Adategységek létrehozása és kezelése
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Ez a cikk bemutatja, hogyan hozhat létre és kezelhet adategységeket az Azure Machine Tanulás.
Az adategységek segíthetnek, ha szüksége van ezekre a képességekre:
- Verziószámozás: Az adategységek támogatják az adatok verziószámozását.
- Reprodukálhatóság: Miután létrehozott egy adategység-verziót, az nem módosítható. Nem módosítható és nem törölhető. Ezért az adategységet használó betanítási feladatok vagy folyamatok reprodukálhatók.
- Ellenőrizhetőség: Mivel az adategység verziója nem módosítható, nyomon követheti az eszközverziókat, a verziófrissítéseket és a verziófrissítéseket.
- Életút: Bármely adott adategység esetében megtekintheti, hogy mely feladatok vagy folyamatok használják fel az adatokat.
- Egyszerű használat: Az Azure-beli gépi tanulási adategységek a webböngésző könyvjelzőihez (kedvenceihez) hasonlítanak. Az Azure Storage-ban gyakran használt adatokra hivatkozó hosszú tárolási útvonalak (URI-k) megjegyzése helyett létrehozhat egy adategység-verziót, majd rövid névvel (például:
azureml:<my_data_asset_name>:<version>) elérheti az eszköz ezen verzióját.
Tipp.
Ha interaktív munkamenetben (például jegyzetfüzetben) vagy feladatban szeretné elérni az adatokat, nem kell először létrehoznia egy adategységet. Az adatok eléréséhez az adattár URI-jait használhatja. Az adattár URI-k egyszerű módot kínálnak az Adatok elérésére az Azure machine learning első lépéseihez.
Előfeltételek
Az adategységek létrehozásához és használatához a következőkre van szükség:
Azure-előfizetés. Ha még nincs előfizetése, hozzon létre egy ingyenes fiókot, mielőtt hozzákezd. Próbálja ki az Azure Machine Tanulás ingyenes vagy fizetős verzióját.
Egy Azure Machine Learning-munkaterület. Munkaterületi erőforrások létrehozása.
Adategységek létrehozása
Az adategység létrehozásakor be kell állítania az adategység típusát. Az Azure Machine Tanulás három adategységtípust támogat:
| Type | API | Canonical Scenarios |
|---|---|---|
| Fájl Hivatkozás egyetlen fájlra |
uri_file |
Egyetlen fájl olvasása az Azure Storage-ban (a fájl bármilyen formátumú lehet). |
| Mappa Hivatkozás mappára |
uri_folder |
Parquet-/CSV-fájlok mappájának beolvasása a Pandasba/Sparkba. Egy mappában található strukturálatlan adatok (képek, szöveg, hang stb.) olvasása. |
| Table Adattáblára mutató hivatkozás |
mltable |
Összetett sémája gyakran változik, vagy nagy táblázatos adatok egy részhalmazára van szüksége. AutoML táblákkal. Több tárolóhelyre kiterjedő strukturálatlan adatok (képek, szöveg, hang stb.) olvasása. |
Megjegyzés:
Ne használjon beágyazott újvonalakat csv-fájlokban, hacsak nem regisztrálja az adatokat MLTable-ként. A csv-fájlokba ágyazott újvonalak az adatok olvasása során hibás mezőértékeket okozhatnak. Az MLTable az átalakítás során read_delimited ezt a paramétert support_multi_linehasználja az idézett sortörések egyetlen rekordként való értelmezéséhez.
Amikor egy Azure Machine Tanulás feladatban használja az adategységet, csatlakoztathatja vagy letöltheti az objektumot a számítási csomópont(ok)ra. További információkért olvassa el a Módokat.
Emellett meg kell adnia egy paramétert path , amely az adategység helyére mutat. A támogatott elérési utak a következők:
| Location | Példák |
|---|---|
| Elérési út a helyi számítógépen | ./home/username/data/my_data |
| Elérési út egy adattárban | azureml://datastores/<data_store_name>/paths/<path> |
| Elérési út egy nyilvános HTTP-kiszolgálón | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Elérési út az Azure Storage-ban | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Megjegyzés:
Amikor helyi elérési útból hoz létre adategységet, az automatikusan feltölti az alapértelmezett Azure Machine Tanulás felhőalapú adattárba.
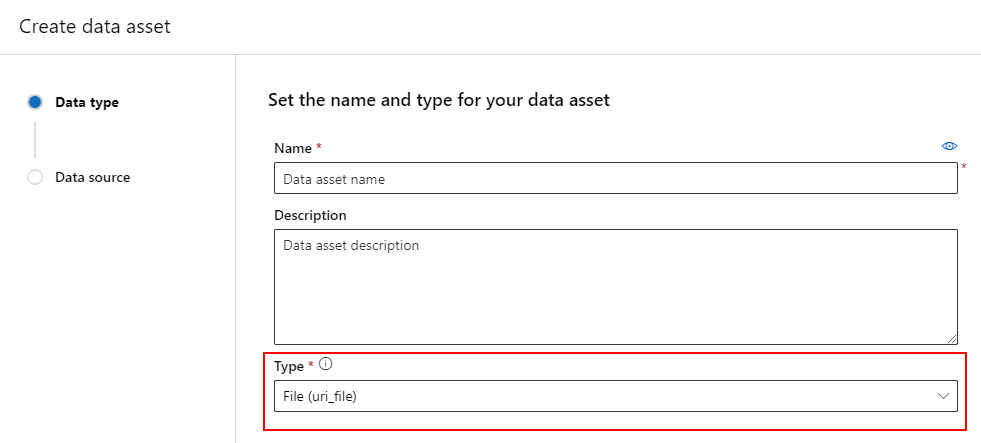
Adategység létrehozása: Fájltípus
A Fájl (uri_file) típusú adategységek egyetlen tárolófájlra (például CSV-fájlra) mutatnak. Fájltípusú adategységet az alábbiakkal hozhat létre:
Hozzon létre egy YAML-fájlt, és másolja és illessze be a következő kódot. Frissítenie kell a <> helyőrzőket az adategység nevével, a verzióval, a leírással és a támogatott helyen található egyetlen fájl elérési útjával.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Ezután hajtsa végre a következő parancsot a parancssori felületen (frissítse a <filename> helyőrzőt a YAML-fájlnévre):
az ml data create -f <filename>.yml
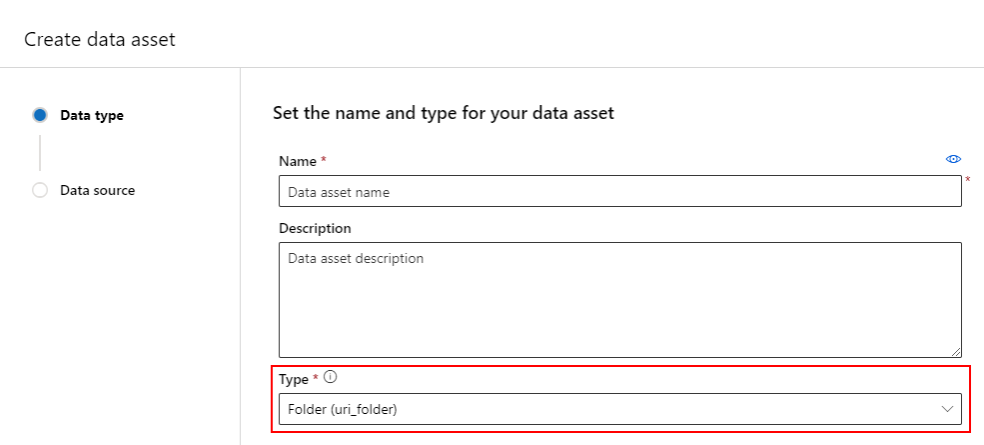
Adategység létrehozása: Mappa típusa
A Mappa (uri_folder) típusú adategység egy olyan adategység, amely a tároló egy mappájára mutat (például egy olyan mappára, amely több kép almappáját tartalmazza). Mappatípusú adategységet az alábbiakkal hozhat létre:
Hozzon létre egy YAML-fájlt, és másolja és illessze be a következő kódot. Frissítenie kell a <> helyőrzőket az adategység nevével, a verzióval, a leírással és a támogatott helyen található mappa elérési útjával.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Ezután hajtsa végre a következő parancsot a parancssori felületen (frissítse a <filename> helyőrzőt a fájlnévre a YAML-fájlnévre):
az ml data create -f <filename>.yml
Adategység létrehozása: Tábla típusa
Az Azure Machine Tanulás-táblák (MLTable) számos funkcióval rendelkeznek, amelyekről részletesebben is olvashat az Azure Machine-Tanulás táblákkal való munka során. Ahelyett, hogy megismételnénk ezt a dokumentációt, egy táblázattípusú adategységet hozunk létre egy nyilvánosan elérhető Azure Blob Storage-fiókon található Titanic-adatok használatával.
Először hozzon létre egy új, adatok nevű könyvtárat, és hozzon létre egy MLTable nevű fájlt:
mkdir data
touch MLTable
Ezután másolja és illessze be a következő YAML-fájlt az előző lépésben létrehozott MLTable fájlba:
Figyelmeztetés
Ne nevezze át a fájlt a MLTable következőreMLTable.yaml: vagy MLTable.yml. Az Azure Machine Learning egy MLTable fájlt vár.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Ezután hajtsa végre a következő parancsot a parancssori felületen. Győződjön meg arról, hogy frissíti a <> helyőrzőket az adategység nevével és verzióértékeivel.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Fontos
Az path érvényes MLTable fájlt tartalmazó mappának kell lennie.
Adategységek létrehozása feladatkimenetekből
Adategységet egy Azure Machine-Tanulás-feladatból hozhat létre a kimenet paraméterének name beállításával. Ebben a példában elküld egy feladatot, amely adatokat másol egy nyilvános blobtárolóból az alapértelmezett Azure Machine Tanulás Adattárba, és létrehoz egy úgynevezett adategységetjob_output_titanic_asset.
Feladatspecifikációs YAML-fájl létrehozása (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: azureml:wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Ezután küldje el a feladatot a parancssori felület használatával:
az ml job create --file <file-name>.yml
Adategységek felügyelete
Adategység törlése
Fontos
Az adategységek törlése tervezés szerint nem támogatott.
Ha az Azure Machine Learning lehetővé teszi az adategységek törlését, az alábbi káros hatásokkal járna:
- A később törölt adategységeket használó éles feladatok sikertelenek lesznek.
- Nehezebb lenne reprodukálni egy ML-kísérletet.
- A feladatsor megszakadna, mert lehetetlenné válik a törölt adategység-verzió megtekintése.
- Nem tudja megfelelően nyomon követni és naplózni, mivel a verziók hiányoznak.
Ezért az adategységek nem módosíthatósága biztosít szintű védelmet az éles számítási feladatokat létrehozó csapatban végzett munka során.
Ha egy adategység hibásan lett létrehozva – például helytelen névvel, típussal vagy elérési úttal –, az Azure Machine Tanulás megoldást kínál a helyzet kezelésére a törlés negatív következményei nélkül:
| Törölni szeretném ezt az adategységet, mert... | Megoldás |
|---|---|
| A név helytelen | Az adategység archiválása |
| A csapat már nem használja az adategységet | Az adategység archiválása |
| Zsúfolttá teszi az adategységek listáját | Az adategység archiválása |
| Az elérési út helytelen | Hozza létre az adategység új verzióját (ugyanaz a név) a megfelelő elérési úttal. További információ: Adategységek létrehozása. |
| Helytelen típussal rendelkezik | Az Azure Machine Tanulás jelenleg nem engedélyezi az új verzió létrehozását a kezdeti verzióhoz képest. (1) Az adategység archiválása (2) Hozzon létre egy új adategységet egy másik néven, a megfelelő típussal. |
Adategység archiválása
Az adategységek archiválása alapértelmezés szerint elrejti azt mindkét lista-lekérdezésből (például a PARANCSSOR-ban az ml data list) és az adategység-listából a Studio felhasználói felületén. Továbbra is hivatkozhat és használhat archivált adategységet a munkafolyamatokban. Archiválhatja a következőt:
- az adategység minden verziója egy adott név alatt, vagy
- egy adott adategység-verzió
Adategység összes verziójának archiválása
Ha az adategység összes verzióját egy adott név alatt szeretné archiválni, használja a következőt:
Hajtsa végre a következő parancsot (frissítse a <> helyőrzőt az adategység nevével):
az ml data archive --name <NAME OF DATA ASSET>
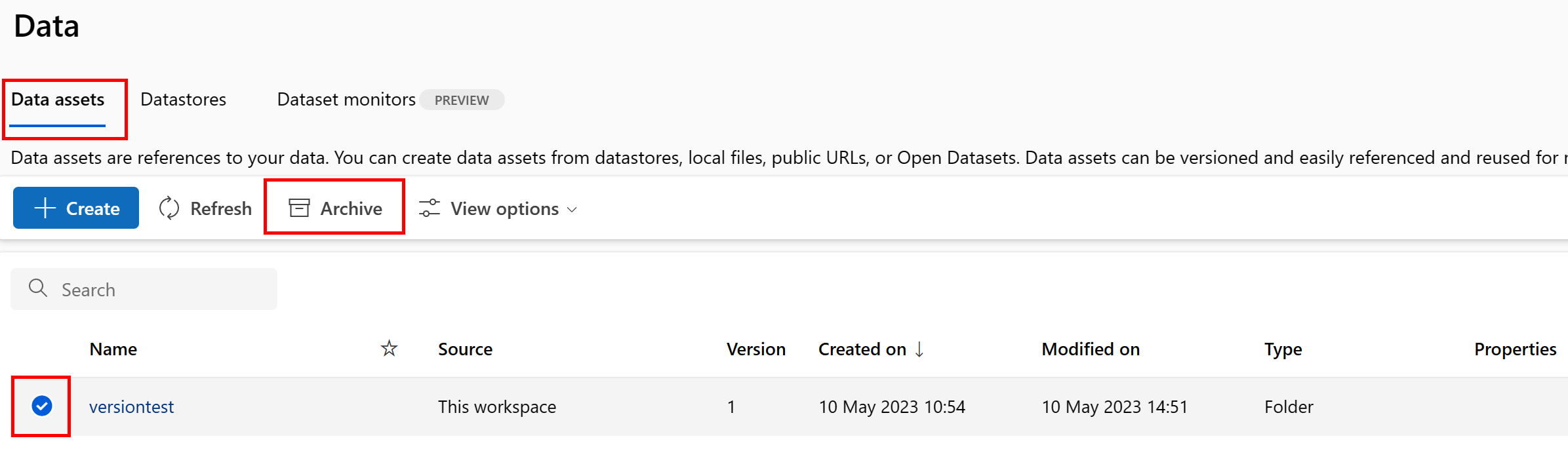
Adott adategység-verzió archiválása
Az adategység adott verziójának archiválásához használja a következőt:
Hajtsa végre a következő parancsot (frissítse a <> helyőrzőket az adategység nevével és verziójával):
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Archivált adategység visszaállítása
Az archivált adategységeket visszaállíthatja. Ha az adategység összes verziója archiválva van, az adategység egyes verziói nem állíthatók vissza – az összes verziót vissza kell állítania.
Adategység összes verziójának visszaállítása
Ha az adategység összes verzióját vissza szeretné állítani egy adott név alatt, használja a következőt:
Hajtsa végre a következő parancsot (frissítse a <> helyőrzőt az adategység nevével):
az ml data restore --name <NAME OF DATA ASSET>

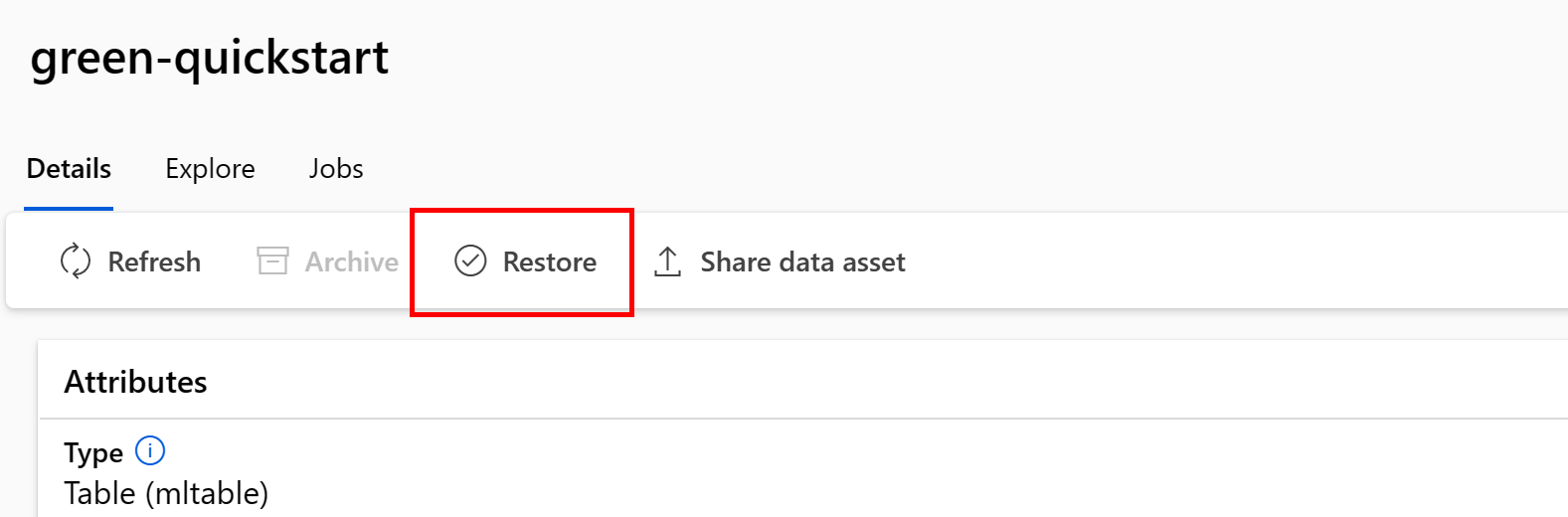
Az adategység adott verziójának visszaállítása
Fontos
Ha az adategység összes verziója archiválva lett, nem állíthatja vissza az adategység egyes verzióit – az összes verziót vissza kell állítania.
Az adategység adott verziójának visszaállításához használja a következőt:
Hajtsa végre a következő parancsot (frissítse a <> helyőrzőket az adategység nevével és verziójával):
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Adatéletút
Az adatéletciklust széles körben az adatok eredetére kiterjedő életciklusként értelmezik, és ahol az idő múlásával a tárolók között mozog. A visszafelé irányuló forgatókönyvek különböző típusai használják, például hibaelhárítást, az ML-folyamatok alapvető okainak nyomon követését és a hibakeresést. Az adatminőség-elemzés, a megfelelőség és a "mi van, ha" forgatókönyvek is az adatminőséget használják. A lineage vizuálisan jelenik meg az adatok forrásról célhelyre való áthelyezésére, valamint az adatátalakításokra is. A legtöbb vállalati adatkörnyezet összetettsége miatt ezek a nézetek nehezen értelmezhetők a perifériás adatpontok összevonása vagy maszkolása nélkül.
Egy Azure Machine Tanulás-folyamatban az adategységek az adatok eredetét és az adatok feldolgozásának módját mutatják, például:
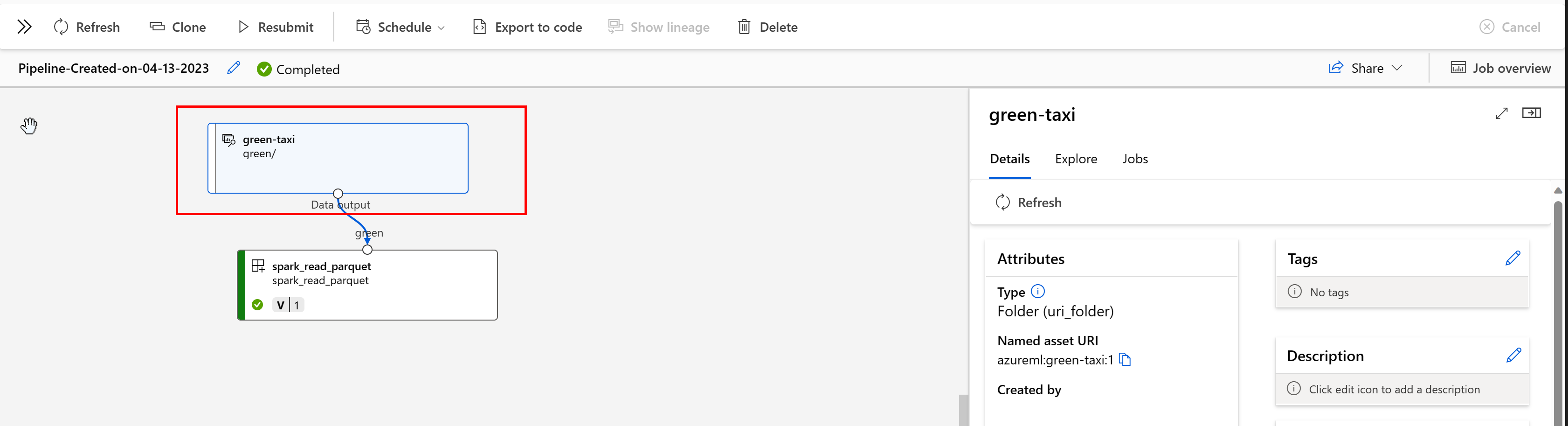
Az adategységet használó feladatokat a Studio felhasználói felületén tekintheti meg. Először válassza az Adatok lehetőséget a bal oldali menüben, majd válassza ki az adategység nevét. Láthatja az adategységet használó feladatokat:
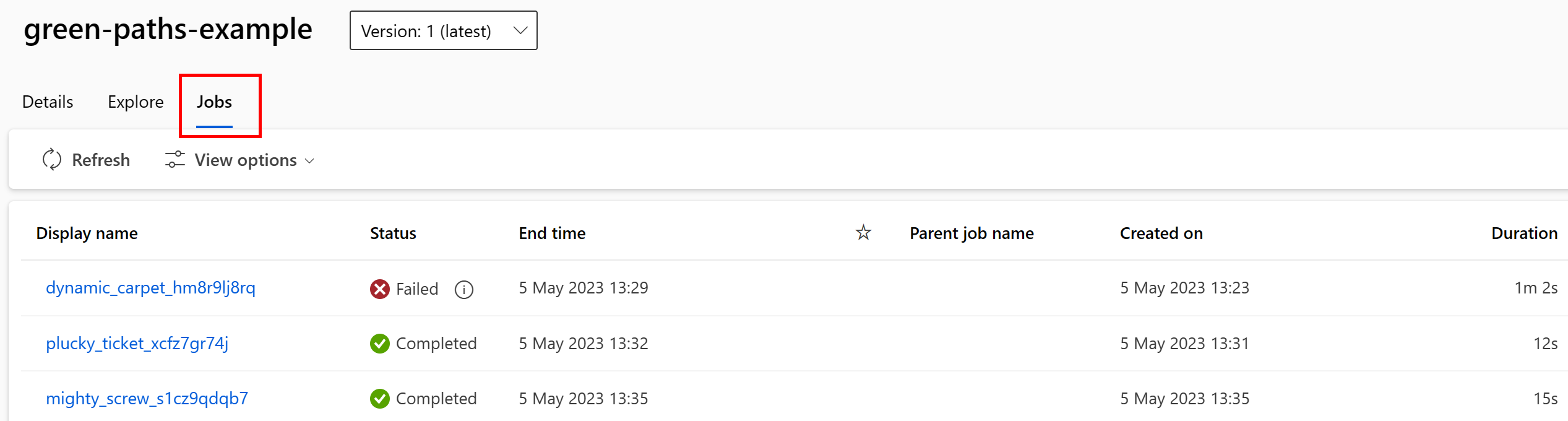
Az Adategységek feladatnézete megkönnyíti a feladathibák keresését, valamint az útvonal-ok elemzését az ML-folyamatokban és a hibakeresésben.
Adategység címkézése
Az adategységek támogatják a címkézést, amely az adategységre kulcs-érték pár formájában alkalmazott további metaadatok. Az adatcímkézés számos előnnyel jár:
- Adatminőség leírása. Ha például a szervezet egy medallion lakehouse architektúrát használ, az objektumokat (nyers), (érvényesített)
medallion:silverésmedallion:gold(bővített) címkévelmedallion:bronzeis megjelölheti. - Az adatok hatékony keresését és szűrését biztosítja az adatfelderítés elősegítése érdekében.
- Segít azonosítani a bizalmas személyes adatokat az adathozzáférés megfelelő kezelése és szabályozása érdekében. For example,
sensitivity:PII/sensitivity:nonPII. - Annak azonosítása, hogy az adatok jóváhagyottak-e egy felelős AI-(RAI-) auditból. For example,
RAI_audit:approved/RAI_audit:todo.
Címkéket adhat hozzá az adategységekhez a létrehozási folyamat részeként, vagy hozzáadhat címkéket a meglévő adategységekhez. Ez a szakasz mindkettőt megjeleníti.
Címkék hozzáadása az adategység-létrehozási folyamat részeként
Hozzon létre egy YAML-fájlt, és másolja és illessze be a következő kódot. Frissítenie kell a <> helyőrzőket az adategység nevével, a verzióval, a leírással, a címkékkel (kulcs-érték párok) és egy támogatott helyen található egyetlen fájl elérési útjával.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Ezután hajtsa végre a következő parancsot a parancssori felületen (frissítse a <filename> helyőrzőt a YAML-fájlnévre):
az ml data create -f <filename>.yml
Címkék hozzáadása meglévő adategységhez
Hajtsa végre a következő parancsot az Azure CLI-ben, és frissítse a <> helyőrzőket az adategység nevével, verziójával és kulcs-érték párjával a címkéhez.
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Ajánlott verziószámozási eljárások
Az ETL-folyamatok általában idő szerint rendszerezik a mappastruktúrát az Azure Storage-ban, például:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Az idő/verzió strukturált mappák és az Azure Machine Tanulás Táblák (MLTable) együttes használatával verziószámozott adatkészleteket hozhat létre. A verziószámozott adatok Azure Machine-Tanulás-táblákkal való elérésének bemutatásához egy hipotetikus példát használunk. Tegyük fel, hogy van egy folyamat, amely hetente feltölti a kameraképeket az Azure Blob Storage-ba a következő struktúrában:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Megjegyzés:
Bár bemutatjuk, hogyan lehet verziószámba venni a rendszerkép (jpeg) adatait, ugyanez a módszer bármilyen fájltípusra alkalmazható (például Parquet, CSV).
Az Azure Machine Tanulás Tables (mltable) használatával létrehozhat egy elérési utakat tartalmazó táblázatot, amely 2023 első hetének végéig tartalmazza az adatokat, majd létrehoz egy adategységet:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
A következő hét végén az ETL frissítette az adatokat, hogy további adatokat tartalmazzon:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Az első verzió (20230108) továbbra is csak a fájlok csatlakoztatását year=2022/week=52 /letöltését tartalmazza, és year=2023/week=1 mivel az elérési utak deklarálva vannak a MLTable fájlban. Ez biztosítja a kísérletek reprodukálhatóságát . Az adategység új verziójának year=2023/week2létrehozásához a következőket kell használnia:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Most már két verziója van az adatoknak, ahol a verzió neve megegyezik a képek tárolási helyre való feltöltésének dátumával:
- 20230108: A képek 2023. január 08-ig.
- 20230115: A képek 2023. január 15-ig.
Az MLTable mindkét esetben olyan elérési utakat tartalmazó táblázatot hoz létre, amely csak az adott dátumig tartalmazza a képeket.
Egy Azure Machine Tanulás feladatban csatlakoztathatja vagy letöltheti ezeket az útvonalakat a verziószámozott MLTable-ban a számítási célhoz az eval_download alábbi módok vagy eval_mount módok használatával:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Megjegyzés:
A eval_mount módok és eval_download a módok egyediek az MLTable-ra. Ebben az esetben az AzureML adat-futtatókörnyezeti képessége kiértékeli a MLTable fájlt, és csatlakoztatja az elérési utakat a számítási célhoz.