valószínűségét, hogy egy bemeneti vektor az egyik csoportba vagy a másikba tartozik.
Prediktív elemzési példa az élelmiszer-ellenőrzési adatokra
Ebben a példában a Spark használatával végez némi prediktív elemzést az élelmiszer-ellenőrzési adatokról (Food_Inspections1.csv). Chicago városának adatportálján keresztül beszerzett adatok. Ez az adatkészlet információkat tartalmaz a Chicagóban végzett élelmiszer-létesítmények vizsgálatairól. Beleértve az egyes létesítményekre vonatkozó információkat, a talált jogsértéseket (ha vannak ilyenek), valamint az ellenőrzés eredményeit. A CSV-adatfájl már elérhető a fürthöz társított tárfiókban: /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
A következő lépésekben egy modellt fejleszt, amelyből megtudhatja, hogy mi szükséges egy élelmiszer-ellenőrzés elvégzéséhez vagy sikertelenségéhez.
Apache Spark MLlib gépi tanulási alkalmazás létrehozása
Jupyter-jegyzetfüzet létrehozása a PySpark kernel használatával. Az utasításokért lásd : Jupyter Notebook-fájl létrehozása.
Importálja az alkalmazáshoz szükséges típusokat. Másolja és illessze be a következő kódot egy üres cellába, majd nyomja le a SHIFT + ENTER billentyűkombinációt.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *A PySpark kernel miatt nem kell explicit módon létrehoznia a környezeteket. A Spark- és Hive-környezetek automatikusan létrejönnek az első kódcella futtatásakor.
A bemeneti adatkeret létrehozása
A Spark-környezettel strukturálatlan szövegként lekérhetők a nyers CSV-adatok a memóriába. Ezután használja a Python CSV-kódtárát az adatok egyes sorainak elemzéséhez.
Futtassa az alábbi sorokat egy rugalmas elosztott adatkészlet (RDD) létrehozásához a bemeneti adatok importálásával és elemzésével.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Futtassa a következő kódot egy sor lekéréséhez az RDD-ből, hogy áttekinthesse az adatsémát:
inspections.take(1)A kimenet a következő:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]A kimenet a bemeneti fájl sémáját mutatja be. Tartalmazza az összes létesítmény nevét és a létesítmény típusát. Emellett többek között a címet, az ellenőrzések adatait és a helyszínt is.
Futtassa a következő kódot egy adatkeret (df) és egy ideiglenes tábla (CountResults) létrehozásához néhány olyan oszlopmal, amelyek hasznosak a prediktív elemzéshez.
sqlContextstrukturált adatokon végzett átalakítások végrehajtására szolgál.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Az adatkeret négy oszlopa az azonosító, a név, az eredmények és a szabálysértések.
Futtassa a következő kódot az adatok kis mintájának lekéréséhez:
df.show(5)A kimenet a következő:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Az adatok ismertetése
Kezdjük el megérteni, hogy mit tartalmaz az adathalmaz.
Futtassa a következő kódot a különböző értékek megjelenítéséhez az eredményoszlopban :
df.select('results').distinct().show()A kimenet a következő:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Futtassa a következő kódot az eredmények eloszlásának vizualizációjához:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsAz
%%sqlezt követő-o countResultsdfvarázslat biztosítja, hogy a lekérdezés kimenete helyileg megmarad a Jupyter-kiszolgálón (általában a fürt fejcsomópontján). A kimenet pandas-adatkeretként marad meg a megadott countResultsdf névvel. A PySpark kernelben elérhető varázslatokról%%sqlés egyéb varázslatokról további információt az Apache Spark HDInsight-fürtökkel rendelkező Jupyter Notebookokon elérhető kernelek című témakörben talál.A kimenet a következő:
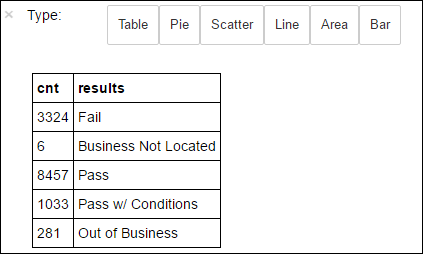
A Matplotlib, az adatok vizualizációjának létrehozásához használt kódtár is használható diagram létrehozásához. Mivel a diagramot a helyileg fenntartott countResultsdf adatkeretből kell létrehozni, a kódrészletnek a
%%localvarázslattal kell kezdődnie. Ez a művelet biztosítja, hogy a kód helyileg fusson a Jupyter-kiszolgálón.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Az élelmiszer-ellenőrzés eredményének előrejelzéséhez ki kell dolgoznia egy modellt a jogsértések alapján. Mivel a logisztikai regresszió bináris besorolási módszer, érdemes az eredményadatokat két kategóriába csoportosítani: Fail and Pass:
Sikeres
- Sikeres
- W/ feltételek átadása
Sikertelen
- Sikertelen
Elvetés
- A vállalkozás nem található
- Üzemen kívüli
A többi találatot tartalmazó adatok ("Business Not Located" vagy "Out of Business") nem hasznosak, és az eredmények kis százalékát teszik ki.
Futtassa a következő kódot a meglévő adatkeret(
dfek)nek egy új adatkeretté alakításához, ahol minden ellenőrzés címkesértési párként jelenik meg. Ebben az esetben a hiba címkéje0.0a sikert, a1.0címkét-1.0pedig a két eredmény mellett néhány találatot jelöl.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Futtassa a következő kódot a címkézett adatok egy sorának megjelenítéséhez:
labeledData.take(1)A kimenet a következő:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Logisztikai regressziós modell létrehozása a bemeneti adatkeretből
Az utolsó feladat a címkézett adatok konvertálása. Konvertálja az adatokat logisztikai regresszióval elemezett formátummá. A logisztikai regressziós algoritmus bemenetéhez címkefunkciós vektorpárokra van szükség. Ahol a "funkcióvektor" a bemeneti pontot képviselő számok vektora. Ezért át kell alakítania a "szabálysértések" oszlopot, amely félig strukturált, és sok megjegyzést tartalmaz szabadszövegben. Alakítsa át az oszlopot valós számokból álló tömbté, amelyet a gép könnyen megérthet.
A természetes nyelv feldolgozásának egyik szabványos gépi tanulási módszere, hogy minden egyes különálló szót indexként rendel hozzá. Ezután adjon át egy vektort a gépi tanulási algoritmusnak. Úgy, hogy az egyes indexek értéke tartalmazza a szó relatív gyakoriságát a szöveges sztringben.
Az MLlib egyszerű módot kínál a művelet végrehajtására. Először "tokenizálja" az egyes szabálysértési sztringeket, hogy lekérje az egyes sztringek egyes szavait. Ezután a HashingTF jogkivonatok mindegyikét átalakíthatja egy funkcióvektorsá, amelyet aztán átadhat a logisztikai regressziós algoritmusnak egy modell létrehozásához. Ezeket a lépéseket sorrendben hajthatja végre egy folyamat használatával.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
A modell kiértékelése egy másik adatkészlet használatával
A korábban létrehozott modell használatával előrejelezheti az új ellenőrzések eredményeit. Az előrejelzések a megfigyelt szabálysértéseken alapulnak. Ezt a modellt betanította az adathalmazra Food_Inspections1.csv. Egy második adatkészletet (Food_Inspections2.csv) is használhat a modell erősségének kiértékeléséhez az új adatokon. Ez a második adatkészlet (Food_Inspections2.csv) a fürthöz társított alapértelmezett tárolóban található.
Futtassa a következő kódot egy új adatkeret, a predictionsDf létrehozásához, amely a modell által létrehozott előrejelzést tartalmazza. A kódrészlet emellett létrehoz egy előrejelzés nevű ideiglenes táblát is az adatkeret alapján.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsA következő szöveghez hasonló kimenetnek kell megjelennie:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Nézze meg az egyik előrejelzést. Futtassa ezt a kódrészletet:
predictionsDf.take(1)A tesztadatkészlet első bejegyzésének előrejelzése.
A
model.transform()metódus ugyanazt az átalakítást alkalmazza az azonos sémával rendelkező új adatokra, és előrejelzést kap az adatok besorolásáról. Statisztikákat is készíthet, hogy képet kapjon az előrejelzésekről:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")A kimenet a következő szöveghez hasonlóan néz ki:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateA Logisztikai regresszió Sparkkal való használatával modellezheti a szabálysértések leírásai közötti kapcsolatot angol nyelven. És hogy egy adott vállalkozás átmegy-e egy élelmiszer-ellenőrzésen, vagy nem.
Az előrejelzés vizuális ábrázolásának létrehozása
Most már létrehozhat egy végleges vizualizációt, amely segít a teszt eredményeinek magyarázatában.
Először a korábban létrehozott Előrejelzések ideiglenes táblából nyeri ki a különböző előrejelzéseket és eredményeket. Az alábbi lekérdezések true_positive, false_positive, true_negative és false_negative választják el a kimenetet. Az alábbi lekérdezésekben kikapcsolhatja a vizualizációt
-qúgy, hogy a kimenetet (a használatával-o) adatkeretekként menti, amelyeket aztán használhat a%%localvarázslattal.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Végül a következő kódrészlettel hozza létre a diagramot a Matplotlib használatával.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')A következő kimenetnek kell megjelennie:
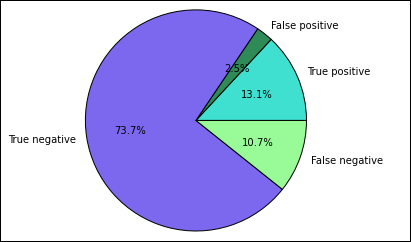
Ebben a diagramban a "pozitív" eredmény a sikertelen élelmiszer-ellenőrzésre, míg a negatív eredmény egy átment ellenőrzésre utal.
A jegyzetfüzet leállítása
Az alkalmazás futtatása után le kell állítania a jegyzetfüzetet az erőforrások felszabadításához. Ehhez a notebook File (Fájl) menüjében kattintson a Close and Halt (Bezárás és leállítás) elemre. Ez a művelet leállítja és bezárja a notebookot.
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: