Az AutoML beállítása idősorozat-előrejelzési modell betanításához Pythonnal (SDKv1)
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Ebből a cikkből megtudhatja, hogyan állíthat be AutoML-betanítást idősorozat-előrejelzési modellekhez az Azure Machine Learning automatizált ml-jével az Azure Machine Learning Python SDK-ban.
Ehhez a következőket kell tennie:
- Adatok előkészítése idősorozat-modellezéshez.
- Adott idősorparaméterek konfigurálása egy
AutoMLConfigobjektumban. - Előrejelzések futtatása idősoradatokkal.
Az alacsony kódélményért tekintse meg az Azure Machine Learning Studióban az automatizált gépi tanulással kapcsolatos igény előrejelzését ismertető oktatóanyagot egy idősoros előrejelzési példához, amely automatizált gépi tanulást használ.
A klasszikus idősoros módszerekkel ellentétben az automatizált gépi tanulásban a múltbeli idősorértékek "kimutatása" további dimenziókká válik a regresszor és más prediktorok számára. Ez a megközelítés több környezeti változót és azok egymáshoz való viszonyát foglalja magában a betanítás során. Mivel több tényező is befolyásolhatja az előrejelzést, ez a módszer jól illeszkedik a valós előrejelzési forgatókönyvekhez. Az értékesítések előrejelzésekor például a korábbi trendek, az árfolyam és az ár interakciói együttesen vezetik az értékesítési eredményeket.
Előfeltételek
Ebben a cikkben a következőt kell megadnia:
Egy Azure Machine Learning-munkaterület. A munkaterület létrehozásához lásd : Munkaterület-erőforrások létrehozása.
Ez a cikk feltételezi, hogy bizonyos ismeretekkel rendelkezik egy automatizált gépi tanulási kísérlet beállításához. Kövesse az útmutatót a gépi tanulási kísérlet fő tervezési mintáinak megtekintéséhez.
Fontos
A cikkben szereplő Python-parancsokhoz a legújabb
azureml-train-automlcsomagverzió szükséges.- Telepítse a legújabb
azureml-train-automlcsomagot a helyi környezetbe. - A legújabb
azureml-train-automlcsomag részleteiért tekintse meg a kibocsátási megjegyzéseket.
- Telepítse a legújabb
Betanítási és érvényesítési adatok
Az előrejelzési regressziós tevékenységtípus és az automatizált gépi tanulás regressziós tevékenységtípusa között a legfontosabb különbség az, hogy a betanítási adatokban szerepel egy érvényes idősort képviselő funkció. A rendszeres idősorok jól definiált és konzisztens gyakorisággal rendelkeznek, és a folyamatos időtartam minden mintapontján értéket mutatnak.
Fontos
A jövőbeli értékek előrejelzésére szolgáló modell betanításakor győződjön meg arról, hogy a betanításban használt összes funkció használható a kívánt horizontra vonatkozó előrejelzések futtatásakor. Például egy keresleti előrejelzés létrehozásakor, beleértve az aktuális részvényárak egyik funkcióját, jelentősen növelheti a betanítás pontosságát. Ha azonban hosszú horizonttal szeretne előrejelzést végezni, előfordulhat, hogy nem tudja pontosan előrejelezni a jövőbeli idősorpontoknak megfelelő jövőbeli részvényértékeket, és a modell pontossága is szenvedhet.
Külön betanítási és érvényesítési adatokat közvetlenül az AutoMLConfig objektumban adhat meg. További információ az AutoMLConfigról.
Az idősorok előrejelzéséhez alapértelmezés szerint csak a gördülő eredetű keresztérvényesítést (ROCV) használja a rendszer. A ROCV betanítási és érvényesítési adatokra osztja az adatsort egy forrásidőpont használatával. A forrás időben történő csúsztatásával keresztérvényesítési redők jönnek létre. Ez a stratégia megőrzi az idősor adatintegritását, és kiküszöböli az adatszivárgás kockázatát.
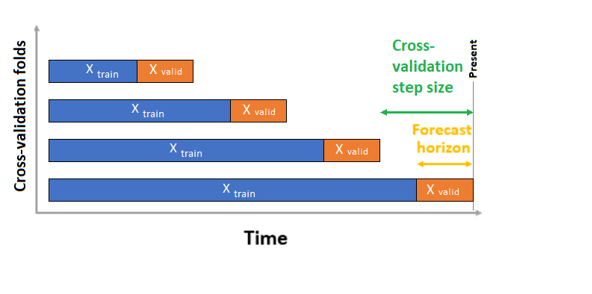
Adja át a betanítási és érvényesítési adatokat egyetlen adatkészletként a paraméternek training_data. Állítsa be a keresztérvényesítési hajtások számát a paraméterrel n_cross_validations , és állítsa be a két egymást követő keresztérvényesítési hajtás közötti időszakok számát a következővel cv_step_size: . A paramétereket üresen is hagyhatja, és az AutoML automatikusan beállítja őket.
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Saját érvényesítési adatokat is használhat, további információt az Adatfelosztások és keresztérvényesítés konfigurálása az AutoML-ben című témakörben talál.
További információ arról, hogy az AutoML hogyan alkalmazza a keresztérvényesítést a túlillesztési modellek elkerülése érdekében.
Kísérlet konfigurálása
Az AutoMLConfig objektum meghatározza az automatizált gépi tanulási feladatokhoz szükséges beállításokat és adatokat. Az előrejelzési modell konfigurációja hasonló a standard regressziós modell beállításához, de bizonyos modellek, konfigurációs beállítások és featurizációs lépések kifejezetten az idősoros adatokhoz léteznek.
Támogatott modellek
Az automatizált gépi tanulás automatikusan kipróbál különböző modelleket és algoritmusokat a modell létrehozásának és finomhangolási folyamatának részeként. Felhasználóként nincs szükség az algoritmus megadására. Az előrejelzési kísérletekhez a natív idősorok és a mélytanulási modellek is a javaslati rendszer részét képezik.
Tipp.
A hagyományos regressziós modelleket az előrejelzési kísérletekre vonatkozó javaslati rendszer részeként is teszteljük. A támogatott modellek teljes listáját az SDK referenciadokumentációjában találja.
Konfigurációs beállítások
A regressziós problémához hasonlóan szabványos betanítási paramétereket is definiálhat, például feladattípust, iterációk számát, betanítási adatokat és keresztérvényesítések számát. Az előrejelzési tevékenységekhez a kísérlet konfigurálásához a paraméterek és forecast_horizon a time_column_name paraméterek szükségesek. Ha az adatok több idősort is tartalmaznak, például több üzlet értékesítési adatait vagy energiaadatokat különböző állapotokban, az automatizált gépi tanulás automatikusan észleli ezt, és beállítja Önnek a time_series_id_column_names paramétert (előzetes verzió). További paramétereket is megadhat a futtatás jobb konfigurálásához. A választható konfigurációk szakaszában részletesebben tájékozódhat a választható lehetőségekről.
Fontos
Az automatikus idősor-azonosítás jelenleg nyilvános előzetes verzióban érhető el. Ez az előzetes verzió szolgáltatásszintű szerződés nélkül érhető el. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. További információ: Kiegészítő használati feltételek a Microsoft Azure előzetes verziójú termékeihez.
| Paraméter neve | Leírás |
|---|---|
time_column_name |
Az idősor létrehozásához és gyakoriságának következtetéséhez használt bemeneti adatok dátum/idő oszlopának megadására szolgál. |
forecast_horizon |
Meghatározza, hogy hány előrejelzendő időszakot szeretne előrejelesíteni. A horizont az idősor gyakoriságának egységében van. Az egységek a betanítási adatok időintervallumán alapulnak, például havonta, hetente, amelyet az előrejelzési szolgáltatónak előre kell jeleznie. |
Az alábbi kód:
- Az osztály használatával
ForecastingParametershatározza meg a kísérleti betanítás előrejelzési paramétereit - Beállítja a
time_column_namemezőt azday_datetimeadathalmazban. - A teljes tesztkészlet előrejelzéséhez állítsa be az
forecast_horizon50-et.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Ezeket forecasting_parameters a rendszer a feladattípussal, az elsődleges metrikával, a kilépési feltételekkel és a betanítási adatokkal együtt átadja a forecasting standard AutoMLConfig objektumnak.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Az előrejelzési modellek automatikus gépi tanulással történő sikeres betanításához szükséges adatok mennyiségét a forecast_horizonkonfiguráláskor AutoMLConfigmegadott , n_cross_validationsés target_lags target_rolling_window_size értékek befolyásolják.
Az alábbi képlet kiszámítja az idősor-funkciók létrehozásához szükséges előzményadatok mennyiségét.
Minimális előzményadatok: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Az adathalmaz bármely olyan adatsorára létrehozunk egy Error exception értéket, amely nem felel meg a megadott beállításokhoz szükséges előzményadatok mennyiségének.
A featurizáció lépései
Minden automatizált gépi tanulási kísérletben alapértelmezés szerint automatikus skálázási és normalizálási technikákat alkalmazunk az adatokra. Ezek a technikák olyan featurizációs típusok, amelyek segítenek bizonyos algoritmusoknak, amelyek érzékenyek a különböző skálázási funkciókra. További információ az AutoML-ben a Featurization alapértelmezett featurizációs lépéseiről
A következő lépéseket azonban csak a tevékenységtípusok esetében forecasting hajtja végre:
- Észlelheti az idősor minta gyakoriságát (például óránként, naponta, hetente), és új rekordokat hozhat létre a hiányzó időpontokhoz, hogy a sorozat folyamatos legyen.
- Hiányzó értékek impute in the target (via forward-fill) and feature columns (using medin column values)
- Idősor-azonosítókon alapuló szolgáltatások létrehozása a különböző sorozatok rögzített effektusainak engedélyezéséhez
- Időalapú funkciók létrehozása a szezonális minták tanulásához
- Kategorikus változók kódolása numerikus mennyiségekre
- Észleli a nem-esztétáris idősort, és automatikusan megkülönbözteti őket, hogy mérsékelje az egységgyökerek hatását.
Az idősoradatokból létrehozott lehetséges mérnöki funkciók teljes listájának megtekintéséhez tekintse meg a TimeIndexFeaturizer osztályt.
Feljegyzés
A gépi tanulás automatizált featurizálási lépései (funkció normalizálása, hiányzó adatok kezelése, szöveg numerikussá alakítása stb.) a mögöttes modell részévé válnak. Ha a modellt előrejelzésekhez használja, a betanítás során alkalmazott featurizációs lépések automatikusan a bemeneti adatokra lesznek alkalmazva.
A featurizáció testreszabása
Emellett testre is szabhatja a featurizációs beállításokat, hogy az ML-modell betanításához használt adatok és funkciók releváns előrejelzéseket eredményezhessenek.
A tevékenységek támogatott testreszabásai a forecasting következők:
| Testreszabás | Definíció |
|---|---|
| Oszlop rendeltetésének frissítése | A megadott oszlop automatikusan észlelt funkciótípusának felülbírálása. |
| Transzformátorparaméter frissítése | Frissítse a megadott transzformátor paramétereit. Jelenleg az Imputer (fill_value és medián) használatát támogatja. |
| Oszlopok elvetése | Megadja azokat az oszlopokat, amelyeket el szeretne dobni a featurizálástól. |
Ha az SDK-val szeretné testre szabni a featurizációkat, adja meg "featurization": FeaturizationConfig az AutoMLConfig objektumban. További információ az egyéni featurizációkról.
Feljegyzés
A drop columns funkció elavult az SDK 1.19-es verziójától. Az adathalmaz oszlopait az adattisztítás részeként csepegtetheti, mielőtt felhasználja azt az automatizált gépi tanulási kísérletben.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Ha az Azure Machine Learning Studiót használja a kísérlethez, tekintse meg , hogyan szabhatja testre a featurizációt a studióban.
Választható konfigurációk
További választható konfigurációk érhetők el az előrejelzési feladatokhoz, például a mélytanulás engedélyezéséhez és a célgördítő ablak összesítésének megadásához. További paraméterek teljes listája elérhető az ForecastingParameters SDK referenciadokumentációjában.
Gyakoriság > céladat-összesítés
Használja a gyakoriság paramétert a freqszabálytalan adatok által okozott hibák elkerüléséhez. A szabálytalan adatok olyan adatokat tartalmaznak, amelyek nem követik a megadott ütemet, például óránkénti vagy napi adatokat.
Rendkívül szabálytalan adatok vagy eltérő üzleti igények esetén a felhasználók igény szerint beállíthatják a kívánt előrejelzési gyakoriságukat, freqés megadhatja az target_aggregation_function idősor céloszlopának összesítését. Ha ezt a két beállítást használja az AutoMLConfig objektumban, azzal időt takaríthat meg az adatok előkészítésében.
A céloszlopértékek támogatott összesítési műveletei a következők:
| Függvény | Leírás |
|---|---|
sum |
Célértékek összege |
mean |
A célértékek középértéke vagy átlaga |
min |
Cél minimális értéke |
max |
Cél maximális értéke |
Mély tanulás engedélyezése
Feljegyzés
Az automatikus gépi tanulásban az előrejelzés DNN-támogatása előzetes verzióban érhető el, és nem támogatott a Databricksben kezdeményezett helyi futtatások vagy futtatások esetében.
A mély tanulást mély neurális hálózatokkal, DNN-ekkel is alkalmazhatja a modell pontszámainak javítása érdekében. Az automatizált gépi tanulás mély tanulása lehetővé teszi az egyváltozós és többváltozós idősorok adatainak előrejelzését.
A mélytanulási modellek három belső képességekkel rendelkeznek:
- A bemenetektől a kimenetekig tetszőleges leképezésekből tanulhatnak
- Több bemenetet és kimenetet támogatnak
- Automatikusan kinyerhetik a hosszú szekvenciákra kiterjedő bemeneti adatok mintáit.
A mély tanulás engedélyezéséhez állítsa be az enable_dnn=True AutoMLConfig objektumot.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Figyelmeztetés
Ha engedélyezi a DNN-t az SDK-val létrehozott kísérletekhez, a legjobb modellmagyarázatok le lesznek tiltva.
Ha engedélyezni szeretné a DNN-t az Azure Machine Learning Studióban létrehozott AutoML-kísérlethez, tekintse meg a studio felhasználói felületén található feladattípus-beállításokat.
Célgördítő ablak összesítése
Az előrejelzők számára gyakran a legjobb információ a cél legutóbbi értéke. A célgördítőablak-összesítések lehetővé teszik az adatértékek funkcióként való gördülő összesítését. Ezeknek a funkcióknak a létrehozása és használata további környezetfüggő adatokként segít a betanított modell pontosságában.
Tegyük fel például, hogy előre szeretné jelezni az energiaigényt. Érdemes lehet három napos gördülőablak-funkciót hozzáadni a fűtött terek hőváltozásainak figyelembe vételével. Ebben a példában a konstruktor beállításával target_rolling_window_size= 3 hozza létre ezt az AutoMLConfig ablakot.
A táblázat az ablak-összesítés alkalmazásakor létrejövő funkciófejlesztést mutatja be. A minimális, maximum és összeg oszlopai a megadott beállítások alapján háromból álló csúsztatási ablakban jönnek létre. Minden sor új számított funkcióval rendelkezik, a 2017. szeptember 8-i időbélyeg esetén 4:00-kor a maximális, a minimum- és az összegértékek kiszámítása a 2017. szeptember 8-án 1:00 és 15:00 között érvényes keresleti értékek alapján történik. Ez a három műszakból álló ablak a fennmaradó sorok adatainak feltöltéséhez.

A célgördítő ablak összesítési funkcióját alkalmazó Python-kód példájának megtekintése.
Rövid sorozatok kezelése
Az automatizált gépi tanulás rövid sorozatnak tekint egy idősort, ha nincs elegendő adatpont a modellfejlesztés betanítása és érvényesítési fázisainak elvégzéséhez. Az adatpontok száma minden kísérlet esetében eltérő, és függ a max_horizon, a keresztérvényesítési megosztások számától és a modellvisszatekintés hosszától, amely az idősor funkcióinak létrehozásához szükséges maximális előzmény.
Az automatizált gépi tanulás alapértelmezés szerint rövid sorozatkezelést biztosít az short_series_handling_configuration objektum paraméterével ForecastingParameters .
A rövid sorozatok kezelésének engedélyezéséhez a freq paramétert is meg kell határozni. Az óránkénti gyakoriság meghatározásához beállítjuk a következőt freq='H': A gyakorisági sztring beállításainak megtekintéséhez keresse fel a Pandas Time series page DataOffset objects szakaszt. Az alapértelmezett viselkedés short_series_handling_configuration = 'auto'módosításához frissítse a paramétert short_series_handling_configuration az ForecastingParameter objektumban.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Az alábbi táblázat a rendelkezésre álló beállításokat short_series_handling_configfoglalja össze.
| Beállítás | Leírás |
|---|---|
auto |
A rövid sorozatok kezelésének alapértelmezett értéke. - Ha az összes adatsor rövid, akkor az adatok kitöltése. - Ha nem minden sorozat rövid, ejtse el a rövid sorozatot. |
pad |
Ha short_series_handling_config = pad, akkor az automatizált gépi tanulás véletlenszerű értékeket ad hozzá az egyes talált rövid sorozatokhoz. Az alábbi lista felsorolja az oszloptípusokat és azokat, amelyekhez ki vannak osztva: - Objektumoszlopok naN-ekkel - Numerikus oszlopok 0-val - Logikai/logikai oszlopok hamis értékkel - A céloszlopot véletlenszerű értékekkel, nulla középértékkel és 1 szórással kell kipárnázni. |
drop |
Ha short_series_handling_config = drop, akkor az automatizált gépi tanulás elveti a rövid sorozatot, és nem használható betanításra vagy előrejelzésre. A sorozat előrejelzései a NaN-eket adják vissza. |
None |
Egyetlen sorozat sem van kipárnázva vagy elvetve |
Figyelmeztetés
A padding hatással lehet az eredményül kapott modell pontosságára, mivel csak azért vezetünk be mesterséges adatokat, hogy hiba nélkül lekérjük a betanítást. Ha a sorozat nagy része rövid, akkor a magyarázhatósági eredményekre is hatással lehet
Nemstationáris idősorok észlelése és kezelése
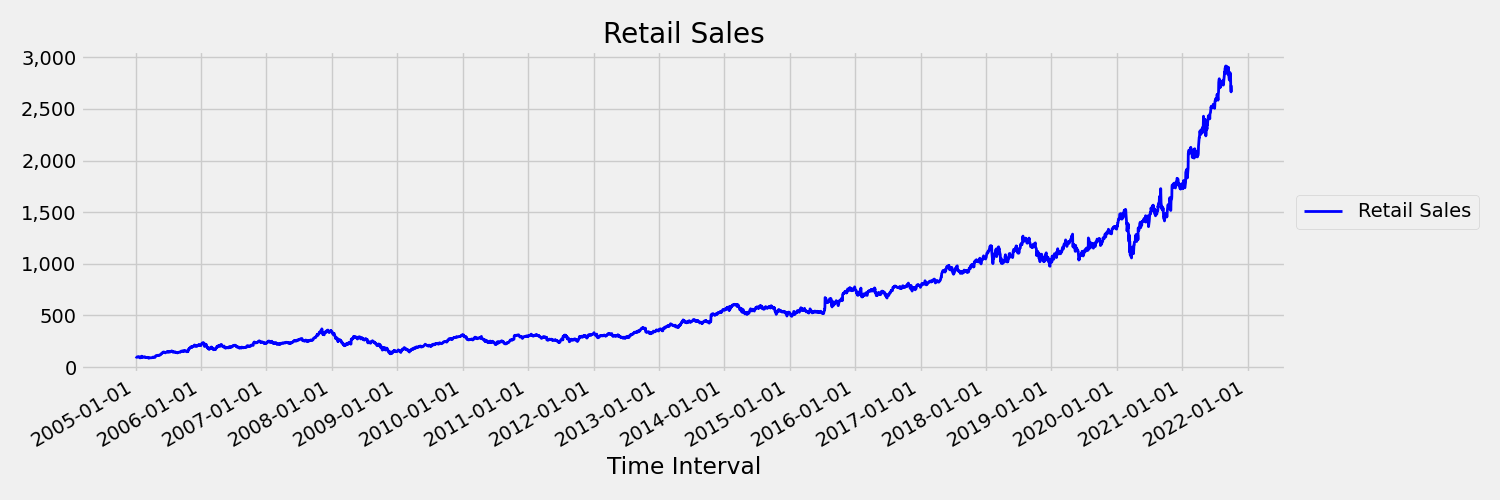
Az idősort, amelynek pillanatai (középérték és variancia) az idő függvényében változnak, nem helyhez kötöttnek nevezzük. A sztochasztikus trendeket megjelenítő idősorok például természet szerint nem helyhez kötöttek. Ennek vizualizációja érdekében az alábbi kép egy általában felfelé növekvő sorozatot ábrázol. Most számítsa ki és hasonlítsa össze az adatsor első és második felének átlagértékét. Ugyanazok? Itt a sorozat középértéke a diagram első felében kisebb, mint a második felében. Az a tény, hogy az adatsor átlaga az adott időintervallumtól függ, az idő függvényében változó pillanatok példája. Itt, a középérték egy sorozat az első pillanat.
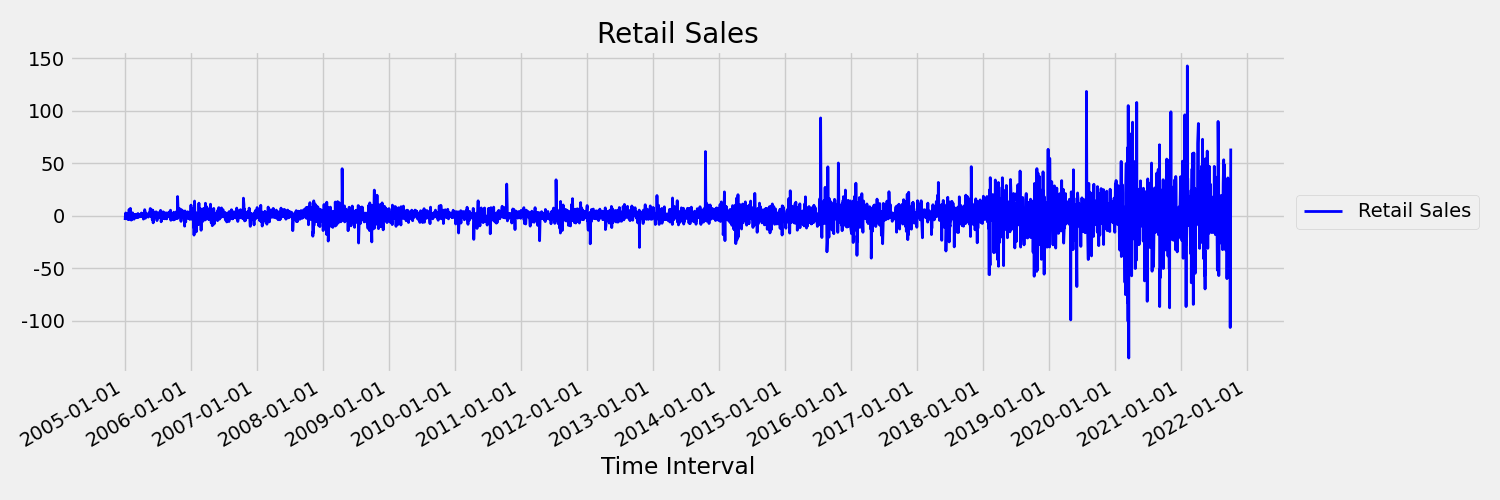
Ezután vizsgáljuk meg a képet, amely az eredeti sorozatot ábrázolja az első különbségekben, $x_t = y_t - y_{t-1}$ ahol $x_t$ a kiskereskedelmi értékesítések változása, és $y_t$ és $y_{t-1}$ az eredeti sorozatot és annak első késését jelöli. A sorozat középértéke nagyjából állandó, függetlenül attól, hogy milyen időkeretet nézünk. Ez egy példa egy elsőrendű helyhez kötött idősorra. Azért adtuk hozzá az első rendelési kifejezést, mert az első pillanat (középérték) nem változik az időintervallummal, ugyanez nem mondható el a varianciáról, ami egy második pillanat.
Az AutoML Gépi tanulási modellek nem tudják kezelni a sztochasztikus trendeket, vagy a nem helyhez kötött idősorokhoz kapcsolódó egyéb jól ismert problémákat. Ennek eredményeképpen a minta előrejelzési pontossága "gyenge", ha ilyen trendek vannak jelen.
Az AutoML automatikusan elemzi az idősor-adatkészletet annak ellenőrzéséhez, hogy az álló-e vagy sem. A nem helyhez kötött idősorok észlelésekor az AutoML automatikusan alkalmaz különbség-átalakítást a nem helyhez kötött idősorok hatásának mérséklésére.
Kísérlet futtatása
Ha elkészült az AutoMLConfig objektum, elküldheti a kísérletet. A modell befejezése után kérje le a legjobb futtatási iterációt.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Előrejelzés a legjobb modellel
A modell legjobb iterációjával előre jelezheti a modell betanításához nem használt adatok értékeit.
Modell pontosságának kiértékelése gördülő előrejelzéssel
Mielőtt éles környezetbe helyeznénk a modellt, értékeljük a pontosságát a betanítási adatokból tartott tesztkészleten. Az ajánlott eljárás egy úgynevezett gördülő értékelés, amely előregörgeti a betanított előrejelzőt a tesztkészleten, és több előrejelzési ablakban átlagolja a hibametrikákat, hogy statisztikailag robusztus becsléseket kapjon bizonyos kiválasztott metrikákhoz. Ideális esetben az értékelés tesztkészlete hosszú a modell előrejelzési horizontjának megfelelően. Az előrejelzési hiba becslése egyébként statisztikailag zajos lehet, ezért kevésbé megbízható.
Tegyük fel például, hogy betanít egy modellt a napi értékesítésekre, hogy a jövőben akár két hétre (14 napra) előre jelezhesse a keresletet. Ha elegendő előzményadat áll rendelkezésre, előfordulhat, hogy az utolsó néhány hónapot a tesztkészlet adatainak egy évére is fenntartja. A gördülő értékelés egy 14 napos előrejelzés létrehozásával kezdődik a tesztkészlet első két hetére vonatkozóan. Ezután az előrejelzőt néhány nappal előrehaladtával a tesztkészletbe helyezi, és az új pozícióból egy újabb 14 napos előrejelző előrejelzést hoz létre. A folyamat addig folytatódik, amíg el nem ér a tesztkészlet végére.
A gördülő értékeléshez meghívja a rolling_forecast metódust fitted_model, majd kiszámítja a kívánt metrikákat az eredményen. Tegyük fel például, hogy a pandas DataFrame-ben van tesztkészlet-funkciója, a cél tényleges értékei pedig egy numpy tömbben vannak meghívva test_features_df test_target. A középérték négyzetes hibát használó gördülő kiértékelés az alábbi kódmintában látható:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
Ebben a mintában a gördülő előrejelzés lépésmérete egyre van állítva, ami azt jelenti, hogy az előrejelzés előrehaladtával minden iterációban egy vagy egy nap áll elő az igény előrejelzési példájában. Az így visszaadott rolling_forecast előrejelzések teljes száma a tesztkészlet hosszától és a lépés méretétől függ. További részletekért és példákért tekintse meg a rolling_forecast() dokumentációját és az előrejelzést a betanítási adatjegyzetfüzetből.
Előrejelzés a jövőbe
A forecast_quantiles() függvény lehetővé teszi, hogy az előrejelzések mikor kezdődjenek, ellentétben a predict() módszerrel, amelyet általában a besorolási és regressziós feladatokhoz használnak. A forecast_quantiles() módszer alapértelmezés szerint pont-előrejelzést vagy közép/medián előrejelzést hoz létre, amely körül nincs bizonytalansági kúp. További információ az előrejelzésről a betanítási adatjegyzetfüzettől távol.
Az alábbi példában először az összes értéket lecseréli a y_pred következőre NaN: Az előrejelzés forrása ebben az esetben a betanítási adatok végén van. Ha azonban csak a második felét y_pred NaNcseréli le, a függvény az első felében változatlanul hagyja a numerikus értékeket, de a második felében előrejelezi az NaN értékeket. A függvény az előrejelzett értékeket és az igazított szolgáltatásokat is visszaadja.
A függvény paraméterével forecast_destination előre jelezheti az forecast_quantiles() értékeket egy megadott dátumig.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Az ügyfelek gyakran meg szeretnék érteni az előrejelzéseket az eloszlás egy adott kvantitására vonatkozóan. Ha például az előrejelzést a készlet szabályozására használják, például élelmiszerboltokat vagy virtuális gépeket egy felhőszolgáltatáshoz. Ilyen esetekben az ellenőrzési pont általában a következőhöz hasonló: "azt szeretnénk, hogy az elem raktáron legyen, és ne fogyjon el az idő 99%-a". Az alábbiak bemutatják, hogyan adhatja meg, hogy mely kvantiliseket szeretné megtekinteni az előrejelzésekhez, például az 50. vagy a 95. percentilishez. Ha nem ad meg kvantilist, például a fent említett kód példájában, akkor csak az 50. percentilis előrejelzések jönnek létre.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
A modell teljesítményének becsléséhez kiszámíthatja a modellmetrikákat, például a fő középérték négyzetes hibát (RMSE) vagy az abszolút százalékos középértéket (MAPE). Példaként tekintse meg a Kerékpármegosztási igény jegyzetfüzet Kiértékelése szakaszát.
A modell teljes pontosságának meghatározása után a legreálisabb következő lépés az ismeretlen jövőbeli értékek előrejelzése a modell használatával.
Adjon meg egy adathalmazt a tesztkészlettel test_dataset megegyező formátumban, de a jövőbeli dátumidőkkel együtt, és az eredményként kapott előrejelzési csoport az egyes idősoros lépések előrejelzett értékei. Tegyük fel, hogy az adathalmaz utolsó idősorrekordja 2018. 12. 31. volt. Ha a következő napra (vagy az előrejelzéshez szükséges számú időszakra) szeretné előrejelezni a keresletet, <forecast_horizonhozzon létre egyetlen idősorrekordot az egyes áruházakhoz 2019. 01. 01- hez.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Ismételje meg a szükséges lépéseket a jövőbeli adatok adatkeretbe való betöltéséhez, majd futtassa best_run.forecast_quantiles(test_dataset) a jövőbeli értékek előrejelzéséhez.
Feljegyzés
A mintában szereplő előrejelzések nem támogatottak az automatizált gépi tanulással való előrejelzéshez, ha target_lags és/vagy target_rolling_window_size engedélyezve vannak.
Nagy léptékű előrejelzés
Vannak olyan helyzetek, amikor egyetlen gépi tanulási modell nem elegendő, és több gépi tanulási modellre van szükség. Például az egyes áruházak értékesítésének előrejelzése egy márkához, vagy egy felhasználói élmény személyre szabása. Az egyes példányokhoz tartozó modellek létrehozása számos gépi tanulási probléma jobb eredményéhez vezethet.
A csoportosítás az idősor-előrejelzés egyik fogalma, amely lehetővé teszi az idősorok kombinálását, hogy csoportonként betanítsa az egyes modelleket. Ez a megközelítés különösen hasznos lehet, ha olyan idősorokkal rendelkezik, amelyek simítást, kitöltést vagy entitásokat igényelnek a csoportban, amelyek kihasználhatják más entitások előzményeit vagy trendjeit. Számos modell és hierarchikus idősor-előrejelzés automatizált gépi tanulással működő megoldások ezekhez a nagy léptékű előrejelzési forgatókönyvekhez.
Számos modell
Az Azure Machine Learning számos modellmegoldása automatizált gépi tanulással lehetővé teszi a felhasználók számára több millió modell párhuzamos betanítása és kezelése. Számos modell A megoldásgyorsító Azure Machine Learning-folyamatokat használ a modell betanításához. Pontosabban egy folyamatobjektumot és a ParalleRunStepet használjuk, és a ParallelRunConfigon keresztül meghatározott konfigurációs paramétereket igényelünk.
Az alábbi ábra a számos modellmegoldás munkafolyamatát mutatja be.

Az alábbi kód bemutatja, hogy a felhasználóknak hány modell futtatásához kell beállítaniuk a legfontosabb paramétereket. Tekintse meg a Több modell – Automatizált gépi tanulási jegyzetfüzetet számos modell előrejelzési példájához
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Hierarchikus idősor-előrejelzés
A legtöbb alkalmazásban az ügyfeleknek meg kell érteniük az előrejelzéseiket a vállalat makró- és mikroszintjén. Az előrejelzések előre jelezhetik a termékek különböző földrajzi helyeken történő értékesítését, vagy megérthetik a vállalat különböző szervezeteinek várható munkaerőigényét. A gépi tanulási modellek betanítása elengedhetetlen a hierarchiaadatok intelligens előrejelzéséhez.
A hierarchikus idősorok olyan szerkezetek, amelyekben az egyes egyedi sorozatok egy hierarchiába vannak rendezve dimenziók, például földrajzi hely vagy terméktípus alapján. Az alábbi példa egy hierarchiát alkotó egyedi attribútumokkal rendelkező adatokat mutat be. A hierarchiát a következők határozzák meg: a terméktípus, például a fejhallgató vagy a táblagép, a termékkategória, amely a terméktípusokat tartozékokra és eszközökre osztja, valamint a termékek értékesítési régióját.

Ennek további szemléltetéséhez a hierarchia levélszintjei az összes idősort tartalmazzák az attribútumértékek egyedi kombinációival. A hierarchia minden magasabb szintje egy kisebb dimenziót figyelembe veszi az idősor meghatározásához, és összesíti az egyes gyermekcsomópontok készleteit az alsó szintről egy szülőcsomópontba.

A hierarchikus idősoros megoldás a Számos modell megoldásra épül, és hasonló konfigurációs beállításokat használ.
Az alábbi kód bemutatja a hierarchikus idősor-előrejelzési futtatások beállításának legfontosabb paramétereit. A teljes körű példaért tekintse meg a hierarchikus idősor automatizált gépi tanulási jegyzetfüzetét.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Példajegyzetfüzetek
Tekintse meg az előrejelzési mintanotebookokat, amelyekben részletes kódpéldákat találhat az előrejelzési konfigurációkra, például a következőkre:
- ünnepészlelés és jellemzőkre bontás
- gördülő kiindulópont keresztellenőrzése
- konfigurálható késés
- görgő ablakösszesítési szolgáltatások
Következő lépések
- További információ az AutoML-modellek online végponton való üzembe helyezéséről.
- Tudnivalók az értelmezhetőségről : modellmagyarázatok az automatizált gépi tanulásban (előzetes verzió).
- Ismerje meg, hogyan építi ki az AutoML az előrejelzési modelleket.