Az Apache Spark hibaelhárítása az Azure HDInsighttal
Megismerheti az Apache Spark hasznos adatainak Apache Ambariban való használatakor felmerülő leggyakoribb problémákat és azok megoldásait.
Hogyan konfigurálható egy Apache Spark-alkalmazás az Apache Ambari fürtökön történő használatával?
A Spark konfigurációs értékei hangolhatók, így elkerülhetők az Apache Spark-alkalmazáskivételek OutofMemoryError . Az alábbi lépések az Alapértelmezett Spark-konfigurációs értékeket mutatják be az Azure HDInsightban:
Jelentkezzen be az Ambariba
https://CLUSTERNAME.azurehdidnsight.neta fürt hitelesítő adataival. A kezdeti képernyőn megjelenik egy áttekintő irányítópult. A HDInsight 4.0 között enyhe kozmetikai különbségek vannak.Lépjen a Spark2>konfigurációihoz.

A konfigurációk listájában válassza ki és bontsa ki a Custom-spark2 alapértelmezett beállításait.
Keresse meg a módosítani kívánt értékbeállítást, például a spark.executor.memory értéket. Ebben az esetben a 9728m értéke túl magas.

Állítsa be az értéket a javasolt beállításra. Ehhez a beállításhoz a 2048m érték ajánlott.
Mentse az értéket, majd mentse a konfigurációt. Válassza a Mentés lehetőséget.

Jegyezze fel a konfiguráció változásait, majd válassza a Mentés lehetőséget.
Értesítést kap, ha a konfigurációk figyelmet igényelnek. Jegyezze fel az elemeket, majd válassza a Folytatás elemet.

Amikor egy konfigurációt ment, a rendszer kérni fogja a szolgáltatás újraindítását. Válassza az Újraindítás lehetőséget.

Ellenőrizze az újraindítást.

Áttekintheti a futó folyamatokat.
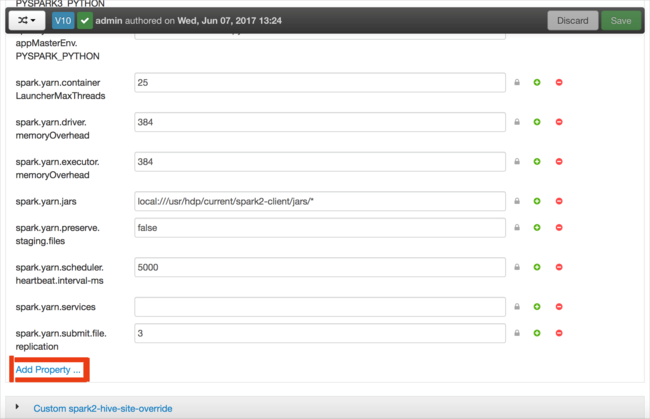
Konfigurációkat adhat hozzá. A konfigurációk listájában válassza a Custom-spark2 alapértelmezett beállításait, majd válassza a Tulajdonság hozzáadása lehetőséget.
Adjon meg egy új tulajdonságot. Egyetlen tulajdonságot definiálhat egy párbeszédpanel használatával bizonyos beállításokhoz, például az adattípushoz. Vagy több tulajdonságot is meghatározhat egy definíció használatával soronként.
Ebben a példában a spark.driver.memory tulajdonság 4g értékkel van definiálva.

Mentse a konfigurációt, majd indítsa újra a szolgáltatást a 6. és a 7. lépésben leírtak szerint.
Ezek a módosítások fürtszintűek, de felülbíráltak lehetnek a Spark-feladat elküldésekor.
Hogyan Konfiguráljon egy Apache Spark-alkalmazást egy Jupyter Notebook használatával fürtökön?
A Jupyter Notebook első cellájában a %%konfigurálási irányelv után adja meg a Spark-konfigurációkat érvényes JSON formátumban. Szükség szerint módosítsa a tényleges értékeket:

Hogyan konfigurálható egy Apache Spark-alkalmazás az Apache Livy fürtökön történő használatával?
Küldje el a Spark-alkalmazást Livynek egy REST-ügyféllel, például a cURL-sel. Az alábbiakhoz hasonló parancsot használjon. Szükség szerint módosítsa a tényleges értékeket:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Hogyan konfigurálható egy Apache Spark-alkalmazás a spark-submit fürtökön történő használatával?
Indítsa el a Spark-Shellt az alábbihoz hasonló paranccsal. Szükség szerint módosítsa a konfigurációk tényleges értékét:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
További olvasás
Apache Spark-feladat beküldése HDInsight-fürtökön
Következő lépések
Ha nem látja a problémát, vagy nem tudja megoldani a problémát, további támogatásért látogasson el az alábbi csatornák egyikére:
Azure-szakértőktől kaphat választ az Azure közösségi támogatásán keresztül.
Csatlakozzon a @AzureSupport - a hivatalos Microsoft Azure-fiókhoz az ügyfélélmény javításához. Az Azure-közösség csatlakoztatása a megfelelő erőforrásokhoz: válaszok, támogatás és szakértők.
Ha további segítségre van szüksége, támogatási kérelmet küldhet az Azure Portalról. Válassza a Támogatás lehetőséget a menüsávon, vagy nyissa meg a Súgó + támogatási központot. Részletesebb információkért tekintse át a Azure-támogatás kérések létrehozását ismertető cikket. Az előfizetés-kezeléssel és számlázással kapcsolatos támogatás a Microsoft Azure-előfizetés részét képezi, míg a technikai támogatást Azure-támogatási csomagjainkkal biztosítjuk.