Gépi tanulási folyamatok létrehozása és futtatása összetevők használatával az Azure Machine Learning Studióval
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)
Ebben a cikkben megtanulhatja, hogyan hozhat létre és futtathat gépi tanulási folyamatokat az Azure Machine Learning Studióval és -összetevőkkel. A folyamatokat összetevők használata nélkül is létrehozhatja, de az összetevők nagyobb rugalmasságot és újrafelhasználást biztosítanak. Az Azure Machine Learning Pipelines a YAML-ben definiálható, és a parancssori felületről futtatható, Pythonban készült, vagy az Azure Machine Learning Studio Designerben áll össze húzással. Ez a dokumentum az Azure Machine Learning Studio tervezői felhasználói felületére összpontosít.
Előfeltételek
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot. Próbálja ki az Azure Machine Learning ingyenes vagy fizetős verzióját.
Azure Machine Learning-munkaterület munkaterületi erőforrások létrehozása.
Telepítse és állítsa be a Machine Learninghez készült Azure CLI-bővítményt.
Klónozza a példák adattárát:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Feljegyzés
A Tervező kétféle összetevőt támogat, a klasszikus előre összeállított összetevőket (v1) és az egyéni összetevőket (v2). Ez a két összetevőtípus NEM kompatibilis.
A klasszikus előre összeállított összetevők elsősorban az adatfeldolgozáshoz és a hagyományos gépi tanulási feladatokhoz, például a regresszióhoz és a besoroláshoz biztosítanak előre összeállított összetevőket. A klasszikus előre összeállított összetevők továbbra is támogatottak, de új összetevők nem lesznek hozzáadva. Emellett a klasszikus előre összeállított (v1) összetevők üzembe helyezése nem támogatja a felügyelt online végpontokat (v2).
Az egyéni összetevők lehetővé teszik, hogy a saját kódját összetevőként csomagolja. Támogatja az összetevők munkaterületek közötti megosztását és a közvetlen létrehozást a stúdió, a CLI v2 és az SDK v2-felületeken.
Új projektek esetén javasoljuk, hogy egyéni összetevőt használjon, amely kompatibilis az AzureML V2-vel, és folyamatosan új frissítéseket fog kapni.
Ez a cikk egyéni összetevőkre vonatkozik.
Összetevő regisztrálása a munkaterületen
Ahhoz, hogy a folyamat összetevőket használjon a felhasználói felületen, először regisztrálnia kell az összetevőket a munkaterületen. A felhasználói felület, a parancssori felület vagy az SDK használatával regisztrálhatja az összetevőket a munkaterületen, így megoszthatja és újra felhasználhatja az összetevőt a munkaterületen belül. A regisztrált összetevők támogatják az automatikus verziószámozást, így frissítheti az összetevőt, de biztosíthatja, hogy a régebbi verziót igénylő folyamatok továbbra is működjenek.
Az alábbi példa felhasználói felületen regisztrálja az összetevőket, és az összetevő forrásfájljai azazureml-examples cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components adattár könyvtárában találhatók. Először klónoznia kell az adattárat a helyire.
- Az Azure Machine Learning-munkaterületen lépjen az Összetevők lapra, és válassza az Új összetevő lehetőséget (a két stíluslap egyike megjelenik).


Ez a példa a címtárban található train.yml . A YAML-fájl határozza meg az összetevő nevét, típusát, felületét, beleértve a bemeneteket és kimeneteket, a kódot, a környezetet és az összetevő parancsát. Az összetevő train.py kódja a mappa alatt ./train_src található, amely az összetevő végrehajtási logikáját írja le. Az összetevősémával kapcsolatos további információkért tekintse meg a parancsösszetevő YAML-sémareferenciáját.
Feljegyzés
Ha összetevőket regisztrál a felhasználói felületen, code az összetevő YAML-fájljában meghatározottak csak arra a mappára mutathatnak, amelyben a YAML-fájl található vagy az almappák, ami azt jelenti, hogy nem adható meg ../ code , mert a felhasználói felület nem ismeri fel a szülőkönyvtárat.
additional_includes csak az aktuális vagy almappára mutathat.
A felhasználói felület jelenleg csak típussal command támogatja az összetevők regisztrálását.
- Válassza a Feltöltés mappából lehetőséget, és válassza ki a
1b_e2e_registered_componentsfeltölteni kívánt mappát. Válasszontrain.ymla legördülő listából.

Kattintson a Tovább gombra az alján, és megerősítheti ennek az összetevőnek a részleteit. Miután megerősítette, válassza a Létrehozás lehetőséget a regisztrációs folyamat befejezéséhez.
Ismételje meg az előző lépéseket a Score és az Eval összetevő regisztrálásához és használatával
score.ymleval.ymlis.A három összetevő sikeres regisztrálása után az összetevők megjelennek a studio felhasználói felületén.

Folyamat létrehozása regisztrált összetevővel
Hozzon létre egy új folyamatot a tervezőben. Ne felejtse el kiválasztani az Egyéni lehetőséget.
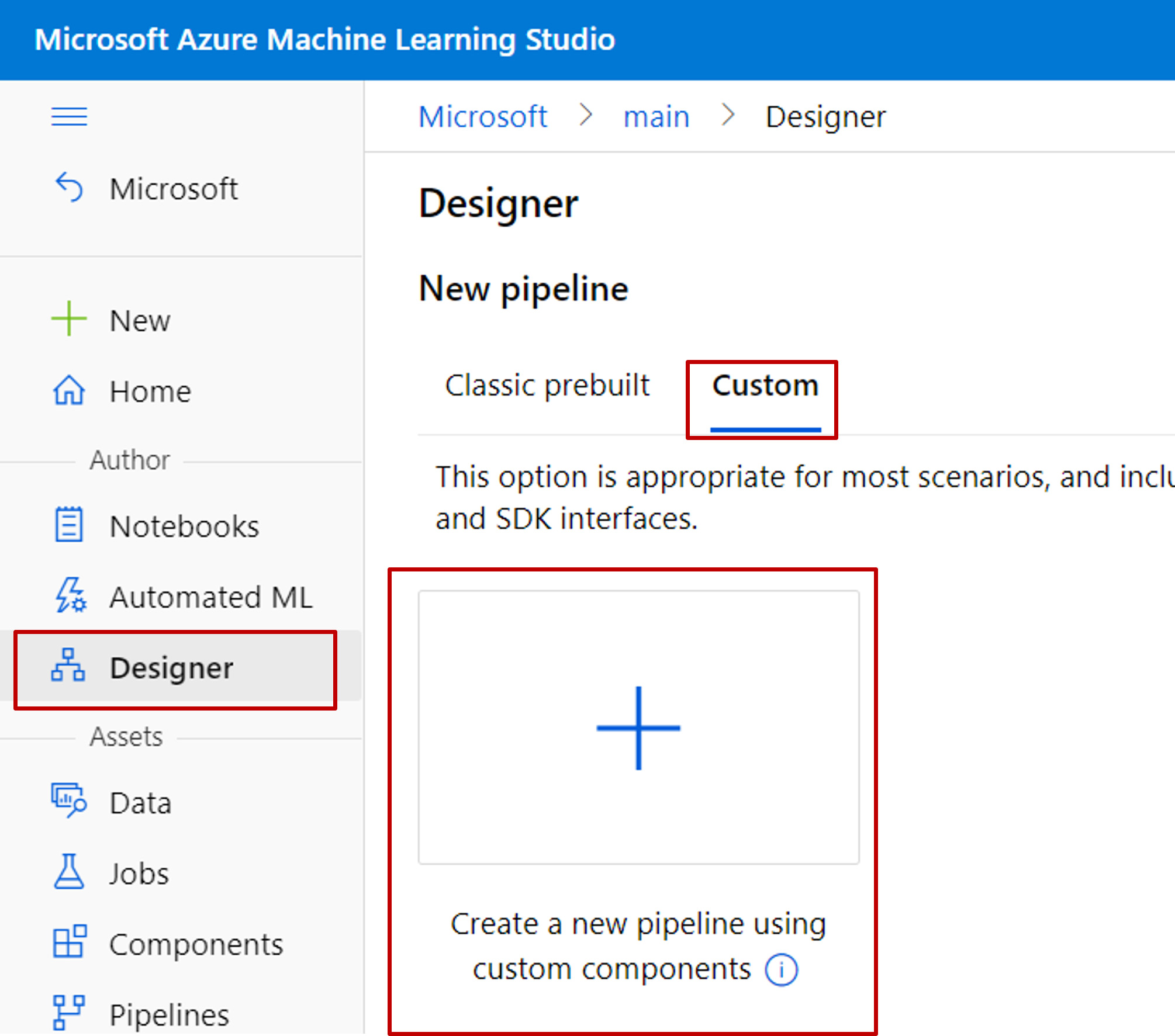
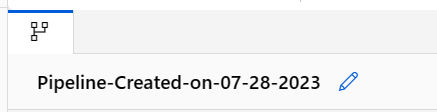
Adjon értelmes nevet a folyamatnak az automatikusan létrehozott név mellett a ceruza ikon kiválasztásával.
A tervezőeszköztárban megtekintheti az Adatok, a Modell és az Összetevők lapot. Váltson az Összetevők lapra, és láthatja az előző szakaszban regisztrált összetevőket. Ha túl sok összetevő van, az összetevő nevével kereshet.
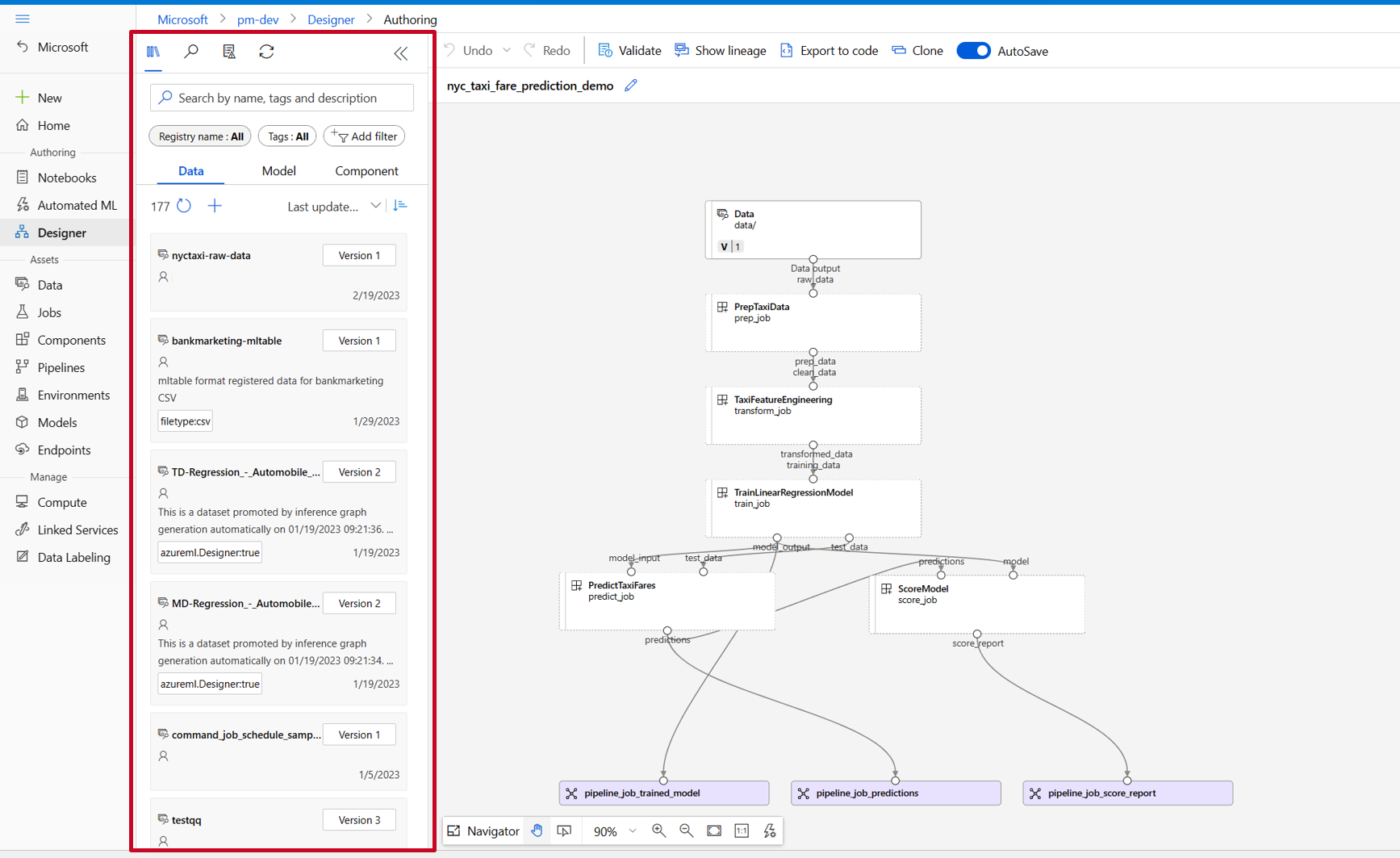
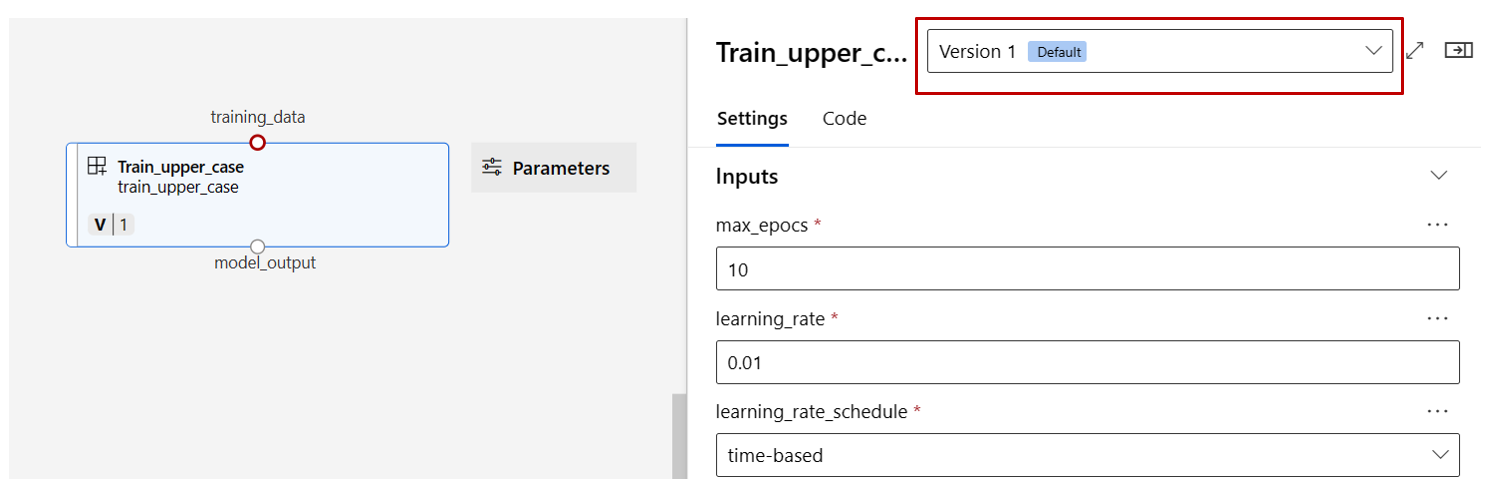
Keresse meg az előző szakaszban regisztrált vonat-, pontszám- és eval-összetevőket, majd húzza őket a vászonra. Alapértelmezés szerint az összetevő alapértelmezett verzióját használja, és az összetevő jobb oldali ablaktábláján egy adott verzióra válthat. Az összetevő jobb oldali ablaktábláját az összetevőre duplán kattintva hívja meg a rendszer.
Ebben a példában az elérési út alatti mintaadatokat fogjuk használni. Regisztrálja az adatokat a munkaterületen a tervezőeszköztár Hozzáadás ikonjának kiválasztásával –> Adat lap, Típus = Mappa(uri_folder) beállítás, majd a varázslót követve regisztrálja az adatokat. Az adattípusnak uri_folder kell lennie a betanítási összetevő definíciójával való összhangban.

Ezután húzza az adatokat a vászonra. A folyamatnak most az alábbi képernyőképhez hasonlóan kell kinéznie.
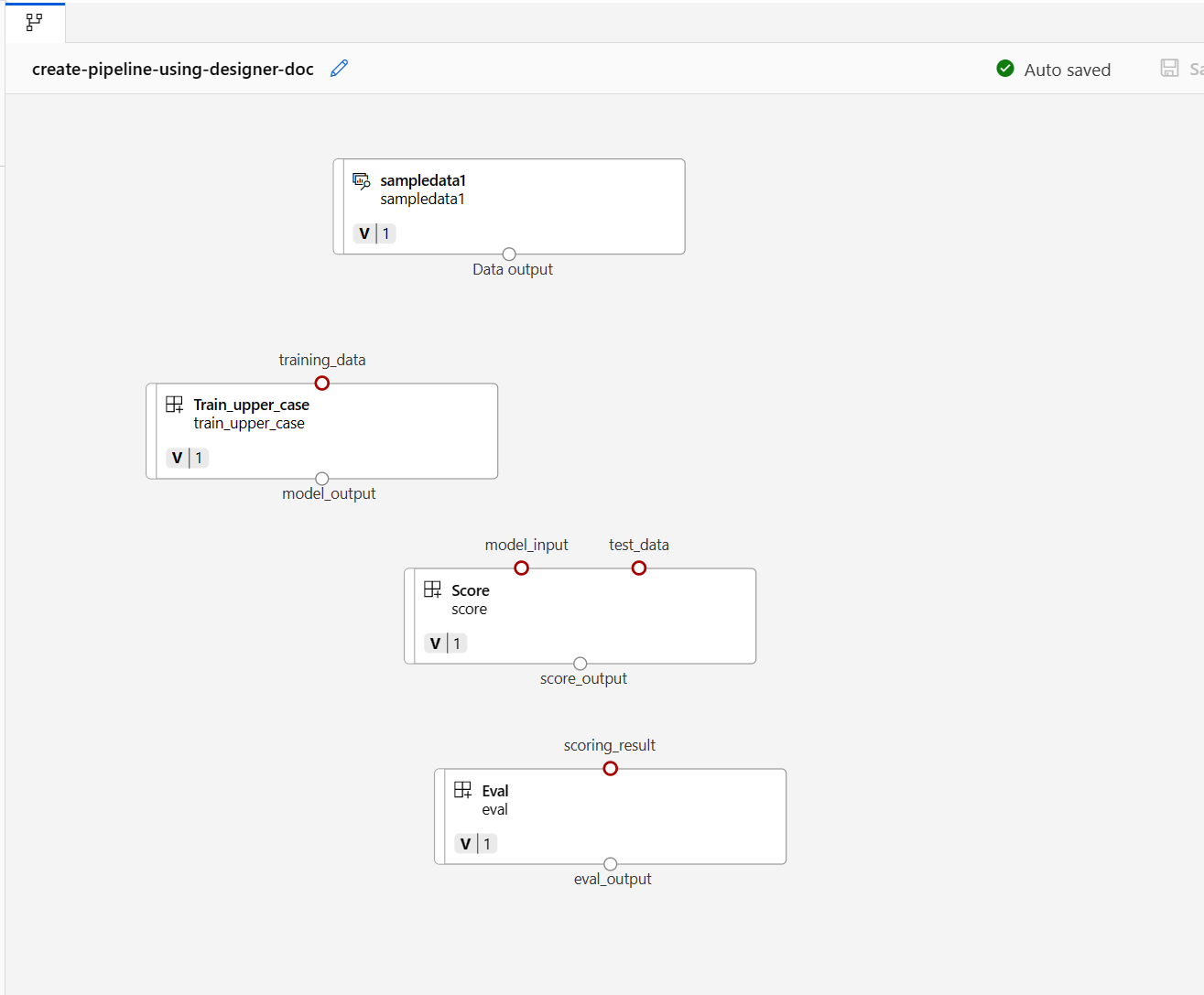
Csatlakoztassa az adatokat és az összetevőket a vásznon lévő kapcsolatok húzásával.
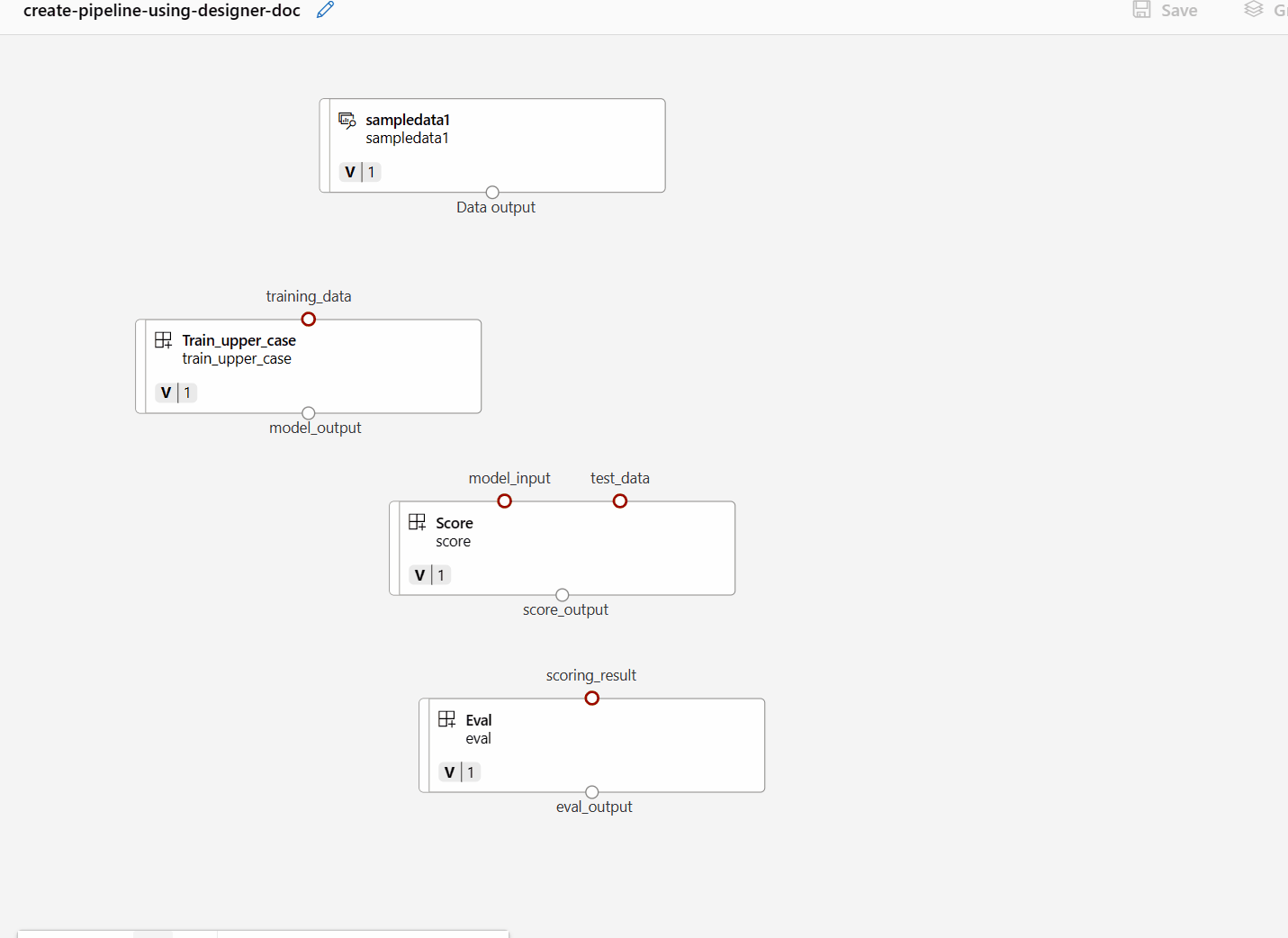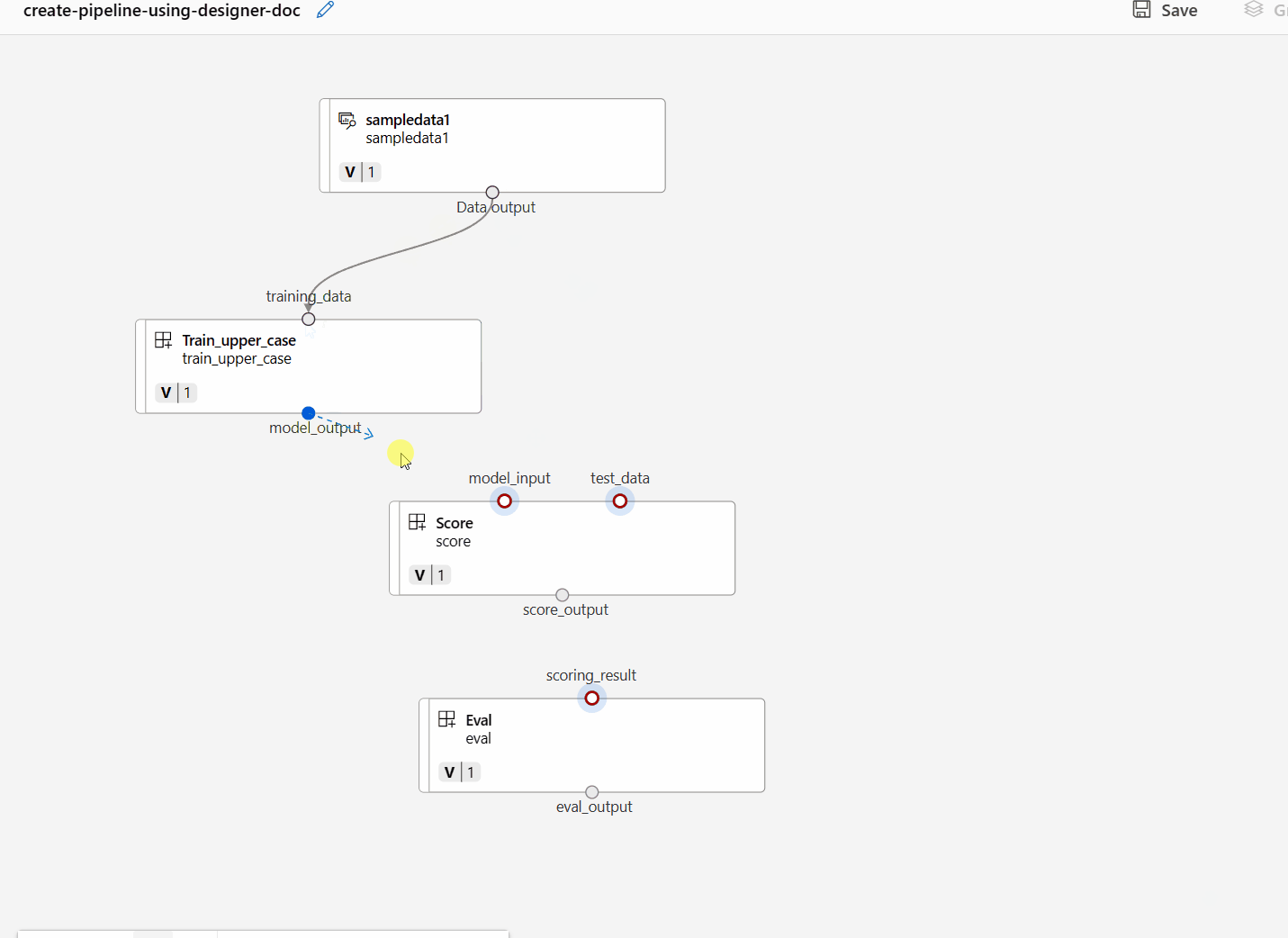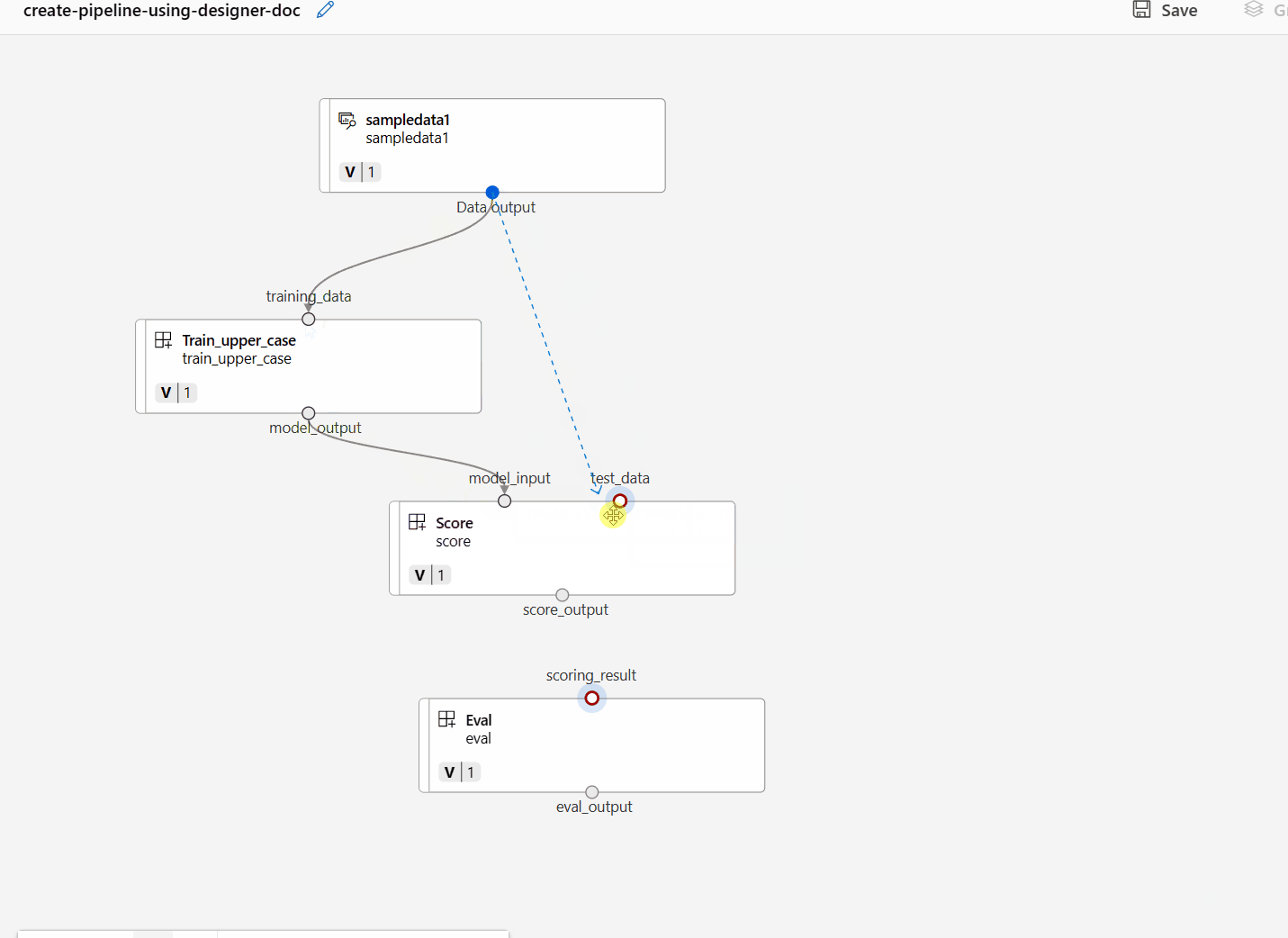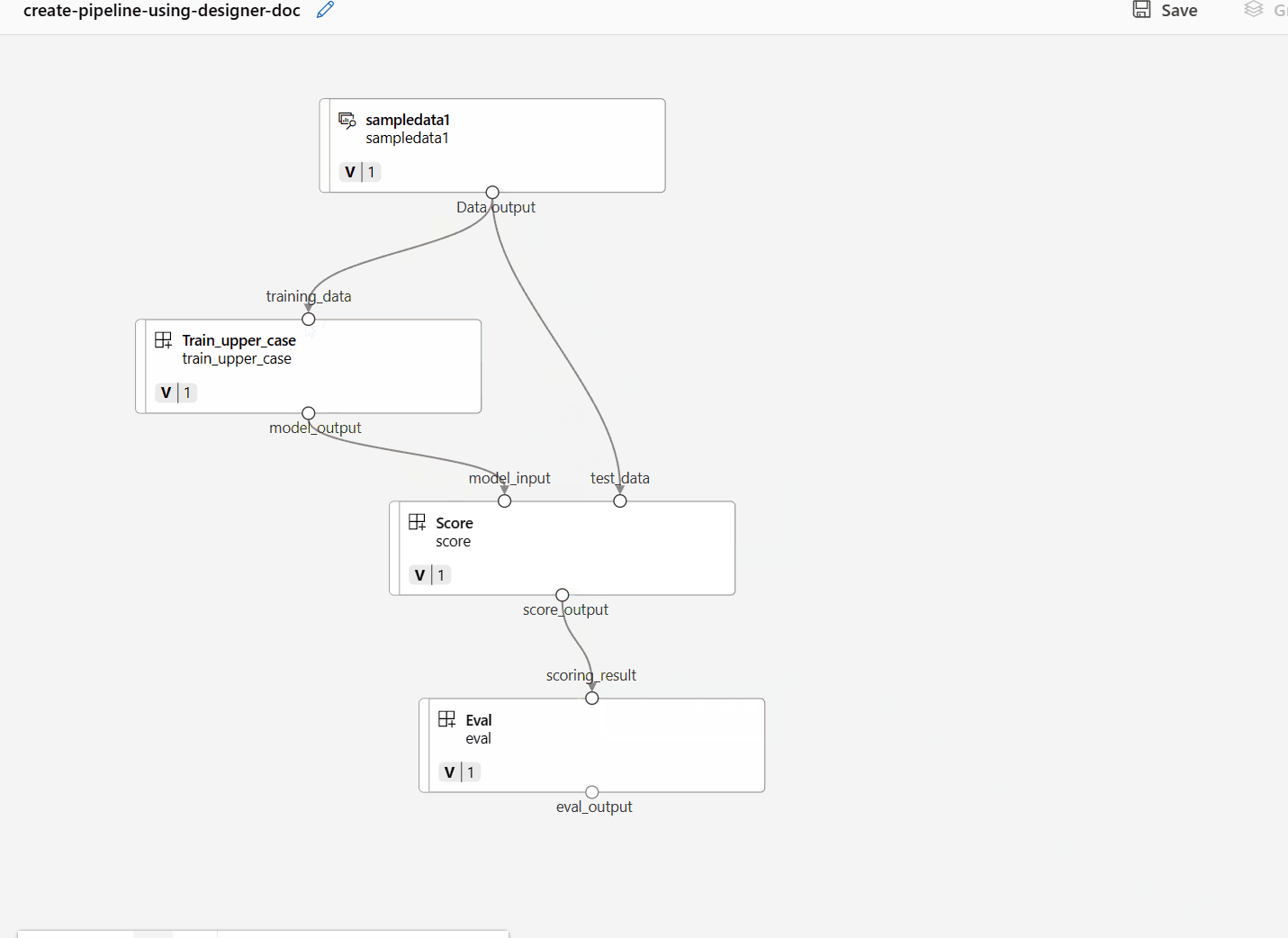
Kattintson duplán egy összetevőre, és megjelenik egy jobb oldali panel, ahol konfigurálhatja az összetevőt.
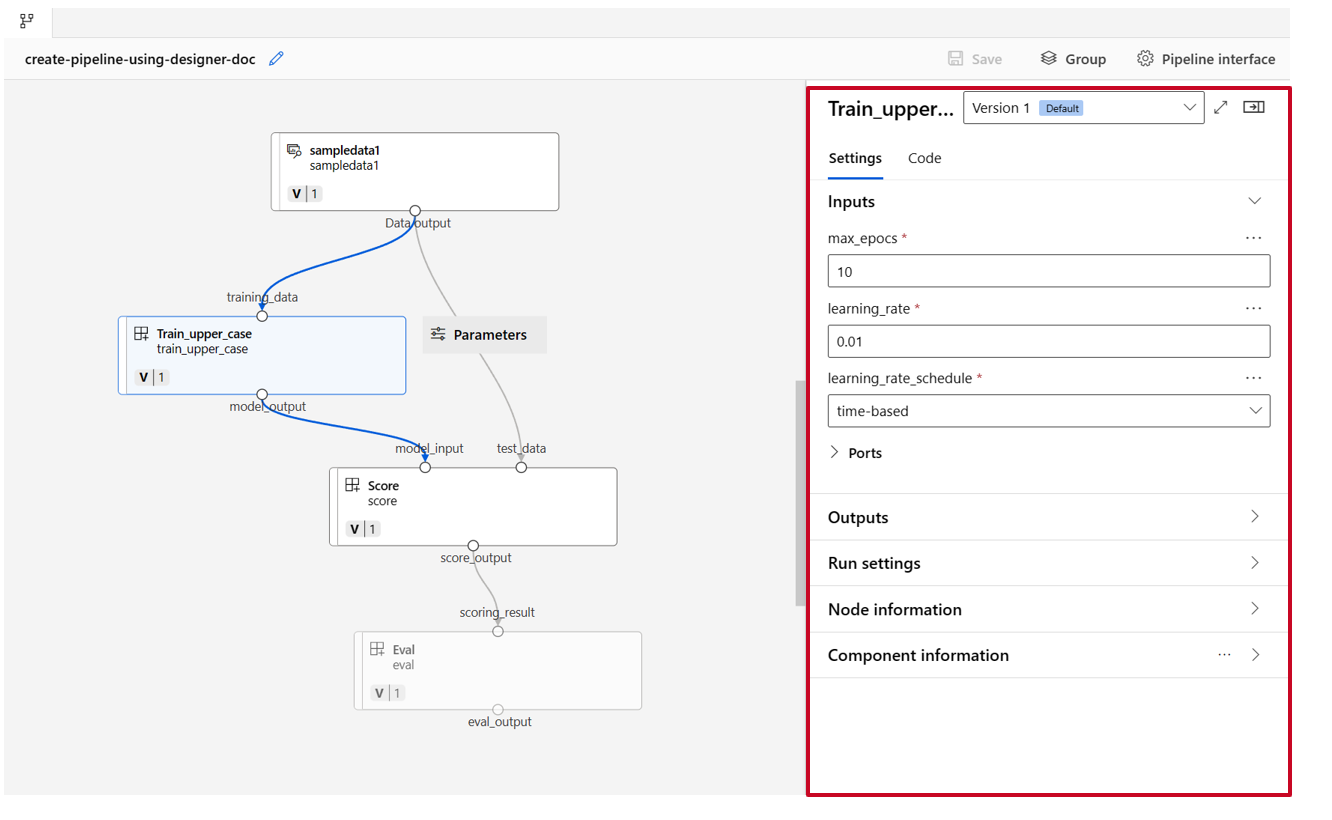
Az olyan primitív típusú bemenetekkel rendelkező összetevők esetében, mint a szám, az egész szám, a sztring és a logikai érték, az összetevők részletes paneljén, a Bemenetek szakaszban módosíthatja az ilyen bemenetek értékeit .
A jobb oldali panelen módosíthatja a kimeneti beállításokat (az összetevő kimenetének tárolási helyét), és futtathatja a beállításokat (számítási cél az összetevő futtatásához).
Most előléptetjük a vonatösszetevő max_epocs bemenetét folyamatszintű bemenetre. Így a folyamat elküldése előtt minden alkalommal hozzárendelhet egy másik értéket ehhez a bemenethez.
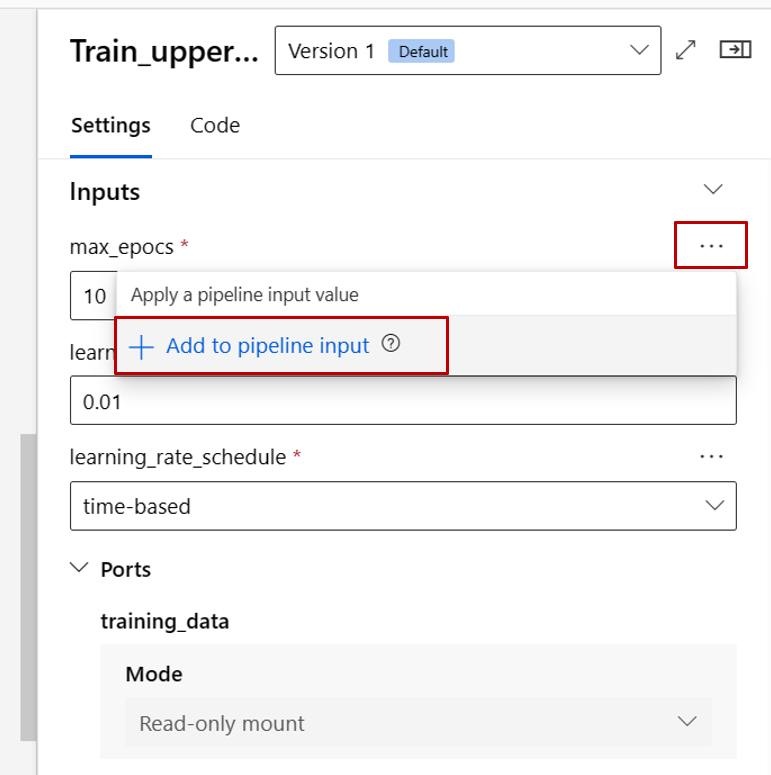









Feljegyzés
Az egyéni összetevők és a tervező klasszikus előre összeállított összetevői nem használhatók együtt.
Folyamat elküldése
A folyamat elküldéséhez válassza a Konfigurálás > Küldés lehetőséget a jobb felső sarokban.

Ezután megjelenik egy lépésenkénti varázsló, amely a varázslót követve küldi el a folyamatfeladatot.

Az Alapszintű lépésekben konfigurálhatja a kísérletet, a feladat megjelenítendő nevét, a feladat leírását stb.
A Bemenetek és kimenetek lépésben konfigurálhatja a folyamatszintre előléptetett bemeneteket/kimeneteket. Az előző lépésben előléptettük a folyamatbemenetbe való betanítási összetevő max_epocs, így itt láthatja és hozzárendelheti az értéket max_epocs.
A futtatókörnyezet beállításaiban konfigurálhatja a folyamat alapértelmezett adattárát és alapértelmezett számítását. Ez a folyamat összes összetevőjének alapértelmezett adattára/számítása. Vegye figyelembe azonban, hogy ha explicit módon állít be egy másik számítási vagy adattárat egy összetevőhöz, a rendszer tiszteletben tartja az összetevőszint-beállítást. Ellenkező esetben a folyamat alapértelmezett értékét használja.
A Felülvizsgálat + Küldés lépés az utolsó lépés az összes konfiguráció áttekintéséhez a küldés előtt. A varázsló emlékszik a legutóbbi konfigurálásra, ha valaha is beküldi a folyamatot.
A folyamatfeladat elküldése után a tetején egy üzenet jelenik meg, amely a feladat részleteire mutató hivatkozást tartalmaz. Erre a hivatkozásra kattintva áttekintheti a feladat részleteit.

Identitás megadása a folyamatfeladatban
A folyamatfeladat elküldésekor megadhatja az adatok Run settingseléréséhez szükséges identitást. Az alapértelmezett identitás, AMLToken amely nem használt identitást, mind a UserIdentity Managed. A UserIdentityfeladat-beküldő identitása a bemeneti adatok elérésére és az eredménynek a kimeneti mappába való írására szolgál. Ha megadja Managed, a rendszer a felügyelt identitással fogja elérni a bemeneti adatokat, és az eredményt a kimeneti mappába írja.

Következő lépések
- Ezeket a Jupyter-jegyzetfüzeteket a GitHubon használhatja a gépi tanulási folyamatok további megismeréséhez
- Megtudhatja , hogyan hozhat létre folyamatokat összetevők használatával a CLI v2 használatával.
- Megtudhatja , hogyan hozhat létre folyamatokat összetevők használatával az SDK v2 használatával