Az adateltolódás (előzetes verzió) megszűnik, és a Modellfigyelő váltja fel
Az adateltolódás (előzetes verzió) 2025. 09. 01-én megszűnik, és megkezdheti a Modellfigyelő használatát az adatelsodrési feladatokhoz. Az alábbi tartalomban megismerheti a csere, a funkcióhiányok és a manuális módosítás lépéseit.
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Megtudhatja, hogyan figyelheti az adateltolódást, és hogyan állíthat be riasztásokat magas sodródás esetén.
Feljegyzés
Az Azure Machine Learning-modell monitorozása (v2) továbbfejlesztett képességeket biztosít az adateltolódáshoz, valamint további funkciókat biztosít a jelek és metrikák monitorozásához. Az Azure Machine Learning (v2) modellmonitorozásának képességeiről az Azure Machine Learning modellmonitorozásával kapcsolatos további információkért lásd: Modellfigyelés az Azure Machine Learning használatával.
Az Azure Machine Learning-adathalmaz-monitorokkal (előzetes verzió) a következőket teheti:
- Elemezze az adatok sodródását, hogy megértse, hogyan változnak az idő múlásával.
- Modelladatok monitorozása a betanítás és az adatkészletek kiszolgálása közötti különbségek érdekében. Először gyűjtse össze a modelladatokat az üzembe helyezett modellekből.
- Új adatok monitorozása az alapkonfiguráció és a céladatkészlet közötti különbségek érdekében.
- Profilfunkciók az adatokban a statisztikai tulajdonságok időbeli változásának nyomon követéséhez.
- Riasztások beállítása az adateltolódásról a lehetséges problémákra vonatkozó korai figyelmeztetésekhez.
- Hozzon létre egy új adathalmaz-verziót , amikor megállapítja, hogy az adatok túl sokat sodródtak.
A monitor létrehozásához egy Azure Machine Learning-adatkészletet használunk. Az adatkészletnek tartalmaznia kell egy időbélyegoszlopot.
Az adateltolódási metrikákat a Python SDK-val vagy az Azure Machine Learning Studióban tekintheti meg. Más metrikák és elemzések az Azure Machine Learning-munkaterülethez társított Azure-alkalmazás Insights-erőforráson keresztül érhetők el.
Fontos
Az adathalmazok adateltolódás-észlelése jelenleg nyilvános előzetes verzióban érhető el. Az előzetes verzió szolgáltatásszint-szerződés nélkül érhető el, és éles számítási feladatokhoz nem ajánlott. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. További információ: Kiegészítő használati feltételek a Microsoft Azure előzetes verziójú termékeihez.
Előfeltételek
Az adathalmaz-figyelők létrehozásához és használatához a következőkre van szükség:
- Azure-előfizetés. Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot. Próbálja ki ma az Azure Machine Learning ingyenes vagy fizetős verzióját.
- Egy Azure Machine Learning-munkaterület.
- Telepítette a Pythonhoz készült Azure Machine Learning SDK-t, amely tartalmazza az azureml-datasets csomagot.
- Strukturált (táblázatos) adatok az adatok fájlelérési útvonalában, fájlnevében vagy oszlopában megadott időbélyeggel.
Előfeltételek (Migrálás a modellfigyelőbe)
Amikor a Modellfigyelőre migrál, tekintse meg a jelen cikkben említett előfeltételeket az Azure Machine Learning-modell monitorozásának előfeltételei között.
Mi az adateltolódás?
A modell pontossága idővel csökken, nagyrészt az adateltolódás miatt. A gépi tanulási modellek esetében az adateltolódás a modell bemeneti adatainak változása, amely a modell teljesítménycsökkenéséhez vezet. Az adateltolódás monitorozása segít észlelni ezeket a modellteljesítmény-problémákat.
Az adateltolódás okai a következők:
- A felsőbb rétegbeli folyamatok változásai, például egy olyan érzékelő cseréje, amely hüvelykről centiméterre módosítja a mértékegységeket.
- Adatminőségi problémák, például egy hibás érzékelő mindig 0-t olvas.
- Az adatok természetes sodródása, például az évszakok középhőmérsékletének változása.
- A funkciók közötti kapcsolat módosítása vagy a kovarianiátumváltás.
Az Azure Machine Learning leegyszerűsíti a sodródás észlelését azáltal, hogy egyetlen metrikát használ, amely absztrakciót ad az összehasonlítandó adathalmazok összetettségéről. Ezek az adathalmazok több száz funkcióval és több tízezer sorból állhatnak. Az eltolódás észlelése után részletezheti, hogy mely funkciók okozzák a sodródást. Ezután megvizsgálja a szolgáltatásszintű metrikákat a hibakereséshez és a sodródás kiváltó okának elkülönítéséhez.
Ez a felülről lefelé történő megközelítés megkönnyíti az adatok monitorozását a hagyományos szabályokon alapuló technikák helyett. A szabályokon alapuló technikák, például az engedélyezett adattartomány vagy az engedélyezett egyedi értékek időigényesek és hibalehetőségek lehetnek.
Az Azure Machine Learningben adathalmaz-monitorokkal észlelheti és riasztást jeleníthet meg az adateltolódásra vonatkozóan.
Adathalmaz-figyelők
Adathalmaz-monitorral a következőt teheti:
- Észleli és riasztást küld az adathalmaz új adatainak adateltolódásáról.
- Az előzményadatok elemzése a sodródáshoz.
- Új adatok profilkészítése idővel.
Az adateltolódási algoritmus általános mértéke az adatok változásának, valamint annak jelzése, hogy mely funkciók felelősek a további vizsgálatért. Az adathalmaz-figyelők számos más metrikát is létrehoznak az timeseries adathalmaz új adatainak profilozásával.
Az egyéni riasztások a monitor által generált összes metrikára beállíthatók a Azure-alkalmazás Insightson keresztül. Az adathalmaz-figyelők segítségével gyorsan elkaphatók az adatproblémák, és csökkentheti a hibakeresési időt a valószínű okok azonosításával.
Elméletileg három elsődleges forgatókönyv létezik az adathalmaz-monitorok Azure Machine Learningben való beállításához.
| Eset | Leírás |
|---|---|
| Modell adatmegjelenítésének monitorozása a betanítási adatoktól való eltérés érdekében | Az ebből a forgatókönyvből származó eredmények úgy értelmezhetők, mint a modell pontosságának egy proxyjának figyelése, mivel a modell pontossága csökken, ha a kiszolgáló adatok eltérnek a betanítási adatoktól. |
| Egy idősor adatkészletének figyelése az előző időszaktól való eltérés érdekében. | Ez a forgatókönyv általánosabb, és a modellkészítés felső vagy alsó rétegében lévő adathalmazok monitorozására használható. A céladatkészletnek időbélyegoszlopot kell tartalmaznia. Az alapadatkészlet bármilyen táblázatos adathalmaz lehet, amely a céladatkészlettel közös funkciókkal rendelkezik. |
| Végezzen elemzést a múltbeli adatokon. | Ez a forgatókönyv az előzményadatok megértésére és az adathalmaz-figyelők beállításaival kapcsolatos döntések tájékoztatására használható. |
Az adathalmaz-figyelők az alábbi Azure-szolgáltatásoktól függenek.
| Azure-szolgáltatás | Leírás |
|---|---|
| Adatkészlet | A Drift Machine Learning-adatkészleteket használ a betanítási adatok lekéréséhez és a modell betanítási adatainak összehasonlításához. Az adatok profiljának generálása a jelentett metrikák némelyikének létrehozására szolgál, például min, max, különböző értékek, eltérő értékek száma. |
| Azure Machine Learning-folyamat és -számítás | Az eltolódás számítási feladatát egy Azure Machine Learning-folyamat üzemelteti. A feladat igény szerint vagy ütemezés szerint aktiválódik a drift monitor létrehozási idején konfigurált számításon való futtatáshoz. |
| Application Insights | A Drift metrikákat bocsát ki a gépi tanulási munkaterülethez tartozó Application Insightsba. |
| Azure Blob Storage | A Drift json formátumban bocsát ki metrikákat az Azure Blob Storage-ba. |
Alapkonfiguráció és céladatkészletek
Az Azure Machine Learning-adathalmazokat az adateltolódások figyelése céljából figyelheti. Adathalmaz-figyelő létrehozásakor a következőre kell hivatkozni:
- Alapkonfigurációs adatkészlet – általában egy modell betanítási adatkészlete.
- A céladatkészletet – általában a bemeneti adatokat – idővel összehasonlítjuk az alapadatkészlettel. Ez az összehasonlítás azt jelenti, hogy a céladatkészletnek meg kell adnia egy időbélyegoszlopot.
A figyelő összehasonlítja az alapkonfigurációt és a céladatkészleteket.
Migrálás a Modellfigyelőbe
A Modellfigyelőben a következő módon talál megfelelő fogalmakat, és ebben a cikkben további részleteket talál a Modellfigyelés beállítása az éles adatok Azure Machine Learningbe való beléptetésével:
- Referenciaadatkészlet: az adateltolódás-észleléshez használt alapadatkészlethez hasonlóan a legutóbbi éles adathalmazként van beállítva.
- Éles következtetési adatok: az adateltolódás-észlelésben használt céladatkészlethez hasonlóan az éles következtetési adatok automatikusan összegyűjthetők az éles környezetben üzembe helyezett modellekből. Következtethet arra is, hogy milyen adatokat tárol.
Céladatkészlet létrehozása
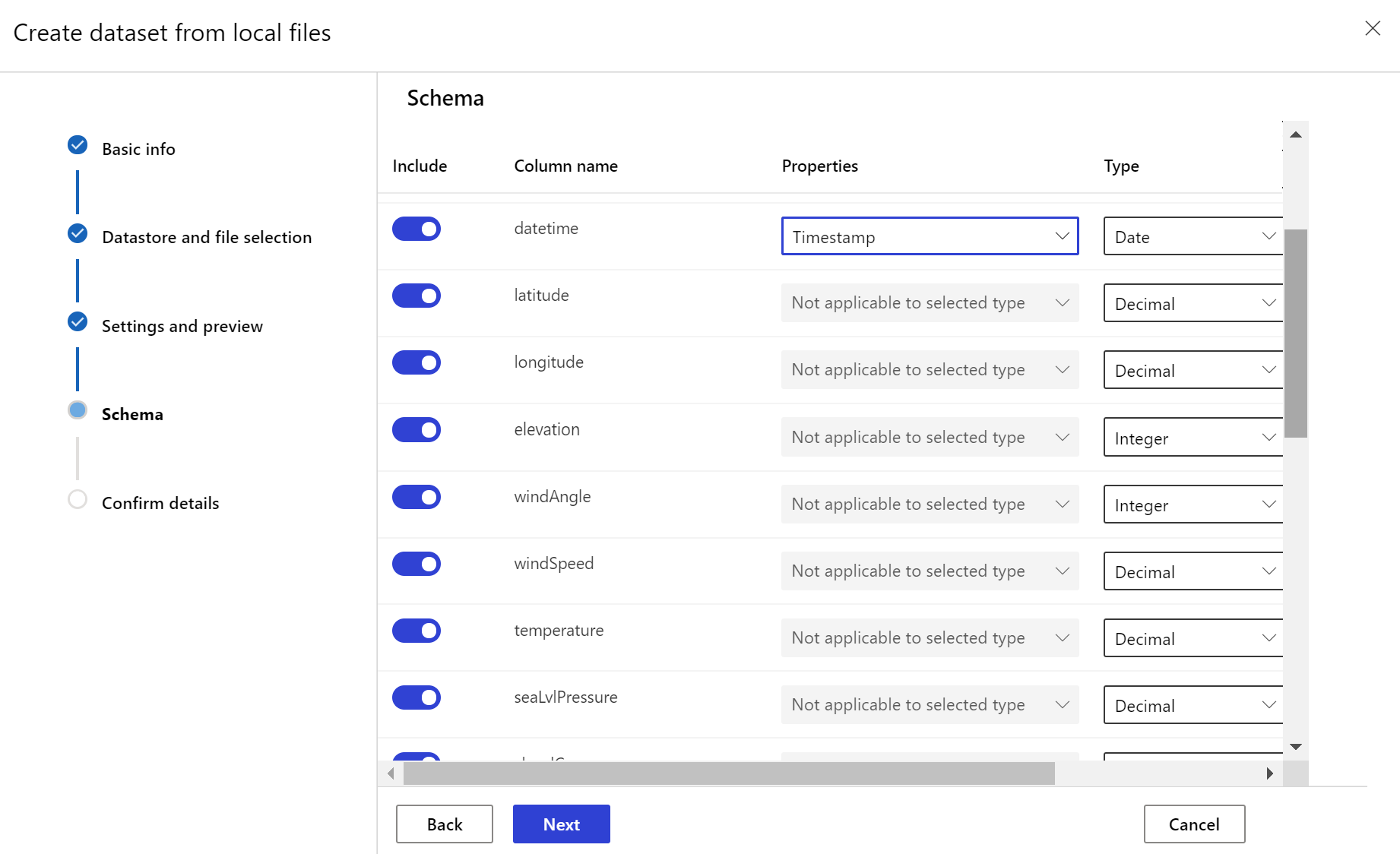
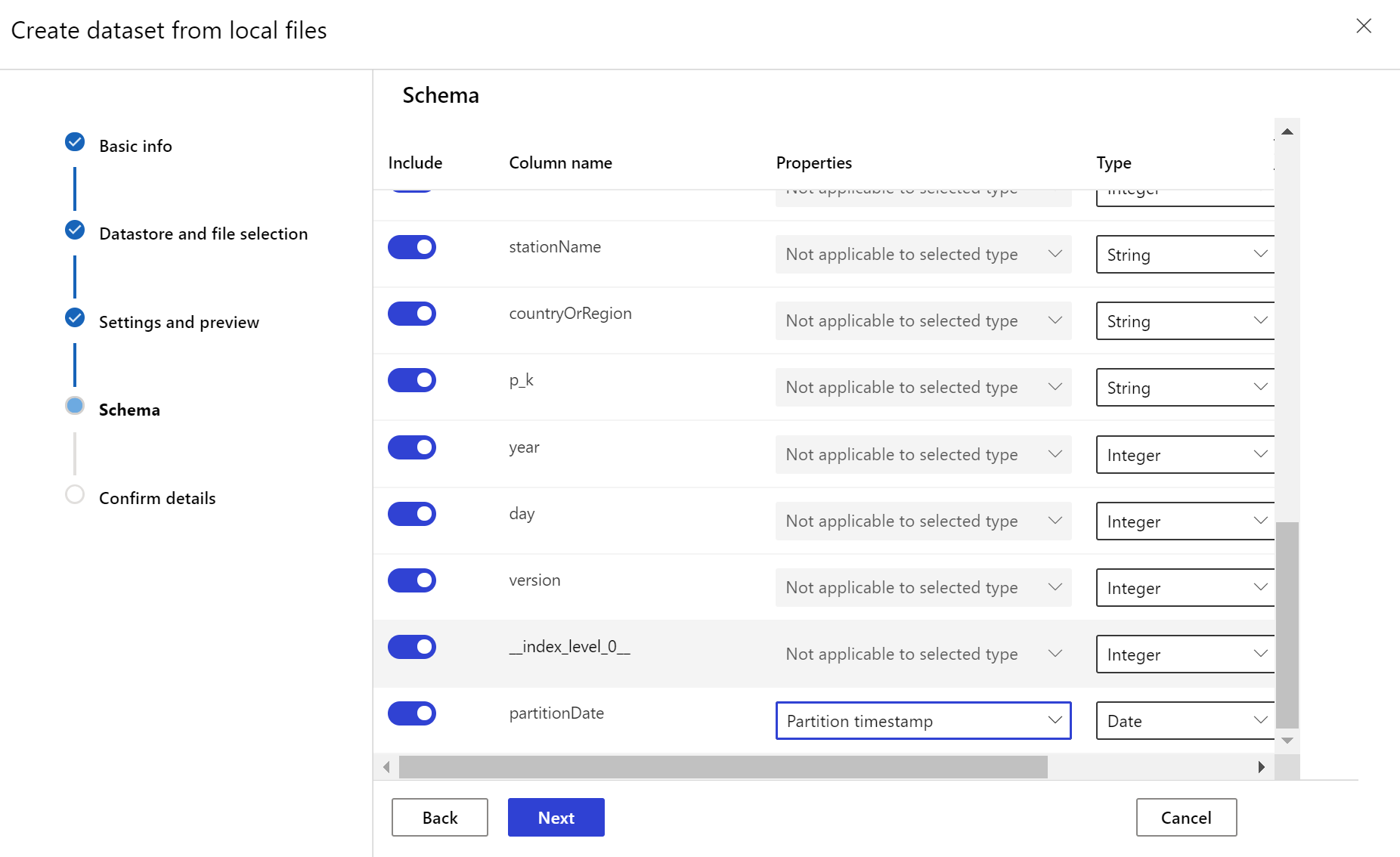
A céladatkészletnek szüksége van rá az timeseries időbélyeg-oszlop megadásával, vagy az adatok egyik oszlopából, vagy a fájlok elérési útvonalmintájából származtatott virtuális oszlopból. Hozza létre az adathalmazt időbélyeggel a Python SDK-ban vagy az Azure Machine Learning Studióban. Meg kell adni egy "időbélyeget" képviselő oszlopot az adathalmazhoz való vonás hozzáadásához timeseries . Ha az adatok időadatokkal (például "{yyyy/MM/dd}") van particionálva a mappastruktúrában, hozzon létre egy virtuális oszlopot az elérési út mintabeállításával, és állítsa be "partícióidőbélyegként" az idősor API-funkcióinak engedélyezéséhez.
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Az Dataset osztálymetódus with_timestamp_columns() határozza meg az adathalmaz időbélyeg-oszlopát.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Tipp.
Az adathalmazok tulajdonságainak használatára timeseries vonatkozó teljes példáért tekintse meg a példajegyzetfüzetet vagy az adathalmazok SDK dokumentációját.

Adathalmaz-figyelő létrehozása
Adathalmaz-figyelő létrehozása új adathalmaz adateltolódásának észleléséhez és riasztásához. Használja a Python SDK-t vagy az Azure Machine Learning Studiót.
A későbbiekben leírtak szerint az adathalmaz-monitorok meghatározott gyakorisággal (napi, heti, havi) futnak. Elemzi a céladatkészletben az utolsó futtatás óta elérhető új adatokat. Bizonyos esetekben előfordulhat, hogy a legfrissebb adatok ilyen elemzése nem elegendő:
- A felsőbb rétegbeli forrásból származó új adatok egy hibás adatfolyam miatt késtek, és ez az új adat nem volt elérhető az adathalmaz-figyelő futtatásakor.
- Az idősorozat-adathalmazok csak előzményadatokkal rendelkeztek, és az adathalmaz időbeli eltérési mintáit szeretné elemezni. Például: hasonlítsa össze a webhely felé irányuló forgalmat a téli és a nyári szezonban, hogy azonosítsa a szezonális mintákat.
- Ön most ismerkedik az Adathalmaz-figyelőkkel. Szeretné kiértékelni, hogyan működik a funkció a meglévő adatokkal, mielőtt beállítja azokat a jövőbeli napok monitorozására. Ilyen esetekben igény szerinti futtatásokat küldhet be egy meghatározott céladatkészlet dátumtartományával az alapadatkészlettel való összehasonlításhoz.
A backfill függvény egy backfill feladatot futtat egy megadott kezdő és záró dátumtartományhoz. A háttérbetöltési feladatok kitöltik az adathalmaz várt hiányzó adatpontjait, így biztosítják az adatok pontosságát és teljességét.
Feljegyzés
Az Azure Machine Learning-modell monitorozása nem támogatja a manuális backfill függvényt, ha újra szeretné végezni a modellfigyelőt egy adott időtartományhoz, létrehozhat egy másik modellfigyelőt az adott időtartományhoz.
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
A részletes információkért tekintse meg a Python SDK adatelsodrási referenciadokumentációját.
Az alábbi példa bemutatja, hogyan hozhat létre adathalmaz-monitort a Python SDK használatával:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Modellfigyelő létrehozása (Migrálás a Modellfigyelőbe)
A Modellfigyelőbe való migráláskor, ha a modellt éles környezetben helyezte üzembe egy Azure Machine Learning online végponton, és az üzembe helyezéskor engedélyezte az adatgyűjtést, az Azure Machine Learning összegyűjti az éles következtetési adatokat, és automatikusan tárolja azokat a Microsoft Azure Blob Storage-ban. Ezután az Azure Machine Learning-modell monitorozásával folyamatosan figyelheti ezeket az éles következtetési adatokat, és közvetlenül kiválaszthatja a modellt a céladatkészlet létrehozásához (éles következtetési adatok a Modellfigyelőben).
Amikor a Modellfigyelőbe migrál, ha nem éles környezetben telepítette a modellt egy Online Azure Machine Learning-végponton, vagy nem szeretne adatgyűjtést használni, a modellfigyelést egyéni jelekkel és metrikákkal is beállíthatja.
A következő szakaszok további részleteket tartalmaznak a Modellfigyelőbe való migrálásról.
Modellfigyelő létrehozása automatikusan gyűjtött éles adatokon keresztül (Migrálás a Modellfigyelőbe)
Ha a modellt éles környezetben telepítette egy Azure Machine Learning online végponton, és az üzembe helyezéskor engedélyezte az adatgyűjtést.
Az alábbi kóddal állíthatja be a beépített modellfigyelést:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Modellfigyelő létrehozása egyéni adatelőfeldolgozási összetevőn keresztül (Migrálás a Modellfigyelőbe)
Amikor a Modellfigyelőbe migrál, ha nem éles környezetben telepítette a modellt egy Online Azure Machine Learning-végponton, vagy nem szeretne adatgyűjtést használni, a modellfigyelést egyéni jelekkel és metrikákkal is beállíthatja.
Ha nem rendelkezik üzembe helyezéssel, de éles adatokkal rendelkezik, az adatokkal folyamatos modellfigyelést végezhet. A modellek monitorozásához képesnek kell lennie a következőkre:
- Termelési következtetési adatok gyűjtése az éles környezetben üzembe helyezett modellekből.
- Regisztrálja az éles következtetési adatokat Azure Machine Learning-adategységként, és biztosítsa az adatok folyamatos frissítését.
- Adjon meg egy egyéni adatelőfeldolgozási összetevőt, és regisztrálja azt Azure Machine Learning-összetevőként.
Egyéni adat-előfeldolgozási összetevőt kell megadnia, ha az adatokat nem gyűjti össze az adatgyűjtő. Az egyéni adatelőfeldolgozási összetevő nélkül az Azure Machine Learning-modell monitorozási rendszere nem fogja tudni, hogyan dolgozhatja fel az adatokat táblázatos formában az időkeretek támogatásával.
Az egyéni előfeldolgozási összetevőnek a következő bemeneti és kimeneti aláírásokkal kell rendelkeznie:
| Bemenet/kimenet | Aláírás neve | Típus | Leírás | Példaérték |
|---|---|---|---|---|
| bemenet | data_window_start |
literál, sztring | ISO8601 formátumban. | 2023-05-01T04:31:57.012Z |
| bemenet | data_window_end |
literál, sztring | ISO8601 formátumban. | 2023-05-01T04:31:57.012Z |
| bemenet | input_data |
uri_folder | Az összegyűjtött éles következtetési adatok, amelyek Azure Machine Learning-adategységként regisztrálva lesznek. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Táblázatos adatkészlet, amely megfelel a referenciaadat-séma egy részhalmazának. |
Egy egyéni adatelőfeldolgozási összetevőre példa: custom_preprocessing az azuremml-examples GitHub-adattárban.
Az adateltolódási eredmények ismertetése
Ez a szakasz egy adathalmaz monitorozásának eredményeit mutatja be, amely az Adathalmazok / adatkészlet monitorozása lapon található az Azure Studióban. Ezen a lapon frissítheti a beállításokat, és elemezheti a meglévő adatokat egy adott időszakra vonatkozóan.
Kezdje a legfelső szintű elemzésekkel az adateltolódás nagyságával és a további vizsgálandó funkciók kiemelésével.
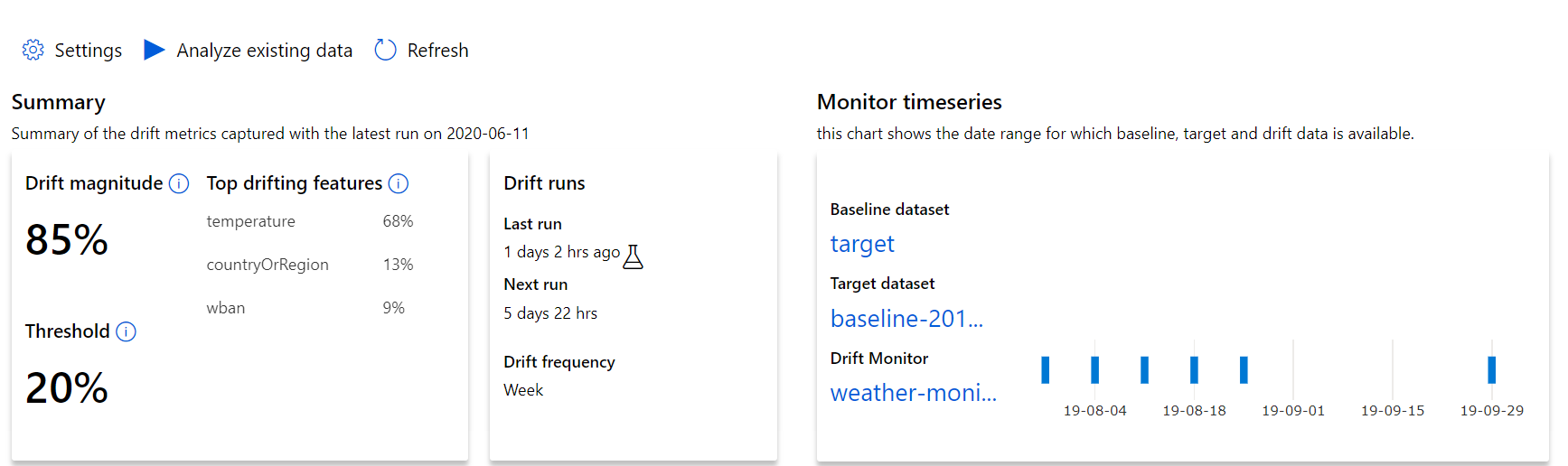
| Metrika | Leírás |
|---|---|
| Adateltolódás mértéke | Az alapkonfiguráció és a céladatkészlet közötti időbeli eltérés százalékos aránya. Ez a százalékos érték 0 és 100 között mozog, a 0 azonos adathalmazokat, a 100 pedig azt jelzi, hogy az Azure Machine Learning adateltolódási modellje teljesen képes megkülönböztetni a két adathalmazt. A pontos százalékban mért zaj várható az ilyen mértékű gépi tanulási technikák miatt. |
| A legfontosabb elsodródási funkciók | Az adathalmaz azon funkcióit jeleníti meg, amelyek a legtöbbet sodródtak, és ezért a legtöbbet járulnak hozzá az elsodródási magnitúdó metrikáihoz. A kovariansátumok eltolódása miatt a funkció mögöttes eloszlásának nem feltétlenül kell változnia ahhoz, hogy viszonylag nagy fontossággal rendelkezzen. |
| Küszöbérték | A megadott küszöbértéken túli adateltolódás riasztásokat aktivál. Konfigurálja a küszöbértéket a figyelő beállításai között. |
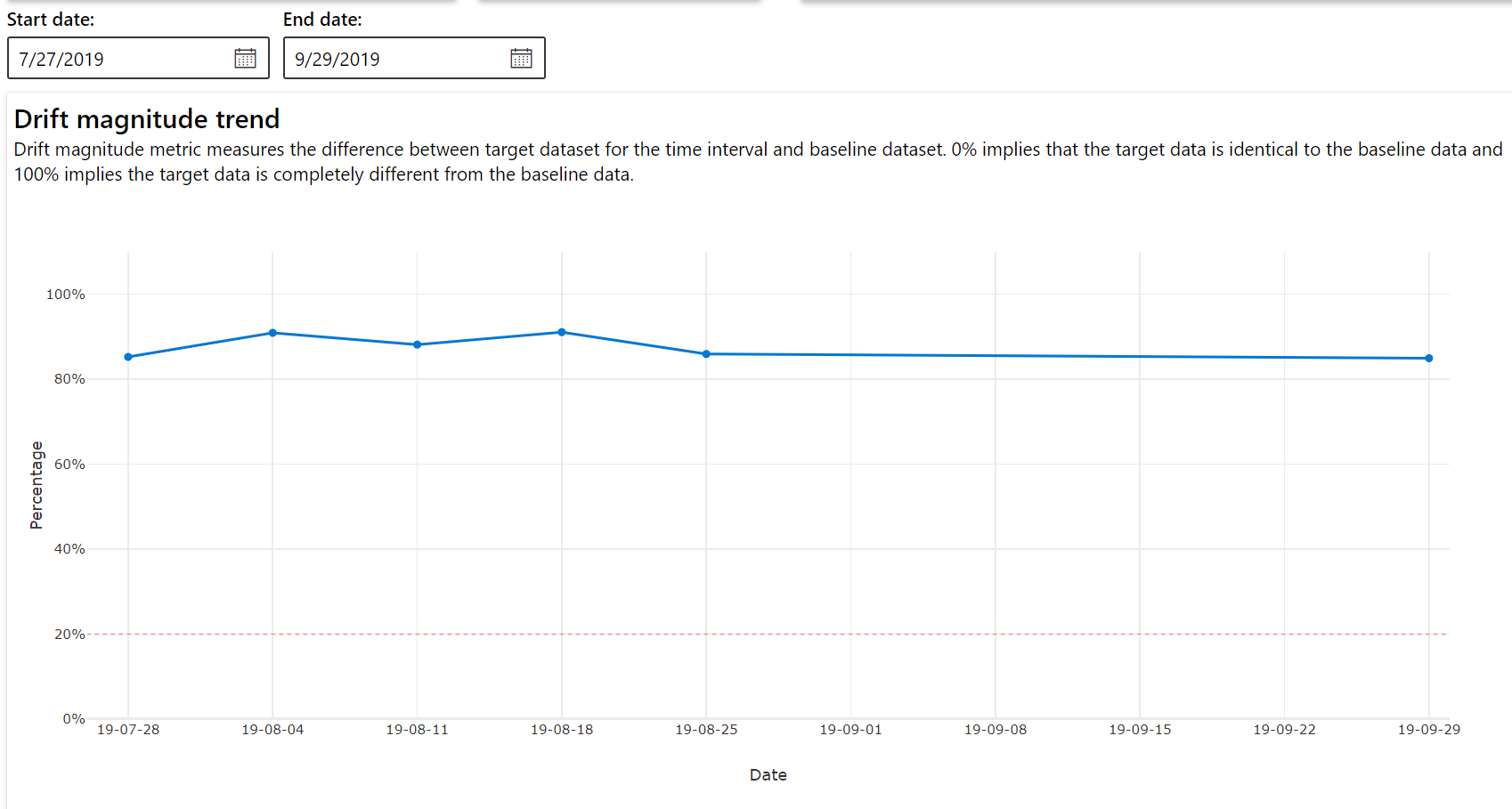
Sodródási magnitúdó trend
Megtudhatja, hogy az adathalmaz miben különbözik a céladatkészlettől a megadott időszakban. Minél közelebb van a 100%-hoz, annál inkább különbözik a két adathalmaz.
Elsodródás mértéke funkciók szerint
Ez a szakasz funkciószintű elemzéseket tartalmaz a kiválasztott szolgáltatás eloszlásának változásával és az egyéb statisztikák időbeli változásával kapcsolatban.
A céladatkészlet is profilozott az idő függvényében. Az egyes funkciók alapkonfigurációs eloszlása közötti statisztikai távolságot összehasonlítjuk a céladatkészlet időbeli eloszlásával. Elméletileg ez hasonlít az adateltolódás mértékére. Ez a statisztikai távolság azonban nem az összes jellemző, hanem egy adott jellemző esetében van. A minimális, a maximális és a középérték is elérhető.
Az Azure Machine Learning Studióban válasszon egy sávot a grafikonon az adott dátum funkciószintű részleteinek megtekintéséhez. Alapértelmezés szerint az alapadatkészlet eloszlása és a legutóbbi feladat eloszlása jelenik meg ugyanahhoz a funkcióhoz.
Ezek a metrikák a Python SDK-ban is lekérhetők egy get_metrics() DataDriftDetector objektum metódusán keresztül.
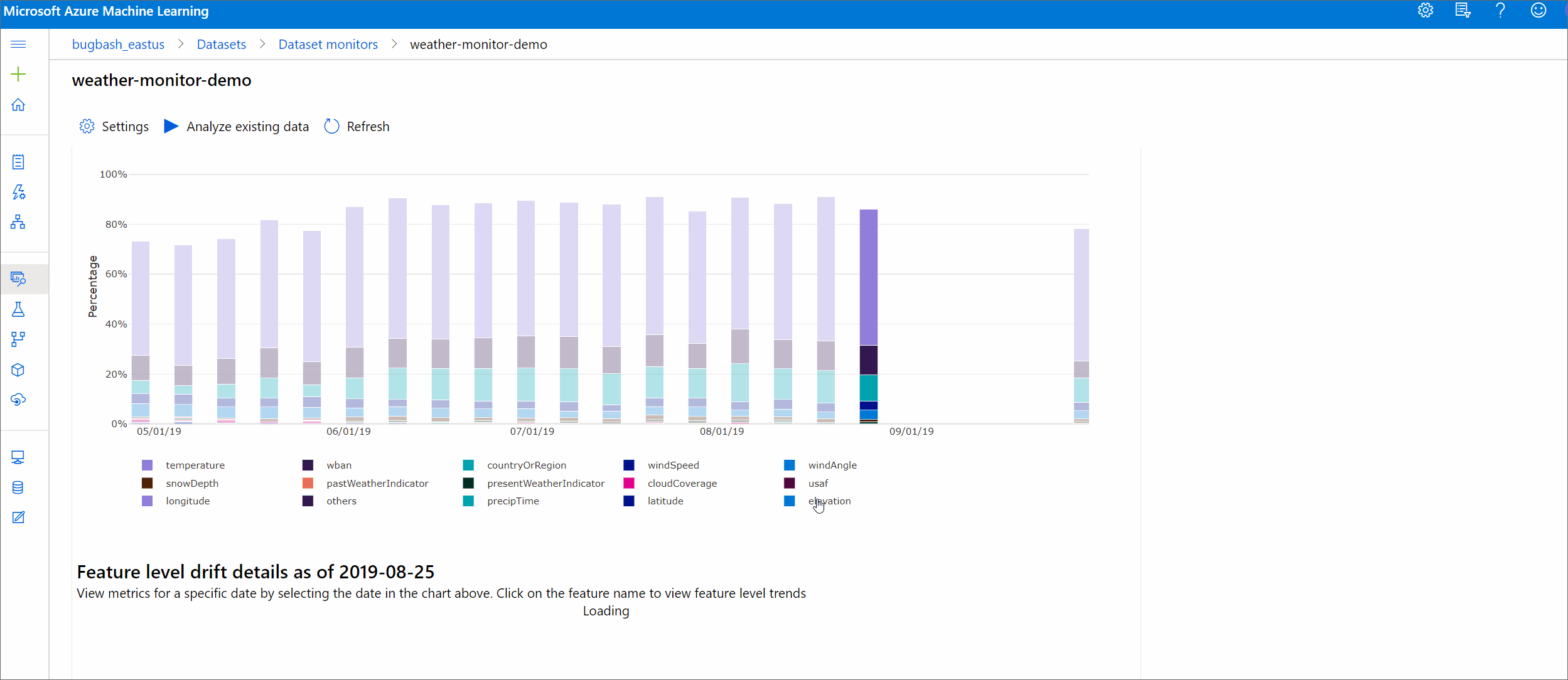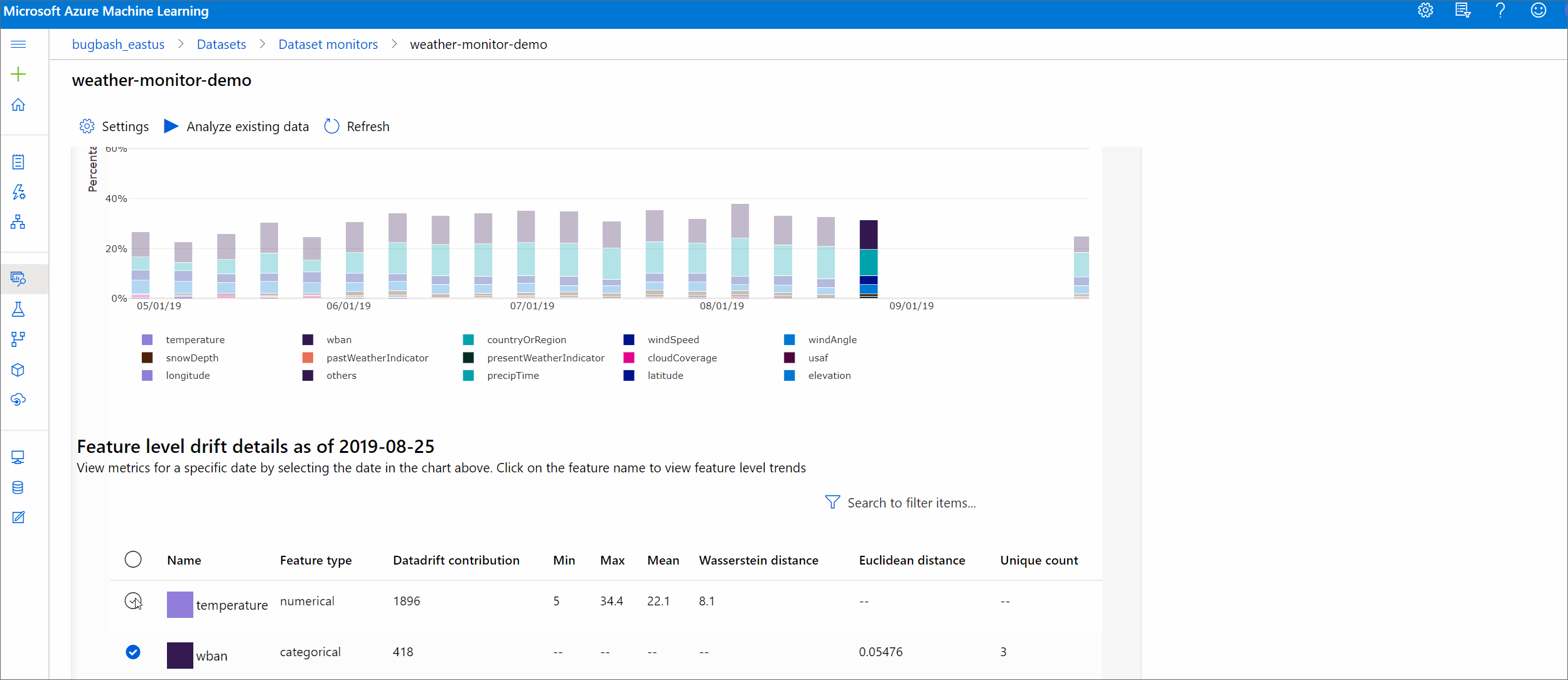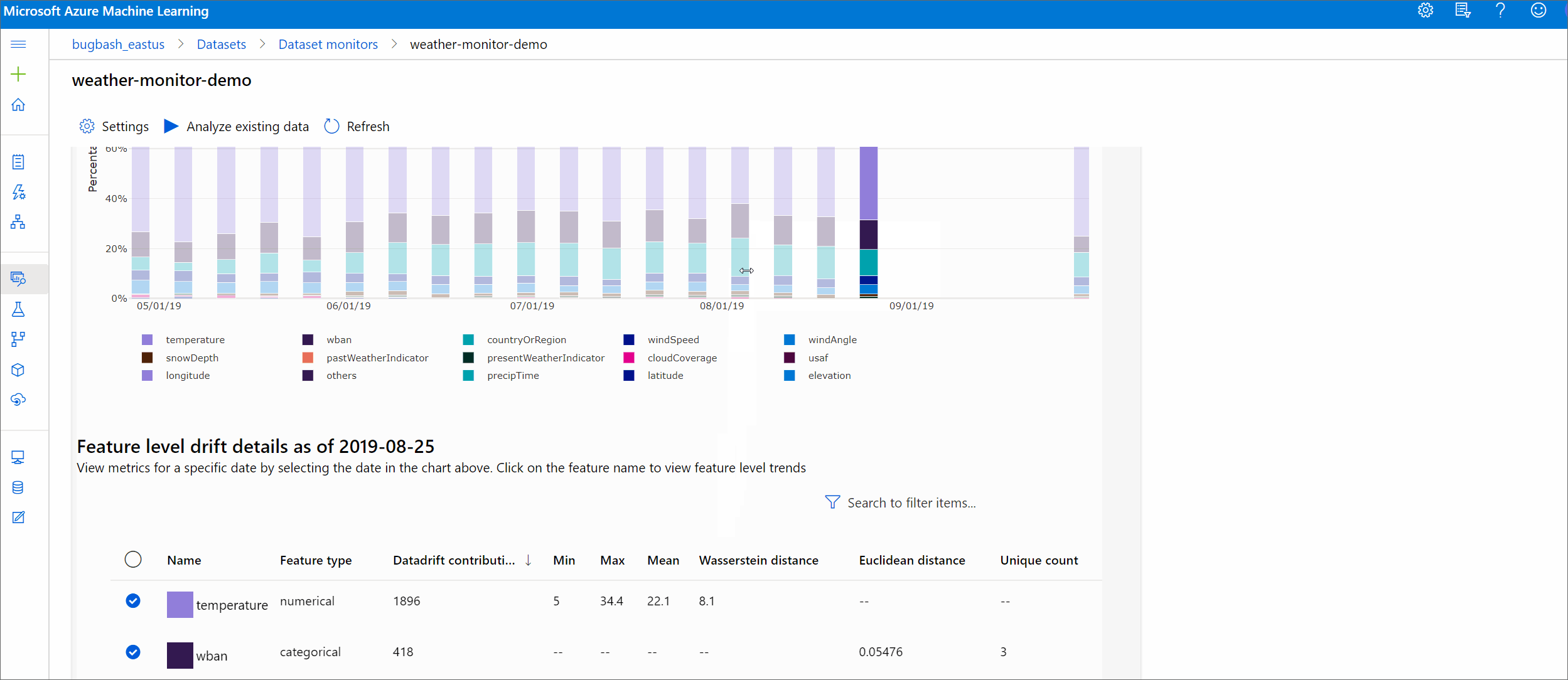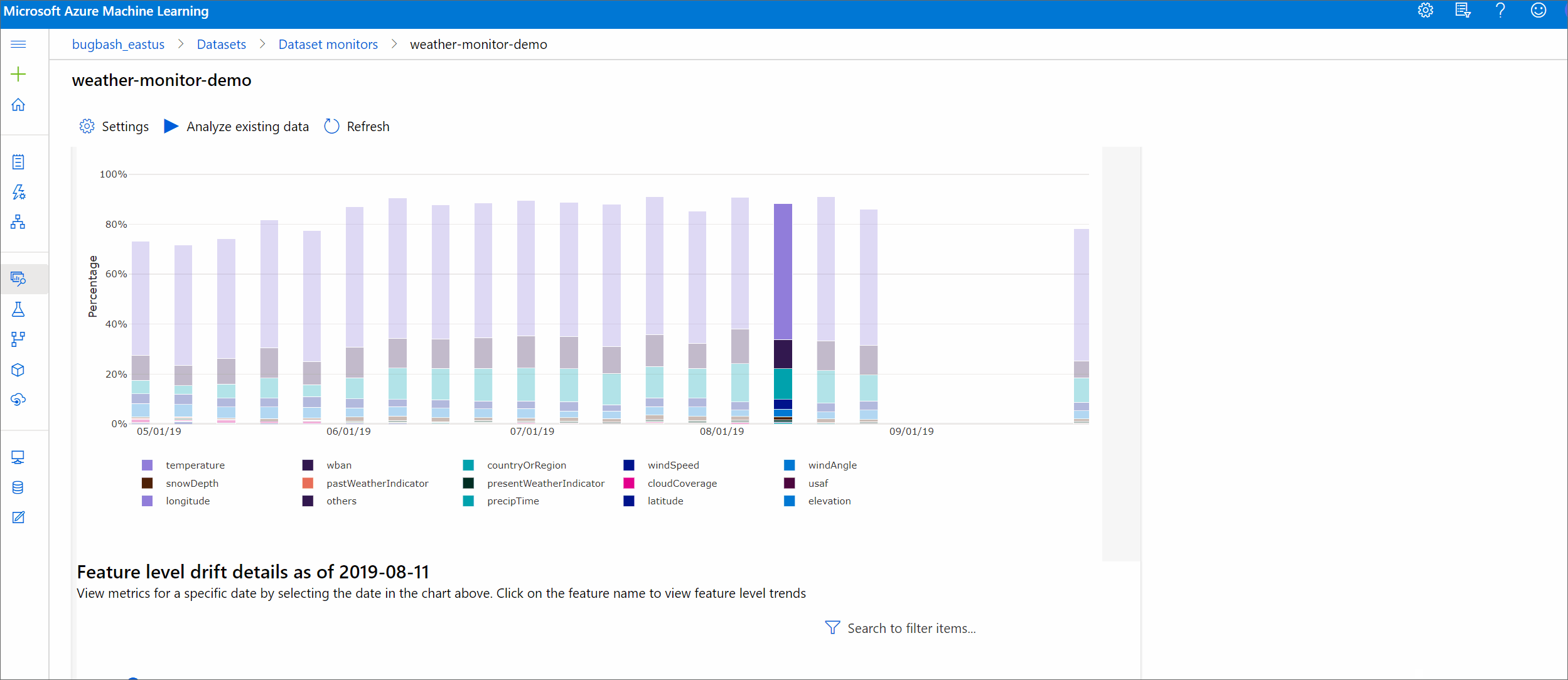
Szolgáltatás részletei
Végül görgessen le az egyes funkciók részleteinek megtekintéséhez. A diagram feletti legördülő menükkel jelölje ki a funkciót, és válassza ki a megtekinteni kívánt metrikát is.
A diagram metrikái a funkció típusától függenek.
Numerikus funkciók
Metrika Leírás Wasserstein távolság Minimális munkamennyiség az alapszintű eloszlás céleloszlássá alakításához. Középérték A szolgáltatás átlagos értéke. Minimális érték A szolgáltatás minimális értéke. Maximális érték A funkció maximális értéke. Kategorikus funkciók
Metrika Leírás Euklideszi távolság Kategorikus oszlopokhoz számítva. Az euklideszi távolság kiszámítása két vektoron történik, amely ugyanazon kategorikus oszlop empirikus eloszlásából jön létre két adatkészletből. A 0 nem jelez különbséget az empirikus eloszlásokban. Minél jobban eltér a 0-tól, annál jobban elsodródott ez az oszlop. A trendek a metrika idősordiagramjából figyelhetők meg, és hasznosak lehetnek egy sodródó funkció feltárásában. Egyedi értékek A funkció egyedi értékeinek száma (számossága).
Ezen a diagramon egyetlen dátumot jelöljön ki a cél és a megjelenített funkció funkcióeloszlásának összehasonlításához. Numerikus jellemzők esetén ez két valószínűségeloszlást jelenít meg. Ha a funkció numerikus, megjelenik egy sávdiagram.
Metrikák, riasztások és események
A metrikák lekérdezhetők a gépi tanulási munkaterülethez társított Azure-alkalmazás Insights-erőforrásban. Hozzáféréssel rendelkezik az Application Insights összes funkcióhoz, beleértve az egyéni riasztási szabályok és műveleti csoportok beállítását egy művelet, például e-mail/SMS/Push/Voice vagy Azure-függvény aktiválásához. A részletekért tekintse meg az Application Insights teljes dokumentációját.
Első lépésként keresse meg az Azure Portalt, és válassza ki a munkaterület Áttekintés lapját. A társított Application Insights-erőforrás a jobb szélen található:

Válassza a Naplók (Elemzés) lehetőséget a figyelés alatt a bal oldali panelen:
Az adathalmaz monitorozási metrikái a következőképpen vannak tárolva customMetrics: . Miután beállította az adathalmaz-figyelőt, megírhat és futtathat lekérdezést, hogy megtekinthesse őket:

Miután azonosította a metrikákat a riasztási szabályok beállításához, hozzon létre egy új riasztási szabályt:
Használhat egy meglévő műveletcsoportot, vagy létrehozhat egy újat a megadott feltételek teljesülése esetén végrehajtandó művelet meghatározásához:
Hibaelhárítás
Az adateltolódás-figyelők korlátozásai és ismert problémái:
Az előzményadatok elemzésekor az időtartomány a monitor gyakorisági beállításának 31 intervallumára korlátozódik.
200 funkció korlátozása, kivéve, ha nincs megadva egy funkciólista (az összes használt funkció).
A számítási méretnek elég nagynak kell lennie az adatok kezeléséhez.
Győződjön meg arról, hogy az adathalmaz egy adott figyelőfeladat kezdő és záró dátumán belül rendelkezik adatokkal.
Az adathalmaz-figyelők csak olyan adathalmazokon működnek, amelyek legalább 50 sort tartalmaznak.
Az adathalmaz oszlopai vagy funkciói kategorikus vagy numerikus besorolásúak az alábbi táblázatban szereplő feltételek alapján. Ha a szolgáltatás nem felel meg ezeknek a feltételeknek – például egy 100 egyedi értékkel rendelkező >típussztring oszlopa –, a funkció el lesz távolítva az adateltolódási algoritmusból, de továbbra is profilozott.
Szolgáltatás típusa Adattípus Feltétel Korlátozások Kategorikus húr A funkció egyedi értékeinek száma kisebb, mint 100, és kevesebb, mint a sorok számának 5%-a. A null a saját kategóriája. Numerikus int, float A funkció értékei numerikus adattípusúak, és nem felelnek meg a kategorikus funkciók feltételének. Ha az értékek 15%-a null értékű, a >funkció el lett hagyva. Ha létrehozott egy adatelsodrési monitort, de nem látja az adatokat az Adathalmaz-monitorok lapon az Azure Machine Learning Studióban, próbálkozzon az alábbiakkal.
- Ellenőrizze, hogy a lap tetején a megfelelő dátumtartományt választotta-e ki.
- Az Adathalmaz figyelői lapon válassza a kísérlet hivatkozását a feladat állapotának ellenőrzéséhez. Ez a hivatkozás a táblázat jobb szélén található.
- Ha a feladat sikeresen befejeződött, ellenőrizze az illesztőprogram-naplókban, hogy hány metrikát hoztak létre, vagy hogy vannak-e figyelmeztető üzenetek. A kísérlet kiválasztása után keresse meg az illesztőprogram-naplókat a Kimenet + naplók lapon.
Ha az SDK-függvény
backfill()nem hozza létre a várt kimenetet, lehet, hogy hitelesítési probléma miatt. Amikor létrehoz egy számítást a függvénybe való továbbításhoz, ne használjaRun.get_context().experiment.workspace.compute_targetsa függvényt. Ehelyett a Következőhöz hasonló ServicePrincipalAuthentication használatával hozza létre a függvénybebackfill()átadott számítást:
Feljegyzés
Ne kódozza be a szolgáltatásnév jelszavát a kódban. Ehelyett kérje le a Python-környezetből, a kulcstárolóból vagy a titkos kódok elérésének más biztonságos módszeréből.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
A Modelladat-gyűjtőből akár 10 percet is igénybe vehet, amíg az adatok megérkeznek a Blob Storage-fiókba. Ez azonban általában kevesebb időt vesz igénybe. Egy szkriptben vagy jegyzetfüzetben várjon 10 percet, hogy az alábbi cellák sikeresen fussanak.
import time time.sleep(600)
Következő lépések
- Lépjen az Azure Machine Learning Studióba vagy a Python-jegyzetfüzetbe egy adathalmaz-monitor beállításához.
- Megtudhatja, hogyan állíthat be adateltolódást az Azure Kubernetes Service-ben üzembe helyezett modelleken.
- Adathalmazok eltérésfigyelőinek beállítása az Azure Event Grid használatával.