Adatok gyűjtése éles modellekből
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Ez a cikk bemutatja, hogyan gyűjthet adatokat egy Azure Kubernetes Service-fürtön üzembe helyezett Azure Machine Learning-modellből. Az összegyűjtött adatok ezután az Azure Blob Storage-ban lesznek tárolva.
A gyűjtemény engedélyezése után az összegyűjtött adatok a következőkben segítenek:
Az összegyűjtött éles adatok adateltolódásainak monitorozása.
Összegyűjtött adatok elemzése a Power BI vagy az Azure Databricks használatával
Hozzon jobb döntéseket arról, hogy mikor kell újratanítást vagy optimalizálni a modellt.
A modell újratanítása az összegyűjtött adatokkal.
Korlátozások
- A modell adatgyűjtési funkciója csak az Ubuntu 18.04-rendszerképekkel használható.
Fontos
2023. 03. 10-én az Ubuntu 18.04 kép elavult. Az Ubuntu 18.04-es rendszerképek támogatása 2023. januártól megszűnik, amikor 2023. április 30-án eléri az EOL-t.
Az MDC funkció nem kompatibilis az Ubuntu 18.04-nél más képpel, amely az Ubuntu 18.04-rendszerkép elavultsága után nem érhető el.
mTovábbi információ, amelyre hivatkozhat:
Feljegyzés
Az adatgyűjtési funkció jelenleg előzetes verzióban érhető el, az éles számítási feladatokhoz nem ajánlott előzetes verziójú funkciók használata.
Az összegyűjtött adatok és azok helye
A következő adatok gyűjthetők:
Egy AKS-fürtben üzembe helyezett webszolgáltatások bemeneti adatainak modellezése. A rendszer nem gyűjt hangokat, képeket és videókat.
Modell-előrejelzések éles bemeneti adatokkal.
Feljegyzés
Ezen adatok előaggregációja és előszámításai jelenleg nem részei a gyűjtési szolgáltatásnak.
A kimenet a Blob Storage-ba lesz mentve. Mivel az adatok hozzáadva lesznek a Blob Storage-hoz, kiválaszthatja a kedvenc eszközét az elemzés futtatásához.
A blob kimeneti adatainak elérési útja a következő szintaxist követi:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Feljegyzés
A PythonHoz készült Azure Machine Learning SDK 0.1.0a16-osnál korábbi verzióiban az designation argumentum neve identifier. Ha a kódot egy korábbi verzióval fejlesztette ki, ennek megfelelően frissítenie kell.
Előfeltételek
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
Telepíteni kell egy Azure Machine Learning-munkaterületet, egy szkripteket tartalmazó helyi könyvtárat és a Pythonhoz készült Azure Machine Learning SDK-t. A telepítésükről további információt a fejlesztési környezet konfigurálása című témakörben talál.
Az AKS-ben üzembe kell helyeznie egy betanított gépi tanulási modellt. Ha nem rendelkezik modellel, tekintse meg a Képosztályozási modell betanítása oktatóanyagot.
Szüksége van egy AKS-fürtre. A gépi tanulási modellek Azure-ban való üzembe helyezésével kapcsolatos információkért lásd : Gépi tanulási modellek üzembe helyezése az Azure-ban.
Állítsa be a környezetet, és telepítse az Azure Machine Learning Monitoring SDK-t.
Használjon egy docker-rendszerképet az Ubuntu 18.04-es verzióján alapuló, a modeldatacollector alapvető függőségével együtt
libssl 1.0.0szállítva. További információt az előre összeállított lemezképeket ismertető cikkben tekinthet meg.
Az adatgyűjtés engedélyezése
Az adatgyűjtést az Azure Machine Learningben vagy más eszközökkel üzembe helyezhető modelltől függetlenül engedélyezheti.
Az adatgyűjtés engedélyezéséhez a következőkre van szükség:
Nyissa meg a pontozófájlt.
Adja hozzá a következő kódot a fájl tetején:
from azureml.monitoring import ModelDataCollectorAz adatgyűjtési változók deklarálása a
initfüggvényben:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])A CorrelationId nem kötelező paraméter. Nem kell használnia, ha a modell nem igényli. A CorrelationId használata megkönnyíti a más adatok, például a LoanNumber vagy a CustomerId leképezését.
Az Azonosító paramétert később a blob mappastruktúrájának létrehozásához használják. Használatával megkülönböztetheti a nyers adatokat a feldolgozott adatoktól.
Adja hozzá a következő kódsorokat a
run(input_df)függvényhez:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobAz adatgyűjtés nem lesz automatikusan igaz, amikor egy szolgáltatást helyez üzembe az AKS-ben. Frissítse a konfigurációs fájlt az alábbi példához hasonlóan:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)A konfiguráció módosításával az Application Insights szolgáltatásfigyelési funkcióját is engedélyezheti:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Új rendszerkép létrehozásához és a gépi tanulási modell üzembe helyezéséhez lásd : Gépi tanulási modellek üzembe helyezése az Azure-ban.
Adja hozzá az "Azure-Monitoring" pipcsomagot a webszolgáltatás-környezet conda-függőségeihez:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Adatgyűjtés letiltása
Az adatok gyűjtését bármikor megszüntetheti. Python-kóddal tiltsa le az adatgyűjtést.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Adatok ellenőrzése és elemzése
Kiválaszthatja a kívánt eszközt a Blob Storage-ban gyűjtött adatok elemzéséhez.
Blobadatok gyors elérése
Jelentkezzen be az Azure Portalra.
Nyissa meg a munkaterületet.
Válassza a Storage lehetőséget.

Kövesse a blob kimeneti adatainak elérési útját az alábbi szintaxissal:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Modelladatok elemzése a Power BI használatával
Töltse le és nyissa meg a Power BI Desktopot.
Válassza az Adatok lekérése, majd az Azure Blob Storage lehetőséget.

Adja meg a tárfiók nevét, és adja meg a tárkulcsot. Ezeket az információkat a Blob Beállítások>hozzáférési kulcsai lehetőséget választva találja meg.
Válassza ki a modell adattárolót , és válassza a Szerkesztés lehetőséget.

A lekérdezésszerkesztőben kattintson a Név oszlop alatt, és adja hozzá a tárfiókot.
Adja meg a modell elérési útját a szűrőbe. Ha csak egy adott év vagy hónap fájljait szeretné megvizsgálni, bontsa ki a szűrő elérési útját. Ha például csak a márciusi adatokat szeretné megvizsgálni, használja ezt a szűrőútvonalat:
/modeldata/<subscriptionid>/<resourcegroupname/<workspacename>>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
A névértékek alapján szűrheti az Ön számára releváns adatokat. Ha előrejelzéseket és bemeneteket tárolt, mindegyikhez létre kell hoznia egy lekérdezést.
A fájlok kombinálásához válassza a Tartalom oszlopfejléc melletti lefelé mutató dupla nyilakat.
Kattintson az OK gombra. Az adatok előre betöltődnek.

Válassza a Bezárás és alkalmazás lehetőséget.
Ha bemeneteket és előrejelzéseket adott hozzá, a rendszer automatikusan a RequestId értékek alapján rendezi a táblákat.
Kezdje el az egyéni jelentések készítését a modelladatokon.




Modelladatok elemzése az Azure Databricks használatával
Azure Databricks-munkaterület létrehozása.
Lépjen a Databricks-munkaterületre.
A Databricks-munkaterületen válassza az Adatok feltöltése lehetőséget.

Válassza az Új tábla létrehozása lehetőséget, és válassza az Egyéb adatforrások>Azure Blob Storage>Tábla létrehozása jegyzetfüzetben lehetőséget.
Frissítse az adatok helyét. Egy példa:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"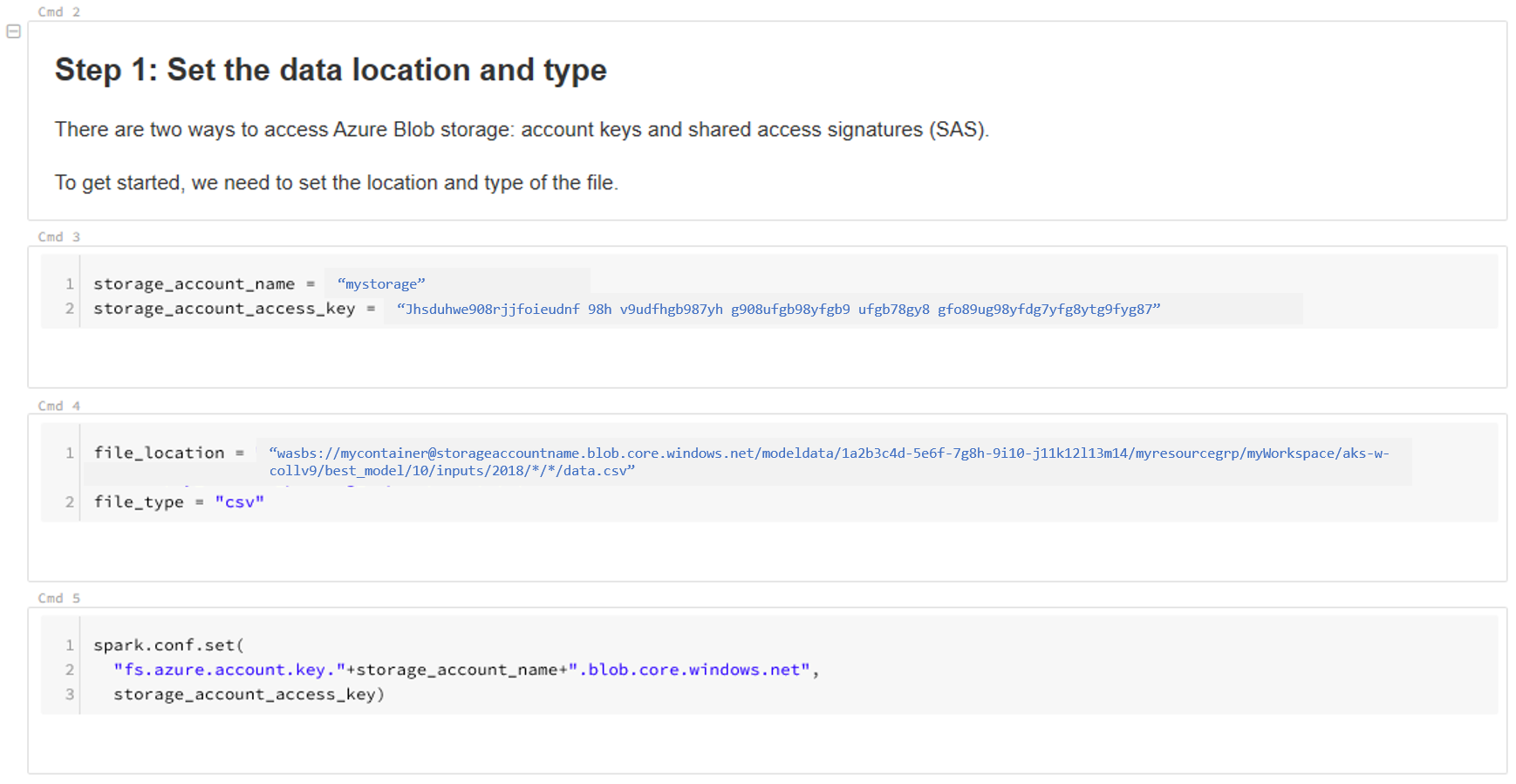
Az adatok megtekintéséhez és elemzéséhez kövesse a sablon lépéseit.


