Apache Zeppelin-notebookok használata Apache Spark-fürtökön az Azure HDInsight rendszerében
A HDInsight Spark-fürtök apache Zeppelin-jegyzetfüzeteket tartalmaznak. Apache Spark-feladatok futtatásához használja a jegyzetfüzeteket. Ebből a cikkből megtudhatja, hogyan használhatja a Zeppelin-jegyzetfüzetet EGY HDInsight-fürtön.
Előfeltételek
- Apache Spark-fürt megléte a HDInsightban. További útmutatásért lásd: Apache Spark-fürt létrehozása az Azure HDInsightban.
- A fürtök elsődleges tárolójának URI-sémája. A séma az Azure Blob Storage,
abfs://az Azure Data Lake Storage Gen2 vagyadl://az Azure Data Lake Storage Gen1 esetében lennewasb://. Ha a Blob Storage biztonságos átvitele engedélyezve van, az URI leszwasbs://. További információ: Biztonságos átvitel megkövetelése az Azure Storage-ban .
Apache Zeppelin-jegyzetfüzet indítása
A Spark-fürt áttekintésében válassza a Zeppelin-jegyzetfüzetet a fürt irányítópultjai közül. Adja meg a fürt rendszergazdai hitelesítő adatait.
Feljegyzés
A fürt Zeppelin-jegyzetfüzetét is elérheti az alábbi URL-cím böngészőben való megnyitásával. Cserélje le a CLUSTERNAME elemet a fürt nevére:
https://CLUSTERNAME.azurehdinsight.net/zeppelinHozzon létre új notebookot. Az élőfej panelen lépjen az Új jegyzet létrehozása jegyzetfüzetbe>.
Adja meg a jegyzetfüzet nevét, majd válassza a Jegyzet létrehozása lehetőséget.
Győződjön meg arról, hogy a jegyzetfüzet fejléce csatlakoztatott állapotot jelenít meg. A jobb felső sarokban egy zöld pont jelöli.
Töltse be a mintaadatokat egy ideiglenes táblába. Amikor létrehoz egy Spark-fürtöt a HDInsightban, a rendszer a mintaadatfájlt
hvac.csvátmásolja a társított tárfiókba\HdiSamples\SensorSampleData\hvac.Az új jegyzetfüzetben alapértelmezés szerint létrehozott üres bekezdésbe illessze be a következő kódrészletet.
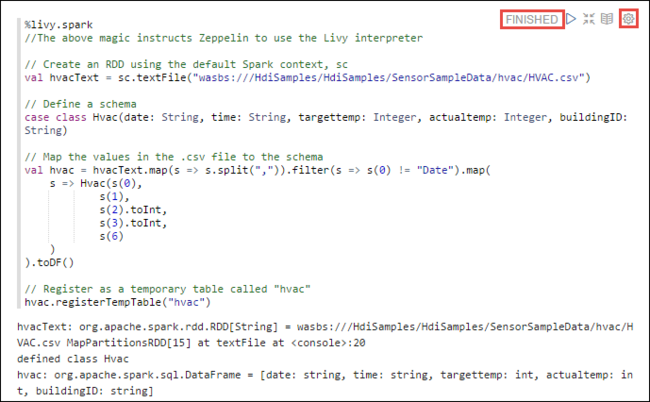
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Nyomja le a SHIFT +ENTER billentyűkombinációt , vagy válassza a bekezdés Lejátszás gombját a kódrészlet futtatásához. A bekezdés jobb sarkában lévő állapotnak a KÉSZ, a FÜGGŐBEN, a FUTTATÁStól a KÉSZ állapotig kell haladnia. A kimenet ugyanazon bekezdés alján jelenik meg. A képernyőkép a következő képhez hasonlóan néz ki:
Az egyes bekezdések címmel is elláthatók. A bekezdés jobb sarkában válassza a Gépház ikont (sprocket), majd válassza a Cím megjelenítése lehetőséget.
Feljegyzés
A (z) %spark2 értelmező nem támogatott a Zeppelin-jegyzetfüzetekben az összes HDInsight-verzióban, és a (z) %sh értelmező a HDInsight 4.0-tól kezdve nem támogatott.
Mostantól Spark SQL-utasításokat is futtathat a
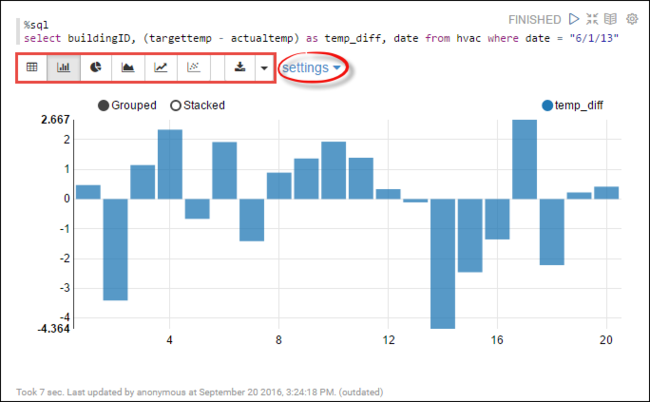
hvactáblában. Illessze be a következő lekérdezést egy új bekezdésbe. A lekérdezés lekéri az épületazonosítót. A cél és a tényleges hőmérséklet közötti különbség is az egyes épületeknél egy adott napon. Nyomja le a SHIFT+ENTER billentyűkombinációt.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Az elején található %sql utasítás tájékoztatja a jegyzetfüzetet a Livy Scala-értelmező használatáról.
A megjelenítés módosításához válassza a Sávdiagram ikont. a beállítások a sávdiagram kiválasztása után jelennek meg, és lehetővé teszi a Kulcsok és értékek lehetőséget. Az alábbi képernyőképen a kimenet látható.
Spark SQL-utasításokat is futtathat változók használatával a lekérdezésben. A következő kódrészlet bemutatja,
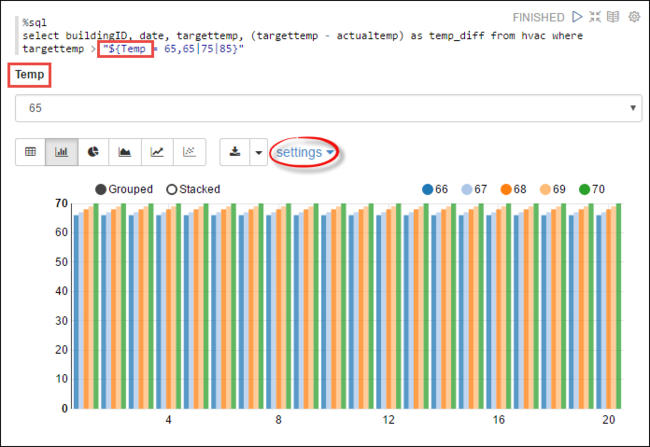
Temphogyan definiálhat egy változót a lekérdezésben a lekérdezni kívánt lehetséges értékekkel. A lekérdezés első futtatásakor a rendszer automatikusan kitölti a legördülő menüt a változóhoz megadott értékekkel.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Illessze be ezt a kódrészletet egy új bekezdésbe, és nyomja le a SHIFT + ENTER billentyűkombinációt. Ezután válassza a 65-öt a Temp legördülő listából.
A megjelenítés módosításához válassza a Sávdiagram ikont. Ezután válassza ki a beállításokat , és végezze el a következő módosításokat:
Csoportok: Céltemp hozzáadása.
Értékek: 1. Dátum eltávolítása. 2. Temp_diff hozzáadása. 3. Módosítsa az összesítőt SZUM-ról AVG-re.
Az alábbi képernyőképen a kimenet látható.
Hogyan külső csomagokat használ a jegyzetfüzettel?
A HDInsighton futó Apache Spark-fürt Zeppelin-jegyzetfüzete olyan külső, közösség által közzétett csomagokat is használhat, amelyek nem szerepelnek a fürtben. Keresse meg a Maven-adattárban az elérhető csomagok teljes listáját. Az elérhető csomagok listáját más forrásokból is lekérheti. A Közösség által létrehozott csomagok teljes listája például elérhető a Spark Packagesben.
Ebből a cikkből megtudhatja, hogyan használhatja a spark-csv csomagot a Jupyter Notebookkal.
Nyissa meg a értelmező beállításait. A jobb felső sarokban válassza ki a bejelentkezett felhasználónevet, majd válassza az Értelmező lehetőséget.
Görgessen a livy2 lapra, majd válassza a szerkesztés lehetőséget.
Lépjen a kulcsra
livy.spark.jars.packages, és állítsa be az értékét a formátumbagroup:id:version. Ha tehát a spark-csv csomagot szeretné használni, a kulcs értékét a következőrecom.databricks:spark-csv_2.10:1.4.0kell állítania: .
Kattintson a Mentés , majd az OK gombra a Livy-értelmező újraindításához.
Ha meg szeretné érteni, hogyan érkezhet meg a fent megadott kulcs értéke, az alábbiak szerint.
a. Keresse meg a csomagot a Maven-adattárban. Ebben a cikkben spark-csv-t használtunk.
b. Az adattárból gyűjtse össze a GroupId, az ArtifactId és a Version értékeit.
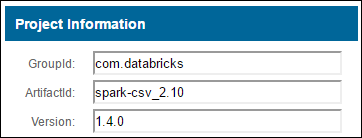
c. Fűzd össze a három értéket kettősponttal (:) elválasztva.
com.databricks:spark-csv_2.10:1.4.0
Hol vannak mentve a Zeppelin-jegyzetfüzetek?
A Zeppelin-jegyzetfüzeteket a rendszer a fürt fejcsomópontjaiba menti. Így ha törli a fürtöt, a jegyzetfüzetek is törlődnek. Ha meg szeretné őrizni a jegyzetfüzeteket más fürtökön való későbbi használatra, a feladatok futtatása után exportálnia kell őket. Jegyzetfüzet exportálásához válassza az Exportálás ikont az alábbi képen látható módon.
Ez a művelet JSON-fájlként menti a jegyzetfüzetet a letöltési helyre.
Feljegyzés
A HDI 4.0-ban a zeppelin notebook könyvtár elérési útja:
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Például /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Ahol a HDI 5.0-s és újabb verziója eltérő
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Például /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
A tárolt fájlnév eltér a HDI 5.0-s verzióban. A rendszer a következőképpen tárolja:
<notebook_name>_<sessionid>.zplnPéldául testzeppelin_2JJK53XQA.zpln
A HDI 4.0-ban a fájlnév csak note.json session_id könyvtárban van tárolva.
Például /2JMC9BZ8X/note.json
A HDI Zeppelin mindig a hn0 helyi lemez elérési útján
/usr/hdp/<version>/zeppelin/notebook/menti a jegyzetfüzetet.Ha azt szeretné, hogy a jegyzetfüzet a fürt törlése után is elérhető legyen, próbálja meg használni az Azure File Storage-t (SMB protokoll használatával), és csatolja a helyi elérési úthoz. További részletekért lásd : SMB Azure-fájlmegosztás csatlakoztatása Linuxon
A csatlakoztatás után módosíthatja a zeppelin konfigurációs zeppelin.notebook.dir fájlt az ambari felhasználói felületén lévő csatlakoztatott útvonalra.
- A Zeppelin 0.10.1-es verziójához nem ajánlott gitNotebookRepo-tárolóként használni az SMB-fájlokat
A Shiro Zeppelin-értelmezők hozzáférésének konfigurálása az Enterprise Security Package (ESP) fürtökben
Ahogy fentebb említettük, az %sh értelmező a HDInsight 4.0-tól kezdve nem támogatott. Továbbá, mivel %sh az értelmező potenciális biztonsági problémákat, például a rendszerhéjparancsokat használó hozzáférési kulcstartókat vezet be, a HDInsight 3.6 ESP-fürtökről is eltávolították. Ez azt jelenti, hogy %sh az Értelmező nem érhető el az Új jegyzet létrehozása vagy az Értelmező felhasználói felületén alapértelmezés szerint.
A kiemelt tartomány felhasználói a Shiro.ini fájl használatával szabályozhatják az értelmező felhasználói felülethez való hozzáférést. Csak ezek a felhasználók hozhatnak létre új %sh értelmezőket, és állíthatnak be engedélyeket minden egyes új %sh értelmezőre. A fájllal shiro.ini való hozzáférés szabályozásához kövesse az alábbi lépéseket:
Definiáljon egy új szerepkört egy meglévő tartománycsoportnév használatával. Az alábbi példában
adminGroupNameaz AAD kiemelt felhasználóinak egy csoportja látható. Ne használjon speciális karaktereket vagy fehér szóközöket a csoport nevében. A szerepkör engedélyeinek megadása után=megjelenő karakterek.*azt jelenti, hogy a csoport teljes engedélyekkel rendelkezik.[roles] adminGroupName = *Adja hozzá az új szerepkört a Zeppelin-értelmezőkhöz való hozzáféréshez. Az alábbi példában
adminGroupNameminden felhasználó hozzáfér a Zeppelin-értelmezőkhöz, és új értelmezőket hozhat létre. Több szerepkört is elhelyezhet a zárójelekroles[]között vesszővel elválasztva. Ezután a szükséges engedélyekkel rendelkező felhasználók hozzáférhetnek a Zeppelin-értelmezőkhöz.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Példa shiro.ini több tartománycsoportra:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy-munkamenetek kezelése
A Zeppelin-jegyzetfüzet első kód bekezdése létrehoz egy új Livy-munkamenetet a fürtben. Ezt a munkamenetet a rendszer megosztja a később létrehozott Összes Zeppelin-jegyzetfüzetben. Ha a Livy-munkamenet bármilyen okból le lesz ölve, a feladatok nem futnak a Zeppelin-jegyzetfüzetből.
Ilyen esetben a következő lépéseket kell végrehajtania, mielőtt elkezdené futtatni a feladatokat egy Zeppelin-jegyzetfüzetből.
Indítsa újra a Livy-értelmezőt a Zeppelin-jegyzetfüzetből. Ehhez nyissa meg az értelmező beállításait a jobb felső sarokban található bejelentkezett felhasználónév kiválasztásával, majd válassza az Értelmező lehetőséget.
Görgessen a livy2-hez, majd válassza az újraindítást.
Futtasson egy kódcellát egy meglévő Zeppelin-jegyzetfüzetből. Ez a kód létrehoz egy új Livy-munkamenetet a HDInsight-fürtben.
Általános információk
Szolgáltatás érvényesítése
A szolgáltatás Ambariból való érvényesítéséhez lépjen arra https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary a helyre, ahol a FÜRTNÉV a fürt neve.
A szolgáltatás parancssorból történő ellenőrzéséhez az SSH-t a fő csomópontra kell ellenőrizni. Felhasználó váltása zeppelinre a parancs sudo su zeppelinhasználatával. Állapotparancsok:
| Parancs | Leírás |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Szolgáltatás állapota. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Szolgáltatásverzió. |
ps -aux | grep zeppelin |
Azonosítsa a PID-t. |
Naplóhelyek
| Szolgáltatás | Elérési út |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Kiszolgálói naplók | /var/log/zeppelin |
Konfigurációs értelmező, Shirosite.xml, log4j |
/usr/hdp/current/zeppelin-server/conf vagy /etc/zeppelin/conf |
| PID-címtár | /var/run/zeppelin |
Hibakeresési naplózás engedélyezése
Lépjen arra a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summaryhelyre, ahol a FÜRTNÉV a fürt neve.Lépjen a CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Módosítás a
log4j.appender.dailyfile.Threshold = INFOgombralog4j.appender.dailyfile.Threshold = DEBUGHozzáadás
log4j.logger.org.apache.zeppelin.realm=DEBUG.Mentse a módosításokat, és indítsa újra a szolgáltatást.