Automatizált gépi tanulás (AutoML)?
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Az automatizált gépi tanulás, más néven automatizált ml vagy AutoML a gépi tanulási modell fejlesztésének időigényes, iteratív feladatainak automatizálása. Lehetővé teszi az adattudósok, elemzők és fejlesztők számára, hogy nagy léptékű, hatékonyságú és termelékenységű ML-modelleket építsenek, miközben fenntartják a modell minőségét. Az Azure Machine Learning automatizált gépi tanulása a Microsoft Research részlegünk áttörésén alapul.
A hagyományos gépi tanulási modellek fejlesztése erőforrás-igényes, és jelentős tartományismeretet és időt igényel több tucat modell előállításához és összehasonlításához. Az automatizált gépi tanulással felgyorsíthatja az éles üzemre kész gépi tanulási modellek nagy egyszerűséggel és hatékonysággal történő beszerzéséhez szükséges időt.
Az AutoML használatának módjai az Azure Machine Learningben
Az Azure Machine Learning az alábbi két szolgáltatást kínálja az automatizált gépi tanulás használatához. Az egyes szolgáltatások (v1) funkció rendelkezésre állásának megismeréséhez tekintse meg a következő szakaszokat.
Kódtal rendelkező ügyfelek számára az Azure Machine Learning Python SDK. Ismerkedés az oktatóanyaggal : Automatizált gépi tanulás használata a taxidíjak (v1) előrejelzéséhez.
A korlátozott/kód nélküli felhasználói élmény érdekében az Azure Machine Learning Studio a következő címen érhető el https://ml.azure.com: . Első lépésként kezdje ezekkel az oktatóanyagokkal:
Kísérlet beállításai
Az alábbi beállítások lehetővé teszik az automatizált gépi tanulási kísérlet konfigurálását.
| A Python SDK | A studio webes felülete | |
|---|---|---|
| Adatok felosztása betanítási/érvényesítési csoportokra | ✓ | ✓ |
| Támogatja a gépi tanulási feladatokat: besorolás, regresszió, > előrejelzés | ✓ | ✓ |
| Támogatja a számítógépes látással kapcsolatos feladatokat: képosztályozás, objektumészlelés & példányszegmentálás | ✓ | |
| Optimalizálás elsődleges metrikák alapján | ✓ | ✓ |
| Az Azure Machine Learning számítási célként való használatát támogatja | ✓ | ✓ |
| Előrejelzési horizont, célelmaradások és gördülő ablak konfigurálása | ✓ | ✓ |
| Kilépési feltételek beállítása | ✓ | ✓ |
| Egyidejű iterációk beállítása | ✓ | ✓ |
| Oszlopok elvetése | ✓ | ✓ |
| Algoritmusok blokkolása | ✓ | ✓ |
| Keresztérvényesítés | ✓ | ✓ |
| Az Azure Databricks-fürtök betanítását támogatja | ✓ | |
| A megtervezett funkciók neveinek megtekintése | ✓ | |
| A featurizáció összefoglalása | ✓ | |
| Ünnepnapok featurizációja | ✓ | |
| A naplófájl részletességi szintjei | ✓ |
Modellbeállítások
Ezek a beállítások az automatizált gépi tanulási kísérlet eredményeként alkalmazhatók a legjobb modellre.
| A Python SDK | A studio webes felülete | |
|---|---|---|
| A legjobb modellregisztráció, üzembe helyezés, magyarázhatóság | ✓ | ✓ |
| Szavazati együttes & verem-együttesmodellek engedélyezése | ✓ | ✓ |
| A legjobb modell megjelenítése nem elsődleges metrika alapján | ✓ | |
| ONNX-modell kompatibilitásának engedélyezése/letiltása | ✓ | |
| A modell tesztelése | ✓ | ✓ (előzetes verzió) |
Feladatvezérlési beállítások
Ezek a beállítások lehetővé teszik a kísérleti feladatok és a gyermekfeladatok áttekintését és vezérlését.
| A Python SDK | A studio webes felülete | |
|---|---|---|
| Feladatösszegző táblázat | ✓ | ✓ |
| Feladatok megszakítása > gyermekfeladatok | ✓ | ✓ |
| Védőkorlátok lekérése | ✓ | ✓ |
| Feladatok szüneteltetése és folytatása | ✓ |
Mikor érdemes használni az AutoML-t: besorolás, regresszió, előrejelzés, számítógépes látás & NLP
Alkalmazza az automatizált gépi tanulást, ha azt szeretné, hogy az Azure Machine Learning betanítson és hangoljon egy modellt az Ön számára a megadott célmetrika használatával. Az automatizált gépi tanulási folyamat demokratizálja a gépi tanulási modell fejlesztési folyamatát, és lehetővé teszi a felhasználók számára az adatelemzési szakértelmüktől függetlenül egy teljes körű gépi tanulási folyamat azonosítását bármilyen probléma esetén.
Az ml-szakemberek és a fejlesztők az iparágakban az automatizált gépi tanulást a következő célra használhatják:
- Ml-megoldások implementálása széles körű programozási ismeretek nélkül
- Időt és erőforrásokat takaríthat meg
- Adatelemzési ajánlott eljárások használata
- Agilis problémamegoldás biztosítása
Osztályozás
A besorolás gyakori gépi tanulási feladat. A besorolás a felügyelt tanulás olyan típusa, amelyben a modellek tanítási adatok használatával tanulnak, és a megtanultakat új adatokra alkalmazzák. Az Azure Machine Learning kifejezetten ezekhez a feladatokhoz kínál jellemzőkre bontást, például mély neurális hálózati szövegek jellemzőkre bontását a besoroláshoz. További információ a featurizálási (v1) lehetőségekről.
A besorolási modellek fő célja annak előrejelzése, hogy a betanítási adatokból tanultak alapján milyen kategóriákba sorolhatók az új adatok. Gyakori besorolási példák a csalások észlelése, a kézírás-felismerés és az objektumészlelés. További információ és egy példa : Besorolási modell létrehozása automatizált gépi tanulással (v1).
Példák a besorolásra és az automatizált gépi tanulásra ezekben a Python-jegyzetfüzetekben: Csalásészlelés, marketing előrejelzés és Newsgroup-adatbesorolás
Regresszió
A besoroláshoz hasonlóan a regressziós feladatok is gyakori felügyelt tanulási feladatok.
A besorolástól eltérően, ahol az előrejelzett kimeneti értékek kategorikusak, a regressziós modellek numerikus kimeneti értékeket jeleznek előre független prediktorok alapján. A regresszió célja, hogy segítsen a független prediktorváltozók közötti kapcsolat felállításában azáltal, hogy megbecsüli, milyen hatással van egy változó a többire. Például előre jelzi egy autó árát olyan jellemzők alapján, mint az üzemanyagfogyasztás, a biztonsági minősítés stb. További információ és példa az automatizált gépi tanulás (v1) regressziójára.
Példák a regresszióra és az automatizált gépi tanulásra az előrejelzésekhez ezekben a Python-jegyzetfüzetekben: CPU-teljesítmény előrejelzése,
Idősoros előrejelzés
Az előrejelzések minden vállalkozás fontos részét képezik, legyen szó bevételről, leltárról, értékesítésről vagy vásárlói keresletről. Az automatizált ML segítségével egyesítheti a technikai megoldásokat és módszereket, és ajánlott, magas minőségű idősor-előrejelzést kaphat. További információ ezzel a útmutatóval: automatizált gépi tanulás idősor-előrejelzéshez (v1).
Az automatizált idősoros kísérletek többváltozós regressziós problémaként vannak kezelve. A múltbeli idősorértékek "kimutatása" további dimenziókká válik a regresszor és más prediktorok számára. Ez a megközelítés a klasszikus idősoros módszerekkel ellentétben azzal az előnnyel jár, hogy a betanítás során természetesen több környezeti változót és azok egymáshoz való viszonyát is beépíti. Az automatizált gépi tanulás egyetlen, de gyakran belsőleg elágaztatott modellt tanul az adathalmaz és az előrejelzési horizont összes eleméhez. Így több adat áll rendelkezésre a modellparaméterek becsléséhez, és lehetővé válik a nem látott adatsorok általánosítása.
A speciális előrejelzési konfiguráció a következőket tartalmazza:
- ünnepészlelés és jellemzőkre bontás
- idősorok és DNN-tanulók (Auto-ARIMA, Prophet, ForecastTCN)
- számos modell támogatja a csoportosítást
- gördülő kiindulópont keresztellenőrzése
- konfigurálható késés
- görgő ablakösszesítési szolgáltatások
Példák a regresszióra és az automatizált gépi tanulásra az előrejelzésekhez ezekben a Python-jegyzetfüzetekben: Sales Forecasting, Demand Forecasting és Forecasting GitHub's Daily Active Users.
Számítógépes látástechnológia
A számítógépes látási feladatok támogatása lehetővé teszi a képadatokra betanított modellek egyszerű létrehozását olyan forgatókönyvek esetében, mint a képbesorolás és az objektumészlelés.
Ezzel a képességgel a következő lehetőségeket használhatja:
- Zökkenőmentes integráció az Azure Machine Learning adatcímkézési funkciójával
- Címkézett adatok használata képmodellek létrehozásához
- Optimalizálja a modell teljesítményét a modellalgoritmus megadásával és a hiperparaméterek finomhangolásával.
- Töltse le vagy telepítse az eredményként kapott modellt webszolgáltatásként az Azure Machine Learningben.
- Az Azure Machine Learning MLOps és az ML Pipelines (v1) képességeinek kihasználása nagy méretekben.
A látási feladatokhoz készült AutoML-modellek létrehozása az Azure Machine Learning Python SDK-val támogatott. Az eredményként kapott kísérletezési feladatok, modellek és kimenetek az Azure Machine Learning Studio felhasználói felületén érhetők el.
Megtudhatja, hogyan állíthat be AutoML-betanítást számítógépes látásmodellekhez.

A képek esetében az automatizált gépi tanulás az alábbi számítógépes látástechnológiai feladatokat támogatja:
| Feladat | Leírás |
|---|---|
| Többosztályos képbesorolás | Olyan feladatok, amelyekben a kép egy osztálykészletből származó egyetlen címkével van besorolva – például minden kép egy „macska” vagy egy „kutya” vagy egy „kacsa” képeként van besorolva |
| Többcímkés képbesorolás | Olyan feladatok, amelyekben a kép egy vagy több címkét is kaphat egy címkekészletből – például egy kép címkéje lehet „macska” és „kutya” is |
| Objektumészlelés | Olyan feladatok, amelyek a képen látható objektumok azonosítására és az egyes objektumok határolókeretekkel való megkeresése szolgálnak – például az összes kutya és macska megkeresése egy képen, és határolókeret rajzolása mindegyik köré. |
| Példányszegmentálás | A képeken látható objektumok képpontszintű azonosítására használható feladatok, amelyek egy sokszöget rajzolnak a kép egyes objektumai köré. |
Természetes nyelvi feldolgozás: NLP
Az automatizált gépi tanulás természetes nyelvi feldolgozási (NLP) feladatainak támogatása lehetővé teszi a szöveges adatokon betanított modellek egyszerű létrehozását a szövegbesoroláshoz és az elnevezett entitásfelismerési forgatókönyvekhez. Az automatizált gépi tanulási betanított NLP-modellek létrehozása az Azure Machine Learning Python SDK-n keresztül támogatott. Az eredményként kapott kísérletezési feladatok, modellek és kimenetek az Azure Machine Learning Studio felhasználói felületén érhetők el.
Az NLP-képesség a következőket támogatja:
- Teljes körű mély neurális hálózati NLP-képzés a legújabb előre betanított BERT-modellekkel
- Zökkenőmentes integráció az Azure Machine Learning-adatok címkézésével
- Címkézett adatok használata NLP-modellek létrehozásához
- Többnyelvű támogatás 104 nyelven
- Elosztott betanítás a Horovod használatával
Megtudhatja, hogyan állíthat be AutoML-betanítást NLP-modellekhez (v1).
Az automatizált gépi tanulás működése
A betanítás során az Azure Machine Learning számos folyamatot hoz létre párhuzamosan, amelyek különböző algoritmusokat és paramétereket próbálnak ki Önnek. A szolgáltatás a funkciók kiválasztásával párosított ML-algoritmusokon keresztül iterál, ahol minden iteráció egy betanítási pontszámmal rendelkező modellt hoz létre. Minél magasabb a pontszám, annál jobb, ha a modell "illeszkedik" az adatokhoz. A művelet leáll, amint eléri a kísérletben meghatározott kilépési feltételeket.
Az Azure Machine Learning használatával az alábbi lépésekkel tervezheti meg és futtathatja automatizált gépi tanulási kísérleteit:
A megoldandó gépi tanulási probléma azonosítása: besorolás, előrejelzés, regresszió vagy számítógépes látás.
Válassza ki, hogy a Python SDK-t vagy a studio webes felületét szeretné-e használni: Ismerje meg a Python SDK és a studio webes felület közötti paritást.
- Ha korlátozott vagy nincs kódélmény, próbálja ki az Azure Machine Learning Studio webes felületét a következő helyen: https://ml.azure.com
- Python-fejlesztőknek tekintse meg az Azure Machine Learning Python SDK-t (v1)
Adja meg a címkézett betanítási adatok forrását és formátumát: Numpy-tömbök vagy Pandas-adatkeretek
Konfigurálja a számítási célt a modellbetanításhoz, például a helyi számítógéphez, az Azure Machine Learning Computeshez, a távoli virtuális gépekhez vagy az Azure Databrickshez az SDK 1-ben.
Konfigurálja az automatizált gépi tanulási paramétereket, amelyek meghatározzák , hogy hány iteráció van a különböző modelleken, hiperparaméter-beállításokon, speciális előfeldolgozáson/featurizáción, és milyen metrikákat kell figyelembe venni a legjobb modell meghatározásakor.
Küldje el a betanítási feladatot.
Az eredmények áttekintése
Az alábbi ábra ezt a folyamatot szemlélteti.
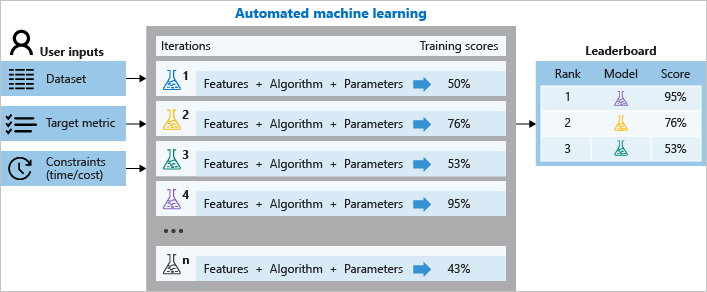
A naplózott feladat adatait is megvizsgálhatja, amelyek a feladat során összegyűjtött metrikákat tartalmazzák. A betanítási feladat létrehoz egy Python szerializált objektumot (.pkl fájlt), amely tartalmazza a modellt és az adatok előfeldolgozását.
Bár a modellépítés automatizált, azt is megtudhatja, hogy mennyire fontosak vagy relevánsak a létrehozott modellek.
Útmutató helyi és távoli felügyelt ml-számítási célokhoz
Az automatizált gépi tanulás webes felülete mindig távoli számítási célt használ. A Python SDK használatakor azonban választhat egy helyi számítást vagy egy távoli számítási célt az automatizált gépi tanulás betanításához.
- Helyi számítás: A betanítás a helyi laptopon vagy virtuálisgép-számításon történik.
- Távoli számítás: A betanítás a Machine Learning számítási fürtökön történik.
Számítási cél kiválasztása
A számítási cél kiválasztásakor vegye figyelembe ezeket a tényezőket:
- Válasszon egy helyi számítást: Ha a forgatókönyv a kis adatokkal és rövid vonatokkal végzett kezdeti feltárásokról vagy demókról szól (például másodperc vagy néhány perc gyermekfeladatonként), akkor a helyi számítógépen történő betanítás jobb választás lehet. Nincs beállítási idő, az infrastruktúra-erőforrások (a számítógép vagy a virtuális gép) közvetlenül elérhetők.
- Válasszon távoli ml számítási fürtöt: Ha olyan nagyobb adatkészletekkel végzett betanítást, mint például az éles betanításokban, amelyek hosszabb vonatokat igénylő modelleket hoznak létre, a távoli számítás sokkal jobb végpontok közötti időt biztosít, mivel
AutoMLpárhuzamossá teszi a vonatokat a fürt csomópontjai között. Távoli számítás esetén a belső infrastruktúra indítási ideje gyermekfeladatonként körülbelül 1,5 percet vesz fel, valamint további perceket a fürtinfrastruktúra számára, ha a virtuális gépek még nem üzemelnek.
Előnyök és hátrányok
Vegye figyelembe ezeket az előnyöket és hátrányokat, ha a helyi és a távoli használatot választja.
| Előnyök (előnyök) | Hátrányok (hátrányok) | |
|---|---|---|
| Helyi számítási cél | ||
| Távoli gépi tanulási számítási fürtök |
Szolgáltatások rendelkezésre állása
A távoli számítás használatakor további funkciók érhetők el az alábbi táblázatban látható módon.
| Szolgáltatás | Távelérés | Helyi |
|---|---|---|
| Adatstreamelés (Nagy méretű adatok támogatása, legfeljebb 100 GB) | ✓ | |
| DNN-BERT-alapú szöveg featurizálása és betanítása | ✓ | |
| Beépített GPU-támogatás (betanítás és következtetés) | ✓ | |
| Képbesorolás és címkézés támogatása | ✓ | |
| Auto-ARIMA, Prophet és ForecastTCN modellek előrejelzéshez | ✓ | |
| Több feladat/iteráció párhuzamosan | ✓ | |
| Modellek létrehozása értelmezhetőséggel az AutoML Studio webes felhasználói felületén | ✓ | |
| Szolgáltatásfejlesztés testreszabása a Studio Web Experience felhasználói felületén | ✓ | |
| Az Azure Machine Learning hiperparaméter-finomhangolása | ✓ | |
| Az Azure Machine Learning Pipeline munkafolyamat-támogatása | ✓ | |
| Feladat folytatása | ✓ | |
| Előrejelzés | ✓ | ✓ |
| Kísérletek létrehozása és futtatása jegyzetfüzetekben | ✓ | ✓ |
| A kísérlet adatainak és metrikáinak regisztrálása és vizualizációja a felhasználói felületen | ✓ | ✓ |
| Adatvédettségi korlátok | ✓ | ✓ |
Betanítási, érvényesítési és tesztelési adatok
Az automatizált gépi tanulással betanítási adatokat biztosít az ML-modellek betanításához, és megadhatja, hogy milyen típusú modellérvényesítést kell végrehajtania. Az automatizált gépi tanulás a betanítás részeként elvégzi a modellérvényesítést. Az automatizált gépi tanulás érvényesítési adatokkal hangolja a modell hiperparamétereit az alkalmazott algoritmus alapján, hogy megtalálja a betanítási adatoknak leginkább megfelelő kombinációt. A hangolás minden iterációja esetében azonban ugyanazokat az érvényesítési adatokat használják, ami modellértékelési torzítást vezet be, mivel a modell folyamatosan fejlődik, és illeszkedik az érvényesítési adatokhoz.
Annak ellenőrzéséhez, hogy az ilyen torzítások nem alkalmazhatók-e a végleges ajánlott modellre, az automatizált gépi tanulás támogatja a tesztadatok használatát az automatizált gépi tanulás által a kísérlet végén javasolt végső modell kiértékeléséhez. Ha tesztadatokat ad meg az AutoML-kísérlet konfigurációjának részeként, a rendszer alapértelmezés szerint teszteli ezt az ajánlott modellt a kísérlet végén (előzetes verzió).
Fontos
A modellek tesztelése egy tesztadatkészlettel a létrehozott modellek kiértékeléséhez előzetes verziójú funkció. Ez a funkció egy kísérleti előzetes verziójú funkció, amely bármikor változhat.
Megtudhatja, hogyan konfigurálhat AutoML-kísérleteket tesztadatok (előzetes verzió) használatára az SDK-val (v1) vagy az Azure Machine Learning Studióval.
A meglévő automatizált gépi tanulási modelleket (előzetes verzió) (v1) is tesztelheti, beleértve a gyermekfeladatokból származó modelleket is, saját tesztadatok megadásával vagy a betanítási adatok egy részének félretenésével.
Jellemzőkiemelés
A szolgáltatásfejlesztés az adatok tartományi ismereteinek felhasználásával olyan funkciókat hoz létre, amelyek segítenek az ml-algoritmusok jobb megismerésében. Az Azure Machine Learningben a skálázási és normalizálási technikákat alkalmazzák a funkciófejlesztés megkönnyítése érdekében. Ezeket a technikákat és jellemzőket együttesen featurizációnak nevezzük.
Automatizált gépi tanulási kísérletek esetén a rendszer automatikusan alkalmazza a featurizációt, de az adatok alapján testre is szabható. További információ a featurizációról (v1) és arról, hogy az AutoML hogyan segít megelőzni a modellek túlillesztését és kiegyensúlyozatlan adatait .
Feljegyzés
A gépi tanulás automatizált featurizálási lépései (funkció normalizálása, hiányzó adatok kezelése, szöveg numerikussá alakítása stb.) a mögöttes modell részévé válnak. Ha a modellt előrejelzésekhez használja, a betanítás során alkalmazott featurizációs lépések automatikusan a bemeneti adatokra lesznek alkalmazva.
A featurizáció testreszabása
További funkciótervezési technikák, például kódolás és átalakítások is elérhetők.
Engedélyezze ezt a beállítást a következőkkel:
Azure Machine Learning Studio: Engedélyezze az automatikus featurizációt a További konfiguráció megtekintése szakaszban az alábbi (v1) lépésekkel.
Python SDK: Adja meg
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'az AutoMLConfig objektumban. További információ a featurizálás (v1) engedélyezéséről.
Együttes modellek
Az automatizált gépi tanulás támogatja az alapértelmezés szerint engedélyezett együttes modelleket. Az együttes tanulás több modell kombinálásával javítja a gépi tanulási eredményeket és a prediktív teljesítményt, és nem egyetlen modelleket használ. Az együttes iterációk a feladat végleges iterációiként jelennek meg. Az automatizált gépi tanulás a szavazati és a halmozási együttes metódusokat is használja a modellek kombinálására:
- Szavazás: az előrejelzett osztály valószínűségeinek súlyozott átlaga (besorolási tevékenységek esetén) vagy az előrejelzett regressziós célok (regressziós tevékenységek esetén) alapján előrejelzést ad.
- Halmozás: a halmozás heterogén modelleket egyesít, és az egyes modellek kimenete alapján betanít egy metamodellt. Az aktuális alapértelmezett metamodellek a logisticRegression a besorolási tevékenységekhez, az ElasticNet pedig a regressziós/előrejelzési tevékenységekhez.
A Caruana-együttes kiválasztási algoritmusa rendezett együttes inicializálásával dönti el, hogy mely modelleket használja az együttesen belül. Magas szinten ez az algoritmus inicializálja az együttest legfeljebb öt, a legjobb egyéni pontszámmal rendelkező modellel, és ellenőrzi, hogy ezek a modellek a legjobb pontszám 5%-os küszöbértékén belül vannak-e a gyenge kezdeti együttes elkerülése érdekében. Ezután minden egyes együttes iterációhoz hozzáad egy új modellt a meglévő együtteshez, és kiszámítja az eredményként kapott pontszámot. Ha egy új modell javította a meglévő együttes pontszámát, az együttes frissül, hogy tartalmazza az új modellt.
Az automatikus gépi tanulás alapértelmezett együttes beállításainak módosításához tekintse meg az útmutatót (v1 ).
AutoML &ONNX
Az Azure Machine Learning segítségével automatizált gépi tanulással létrehozhat egy Python-modellt, és onnx formátumra konvertálhatja. Miután a modellek ONNX formátumban vannak, számos platformon és eszközön futtathatók. További információ az ML-modellek ONNX-sel való felgyorsításáról.
Ebben a Jupyter-jegyzetfüzet-példában megtudhatja, hogyan konvertálhat ONNX formátumra. Megtudhatja, hogy mely algoritmusokat támogatja az ONNX (v1).
Az ONNX-futtatókörnyezet a C#-ot is támogatja, így a C#-alkalmazásokban automatikusan létrehozott modellt anélkül használhatja, hogy a REST-végpontok által bevezetett hálózati késéseket vagy késéseket kellene megszüntetnie. További információ az AutoML ONNX-modell használatáról egy .NET-alkalmazásban az ONNX-modellek ML.NET és az ONNX runtime C# API-val való következtetésével.
Következő lépések
Az AutoML használatához több erőforrás is rendelkezésre áll.
Oktatóanyagok/ útmutatók
Az oktatóanyagok az AutoML-forgatókönyvek bevezető példái.
A kód első élményéhez kövesse az Oktatóanyagot: Regressziós modell betanítása autoML-vel és Pythonnal (v1).
Az alacsony vagy kód nélküli élményért tekintse meg az Oktatóanyagot: Besorolási modell betanítása kód nélküli AutoML-vel az Azure Machine Learning Studióban.
A számítógépes látásmodellek betanítása az AutoML használatával: Oktatóanyag: Objektumészlelési modell betanítása autoML-vel és Pythonnal (v1).
Az útmutatók további részleteket nyújtanak az automatizált gépi tanulás funkcióiról. Például,
Automatikus betanítási kísérletek beállításainak konfigurálása
Megtudhatja, hogyan taníthat be előrejelzési modelleket idősoradatokkal (v1).
Megtudhatja, hogyan taníthat be számítógépes látásmodelleket a Pythonnal (v1).
Megtudhatja, hogyan tekintheti meg a létrehozott kódot az automatizált gépi tanulási modellekből.
Jupyter-jegyzetfüzetminták
Tekintse át a részletes kódmintákat és használati eseteket az automatizált gépi tanulási minták GitHub-jegyzetfüzettárában.
Python SDK-referencia
Az AutoML-osztály referenciadokumentációjával mélyítheti el az SDK tervezési mintáival és osztályspecifikációival kapcsolatos szakértelmét.
Feljegyzés
Az automatizált gépi tanulási képességek más Microsoft-megoldásokban is elérhetők, például ML.NET, HDInsight, Power BI és SQL Server