Apache Spark-fürt erőforrásainak kezelése az Azure HDInsightban
Megtudhatja, hogyan férhet hozzá az Apache Ambari felhasználói felületéhez, az Apache Hadoop YARN felhasználói felületéhez és az Apache Spark-fürthöz társított Spark History Serverhez, és hogyan hangolhatja a fürtkonfigurációt az optimális teljesítmény érdekében.
A Spark-előzmények kiszolgálójának megnyitása
A Spark-előzmények kiszolgálója a kész és futó Spark-alkalmazások webes felhasználói felülete. Ez a Spark webes felhasználói felületének kiterjesztése. További információ: Spark History Server.
A Yarn felhasználói felületének megnyitása
A YARN felhasználói felületén figyelheti a Spark-fürtön jelenleg futó alkalmazásokat.
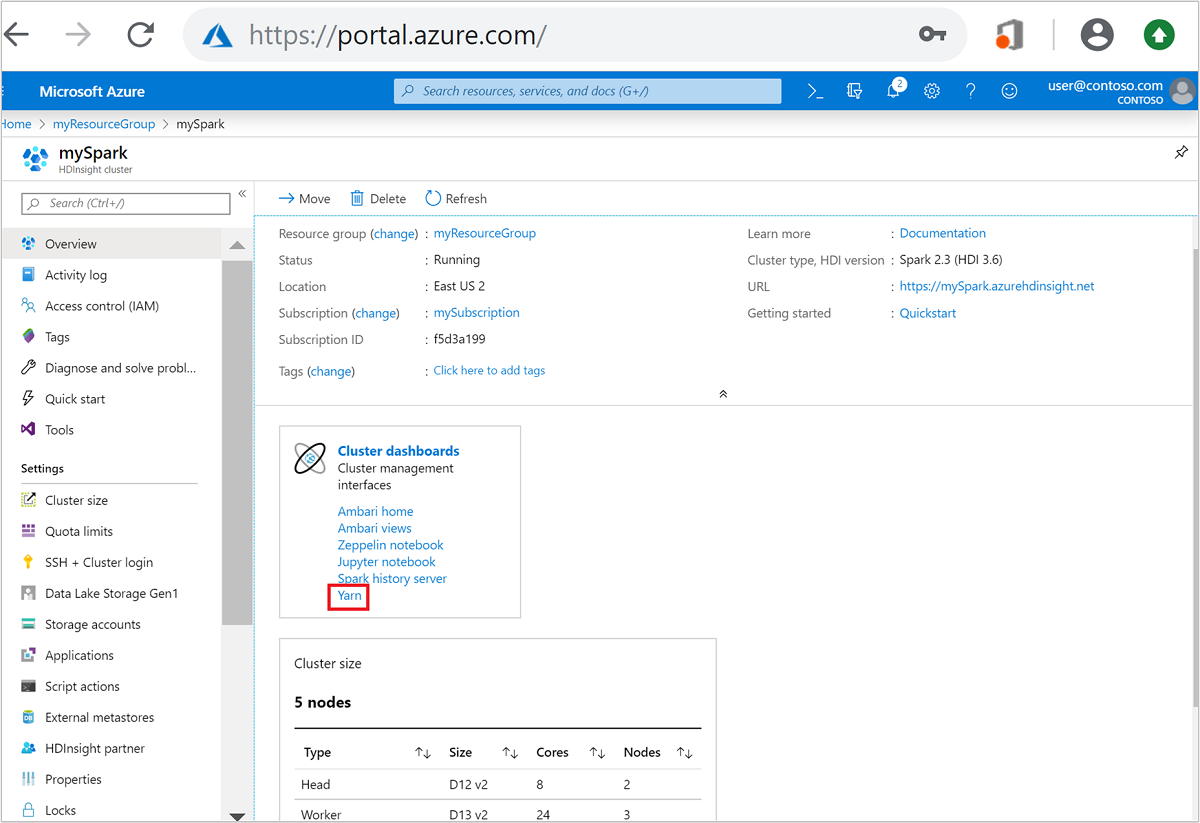
Nyissa meg a Spark-fürtöt az Azure Portalon. További információ: Fürtök listázása és megjelenítése.
A Fürt irányítópultjai között válassza a Yarn lehetőséget. Amikor a rendszer kéri, adja meg a Spark-fürt rendszergazdai hitelesítő adatait.
Tipp.
Azt is megteheti, hogy elindítja a YARN felhasználói felületet az Ambari felhasználói felületén. Az Ambari felhasználói felületén lépjen a YARN>Gyorshivatkozások>aktív>erőforrás-kezelő felhasználói felületére.
Fürtök optimalizálása Spark-alkalmazásokhoz
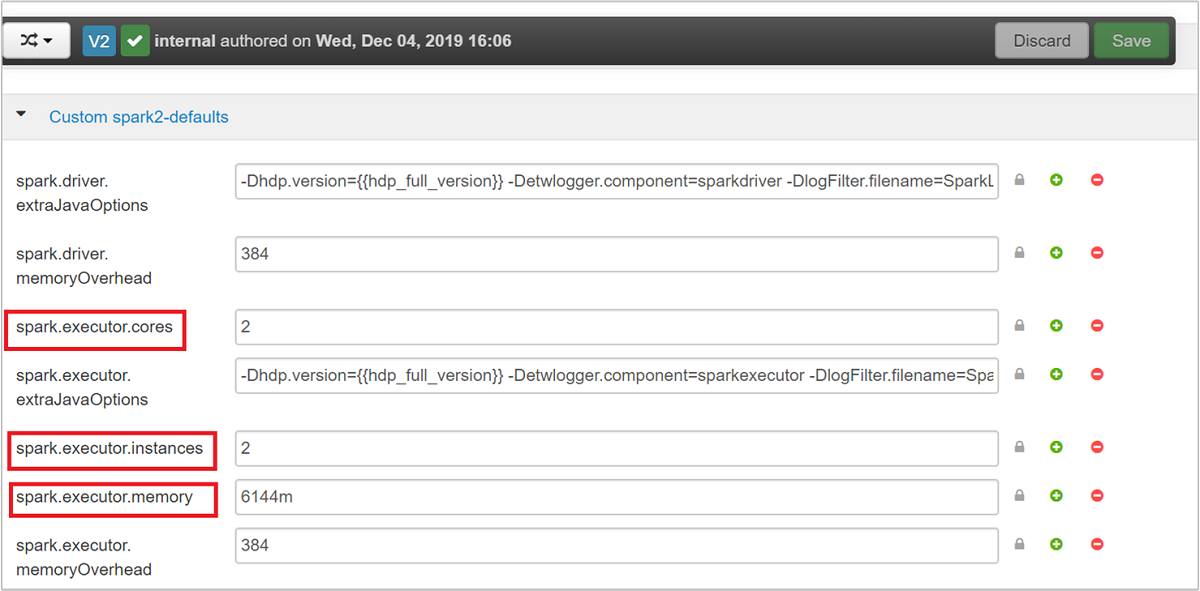
A Spark-konfigurációhoz az alkalmazáskövetelményektől függően használható három fő paraméter a következőkspark.executor.instancesspark.executor.cores: és spark.executor.memory. A végrehajtó egy Spark-alkalmazáshoz indított folyamat. A munkavégző csomóponton fut, és az alkalmazás feladatainak végrehajtásáért felelős. Az egyes fürtök alapértelmezett végrehajtói és végrehajtói méretei a feldolgozó csomópontok száma és a feldolgozó csomópont mérete alapján lesznek kiszámítva. Ezeket az információkat a fürtfejcsomópontok tárolják spark-defaults.conf .
A három konfigurációs paraméter a fürt szintjén konfigurálható (a fürtön futó összes alkalmazáshoz), vagy minden egyes alkalmazáshoz is megadható.
Paraméterek módosítása az Ambari felhasználói felületén
Az Ambari felhasználói felületén lépjen a Spark 2>Configs>Custom spark2 alapértelmezett beállításaihoz.
Az alapértelmezett értékek jóak, ha négy Spark-alkalmazás fut egyszerre a fürtön. Ezeket az értékeket a felhasználói felületről módosíthatja az alábbi képernyőképen látható módon:
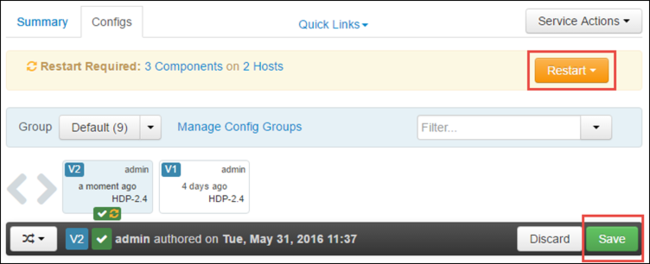
A konfiguráció módosításainak mentéséhez válassza a Mentés lehetőséget. A lap tetején a rendszer az összes érintett szolgáltatás újraindítását kéri. Válassza az Újraindítás lehetőséget.
A Jupyter Notebookban futó alkalmazások paramétereinek módosítása
A Jupyter Notebookban futó alkalmazások esetében a %%configure varázslat segítségével módosíthatja a konfigurációt. Ideális esetben az alkalmazás elején, az első kódcella futtatása előtt végre kell hajtania ezeket a módosításokat. Ezzel biztosítja, hogy a konfiguráció a Livy-munkamenetre legyen alkalmazva a létrehozáskor. Ha az alkalmazás egy későbbi szakaszában szeretné módosítani a konfigurációt, a paramétert -f kell használnia. Ezzel azonban az alkalmazás összes előrehaladása elveszik.
Az alábbi kódrészlet bemutatja, hogyan módosíthatja a Jupyterben futó alkalmazások konfigurációját.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
A konfigurációs paramétereket JSON-sztringként kell átadni, és a varázslat után a következő sorban kell lenniük, ahogyan az a példaoszlopban látható.
A spark-submit használatával elküldött alkalmazás paramétereinek módosítása
Az alábbi parancs egy példa arra, hogyan módosíthatja a konfigurációs paramétereket egy olyan kötegelt alkalmazáshoz, amelyet a rendszer a következő paranccsal spark-submitküld el.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
A cURL használatával elküldött alkalmazás paramétereinek módosítása
Az alábbi parancs egy példa a cURL használatával elküldött batch-alkalmazások konfigurációs paramétereinek módosítására.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Feljegyzés
Másolja a JAR-fájlt a fürt tárfiókjába. Ne másolja a JAR-fájlt közvetlenül a főcsomópontra.
Ezen paraméterek módosítása Spark Thrift-kiszolgálón
A Spark Thrift Server JDBC-/ODBC-hozzáférést biztosít egy Spark-fürthöz, és Spark SQL-lekérdezések kiszolgálására szolgál. Az olyan eszközök, mint a Power BI, a Tableau és így tovább, ODBC protokoll használatával kommunikálhatnak a Spark Thrift Serverrel Spark SQL-lekérdezések Spark-alkalmazásként való végrehajtásához. Spark-fürt létrehozásakor a Spark Thrift-kiszolgáló két példánya indul el, egy-egy a fejcsomóponton. Minden Spark Thrift-kiszolgáló Spark-alkalmazásként látható a YARN felhasználói felületén.
A Spark Thrift Server a Spark dinamikus végrehajtói lefoglalását használja, ezért a rendszer nem használja.spark.executor.instances Ehelyett a Spark Thrift Server a végrehajtók számát használja spark.dynamicAllocation.maxExecutors és spark.dynamicAllocation.minExecutors határozza meg. A konfigurációs spark.executor.coresparaméterek, és spark.executor.memory a végrehajtó méretének módosítására szolgálnak. Ezeket a paramétereket az alábbi lépésekben látható módon módosíthatja:
Bontsa ki az Advanced spark2-thrift-sparkconf kategóriát a paraméterek
spark.dynamicAllocation.maxExecutorsfrissítéséhez, ésspark.dynamicAllocation.minExecutors.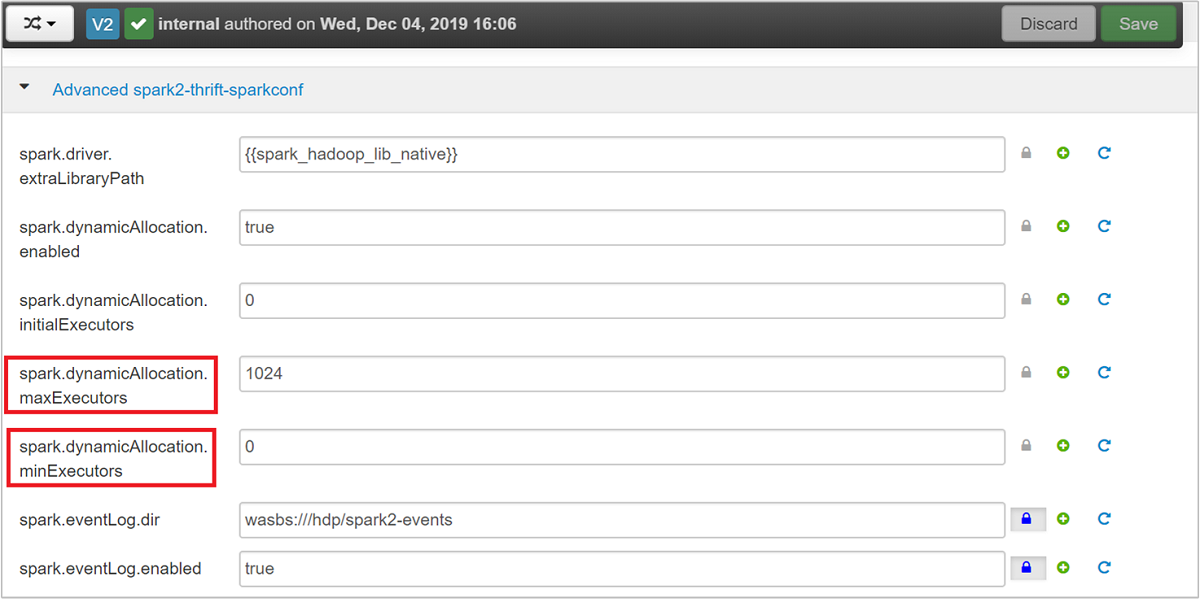
Bontsa ki az Egyéni spark2-thrift-sparkconf kategóriát a paraméterek
spark.executor.coresfrissítéséhez, ésspark.executor.memory.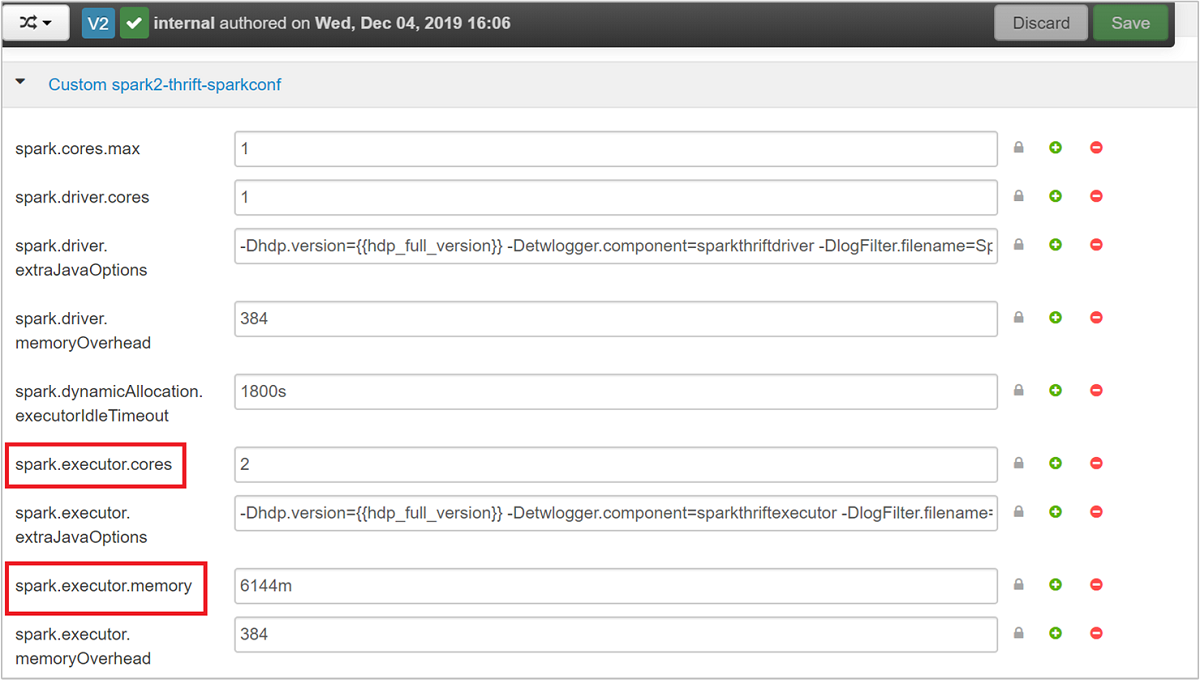
A Spark Thrift-kiszolgáló illesztőprogram-memóriájának módosítása
A Spark Thrift Server-illesztőprogram memóriája a fejcsomópont RAM-méretének 25%-ára van konfigurálva, feltéve, hogy a fejcsomópont ram-mérete nagyobb, mint 14 GB. Az Ambari felhasználói felületén módosíthatja az illesztőprogram memóriakonfigurációját az alábbi képernyőképen látható módon:
Az Ambari felhasználói felületén lépjen a Spark2>Configs>Advanced spark2-env lapra. Ezután adja meg a spark_thrift_cmd_opts értékét.
Spark-fürt erőforrásainak visszaigénylése
A Spark dinamikus lefoglalása miatt a takarékos kiszolgáló csak a két alkalmazásminta erőforrásait használja fel. Az erőforrások visszaigényléséhez le kell állítania a fürtön futó Thrift Server-szolgáltatásokat.
Az Ambari felhasználói felületén, a bal oldali panelen válassza a Spark2 lehetőséget.
A következő lapon válassza a Spark 2 Thrift Servers lehetőséget.
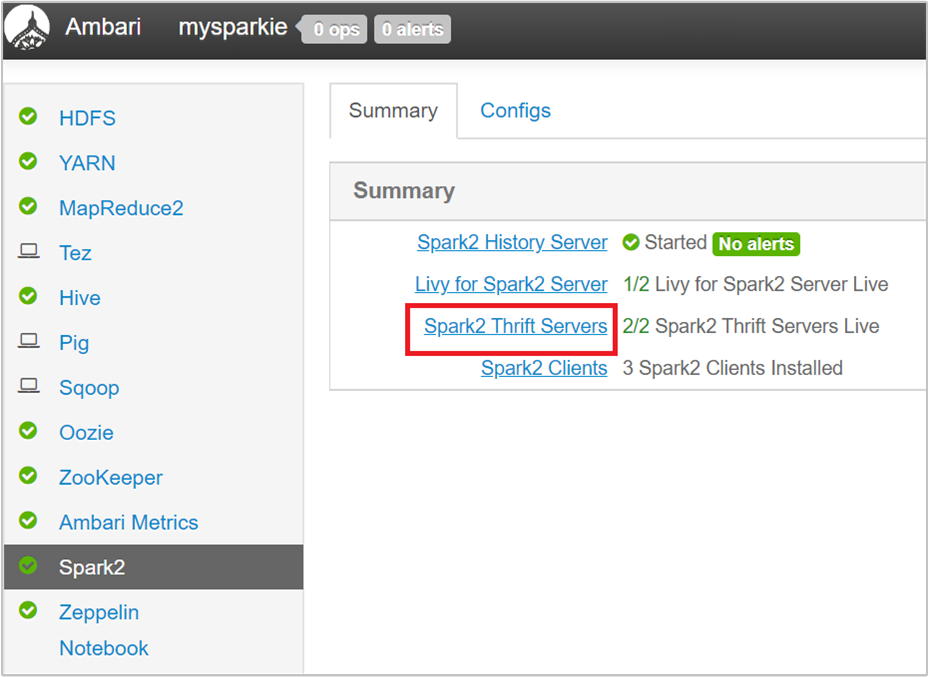
Látnia kell azt a két fejcsomópontot, amelyen a Spark 2 Thrift-kiszolgáló fut. Válassza ki az egyik átjárócsomópontot.
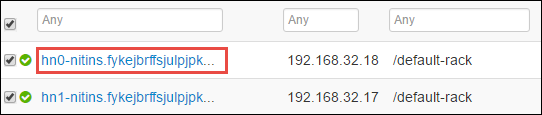
A következő oldalon az adott átjárócsomóponton futó összes szolgáltatás látható. A listából válassza a Spark 2 Thrift Server melletti legördülő gombot, majd válassza a Leállítás lehetőséget.
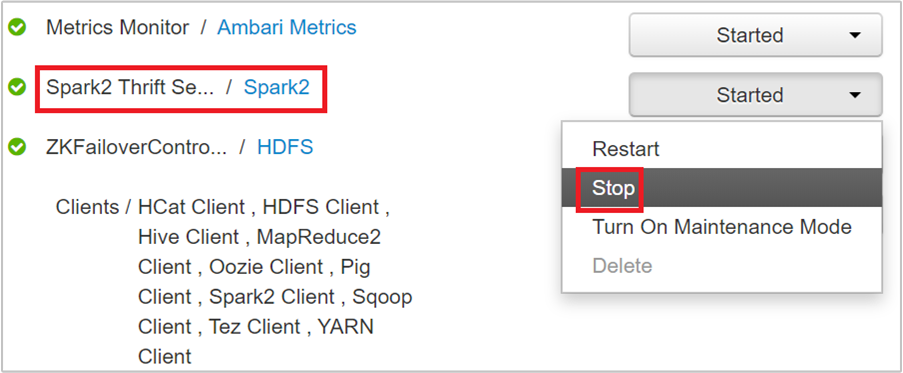
Ismételje meg ezeket a lépéseket a másik fejcsomóponton is.
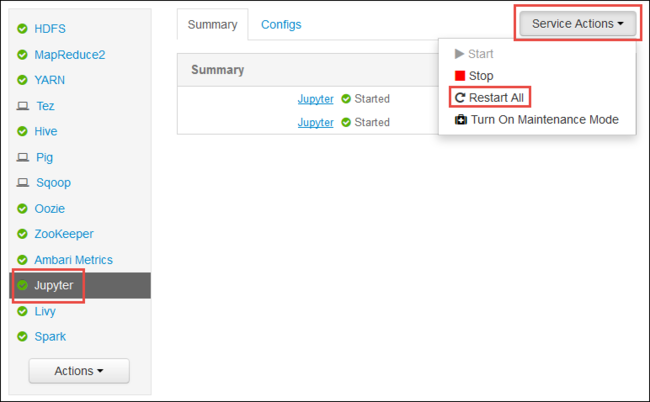
Indítsa újra a Jupyter szolgáltatást
Indítsa el az Ambari webes felhasználói felületet a cikk elején látható módon. A bal oldali navigációs panelen válassza a Jupyter, a Service Actions, majd az Összes újraindítása lehetőséget. Ezzel elindítja a Jupyter szolgáltatást az összes átjárócsomóponton.
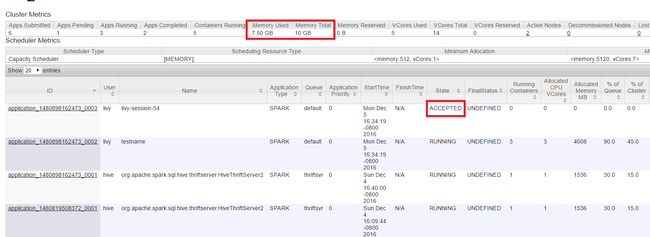
Erőforrások figyelése
Indítsa el a Yarn felhasználói felületet a cikk elején látható módon. A képernyő tetején található Fürtmetrikák táblában ellenőrizze a felhasznált memória és a memóriaösszeg oszlop értékeit. Ha a két érték közel van, előfordulhat, hogy nincs elegendő erőforrás a következő alkalmazás elindításához. Ugyanez vonatkozik a használt virtuális magokra és a virtuális magok teljes oszlopára is. Emellett a fő nézetben, ha egy alkalmazás elfogadott állapotban maradt, és nem vált át a FUTTATÁS vagy a SIKERTELEN állapotra, ez azt is jelezheti, hogy nem kap elegendő erőforrást az indításhoz.
Futó alkalmazások leálltatva
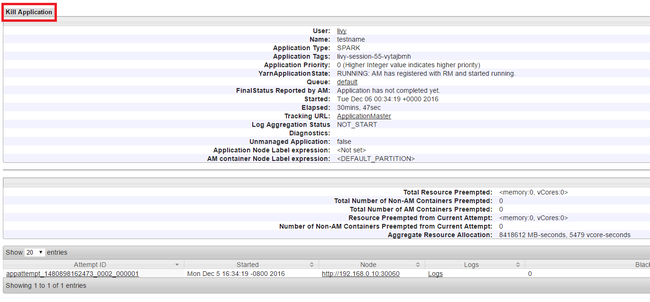
A Yarn felhasználói felületén, a bal oldali panelen válassza a Futtatás lehetőséget. A futó alkalmazások listájában határozza meg a leölni kívánt alkalmazást, és válassza ki az azonosítót.
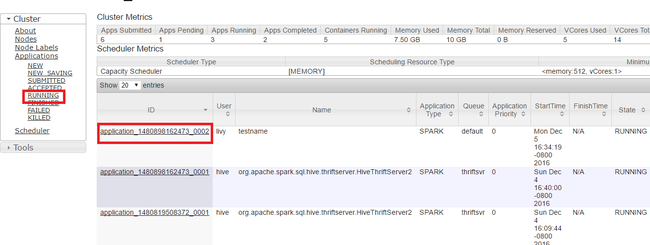
A jobb felső sarokban válassza az Alkalmazás leállása lehetőséget, majd kattintson az OK gombra.
Lásd még
Adatelemzőknek
- Apache Spark és Machine Learning: A Spark használata a HDInsightban az épülethőmérséklet HVAC-adatokkal történő elemzéséhez
- Apache Spark és Machine Learning: A Spark használata a HDInsightban az élelmiszer-ellenőrzési eredmények előrejelzéséhez
- Webhelynapló-elemzés az Apache Spark használatával a HDInsightban
- Az Application Insights telemetriai adatelemzése az Apache Spark használatával a HDInsightban
Apache Spark-fejlesztőknek
- Önálló alkalmazás létrehozása a Scala használatával
- Feladatok távoli futtatása Apache Spark-fürtön az Apache Livy használatával
- Az IntelliJ IDEA HDInsight-eszközei beépülő moduljának használata Spark Scala-alkalmazások létrehozásához és elküldéséhez
- Az Apache Spark-alkalmazások távoli hibakereséséhez használja a HDInsight Tools beépülő modult az IntelliJ IDEA-hoz
- Apache Zeppelin-jegyzetfüzetek használata Apache Spark-fürttel a HDInsighton
- A HDInsighthoz készült Apache Spark-fürtben elérhető Jupyter Notebook-kernelek
- Külső csomagok használata Jupyter Notebookokkal
- A Jupyter telepítése a számítógépre, majd csatlakozás egy HDInsight Spark-fürthöz