Az Apache Spark beállításainak konfigurálása
A HDInsight Spark-fürt tartalmazza az Apache Spark-kódtár telepítését. Minden HDInsight-fürt tartalmazza az összes telepített szolgáltatás alapértelmezett konfigurációs paramétereit, beleértve a Sparkot is. A HDInsight Apache Hadoop-fürtök kezelésének egyik fő aspektusa a számítási feladatok figyelése, beleértve a Spark-feladatokat is. A Spark-feladatok legjobb futtatásához vegye figyelembe a fizikai fürt konfigurációját a fürt logikai konfigurációjának meghatározásakor.
Az alapértelmezett HDInsight Apache Spark-fürt a következő csomópontokat tartalmazza: három Apache ZooKeeper-csomópont, két fejcsomópont és egy vagy több feldolgozó csomópont:
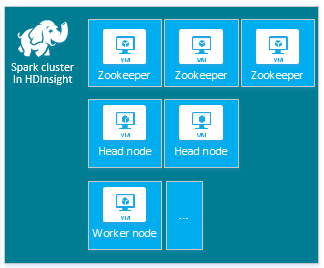
A HDInsight-fürt csomópontjaihoz tartozó virtuális gépek és virtuálisgép-méretek száma befolyásolhatja a Spark-konfigurációt. A nem alapértelmezett HDInsight-konfigurációs értékek gyakran nem alapértelmezett Spark-konfigurációs értékeket igényelnek. HDInsight Spark-fürt létrehozásakor az egyes összetevőkhöz javasolt virtuálisgép-méretek jelennek meg. Az Azure memóriaoptimalizált Linux rendszerű virtuálisgép-méretei jelenleg D12 v2 vagy nagyobbak.
Apache Spark-verziók
Használja a fürthöz legjobb Spark-verziót. A HDInsight szolgáltatás magában foglalja a Spark és a HDInsight több verzióját is. A Spark minden verziója tartalmazza az alapértelmezett fürtbeállításokat.
Új fürt létrehozásakor több Spark-verzió közül választhat. A teljes lista, a HDInsight-összetevők és -verziók megtekintéséhez.
Feljegyzés
A HDInsight szolgáltatásban az Apache Spark alapértelmezett verziója értesítés nélkül változhat. Ha verziófüggőséggel rendelkezik, a Microsoft azt javasolja, hogy ezt az adott verziót adja meg, amikor fürtöket hoz létre a .NET SDK, az Azure PowerShell és a klasszikus Azure CLI használatával.
Az Apache Spark három rendszerkonfigurációs helytel rendelkezik:
- A Spark-tulajdonságok a legtöbb alkalmazásparamétert szabályozzák, és objektummal
SparkConfvagy Java-rendszertulajdonságokkal állíthatók be. - A környezeti változókkal gépenkénti beállításokat állíthat be, például az IP-címet az
conf/spark-env.shegyes csomópontokon lévő szkripten keresztül. - A naplózás konfigurálható a
log4j.properties.
A Spark egy adott verziójának kiválasztásakor a fürt tartalmazza az alapértelmezett konfigurációs beállításokat. Az alapértelmezett Spark-konfigurációs értékeket egyéni Spark-konfigurációs fájllal módosíthatja. Erre mutat példát az alábbi ábra.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
A fenti példa öt Spark-konfigurációs paraméter több alapértelmezett értékét felülbírálja. Ezek az értékek a tömörítési kodek, az Apache Hadoop MapReduce minimális méretének felosztása és a parquet blokkméretek. Emellett a Spark SQL-partíció és a megnyitott fájlméretek alapértelmezett értékeket is tartalmaznak. Ezek a konfigurációmódosítások azért vannak kiválasztva, mert a társított adatok és feladatok (ebben a példában a genomikai adatok) különleges jellemzőkkel rendelkeznek. Ezek a jellemzők jobban kihasználják ezeket az egyéni konfigurációs beállításokat.
Fürtkonfigurációs beállítások megtekintése
Ellenőrizze az aktuális HDInsight-fürtkonfigurációs beállításokat, mielőtt teljesítményoptimalizálást végez a fürtön. Indítsa el a HDInsight-irányítópultot az Azure Portalról a Spark-fürtpanel Irányítópult hivatkozására kattintva. Jelentkezzen be a fürt rendszergazdájának felhasználónevével és jelszavával.
Megjelenik az Apache Ambari webes felhasználói felülete, amelyen a fürt fő erőforrás-használati metrikáinak irányítópultja látható. Az Ambari irányítópulton megtekintheti az Apache Spark konfigurációját és más telepített szolgáltatásokat. Az irányítópult tartalmaz egy Konfigurációs előzmények lapot, ahol megtekintheti a telepített szolgáltatások, köztük a Spark adatait.
Az Apache Spark konfigurációs értékeinek megtekintéséhez válassza a Konfigurációs előzmények lehetőséget, majd a Spark2 lehetőséget. Válassza a Konfigurációk lapot, majd a szolgáltatáslistában válassza a Spark (vagy Spark2a verziótól függően) hivatkozást. Megjelenik a fürt konfigurációs értékeinek listája:
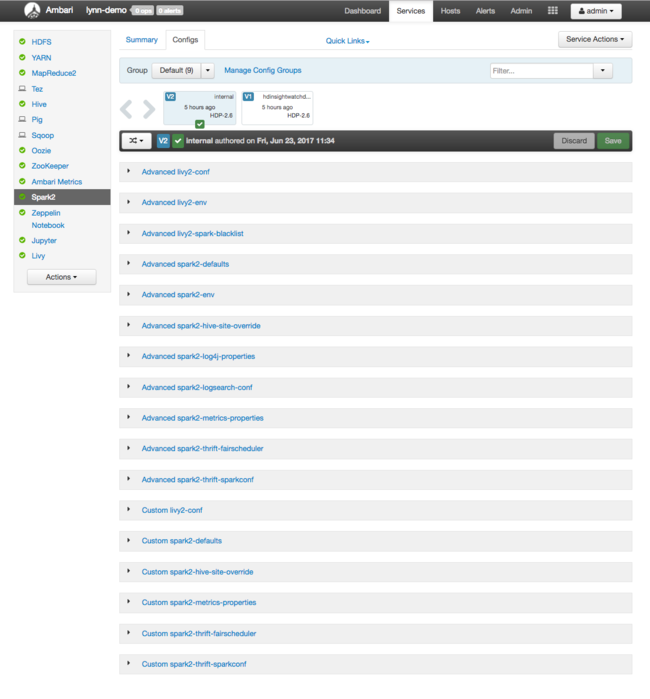
Az egyes Spark-konfigurációs értékek megtekintéséhez és módosításához válassza ki a címben található "spark" hivatkozásokat. A Spark-konfigurációk az egyéni és a speciális konfigurációs értékeket is tartalmazzák az alábbi kategóriákban:
- Egyéni Spark2-alapértelmezett értékek
- Egyéni Spark2-metrics-properties
- Speciális Spark2-alapértelmezések
- Speciális Spark2-env
- Speciális spark2-hive-site-felülbírálás
Ha nem alapértelmezett konfigurációs értékeket hoz létre, a frissítési előzmények láthatók. Ez a konfigurációs előzmény hasznos lehet annak megtekintéséhez, hogy melyik nem alapértelmezett konfiguráció rendelkezik optimális teljesítménnyel.
Feljegyzés
A Spark-fürt általános konfigurációs beállításainak megtekintéséhez, de nem módosításához válassza a Környezet lapot a legfelső szintű Spark-feladat felhasználói felületén .
Spark-végrehajtók konfigurálása
Az alábbi ábra a legfontosabb Spark-objektumokat mutatja be: az illesztőprogram-programot és annak társított Spark-környezetét, valamint a fürtkezelőt és annak n feldolgozó csomópontjait. Minden munkavégző csomópont tartalmaz egy végrehajtót, egy gyorsítótárat és egy n feladatpéldányt.
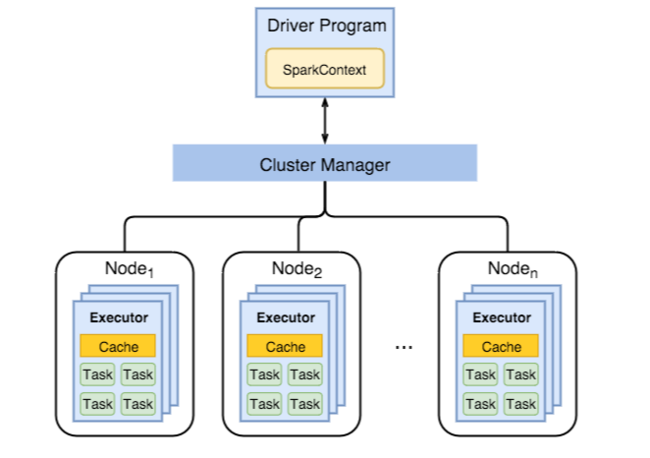
A Spark-feladatok feldolgozói erőforrásokat, különösen memóriát használnak, ezért gyakori a Spark konfigurációs értékeinek módosítása a feldolgozó csomópont végrehajtóihoz.
Az alkalmazáskövetelmények javítása érdekében a Spark-konfigurációk finomhangolásához gyakran igazított három fő paraméter a spark.executor.instancesspark.executor.coreskövetkezők: és spark.executor.memory. A végrehajtó egy Spark-alkalmazáshoz indított folyamat. A végrehajtó a feldolgozó csomóponton fut, és felelős az alkalmazás feladataiért. A feldolgozó csomópontok száma és a feldolgozó csomópont mérete határozza meg a végrehajtók és a végrehajtók méretét. Ezek az értékek a fürtfőcsomópontokon vannak tárolva spark-defaults.conf . Ezeket az értékeket egy futó fürtben szerkesztheti az Ambari webes felhasználói felületén az egyéni spark-defaultok kiválasztásával. A módosítások végrehajtása után a felhasználói felület az összes érintett szolgáltatás újraindítását kéri.
Feljegyzés
Ez a három konfigurációs paraméter a fürt szintjén konfigurálható (a fürtön futó összes alkalmazáshoz), és az egyes alkalmazásokhoz is megadhatók.
A Spark-végrehajtók által használt erőforrásokról egy másik információforrás a Spark-alkalmazás felhasználói felülete. A felhasználói felületen a végrehajtók megjelenítik a konfiguráció és a felhasznált erőforrások összegzési és részletes nézeteit. Határozza meg, hogy a teljes fürt végrehajtói értékeit vagy adott feladatvégrehajtások készletét módosítja-e.
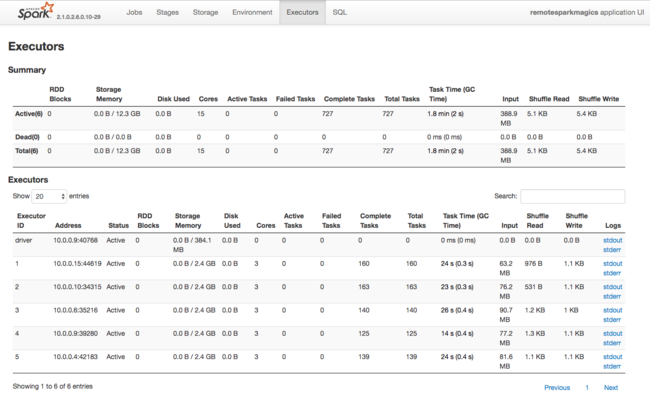
Vagy az Ambari REST API-val programozott módon ellenőrizheti a HDInsight és a Spark-fürt konfigurációs beállításait. További információ az Apache Ambari API-referenciában érhető el a GitHubon.
A Spark számítási feladattól függően előfordulhat, hogy egy nem alapértelmezett Spark-konfiguráció optimálisabb Spark feladat-végrehajtásokat biztosít. A nem alapértelmezett fürtkonfigurációk ellenőrzéséhez végezze el a referenciatesztelést mintafeladatokkal. Néhány gyakori paraméter, amelyeket érdemes lehet módosítani:
| Paraméter | Leírás |
|---|---|
| --szám-végrehajtók | Beállítja a végrehajtók számát. |
| --executor-cores | Beállítja az egyes végrehajtók magjainak számát. Javasoljuk, hogy közepes méretű végrehajtókat használjunk, mivel más folyamatok a rendelkezésre álló memória egy részét is felhasználják. |
| --executor-memory | Szabályozza az Apache Hadoop YARN egyes végrehajtóinak memóriaméretét (halomméretét), és némi memóriát kell hagynia a végrehajtási többletterheléshez. |
Íme egy példa két különböző konfigurációs értékkel rendelkező feldolgozó csomópontra:

Az alábbi listában a Spark-végrehajtó kulcsfontosságú memóriaparaméterei láthatók.
| Paraméter | Leírás |
|---|---|
| spark.executor.memory | Meghatározza a végrehajtó számára rendelkezésre álló memória teljes mennyiségét. |
| spark.storage.memoryFraction | (az alapértelmezett ~60%) a tárolt RDD-k tárolásához rendelkezésre álló memória mennyiségét határozza meg. |
| spark.shuffle.memoryFraction | (alapértelmezés szerint ~20%) az elegyítendő memória mennyiségét határozza meg. |
| spark.storage.unrollFraction és spark.storage.safetyFraction | (a teljes memória ~30%-a) – ezeket az értékeket a Spark belsőleg használja, és nem szabad módosítani. |
A YARN az egyes Spark-csomópontokon lévő tárolók által felhasznált memória maximális összegét szabályozza. Az alábbi ábra a YARN-konfigurációs objektumok és a Spark-objektumok csomópontonkénti kapcsolatait mutatja be.
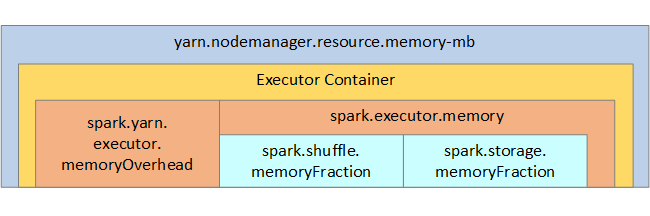
A Jupyter Notebookban futó alkalmazások paramétereinek módosítása
A HDInsight Spark-fürtöi alapértelmezés szerint számos összetevőt tartalmaznak. Ezen összetevők mindegyike alapértelmezett konfigurációs értékeket tartalmaz, amelyeket szükség szerint felül lehet bírálni.
| Összetevő | Leírás |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark streaming API-k, GraphX és Apache Spark MLlib. |
| Anaconda | Egy Python-csomagkezelő. |
| Apache Livy | Az Apache Spark REST API, amellyel távoli feladatokat küldhet egy HDInsight Spark-fürtnek. |
| Jupyter Notebooks és Apache Zeppelin Notebooks | Interaktív böngészőalapú felhasználói felület a Spark-fürttel való interakcióhoz. |
| ODBC-illesztő | A HDInsight Spark-fürtöit olyan üzletiintelligencia-eszközökhöz csatlakoztatja, mint a Microsoft Power BI vagy a Tableau. |
A Jupyter Notebookban futó alkalmazások esetében a parancs használatával végezze el a %%configure konfigurációs módosításokat a jegyzetfüzeten belülről. Ezek a konfigurációmódosítások a jegyzetfüzetpéldányból futtatott Spark-feladatokra lesznek alkalmazva. Végezze el ezeket a módosításokat az alkalmazás elején, mielőtt az első kódcellát futtatja. A rendszer a módosított konfigurációt alkalmazza a Livy-munkamenetre a létrehozáskor.
Feljegyzés
Ha az alkalmazás egy későbbi szakaszában szeretné módosítani a konfigurációt, használja a -f (force) paramétert. Az alkalmazás minden előrehaladása azonban elveszik.
Az alábbi kód bemutatja, hogyan módosíthatja a Jupyter Notebookban futó alkalmazások konfigurációját.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Összegzés
Az alapvető konfigurációs beállítások monitorozása, hogy a Spark-feladatok kiszámítható és teljesíthető módon fussanak. Ezek a beállítások segítenek meghatározni az adott számítási feladatokhoz legmegfelelőbb Spark-fürtkonfigurációt. Emellett figyelnie kell a hosszú ideig futó és erőforrás-igényes Spark-feladatok végrehajtását is. A leggyakoribb kihívások a helytelen konfigurációk, például a helytelen méretű végrehajtók memóriaterhelése köré összpontosulnak. Emellett a hosszú ideig futó műveletek és feladatok, amelyek Cartesian-műveleteket eredményeznek.