Adatösszetevő normalizálása
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti.
Ezzel az összetevővel normalizálással alakíthat át egy adathalmazt.
A normalizálás olyan technika, amelyet gyakran alkalmaznak a gépi tanulásra való adat-előkészítés részeként. A normalizálás célja, hogy az adathalmaz numerikus oszlopainak értékeit úgy módosítsa, hogy közös skálát használjon, anélkül, hogy torzítaná az értéktartományok közötti különbségeket vagy adatvesztést. Bizonyos algoritmusok esetében normalizálásra is szükség van az adatok helyes modellezéséhez.
Tegyük fel például, hogy a bemeneti adatkészlet egy oszlopot tartalmaz 0 és 1 közötti értékekkel, egy másik oszlopot pedig 10 000 és 100 000 közötti értékekkel. A számok skálájának nagy különbsége problémákat okozhat, ha az értékeket funkciókként próbálja kombinálni a modellezés során.
A normalizálás elkerüli ezeket a problémákat azáltal, hogy új értékeket hoz létre, amelyek megőrzik a forrásadatok általános eloszlását és arányait, miközben a modellben használt összes numerikus oszlopra alkalmazott skálán belül tartják az értékeket.
Ez az összetevő számos lehetőséget kínál a numerikus adatok átalakítására:
- Az összes értéket módosíthatja 0-1 skálára, vagy átalakíthatja az értékeket úgy, hogy az abszolút értékek helyett percentilis rangként jelöli őket.
- A normalizálást egyetlen oszlopra vagy ugyanazon adathalmaz több oszlopára is alkalmazhatja.
- Ha meg kell ismételnie a folyamatot, vagy ugyanazokat a normalizálási lépéseket más adatokra is alkalmaznia kell, a lépéseket normalizálási átalakításként mentheti, és alkalmazhatja azokat az azonos sémával rendelkező többi adathalmazra.
Figyelmeztetés
Egyes algoritmusok megkövetelik az adatok normalizálását a modell betanítása előtt. Más algoritmusok saját adatskálázást vagy normalizálást végeznek. Ezért ha egy prediktív modell létrehozásához használandó gépi tanulási algoritmust választ, mindenképpen tekintse át az algoritmus adatkövetelményét, mielőtt normalizálást alkalmaz a betanítási adatokra.
Adatok normalizálásának konfigurálása
Ezzel az összetevővel egyszerre csak egy normalizálási módszert alkalmazhat. Ezért ugyanazt a normalizálási módszert alkalmazza a rendszer az összes kiválasztott oszlopra. Különböző normalizálási módszerek használatához használja az Adatok normalizálása második példányát.
Adja hozzá a Normalize Data összetevőt a folyamathoz. Az Azure Machine Learningben az Adatátalakítás területen található összetevő a Méretezés és csökkentés kategóriában található.
Olyan adatkészlet csatlakoztatása, amely az összes szám legalább egy oszlopát tartalmazza.
Az Oszlopválasztóval válassza ki a normalizálni kívánt numerikus oszlopokat. Ha nem választ ki egyéni oszlopokat, alapértelmezés szerint a bemenet összes numerikus típusú oszlopa megjelenik, és ugyanazt a normalizálási folyamatot alkalmazza a program az összes kijelölt oszlopra.
Ez furcsa eredményekhez vezethet, ha olyan numerikus oszlopokat tartalmaz, amelyeket nem szabad normalizálni! Mindig gondosan ellenőrizze az oszlopokat.
Ha nem észlel numerikus oszlopokat, ellenőrizze az oszlop metaadatait annak ellenőrzéséhez, hogy az oszlop adattípusa támogatott numerikus típus-e.
Tipp.
Ha meg szeretné győződni arról, hogy egy adott típusú oszlop bemenetként van megadva, próbálkozzon az Adathalmaz oszlopainak kijelölése összetevővel az adatok normalizálása előtt.
Ha bejelöli a 0 értéket az állandó oszlopokhoz, jelölje be ezt a beállítást, ha bármely numerikus oszlop egyetlen változatlan értéket tartalmaz. Ez biztosítja, hogy az ilyen oszlopok ne legyenek használva a normalizálási műveletekben.
Az Átalakítási módszer legördülő listájában válasszon egyetlen matematikai függvényt, amely az összes kijelölt oszlopra alkalmazható.
Zscore: Az összes értéket z-pontszámmá alakítja.
Az oszlop értékei a következő képlet használatával lesznek átalakítva:
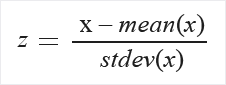
A középérték és a szórás az egyes oszlopokhoz külön van kiszámítva. A sokaság szórása használatos.
MinMax: A min-max normalizer lineárisan újraskáláz minden funkciót a [0,1] intervallumra.
A [0,1] intervallumra való újraskálázás az egyes funkciók értékeinek eltolásával történik, hogy a minimális érték 0 legyen, majd osztva az új maximális értékkel (ami az eredeti maximális és minimális értékek különbsége).
Az oszlop értékei a következő képlet használatával lesznek átalakítva:

Logisztikai: Az oszlop értékei a következő képlet használatával lesznek átalakítva:

LogNormal: Ez a beállítás az összes értéket lognormális skálává alakítja.
Az oszlop értékei a következő képlet használatával lesznek átalakítva:

Itt μ és σ az eloszlás paraméterei, empirikusan számítva az adatokból a legnagyobb valószínűség becsléseként, minden oszlopra külön-külön.
TanH: Minden érték hiperbolikus tangenssé lesz konvertálva.
Az oszlop értékei a következő képlet használatával lesznek átalakítva:

Küldje el a folyamatot, vagy kattintson duplán az Adat normalizálása összetevőre, és válassza a Kijelölt futtatása lehetőséget.
Results (Eredmények)
Az Adat normalizálása összetevő két kimenetet hoz létre:
Az átalakított értékek megtekintéséhez kattintson a jobb gombbal az összetevőre, és válassza a Vizualizáció lehetőséget.
Alapértelmezés szerint az értékek a helyén lesznek átalakítva. Ha össze szeretné hasonlítani az átalakított értékeket az eredeti értékekkel, az Oszlopok hozzáadása összetevővel újrakombinálja az adathalmazokat, és egymás mellett tekintheti meg az oszlopokat.
Ha menteni szeretné az átalakítást, hogy ugyanazt a normalizálási módszert alkalmazza egy másik adatkészletre, jelölje ki az összetevőt, és válassza az Adathalmaz regisztrálása lehetőséget a jobb oldali panel Kimenetek lapján.
Ezután betöltheti a mentett átalakításokat a bal oldali navigációs ablak Átalakítások csoportjából, és alkalmazhatja azokat egy azonos sémával rendelkező adathalmazra az Átalakítás alkalmazásával.
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.