Gépi tanulási folyamatok létrehozása és futtatása összetevők használatával az Azure Machine Learning parancssori felületével
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)
Ebben a cikkben megtudhatja, hogyan hozhat létre és futtathat gépi tanulási folyamatokat az Azure CLI és az összetevők használatával. A folyamatokat összetevők használata nélkül is létrehozhatja, de az összetevők a legnagyobb rugalmasságot és újrafelhasználást biztosítják. Az Azure Machine Learning Pipelines a YAML-ben definiálható, és a parancssori felületről futtatható, Pythonban készült, vagy az Azure Machine Learning Studio Designerben áll össze húzással. Ez a dokumentum a parancssori felületre összpontosít.
Előfeltételek
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot. Próbálja ki az Azure Machine Learning ingyenes vagy fizetős verzióját.
Egy Azure Machine Learning-munkaterület. Munkaterületi erőforrások létrehozása.
Telepítse és állítsa be a Machine Learninghez készült Azure CLI-bővítményt.
Klónozza a példák adattárát:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Javasolt előolvasás
Az első folyamat létrehozása összetevővel
Hozzuk létre az első folyamatot összetevőkkel egy példa használatával. Ez a szakasz egy konkrét példán keresztül bemutatja, hogyan néz ki egy folyamat és összetevő az Azure Machine Learningben.
cli/jobs/pipelines-with-components/basics Az adattár könyvtárábólazureml-examples keresse meg az 3b_pipeline_with_data alkönyvtárat. Ebben a könyvtárban három fájltípus létezik. Ezeket a fájlokat kell létrehoznia a saját folyamat létrehozásakor.
pipeline.yml: Ez a YAML-fájl határozza meg a gépi tanulási folyamatot. Ez a YAML-fájl bemutatja, hogyan lehet egy teljes gépi tanulási feladatot többhelyes munkafolyamattá bontani. Ha például egy értékesítési előrejelzési modell betanítására szolgáló előzményadatok egyszerű gépi tanulási feladatát veszi figyelembe, érdemes lehet egy szekvenciális munkafolyamatot létrehozni adatfeldolgozási, modellbetanítási és modellértékelési lépésekkel. Minden lépés egy jól definiált felülettel rendelkező összetevő, amely egymástól függetlenül fejleszthető, tesztelhető és optimalizálható. A yaml folyamat azt is meghatározza, hogy a gyermeklépések hogyan csatlakoznak a folyamat más lépéseihez, például a modell betanítási lépése létrehoz egy modellfájlt, és a modellfájl egy modellértékelési lépésnek lesz átadva.
component.yml: Ez a YAML-fájl határozza meg az összetevőt. A következő információkat tartalmazza:
- Metaadatok: név, megjelenítendő név, verzió, leírás, típus stb. A metaadatok segítenek az összetevő leírásában és kezelésében.
- Interfész: bemenetek és kimenetek. A modellbetanítási összetevő például bemenetként veszi a betanítási adatokat és a korszakok számát, és kimenetként létrehoz egy betanított modellfájlt. A felület definiálása után a különböző csapatok egymástól függetlenül fejleszthetik és tesztelhetik az összetevőt.
- Parancs, kód > környezet: az összetevő futtatásához szükséges parancs, kód és környezet. A parancs az összetevő végrehajtására szolgáló rendszerhéj-parancs. A kód általában egy forráskódkönyvtárra hivatkozik. A környezet lehet Azure Machine Learning-környezet (válogatott vagy ügyfél által létrehozott), Docker-rendszerkép vagy Conda-környezet.
component_src: Ez egy adott összetevő forráskódkönyvtára. Az összetevőben végrehajtott forráskódot tartalmazza. Használhatja az előnyben részesített nyelvet (Python, R...). A kódot egy rendszerhéjparancsnak kell végrehajtania. A forráskód a rendszerhéj parancssorából adhat néhány bemenetet a lépés végrehajtásának szabályozásához. Egy betanítási lépés lehet például a betanítási adatok, a tanulási arány, a képzési folyamat szabályozásához szükséges korszakok száma. A rendszerhéjparancs argumentumával bemeneteket és kimeneteket ad át a kódnak.
Most hozzunk létre egy folyamatot a példával 3b_pipeline_with_data . Az egyes fájlok részletes jelentését a következő szakaszokban ismertetjük.
Először sorolja fel az elérhető számítási erőforrásokat a következő paranccsal:
az ml compute list
Ha nem rendelkezik vele, hozzon létre egy fürtöt cpu-cluster a következő futtatásával:
Feljegyzés
Hagyja ki ezt a lépést a kiszolgáló nélküli számítás használatához.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Most hozzon létre egy folyamatfeladatot a pipeline.yml fájlban az alábbi paranccsal. A számítási célra a pipeline.yml fájlban a következőként hivatkozik azureml:cpu-cluster: . Ha a számítási cél más nevet használ, ne felejtse el frissíteni a pipeline.yml fájlban.
az ml job create --file pipeline.yml
A folyamatfeladattal kapcsolatos információkat tartalmazó JSON-szótárt kell kapnia, beleértve a következőket:
| Kulcs | Leírás |
|---|---|
name |
A feladat GUID-alapú neve. |
experiment_name |
Az a név, amely alatt a feladatok a studióban lesznek rendszerezve. |
services.Studio.endpoint |
A folyamatfeladat figyelésére és áttekintésére szolgáló URL-cím. |
status |
A feladat állapota. Ez valószínűleg ezen a ponton lesz Preparing . |
Nyissa meg az services.Studio.endpoint URL-címet a folyamat gráfvizualizációjának megtekintéséhez.
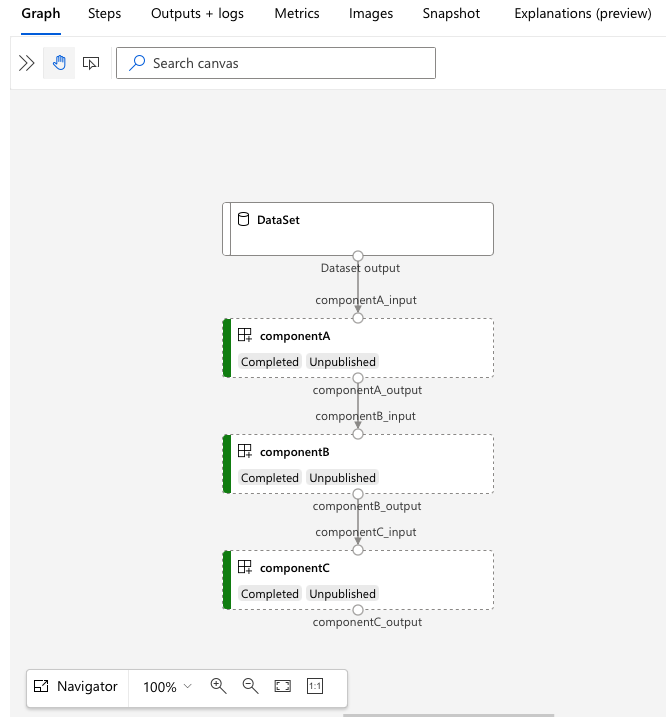
A folyamatdefiníció YAML-jének ismertetése
Tekintsük meg a folyamatdefiníciót a 3b_pipeline_with_data/pipeline.yml fájlban.
Feljegyzés
A kiszolgáló nélküli számítás használatához cserélje le default_compute: azureml:cpu-cluster default_compute: azureml:serverless ezt a fájlt.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
A táblázat a folyamat YAML-sémájának leggyakrabban használt mezőit ismerteti. További információkért tekintse meg a teljes folyamat YAML-sémáját.
| kulcs | leírás |
|---|---|
| típus | Kötelező. A feladattípusnak folyamatfeladatokhoz kell lennie pipeline . |
| display_name | A folyamatfeladat megjelenítendő neve a studio felhasználói felületén. Szerkeszthető a studio felhasználói felületén. Nem kell egyedinek lennie a munkaterület összes feladatában. |
| Munkahelyek | Kötelező. A folyamaton belüli lépésekként futtatandó egyes feladatok szótára. Ezek a feladatok a szülőfolyamat-feladat gyermekfeladatainak minősülnek. Ebben a kiadásban a folyamat támogatott feladattípusai a command következők: sweep |
| Bemenetek | A folyamatfeladat bemeneteinek szótára. A kulcs a feladat környezetében lévő bemenet neve, az érték pedig a bemeneti érték. Ezekre a folyamatbemenetekre a folyamat egyes lépésfeladatainak bemenetei hivatkozhatnak a ${{ parent.inputs használatával.<> input_name }} kifejezés. |
| Kimenetek | A folyamatfeladat kimeneti konfigurációinak szótára. A kulcs a feladat környezetében lévő kimenet neve, az érték pedig a kimeneti konfiguráció. Ezekre a folyamatkimenetekre hivatkozhat a folyamat egyes lépésfeladatainak kimenetei a ${{ parents.outputs használatával.<> output_name }} kifejezés. |
A 3b_pipeline_with_data példában három lépésből álló folyamatot hoztunk létre.
- A három lépés a következő alatt van definiálva
jobs: . Mindhárom lépéstípus parancsfeladat. Minden lépés definíciója a megfelelőcomponent.ymlfájlban található. Az összetevő YAML-fájljai 3b_pipeline_with_data könyvtárban láthatók. A componentA.yml a következő szakaszban ismertetjük. - Ez a folyamat adatfüggőséggel rendelkezik, ami a legtöbb valós folyamatban gyakori. Component_a a helyi mappából
./data(17–20. sor) származó adatbevitelt veszi át, és a kimenetét átadja a componentB -nek (29. sor). Component_a kimenete a következőként${{parent.jobs.component_a.outputs.component_a_output}}hivatkozhat: . - Ez
computehatározza meg a folyamat alapértelmezett számítását. Ha egy összetevő másjobsszámítást határoz meg ehhez az összetevőhöz, a rendszer tiszteletben tartja az összetevő-specifikus beállítást.

Adatok olvasása és írása folyamatban
Az egyik gyakori forgatókönyv az adatok olvasása és írása a folyamatban. Az Azure Machine Learningben ugyanazt a sémát használjuk minden típusú feladat (folyamatfeladat, parancsfeladat és takarítási feladat) adatainak olvasásához és írásához. Az alábbiakban folyamatfeladat-példákat láthat az adatok gyakori forgatókönyvekhez való használatára.
- helyi adatok
- nyilvános URL-címmel rendelkező webfájl
- Azure Machine Learning-adattár és elérési út
- Azure Machine Learning-adategység
A YAML összetevődefiníciójának ismertetése
Most tekintsük meg példaként a componentA.yml a YAML összetevődefiníciójának megértéséhez.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
A YAML összetevő leggyakrabban használt sémáját a táblázat ismerteti. További információkért tekintse meg a teljes yaML-sémát.
| kulcs | leírás |
|---|---|
| név | Kötelező. Az összetevő neve. Az Azure Machine Learning-munkaterületen egyedinek kell lennie. Kisbetűvel kell kezdődnie. Kisbetűk, számok és aláhúzásjel(_) engedélyezése. A maximális hossz 255 karakter. |
| display_name | Az összetevő megjelenítendő neve a studio felhasználói felületén. A munkaterületen belül nem alkalmazható. |
| command | A parancs végrehajtásához szükséges |
| code | A feltöltendő és az összetevőhöz használt forráskódkönyvtár helyi elérési útja. |
| környezet | Kötelező. Az összetevő végrehajtásához használt környezet. |
| Bemenetek | Az összetevők bemeneteinek szótára. A kulcs az összetevő környezetében lévő bemenet neve, az érték pedig az összetevő bemeneti definíciója. A bemenetek a ${{ bemenetek használatával hivatkozhatók a parancsban.<> input_name }} kifejezés. |
| Kimenetek | Az összetevők kimeneteinek szótára. A kulcs az összetevő környezetében lévő kimenet neve, az érték pedig az összetevő kimeneti definíciója. A kimenetek a ${{ kimenetek használatával hivatkozhatók a parancsban.<> output_name }} kifejezés. |
| is_deterministic | Az előző feladat eredményének újbóli felhasználása, ha az összetevő bemenetei nem változnak. Az alapértelmezett érték az trueúgynevezett újrahasználat alapértelmezés szerint. Az adatok felhőbeli tárolóból vagy URL-címről való újrabetöltésének kényszerítése a beállításnál false gyakori forgatókönyv. |
A 3b_pipeline_with_data/componentA.yml példában a ComponentA egy adatbemenettel és egy adatkimenettel rendelkezik, amely a szülőfolyamat más lépéseihez is csatlakoztatható. A YAML összetevő szakaszában található code összes fájl fel lesz töltve az Azure Machine Learningbe a folyamatfeladat elküldésekor. Ebben a példában a program feltölti az alatta lévő ./componentA_src fájlokat (componentA.yml 16. sora). A feltöltött forráskód megjelenik a Studio felhasználói felületén: válassza duplán a ComponentA lépést, és lépjen a Pillanatkép lapra az alábbi képernyőképen látható módon. Láthatjuk, hogy ez egy hello-world szkript, amely csak egy egyszerű nyomtatást végez, és az aktuális dátumidőt írja az componentA_output elérési útra. Az összetevő parancssori argumentumon keresztül veszi át a bemenetet és a kimenetet, és a hello.py kezeliargparse.

Bemenet és kimenet
A bemenet és a kimenet határozza meg egy összetevő interfészét. A bemenet és a kimenet lehet literálérték(típusstring,numberinteger vagy boolean) vagy bemeneti sémát tartalmazó objektum.
Az objektumbemenet (típusuri_folderuri_file, ,mltable,mlflow_model,custom_model) csatlakozhat a szülőfolyamat-feladat más lépéseihez, és így adatokat/modellt továbbíthat más lépéseknek. A folyamatdiagramon az objektumtípus bemenete kapcsolati pontként jelenik meg.
A konstans értékbemenetek (string,number,integerboolean) azok a paraméterek, amelyeket futtatáskor átadhat az összetevőnek. A mező alatt default hozzáadhatja a literális bemenetek alapértelmezett értékét. A number beíráshoz integer az elfogadott érték minimális és maximális értékét is hozzáadhatja a mezők és max a mezők használatávalmin. Ha a bemeneti érték meghaladja a minimális és a maximális értéket, a folyamat az ellenőrzés során meghiúsul. Az ellenőrzés a folyamatfeladat elküldése előtt történik, hogy időt takarítson meg. Az ellenőrzés a CLI, a Python SDK és a tervező felhasználói felülete esetében működik. Az alábbi képernyőképen egy érvényesítési példa látható a tervező felhasználói felületén. Hasonlóképpen megadhatja az engedélyezett értékeket a enum mezőben.

Ha bemenetet szeretne hozzáadni egy összetevőhöz, ne felejtse el szerkeszteni a három helyet:
inputsmező a YAML összetevőbencommandelemet a YAML összetevőben.- Összetevő forráskódja a parancssori bemenet kezeléséhez. Az előző képernyőképen zöld mezőben van megjelölve.
A bemenetekről és kimenetekről további információt az összetevő és a folyamat bemeneteinek és kimeneteinek kezelése című témakörben talál.
Környezet
A környezet határozza meg az összetevő végrehajtásához szükséges környezetet. Ez lehet egy Azure Machine Learning-környezet (válogatott vagy egyénileg regisztrált), Docker-rendszerkép vagy Conda-környezet. Tekintse meg az alábbi példákat.
- Az Azure Machine Learning regisztrált környezeti objektuma. Az összetevő a következő
azureml:<environment-name>:<environment-version>szintaxisban hivatkozik rá. - nyilvános Docker-rendszerkép
- A Conda-fájlt egy alaprendszerképpel együtt kell használni.
Összetevő regisztrálása újrafelhasználáshoz és megosztáshoz
Míg egyes összetevők egy adott folyamatra vonatkoznak, az összetevők valódi előnye az újrafelhasználás és a megosztás. Regisztráljon egy összetevőt a Machine Learning-munkaterületen, hogy újra felhasználható legyen. A regisztrált összetevők támogatják az automatikus verziószámozást, így frissítheti az összetevőt, de biztosíthatja, hogy a régebbi verziót igénylő folyamatok továbbra is működni fognak.
Az azureml-examples adattárban keresse meg a cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components könyvtárat.
Összetevő regisztrálásához használja a az ml component create következő parancsot:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
A parancsok befejeződése után az összetevők a Studio Eszköz –> Összetevők területén láthatók:

Válasszon ki egy összetevőt. Az összetevő minden verziójára vonatkozó részletes információk láthatók.
A Részletek lapon láthatja az összetevő olyan alapvető adatait, mint a név, a létrehozott, a verzió stb. A Címkék és leírás szerkeszthető mezői láthatók. A címkék gyorsan kereshető kulcsszavak hozzáadására használhatók. A leírásmező támogatja a Markdown-formázást, és az összetevő funkcióinak és alapszintű használatának leírására használható.
A Feladatok lapon láthatja az összetevőt használó összes feladat előzményeit.
Regisztrált összetevők használata folyamatfeladat YAML-fájljában
Használjuk 1b_e2e_registered_components a regisztrált összetevők yaML-ben való használatát bemutató bemutatót. Lépjen a könyvtárra 1b_e2e_registered_components , és nyissa meg a pipeline.yml fájlt. A kulcsok és értékek a inputs outputs már tárgyaltakhoz hasonlóak. Az egyetlen jelentős különbség a mező értéke component a jobs.<JOB_NAME>.component tételekben. Az component érték az űrlapon azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>van. A train-job definíció például a regisztrált összetevő my_train legújabb verzióját határozza meg:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Összetevők kezelése
Ellenőrizheti az összetevők részleteit, és kezelheti az összetevőt a parancssori felület (v2) használatával. Az összetevő-parancs részletes utasításainak lekérésére használható az ml component -h . Az alábbi táblázat az összes elérhető parancsot felsorolja. További példák az Azure CLI-referenciaban.
| parancsok | leírás |
|---|---|
az ml component create |
Összetevő létrehozása |
az ml component list |
Összetevők listázása munkaterületen |
az ml component show |
Összetevő részleteinek megjelenítése |
az ml component update |
Összetevő frissítése. Csak néhány mező (leírás, display_name) támogatása |
az ml component archive |
Összetevőtároló archiválása |
az ml component restore |
Archivált összetevő visszaállítása |
Következő lépések
- Példa a CLI v2 összetevő kipróbálására