Modell összetevő betanítása
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti.
Ezzel az összetevővel betanított egy besorolási vagy regressziós modellt. A betanítás egy modell definiálása és paramétereinek megadása után történik, és címkézett adatokat igényel. A Modell betanításával egy meglévő modell új adatokkal való újratanítására is használható.
A betanítási folyamat működése
Az Azure Machine Learningben a gépi tanulási modell létrehozása és használata általában háromlépéses folyamat.
Egy modellt egy adott algoritmustípus kiválasztásával és annak paramétereinek vagy hiperparamétereinek meghatározásával konfigurálhat. Válasszon a következő modelltípusok közül:
- Neurális hálózatokon, döntési fákon és döntési erdőkön és más algoritmusokon alapuló besorolási modellek.
- Regressziós modellek, amelyek tartalmazhatnak standard lineáris regressziót, vagy más algoritmusokat használnak, beleértve a neurális hálózatokat és a Bayes-regressziót.
Adjon meg egy címkézett adathalmazt, amely kompatibilis az algoritmussal. Csatlakoztassa mind az adatokat, mind a modellt a modell betanítása érdekében.
A betanítás egy adott bináris formátum, az iLearner, amely az adatokból tanult statisztikai mintákat foglalja magában. Ezt a formátumot közvetlenül nem módosíthatja vagy olvashatja el; más összetevők azonban használhatják ezt a betanított modellt.
A modell tulajdonságait is megtekintheti. További információkért tekintse meg az Eredmények szakaszt.
A betanítás befejezése után használja a betanított modellt az egyik pontozási összetevővel, hogy előrejelzéseket készítsen az új adatokról.
A betanított modell használata
Adja hozzá a Modell betanítása összetevőt a folyamathoz. Ezt az összetevőt a Machine Learning kategóriában találja. Bontsa ki a Betanítása elemet, majd húzza a Modell betanítása összetevőt a folyamatba.
A bal oldali bemeneten csatlakoztassa a nem betanított módot. Csatolja a betanítási adatkészletet a Train Model jobb oldali bemenetéhez.
A betanítási adatkészletnek címkeoszlopot kell tartalmaznia. A címkék nélküli sorok figyelmen kívül lesznek hagyva.
A Címke oszlopnál kattintson a Szerkesztés oszlopra az összetevő jobb oldali panelén, és válasszon ki egy olyan oszlopot, amely a modell által a betanításhoz használható eredményeket tartalmazza.
Besorolási problémák esetén a címkeoszlopnak kategorikus vagy különálló értékeket kell tartalmaznia. Néhány példa lehet egy igen/nem minősítés, egy betegségbesorolási kód vagy név, vagy egy jövedelemcsoport. Ha nemkategorikus oszlopot választ, az összetevő hibát ad vissza a betanítás során.
Regressziós problémák esetén a címkeoszlopnak olyan numerikus adatokat kell tartalmaznia, amelyek a válaszváltozót jelölik. Ideális esetben a numerikus adatok folyamatos skálázást jelölnek.
Ilyen lehet például a hitelkockázati pontszám, a merevlemez meghibásodásának előrejelzett ideje, vagy egy adott napon vagy időpontban a call centerbe irányuló hívások előrejelzett száma. Ha nem numerikus oszlopot választ, hibaüzenet jelenhet meg.
- Ha nem adja meg, hogy melyik címkeoszlopot használja, az Azure Machine Learning az adathalmaz metaadatainak használatával megpróbálja kikövetkeztetni, hogy melyik a megfelelő címkeoszlop. Ha nem a megfelelő oszlopot választja, az oszlopválasztóval javítsa ki.
Tipp.
Ha problémát tapasztal az Oszlopválasztó használata során, tippekért tekintse meg az Adathalmaz oszlopainak kijelölése című cikket. Néhány gyakori forgatókönyvet és tippet ismertet a WITH RULES és a BY NAME beállítás használatához.
Küldje el a folyamatot. Ha sok adata van, az eltarthat egy ideig.
Fontos
Ha van egy azonosító oszlopa, amely az egyes sorok azonosítója, vagy egy szövegoszlop, amely túl sok egyedi értéket tartalmaz, a Modell betanítása hibát okozhat, például: "A(z) "{column_name}" oszlopban lévő egyedi értékek száma nagyobb az engedélyezettnél.
Ennek az az oka, hogy az oszlop elérte az egyedi értékek küszöbértékét, és memóriakihasználtságot okozhat. A Metaadatok szerkesztése funkcióval megjelölheti az oszlopot Törlés funkcióként, és nem használható a betanításban, vagy N-Gram-szolgáltatások kinyerhetők a Szöveg összetevőből a szövegoszlop előfeldolgozásához. További hibaadatokért tekintse meg a Tervező hibakódját .
Modell értelmezhetősége
A modellértelmezhetőség lehetővé teszi az ml-modell megértését és a döntéshozatal alapjául szolgáló, az emberek számára érthető módon történő bemutatását.
A Modell betanítása összetevő jelenleg az ml-modellek magyarázatára használható értelmező csomag használatát támogatja. A következő beépített algoritmusok támogatottak:
- Lineáris regresszió
- Neurális hálózat típusú regresszió
- Megnövelt Decistion Tree Regresszió
- Döntési erdő típusú regresszió
- Poisson-regresszió
- Kétosztályos logisztikai regresszió
- Kétosztályos támogató vektorgép
- Kétosztályos felturbózott decistion fa
- Kétosztályos döntési erdő
- Többosztályos döntési erdő
- Többosztályos logisztikai regresszió
- Többosztályos neurális hálózat
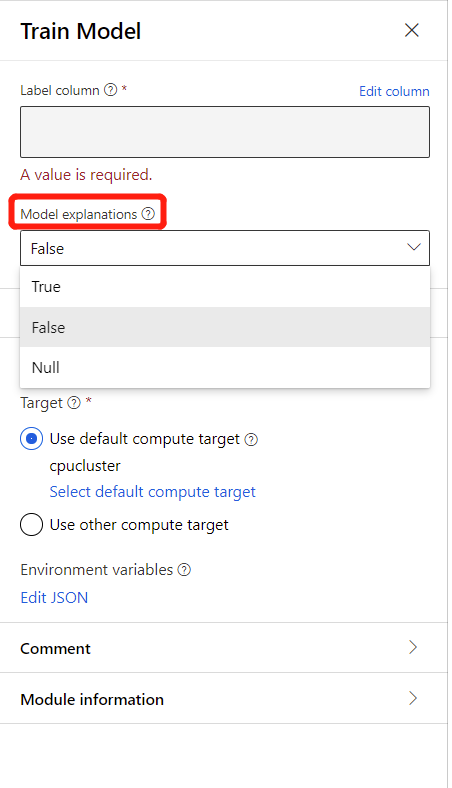
Modellmagyarázatok létrehozásához válassza a True (Igaz) lehetőséget a Modellmagyarázat betanítása összetevő modellmagyarázatának legördülő listájában. Alapértelmezés szerint Hamis értékre van állítva a Modell betanítása összetevőben. Vegye figyelembe, hogy a magyarázat létrehozása extra számítási költséget igényel.
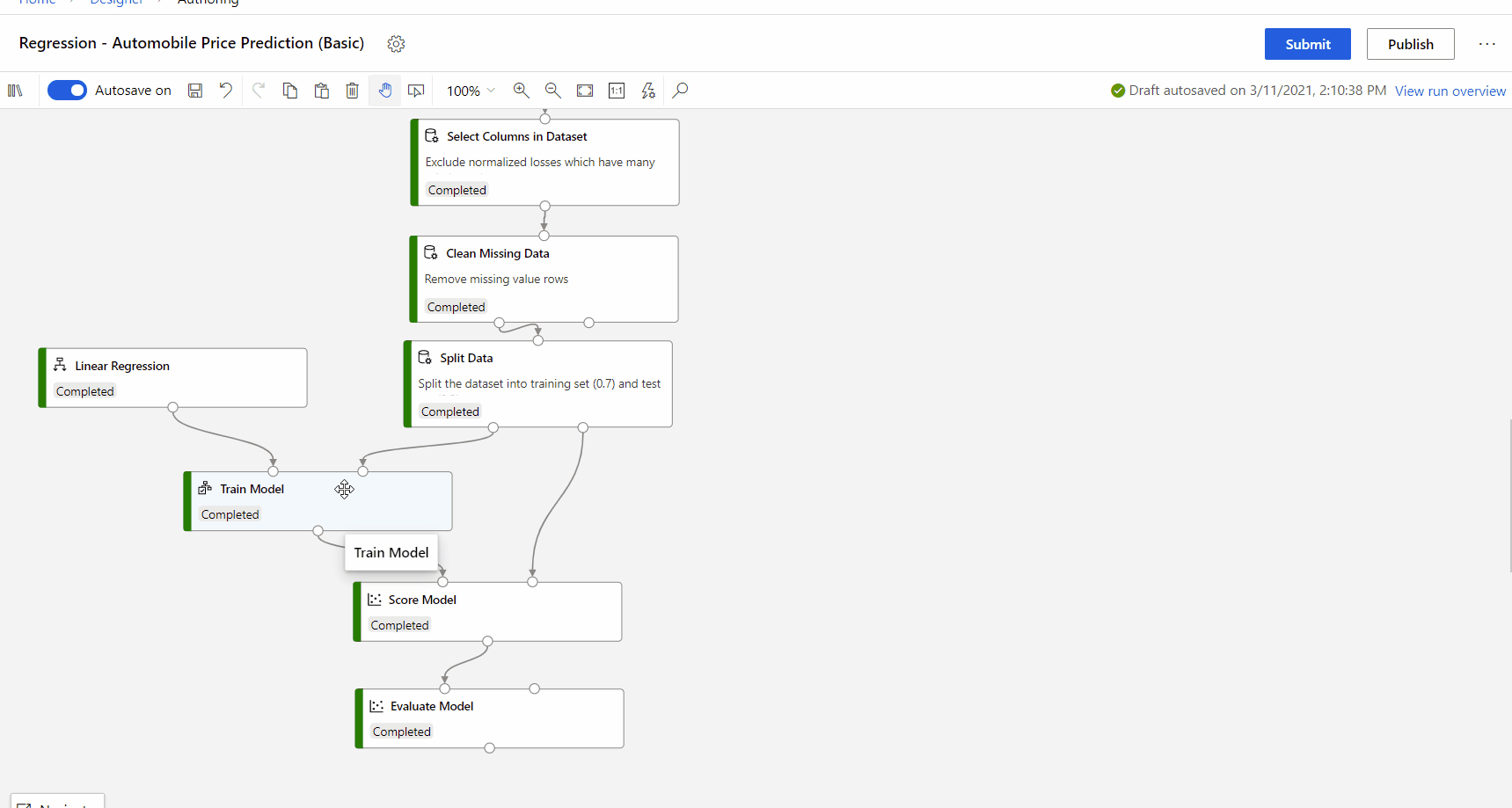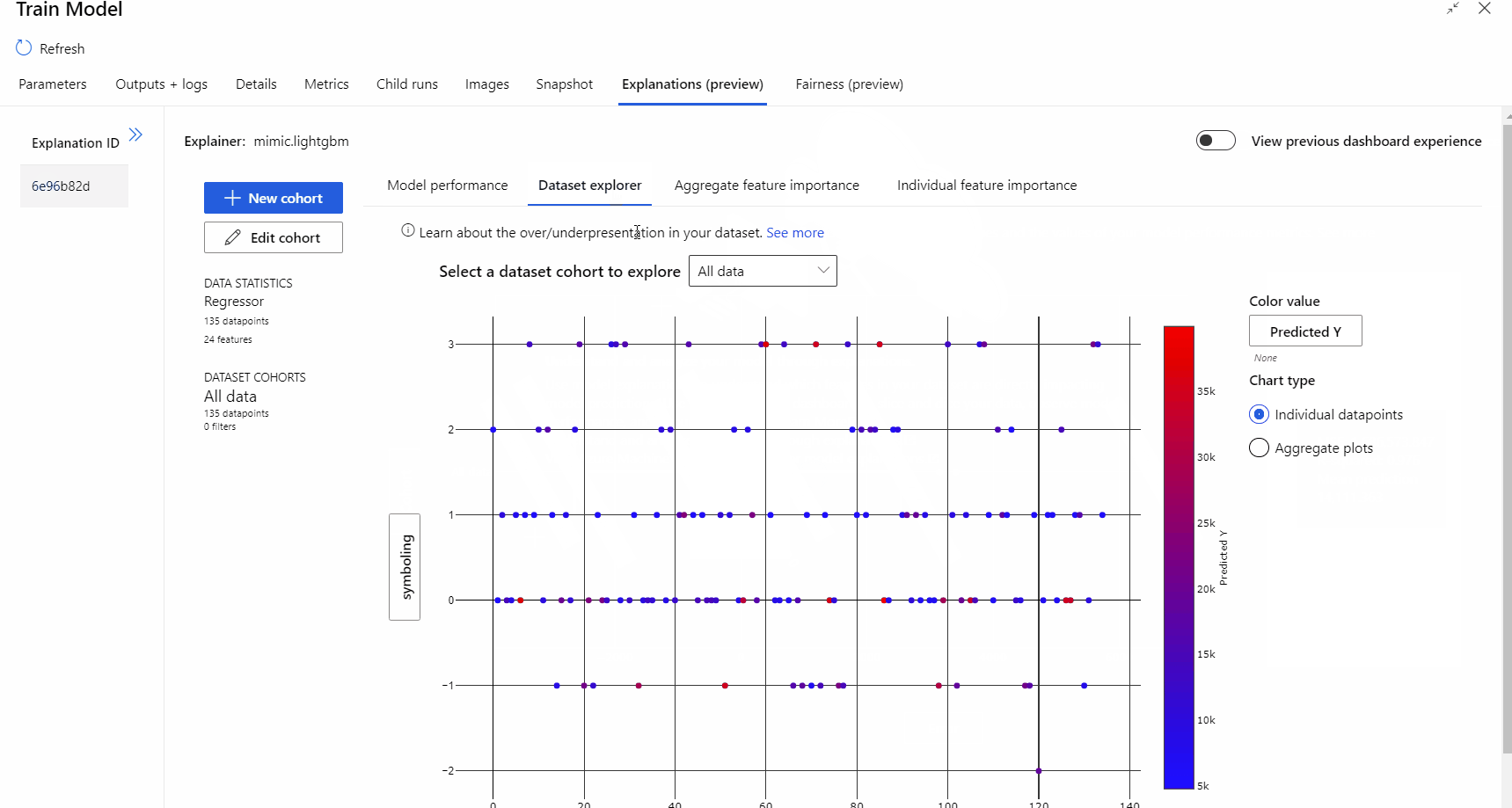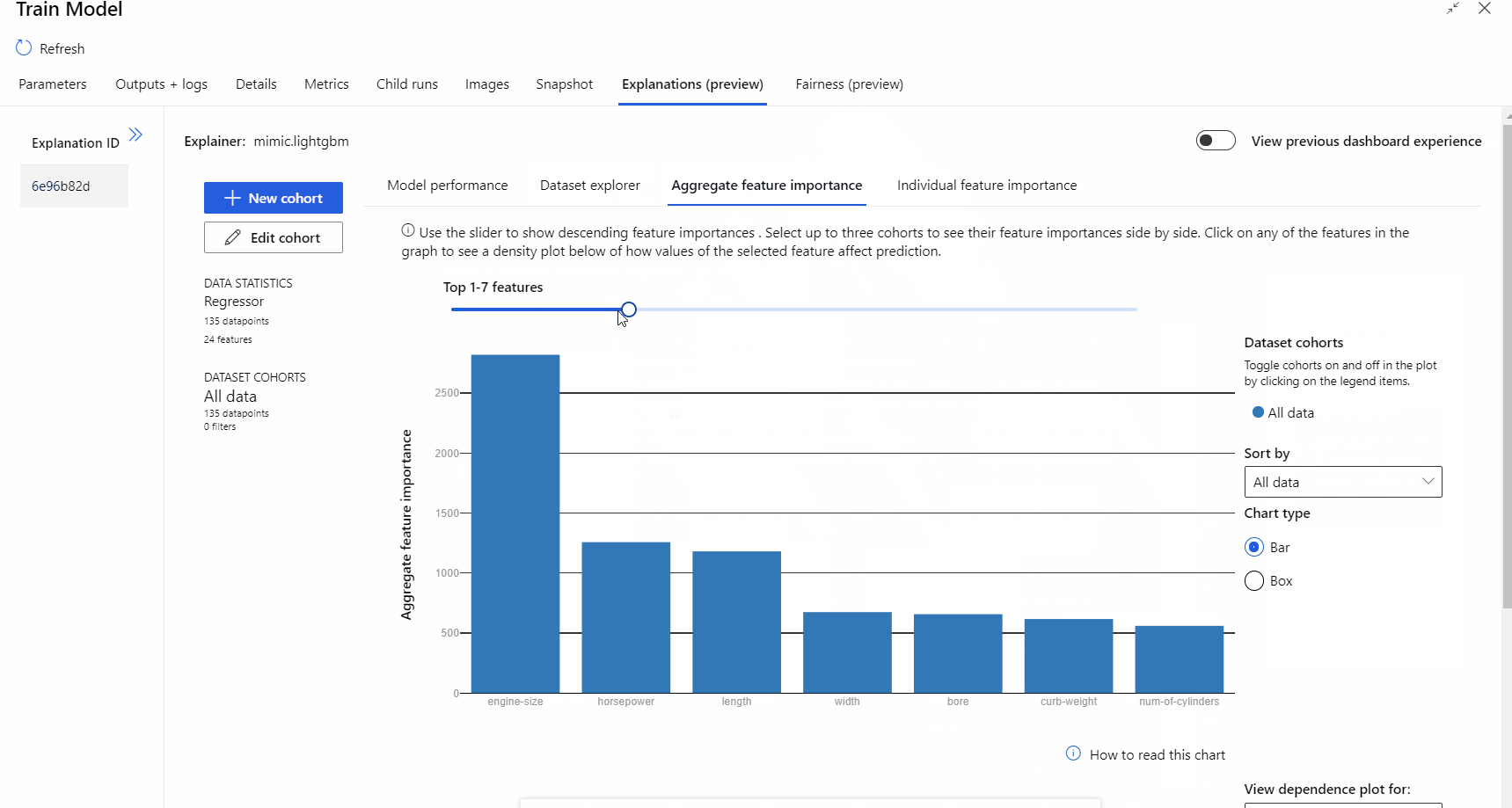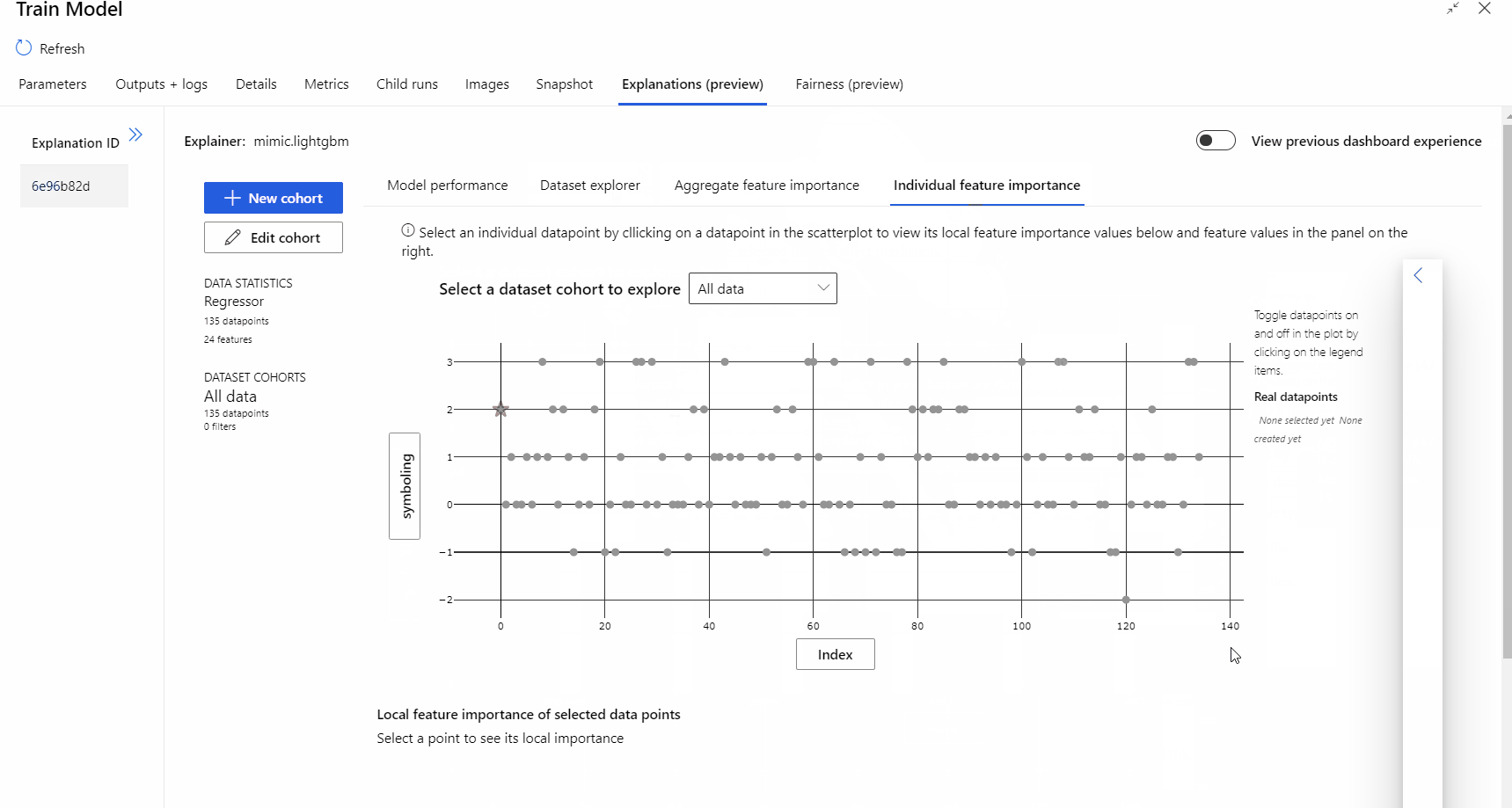
A folyamat futtatása után felkeresheti a Modell betanítása összetevő jobb oldali paneljének Magyarázatok lapját, és megismerheti a modell teljesítményét, az adathalmazt és a funkció fontosságát.
Ha többet szeretne megtudni a modellmagyarázatok Azure Machine Learningben való használatáról, tekintse meg az ML-modellek értelmezéséről szóló útmutatót.
Results (Eredmények)
A modell betanítása után:
Ha más folyamatokban szeretné használni a modellt, válassza ki az összetevőt, és válassza az Adathalmaz regisztrálása ikont a Jobb oldali Panel Kimenetek lapján. A mentett modellek az összetevőpalettán, az Adathalmazok területen érhetők el.
Ha új értékek előrejelzéséhez szeretné használni a modellt, csatlakoztassa a Score Model összetevőhöz új bemeneti adatokkal együtt.
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.