Hozzáférés az adatokhoz egy feladatban
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Ebből a cikkből megtudhatja:
- Adatok beolvasása az Azure Storage-ból egy Azure Machine Learning-feladatban.
- Adatok írása az Azure Machine Learning-feladatból az Azure Storage-ba.
- A csatlakoztatási és letöltési módok közötti különbség.
- Felhasználói identitás és felügyelt identitás használata az adatok eléréséhez.
- A feladatban elérhető csatlakoztatási beállítások.
- Optimális csatlakoztatási beállítások gyakori forgatókönyvekhez.
- V1-adategységek elérése.
Előfeltételek
Azure-előfizetés. Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot. Próbálja ki az Azure Machine Learning ingyenes vagy fizetős verzióját.
Egy Azure Machine Learning-munkaterület
Gyorsútmutató
Mielőtt áttekintené az adatok elérésekor elérhető részletes lehetőségeket, először ismertetjük az adathozzáféréshez szükséges kódrészleteket.
Adatok olvasása az Azure Storage-ból egy Azure Machine Learning-feladatban
Ebben a példában egy Olyan Azure Machine Learning-feladatot küld el, amely egy nyilvános blobtároló-fiókból fér hozzá az adatokhoz. A kódrészletet azonban úgy is módosíthatja, hogy egy privát Azure Storage-fiókban hozzáférjen a saját adataihoz. Frissítse az elérési utat az itt leírtak szerint. Az Azure Machine Learning zökkenőmentesen kezeli a felhőbeli tárterületen történő hitelesítést a Microsoft Entra átengedésével. Feladat elküldésekor a következő lehetőségek közül választhat:
- Felhasználói identitás: A Microsoft Entra-identitás átadása az adatok eléréséhez
- Felügyelt identitás: A számítási cél felügyelt identitásának használata az adatok eléréséhez
- Nincs: Ne adjon meg identitást az adatok eléréséhez. A Nincs használata hitelesítőadat-alapú (kulcs-/SAS-jogkivonat) adattárak használatakor vagy nyilvános adatok elérésekor
Tipp.
Ha kulcsokat vagy SAS-jogkivonatokat használ a hitelesítéshez, javasoljuk, hogy hozzon létre egy Azure Machine Learning-adattárat, mert a futtatókörnyezet automatikusan csatlakozik a tárolóhoz a kulcs/jogkivonat felfedése nélkül.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Adatok írása az Azure Machine Learning-feladatból az Azure Storage-ba
Ebben a példában elküld egy Azure Machine Learning-feladatot, amely adatokat ír az alapértelmezett Azure Machine Learning Datastore-ba. Igény szerint beállíthatja az name adategység értékét, hogy létrehozhasson egy adategységet a kimenetben.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Az Azure Machine Learning adat-futtatókörnyezete
Feladat elküldésekor az Azure Machine Learning adat-futtatókörnyezete szabályozza az adatbetöltést a tárolási helytől a számítási célig. Az Azure Machine Learning adat-futtatókörnyezete a gépi tanulási feladatok sebességére és hatékonyságára van optimalizálva. A fő előnyök többek között:
- Az adatok betöltése a Rust nyelven, a nagy sebességről és a nagy memóriahatékonyságról ismert nyelvről ismert. Az egyidejű adatletöltések esetén Rust elkerüli a Python globális értelmező zárolási (GIL) problémáit
- Könnyű súly; A rust nem függ más technológiáktól , például JVM-hez. Ennek eredményeképpen a futtatókörnyezet gyorsan telepedik, és nem ürít ki extra erőforrásokat (CPU, memória) a számítási célhoz
- Többfolyamatos (párhuzamos) adatbetöltés
- Az adatok előzetes beállítása háttérfeladatként a PROCESSZOR(ok)on, a GPU(k) jobb kihasználtságának lehetővé tétele mély tanuláskor
- Zökkenőmentes hitelesítés kezelése a felhőbeli tárterületen
- Lehetővé teszi az adatok csatlakoztatását (stream) vagy az összes adat letöltését. További információkért látogasson el a Csatlakoztatás (streamelés) és a Letöltés szakaszra.
- Zökkenőmentes integráció az fsspectel – egységes pythonikus interfész helyi, távoli és beágyazott fájlrendszerekhez és bájttárolókhoz.
Tipp.
Javasoljuk, hogy az Azure Machine Learning adat-futtatókörnyezetét használja ahelyett, hogy saját csatlakoztatási/letöltési képességet hozna létre a betanítási (ügyfél-) kódban. Megfigyeltük a tároló átviteli sebességére vonatkozó korlátozásokat, amikor az ügyfélkód a Python használatával tölti le az adatokat a tárolóból a Global Interpret Lock (GIL) problémák miatt.
Elérési utak
Amikor adatbemenetet/kimenetet ad meg egy feladathoz, meg kell adnia egy paramétert path , amely az adathelyre mutat. Ez a táblázat az Azure Machine Learning által támogatott különböző adathelyeket mutatja be, és példákat is mutat path a paraméterekre:
| Hely | Példák | Bevitel | Hozam |
|---|---|---|---|
| Elérési út a helyi számítógépen | ./home/username/data/my_data |
I | N |
| Elérési út egy nyilvános HTTP-kiszolgálón | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
I | N |
| Elérési út az Azure Storage-ban | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, csak identitásalapú hitelesítéshez. | N |
| Egy Azure Machine Learning Datastore elérési útja | azureml://datastores/<data_store_name>/paths/<path> |
I | I |
| Adategység elérési útja | azureml:<my_data>:<version> |
I | N, de name használhatja és version létrehozhat egy adategységet a kimenetből |
Módok
Amikor adatbemenetekkel/kimenetekkel futtat egy feladatot, az alábbi módok közül választhat:
ro_mount: A tárolóhely csatlakoztatása írásvédettként a helyi lemez (SSD) számítási célhelyén.rw_mount: Csatlakoztassa a tárolóhelyet írás-olvasás céljából a helyi lemez (SSD) számítási célhelyén.download: Töltse le az adatokat a tárolási helyről a helyi lemez (SSD) számítási célhelyére.upload: Adatok feltöltése a számítási célról a tárolóhelyre.eval_mount/eval_download: Ezek a módok egyediek az MLTable-ra. Bizonyos esetekben az MLTable olyan fájlokat hozhat létre, amelyek az MLTable-fájlt futtató tárfióktól eltérő tárfiókban találhatók. Vagy az MLTable a tárolási erőforrásban található adatok részhalmazát vagy osztását is végezheti. Az alkészlet/shuffle nézet csak akkor válik láthatóvá, ha az Azure Machine Learning-adatfuttatás ténylegesen kiértékeli az MLTable-fájlt. Ez a diagram például azt mutatja be, hogy egy MLTable hogyan használhatóeval_mountvagyeval_downloadkészíthet képeket két különböző tárolóból, valamint egy másik tárfiókban található széljegyzetfájlt, majd hogyan csatlakoztathatja/töltheti le a távoli számítási cél fájlrendszerét.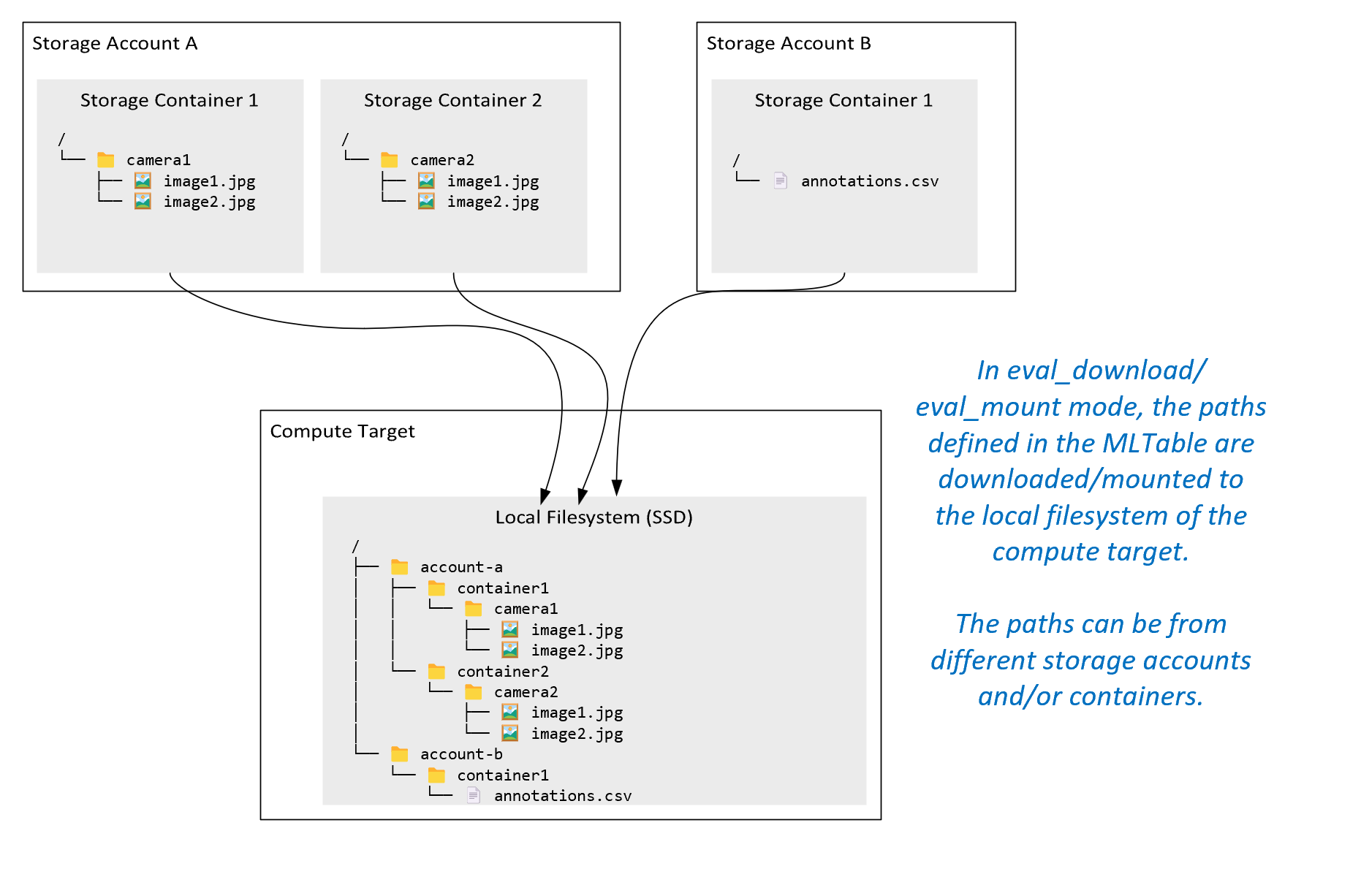
A
camera1mappa,camera2mappa ésannotations.csvfájl ezután elérhető a számítási cél fájlrendszerén a mappastruktúrában:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Érdemes lehet közvetlenül az URI-ból más API-kon keresztül beolvasni az adatokat, nem pedig az Azure Machine Learning adat-futtatókörnyezetét. Előfordulhat például, hogy a boto s3-ügyféllel szeretne hozzáférni egy s3-gyűjtő adataihoz (virtuálisan üzemeltetett stílussal vagy elérésiút-stílusúhttpsURL-címmel). A bemenet URI-ja sztringként lekérhető adirectmóddal. A Spark-feladatokban a közvetlen mód használata látható, mert aspark.read_*()metódusok tudják, hogyan kell feldolgozni az URI-kat. A nem Spark-feladatok esetében az Ön feladata a hozzáférési hitelesítő adatok kezelése. Például explicit módon kell használnia a számítási MSI-t, vagy más módon közvetítői hozzáférést kell használnia.

Ez a táblázat a különböző típus-/mód-/bemeneti/kimeneti kombinációk lehetséges módjait mutatja be:
| Típus | Bemenet/kimenet | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Bevitel | ✓ | ✓ | ✓ | ||||
uri_file |
Bevitel | ✓ | ✓ | ✓ | ||||
mltable |
Bevitel | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Kimenet | ✓ | ✓ | |||||
uri_file |
Kimenet | ✓ | ✓ | |||||
mltable |
Kimenet | ✓ | ✓ | ✓ |
Letöltés
Letöltési módban a rendszer az összes bemeneti adatot a számítási cél helyi lemezére (SSD) másolja. Az Azure Machine Learning adat-futtatókörnyezete elindítja a felhasználói betanítási szkriptet az összes adat másolása után. Amikor a felhasználói szkript elindul, az adatokat a helyi lemezről olvassa be, ugyanúgy, mint bármely más fájlt. Amikor a feladat befejeződik, az adatok törlődnek a számítási cél lemezéről.
| Előnyök | Hátrányok |
|---|---|
| A betanítás indításakor az összes adat elérhető a számítási cél helyi lemezén (SSD) a betanítási szkripthez. Nincs szükség Azure Storage/hálózati interakcióra. | Az adatkészletnek teljesen el kell férnie egy számítási céllemezen. |
| A felhasználói szkript elindítása után nincsenek függőségek a tárolástól és a hálózati megbízhatóságtól. | A teljes adatkészlet letöltődik (ha a betanításnak csak egy kis részét kell véletlenszerűen kiválasztania, akkor a letöltés nagy része elpazarlódik). |
| Az Azure Machine Learning adat-futtatókörnyezete párhuzamossá teheti a letöltést (sok kis fájl esetében jelentős különbség) és a maximális hálózati/ tárolási átviteli sebességet. | A feladat megvárja, amíg az összes adat le nem tölthető a számítási cél helyi lemezére. Egy beküldött mélytanulási feladat esetében a GPU-k tétlenek, amíg az adatok készen nem állnak. |
| A FUSE réteg nem ad hozzá elkerülhetetlen többletterhelést (roundtrip: felhasználói hely hívása felhasználói szkriptben → kernel → felhasználói térbeli biztosíték démon → kernel → válasz a felhasználói szkriptre a felhasználói térben) | A tárolási változások a letöltés után nem jelennek meg az adatokon. |
Mikor érdemes használni a letöltést?
- Az adatok elég kicsik ahhoz, hogy elférjenek a számítási cél lemezén anélkül, hogy zavarják az egyéb betanításokat
- A betanítás a legtöbb vagy az összes adatkészletet használja
- A betanítás többször olvas be fájlokat egy adathalmazból
- A betanításnak egy nagy fájl véletlenszerű pozícióira kell ugrania
- A betanítás megkezdése előtt érdemes megvárni az összes adatletöltést
Elérhető letöltési beállítások
A letöltési beállításokat az alábbi környezeti változókkal hangolhatja a feladatban:
| Környezeti változó neve | Típus | Alapértelmezett érték | Leírás |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Az egyidejűleg letölthető szálak száma |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Az egyes tárolók / http kérések átmeneti hibákból való helyreállítására irányuló újrapróbálkozási kísérletek száma. |
A feladatban módosíthatja a fenti alapértelmezett értékeket a környezeti változók beállításával – például:
A rövidség kedvéért csak azt mutatjuk be, hogyan definiálhatók a környezeti változók a feladatban.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Teljesítménymetrikák letöltése
A számítási cél virtuálisgép-mérete hatással van az adatok letöltési idejére. Ezek konkrétan a következők:
- A magok száma. Minél több mag érhető el, annál több egyidejűség és ezáltal gyorsabb letöltési sebesség.
- A várt hálózati sávszélesség. Az Azure-ban minden virtuális gép maximális átviteli sebességgel rendelkezik a hálózati adapterről (NIC).
Feljegyzés
Az A100 GPU-s virtuális gépek esetében az Azure Machine Learning adat-futtatókörnyezete képes telítetté tenni a hálózati adaptert (hálózati adaptert), amikor adatokat tölt le a számítási célra (~24 Gbit/s): A lehetséges elméleti maximális átviteli sebesség.
Ez a táblázat azt mutatja be, hogy az Azure Machine Learning adat-futtatókörnyezete milyen letöltési teljesítményt képes kezelni egy virtuális gépen található 100 GB-os fájlhoz Standard_D15_v2 (20 mag, 25 Gbit/s hálózati átviteli sebesség):
| Adatszerkezet | Csak letöltés (mps) | MD5 letöltése és kiszámítása (mps) | Elért átviteli sebesség (Gbit/s) |
|---|---|---|---|
| 10 x 10 GB-os fájlok | 55.74 | 260.97 | 14,35 Gbit/s |
| 100 x 1 GB-os fájlok | 58.09 | 259.47 | 13,77 Gbit/s |
| 1 x 100 GB-os fájl | 96.13 | 300.61 | 8,32 Gbit/s |
Láthatjuk, hogy egy nagyobb, kisebb fájlokra bontott fájl a párhuzamosság miatt javíthatja a letöltési teljesítményt. Javasoljuk, hogy kerülje a túl kicsi (4 MB-nál kisebb) fájlokat, mert a tárkérelmek beküldéséhez szükséges idő megnő a hasznos adat letöltésével töltött időhöz képest. További információ: Sok kis fájllal kapcsolatos probléma.
Csatlakoztatás (streamelés)
Csatlakoztatási módban az Azure Machine Learning adatképessége a FUSE (fájlrendszer a felhasználói térben) Linux szolgáltatással hoz létre emulált fájlrendszert. Ahelyett, hogy az összes adatot letölti a számítási cél helyi lemezére (SSD), a futtatókörnyezet valós időben reagálhat a felhasználó szkriptműveleteire. Például: "open file", "read 2-KB chunk from position X", "list directory content".
| Előnyök | Hátrányok |
|---|---|
| A számítási cél helyi lemezkapacitását meghaladó adatok használhatók (a számítási hardver nem korlátozza) | A Linux FUSE modul többletterhelése. |
| Nincs késés a betanítás kezdetekor (a letöltési móddal ellentétben). | A felhasználó kódjának viselkedésétől való függőség (ha a kis fájlokat egyetlen szálon egymás után beolvasó betanítási kód is adatokat kér a tárolóból, előfordulhat, hogy nem maximalizálja a hálózat vagy a tároló átviteli sebességét). |
| További elérhető beállítások a használati forgatókönyvhöz való finomhangoláshoz. | Nincs windows-támogatás. |
| Csak a betanításhoz szükséges adatok olvashatók a tárolóból. |
Mikor érdemes használni a Csatlakoztatást?
- Az adatok nagyok, és nem férnek el a számítási cél helyi lemezén.
- A fürt minden egyes számítási csomópontjának nem kell beolvasnia a teljes adatkészletet (véletlenszerű fájl vagy sorok a CSV-fájl kiválasztásában stb.).
- A betanítás megkezdése előtt az összes adat letöltésére váró késések problémát okozhatnak (tétlen GPU-idő).
Elérhető csatlakoztatási beállítások
A csatlakoztatási beállításokat az alábbi környezeti változókkal hangolhatja a feladatban:
| Változó neve irigylésre | Típus | Alapértelmezett érték | Leírás |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Nincs beállítva (a gyorsítótár soha nem jár le) | Ezredmásodpercben a hívás eredményének getattr gyorsítótárban tartásához és az adatok további kéréseinek a storage-ból való ismételt elkerüléséhez szükséges idő szükséges. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Rendszerkonfigurációra szánt, a számítás kifogástalan állapotának megőrzésére szolgál. A többi beállítás értékeitől függetlenül az Azure Machine Learning adat-futtatókörnyezete nem használja az utolsó RESERVED_FREE_DISK_SPACE bájtnyi lemezterületet. |
DATASET_MOUNT_CACHE_SIZE |
usize | Korlátlan | Szabályozza, hogy mennyi lemezterület-csatlakoztatás használható. A pozitív érték bájtban állítja be az abszolút értéket. A negatív érték azt határozza meg, hogy a lemezterület mekkora részét szabadítsuk fel. Ez a táblázat további lemezgyorsítótár-beállításokat biztosít. MB A kényelem érdekében támogatja KBés GB módosítja a módosításokat. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | A kötet csatlakoztatása elindítja a gyorsítótár metszését, amikor a gyorsítótár fel van töltve.AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD 0 és 1 között kell lennie. < Az 1 beállítás korábban aktiválja a háttér-gyorsítótár metszését. AVAILABLE_CACHE_SIZE nem olyan környezeti változó, amelyet közvetlenül módosíthat vagy megtekinthet. Ebben a kontextusban "a rendszer által a gyorsítótárazáshoz elérhetőként kiszámított bájtok száma". Ez az érték olyan tényezőktől függ, mint a lemez mérete, a rendszerállapothoz szükséges lemezterület mennyisége, valamint a környezeti változókban (például DATASET_RESERVED_FREE_DISK_SPACE és DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | A gyorsítótár metszése megpróbál legalább (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) felszabadítani egy gyorsítótárterületet. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Streamelt olvasási blokk mérete. Ha a fájl elég nagy, kérjen legalább DATASET_MOUNT_READ_BLOCK_SIZE adatokat a tárolóból, és gyorsítótárazza még akkor is, ha a biztosíték olvasási műveletet kért kevesebbért. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Az előkezeléshez használandó blokkok száma (a k olvasási blokk aktiválja a k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNTblokkok háttér-előkezelését) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
A háttérbeli előkezelés szálainak száma. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
logikai | false | Blokkalapú gyorsítótárazás engedélyezése. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Csak a blokkalapú gyorsítótárazásra vonatkozik. A RAM blokkalapú gyorsítótárazásának mérete használható. A 0 érték teljesen letiltja a memória gyorsítótárazását. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
logikai | true | Csak a blokkalapú gyorsítótárazásra vonatkozik. Ha igaz értékre van állítva, a blokkalapú gyorsítótárazás helyi merevlemezt használ a blokkok gyorsítótárazásához. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Csak a blokkalapú gyorsítótárazásra vonatkozik. A blokkalapú gyorsítótárazás gyorsítótárazott blokkot ír egy helyi lemezre a háttérben. Ez a beállítás azt szabályozza, hogy a memória csatlakoztatása mennyi memóriát képes tárolni a helyi lemezgyorsítótárba való kiürítésre váró blokkok tárolására. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Csak a blokkalapú gyorsítótárazásra vonatkozik. A háttérszálak blokkalapú gyorsítótárazásának száma a letöltött blokkok a számítási cél helyi lemezére való írásához. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Az összes függőben lévő művelet (például a hívások kiürítése) befejezéséhez unmount szükséges idő másodpercben, mielőtt a csatlakoztatási üzenet hurkot kényszerítve leállítanák. |
A feladatban módosíthatja a fenti alapértelmezett értékeket a környezeti változók beállításával, például:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Blokkalapú megnyitási mód
A blokkalapú megnyitási mód az egyes fájlokat előre definiált méretű blokkokra osztja fel (az utolsó blokk kivételével). Egy adott pozícióból érkező olvasási kérés egy megfelelő blokkot kér a tárból, és azonnal visszaadja a kért adatokat. Az olvasás az N következő blokkok háttérbeli előkezelését is aktiválja több szál használatával (szekvenciális olvasásra optimalizálva). A letöltött blokkok gyorsítótárazva vannak két rétegbeli gyorsítótárban (RAM és helyi lemez).
| Előnyök | Hátrányok |
|---|---|
| Gyors adatkézbesítés a betanítási szkriptbe (kevesebb blokkolás a még nem kért adattömbök esetében). | A véletlenszerű olvasások előre előkészített blokkokat pazarolhatnak. |
| További munkakiszervezések a háttérszálakra (előkezelés/ gyorsítótárazás). A betanítás ezután folytatódhat. | A gyorsítótárak közötti navigáláshoz hozzáadott többletterhelés a helyi lemezgyorsítótárban lévő fájlok közvetlen olvasásához képest (például teljes fájlgyorsítótár-módban). |
| Csak a kért adatok (plusz az előtárolás) lesznek beolvasva a tárolóból. | |
| Elég kicsi adatokhoz gyors RAM-alapú gyorsítótárat használunk. |
Mikor érdemes blokkalapú nyílt módot használni?
A legtöbb forgatókönyv esetében ajánlott, kivéve , ha gyors olvasásra van szüksége a véletlenszerű fájlhelyekről. Ezekben az esetekben használja a teljes fájlgyorsítótár megnyitási módját.
A teljes fájlgyorsítótár megnyitási módja
Ha egy csatlakoztatási mappa alatt lévő fájlt (például ) teljes fájl módban nyit meg, f = open(path, args)a hívás le lesz tiltva, amíg a teljes fájl le nem töltődik a lemez egyik számítási célgyorsítótár-mappájába. Minden további olvasási hívás átirányítja a gyorsítótárazott fájlba, így nincs szükség tárterület-interakcióra. Ha a gyorsítótár nem rendelkezik elegendő szabad területtel az aktuális fájlhoz, a csatlakoztatás a legkevésbé használt fájl gyorsítótárból való törlésével próbál meg metszeni. Azokban az esetekben, amikor a fájl nem fér el a lemezen (a gyorsítótár-beállítások tekintetében), az adat-futtatókörnyezet visszaáll a streamelési módra.
| Előnyök | Hátrányok |
|---|---|
| A fájl megnyitása után nincs tárolási megbízhatósági/átviteli sebességfüggőség. | A nyitott hívás a teljes fájl letöltéséig le lesz tiltva. |
| Gyors véletlenszerű olvasások (adattömbök olvasása a fájl véletlenszerű helyéről). | A teljes fájl akkor is beolvasható a tárolóból, ha a fájl bizonyos részeire nincs szükség. |
Mikor lehet használni
Ha véletlenszerű olvasásra van szükség a 128 MB-ot meghaladó, viszonylag nagy méretű fájlokhoz.
Használat
Környezeti változó DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED false beállítása a feladatban:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Csatlakoztatás: Fájlok listázása
Ha több millió fájllal dolgozik, kerülje például ls -R /mnt/dataset/folder/a rekurzív listaelemeket. A rekurzív lista számos hívást indít el a szülőkönyvtár könyvtártartalmának listázásához. Ezután minden könyvtárhoz külön rekurzív hívásra van szükség, minden gyermekszinten. Az Azure Storage általában csak 5000 elemet ad vissza egyetlen listakérésenként. Ennek eredményeképpen a 10 fájlt tartalmazó 1M-mappák rekurzív listája megköveteli 1,000,000 / 5000 + 1,000,000 = 1,000,200 a tárterületre irányuló kéréseket. Ehhez képest 10 000 10 000 fájllal rendelkező mappának csak 1001 kérésre lenne szüksége egy rekurzív lista tárolásához.
Az Azure Machine Learning-csatlakoztatás lusta módon kezeli a listaelemeket. Ezért sok kis fájl listázásához jobb, ha iteratív ügyfélkódtár-hívást használ (például os.scandir() Pythonban) a teljes listát visszaadó ügyfélkódtár-hívás helyett (például os.listdir() Pythonban). Az iteratív ügyfélkódtár-hívás egy generátort ad vissza, ami azt jelenti, hogy nem kell megvárnia, amíg a teljes lista betöltődik. Ezután gyorsabban haladhat tovább.
Ez a táblázat összehasonlítja a Python os.scandir() és os.listdir() a függvények számára szükséges időt egy ~4M-fájlokat tartalmazó mappa listázásához egy lapos struktúrában:
| Metrika | os.scandir() |
os.listdir() |
|---|---|---|
| Az első bejegyzés lekérésének ideje (másodperc) | 0,67 | 553.79 |
| Az első 50 ezer bejegyzés lekérésének ideje (másodperc) | 9.56 | 562.73 |
| Az összes bejegyzés lekérésének ideje (másodperc) | 558.35 | 582.14 |
Optimális csatlakoztatási beállítások gyakori forgatókönyvekhez
Bizonyos gyakori forgatókönyvek esetében bemutatjuk az Azure Machine Learning-feladathoz szükséges optimális csatlakoztatási beállításokat.
Nagy fájl egymás utáni olvasása (sorok feldolgozása csv fájlban)
Adja meg ezeket a csatlakoztatási beállításokat az environment_variables Azure Machine Learning-feladat szakaszában:
Feljegyzés
A kiszolgáló nélküli számítás használatához törölje compute="cpu-cluster", ezt a kódot.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Nagy fájl egyszeri olvasása több szálból (particionált CSV-fájl feldolgozása több szálon)
Adja meg ezeket a csatlakoztatási beállításokat az environment_variables Azure Machine Learning-feladat szakaszában:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Több millió kis fájl (kép) olvasása egyszerre több szálból (egyetlen korszakos betanítás képeken)
Adja meg ezeket a csatlakoztatási beállításokat az environment_variables Azure Machine Learning-feladat szakaszában:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Több millió kis fájl (kép) olvasása több szálból többször (több korszak betanítása képeken)
Adja meg ezeket a csatlakoztatási beállításokat az environment_variables Azure Machine Learning-feladat szakaszában:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Nagy fájl olvasása véletlenszerű keresésekkel (például a csatlakoztatott mappából származó fájladatbázis kiszolgálása)
Adja meg ezeket a csatlakoztatási beállításokat az environment_variables Azure Machine Learning-feladat szakaszában:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Adatbetöltési szűk keresztmetszetek diagnosztizálása és megoldása
Amikor egy Azure Machine Learning-feladat adatokat használ, a mode bemenet határozza meg, hogy a bájtok hogyan lesznek beolvasva a tárolóból, és hogyan gyorsítótárazhatók a számítási cél helyi SSD-lemezén. Letöltési mód esetén az összes adatgyorsítótár a lemezen, mielőtt a felhasználói kód elkezdené a végrehajtást. Ezért olyan tényezők, mint a
- párhuzamos szálak száma
- a fájlok száma
- fájlméret
hatással van a maximális letöltési sebességre. Csatlakoztatáshoz a felhasználói kódnak meg kell nyitnia a fájlokat, mielőtt az adatok gyorsítótárazásba kezdenének. A különböző csatlakoztatási beállítások eltérő olvasási és gyorsítótárazási viselkedést eredményeznek. Különböző tényezők befolyásolják az adatok tárolóból való betöltésének sebességét:
- A számításhoz használható adathelyesség: A tárolási és a számítási célhelynek azonosnak kell lennie. Ha a tárolási és számítási cél különböző régiókban található, a teljesítmény csökken, mert az adatoknak régiók közötti átvitelre van szükség. Ha többet szeretne tudni arról, hogyan biztosíthatja, hogy az adatok a számítással együtt legyenek helyezve, látogasson el a Colocate data with compute webhelyre.
- A számítási cél mérete: A kis számítások alacsonyabb magszámmal (kevesebb párhuzamossággal) és kisebb várható hálózati sávszélességtel rendelkeznek a nagyobb számítási méretekhez képest – mindkét tényező befolyásolja az adatbetöltés teljesítményét.
- Ha például kis virtuálisgép-méretet használ, például
Standard_D2_v2(2 mag, 1500 Mbps NIC), és 50 000 MB (50 GB) adatot próbál betölteni, a legjobban elérhető adatbetöltési idő ~270 másodperc (feltéve, hogy a hálózati adaptert 187,5 MB/s átviteli sebességgel telítette). Ezzel szemben egyStandard_D5_v2(16 magos, 12 000 Mb/s)-os adat ~33 másodperc alatt töltené be ugyanazokat az adatokat (feltételezve, hogy a hálózati adaptert 1500 MB/s átviteli sebességgel telítette).
- Ha például kis virtuálisgép-méretet használ, például
- Tárolási szint: A legtöbb forgatókönyv esetében – beleértve a nagy nyelvi modelleket (LLM) – a standard tárterület biztosítja a legjobb költség- és teljesítményprofilt. Ha azonban sok kis fájllal rendelkezik, a prémium szintű tárolás jobb költség- és teljesítményprofilt kínál. További információkért olvassa el az Azure Storage beállításait.
- Tárolási terhelés: Ha a tárfiók nagy terhelés alatt áll – például egy fürtben sok GPU-csomópont kér adatokat –, akkor fennáll a veszélye, hogy eléri a tárterület kimenő kapacitását. További információkért olvassa el a Storage-terhelést. Ha sok kis fájlhoz van hozzáférése párhuzamosan, előfordulhat, hogy eléri a tárterületre vonatkozó kérelmek korlátait. Olvassa el a szabványos tárfiókok méretezési céljainak kimenő kapacitására és tárolási kérelmeire vonatkozó korlátokra vonatkozó naprakész információkat.
- Adathozzáférési minta a felhasználói kódban: Csatlakoztatási mód használata esetén a rendszer a kódban lévő megnyitási/olvasási műveletek alapján olvassa be az adatokat. Ha például egy nagy fájl véletlenszerű szakaszait olvassa be, a csatlakoztatások alapértelmezett adatelőtöltési beállításai olyan blokkok letöltéséhez vezethetnek, amelyek nem lesznek olvashatók. Előfordulhat, hogy a maximális átviteli sebesség eléréséhez hangolnia kell néhány beállítást. További információkért olvassa el az Optimum csatlakoztatási beállításait a gyakori forgatókönyvekhez.
Naplók használata a problémák diagnosztizálásához
Az adat-futtatókörnyezet naplóinak elérése a feladatból:
- Válassza az Outputs+Logs (Kimenetek+Naplók ) lapot a feladatlapon.
- Válassza ki a system_logs mappát, majd data_capability mappát.
- Két naplófájlnak kell megjelennie:
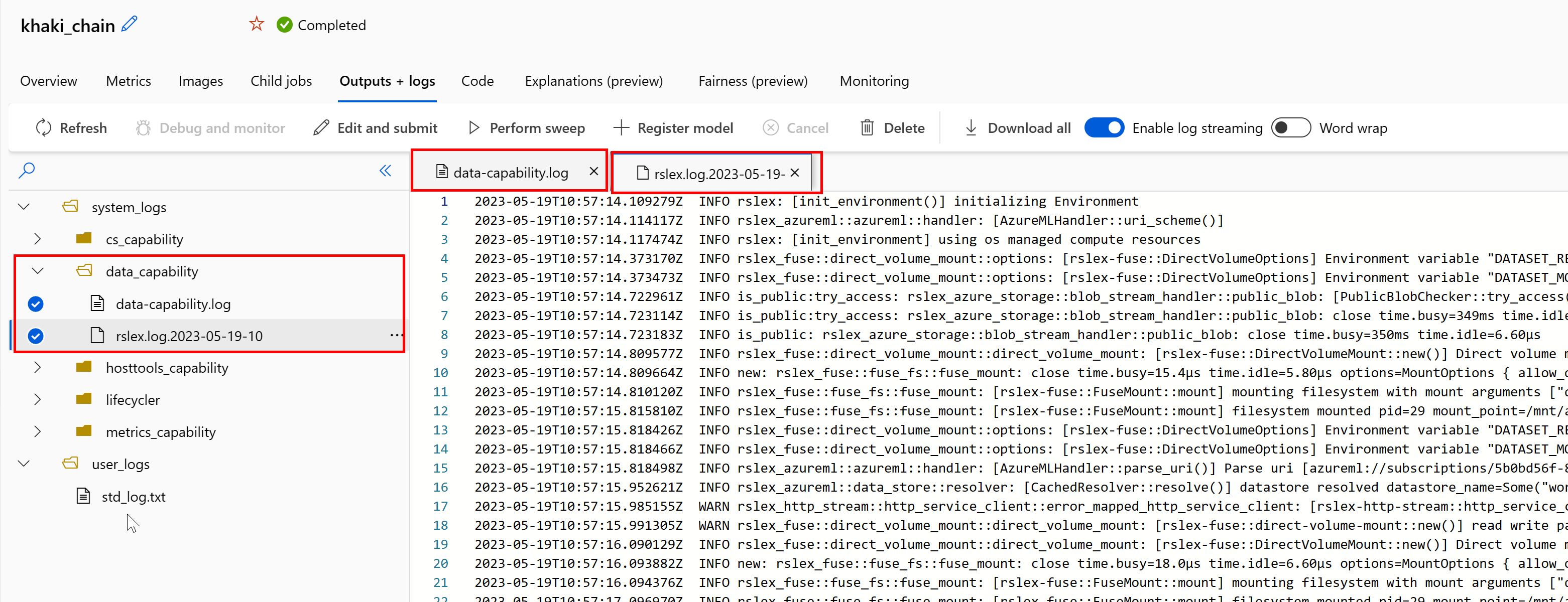

A naplófájl data-capability.log a legfontosabb adatbetöltési feladatokra fordított idő magas szintű adatait jeleníti meg. Az adatok letöltésekor például a futtatókörnyezet naplózza a letöltési tevékenység kezdési és befejezési idejét:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Ha a letöltési átviteli sebesség a virtuális gép méretéhez várt hálózati sávszélesség töredékét teszi ki, akkor a naplófájl rslex.log<.IDŐBÉLYEGZŐ>. Ez a fájl tartalmazza a Rust-alapú futtatókörnyezet összes részletes naplózását; például párhuzamosítás:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
A rslex.log fájl részletesen ismerteti az összes fájl másolását, függetlenül attól, hogy a csatlakoztatási vagy letöltési módot választotta-e. Emellett a használt beállításokat (környezeti változókat) is ismerteti. A hibakeresés megkezdéséhez ellenőrizze, hogy a gyakori forgatókönyvekhez beállította-e az Optimális csatlakoztatási beállításokat.
Az Azure Storage monitorozása
Az Azure Portalon kiválaszthatja a Tárfiókot, majd a Metrikákat a tárolási metrikák megtekintéséhez:

Ezután a SuccessE2ELatency értéket a SuccessServerLatency használatával ábrázolja. Ha a metrikák magas SuccessE2ELatency és alacsony SuccessServerLatency értéket mutatnak, korlátozottan érhetők el szálak, vagy ha alacsonyan fut az erőforrások, például a CPU, a memória vagy a hálózati sávszélesség, akkor a következőkre van szükség:
- Az Azure Machine Learning Studióban a monitorozási nézet használatával ellenőrizheti a feladat processzor- és memóriakihasználtságát. Ha kevés a processzor és a memória, fontolja meg a számítási cél virtuális gép méretének növelését.
- Érdemes lehet növelni
RSLEX_DOWNLOADER_THREADS, ha letölt, és nem használja a processzort és a memóriát. Ha csatlakoztatást használ, növelnieDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTkell az előkezelést, és növelnieDATASET_MOUNT_READ_THREADSkell az olvasási szálakat.
Ha a metrikák alacsony SuccessE2ELatency és alacsony SuccessServerLatency értéket mutatnak, de az ügyfél nagy késést tapasztal, késéssel rendelkezik a szolgáltatáshoz érő tárolási kérelemben. Ellenőrizze a következőt:
- Azt jelzi, hogy a csatlakoztatáshoz/letöltéshez (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) használt szálak száma túl alacsony-e a számítási célon elérhető magok számához képest. Ha a beállítás túl alacsony, növelje a szálak számát. - Azt jelzi, hogy a letöltési (
AZUREML_DATASET_HTTP_RETRY_COUNT) újrapróbálkozási próbálkozások száma túl magas-e. Ha igen, csökkentse az újrapróbálkozések számát.
Lemezhasználat figyelése feladat közben
Az Azure Machine Learning Studióban a számítási céllemez I/O-ját és használatát is figyelheti a feladat végrehajtása során. Lépjen a feladatra, és válassza a Figyelés lapot. Ez a lap 30 napos gördülési alapon nyújt betekintést a feladat erőforrásaiba. Példa:

Feljegyzés
A feladatfigyelés csak az Azure Machine Learning által kezelt számítási erőforrásokat támogatja. Az 5 percnél rövidebb futtatókörnyezettel rendelkező feladatok nem rendelkeznek elegendő adattal a nézet feltöltéséhez.
Az Azure Machine Learning adat-futtatókörnyezete nem használja az utolsó RESERVED_FREE_DISK_SPACE bájtnyi lemezterületet a számítás kifogástalan állapotának megőrzéséhez (az alapértelmezett érték).150MB Ha a lemez megtelt, a kód a fájlok kimenetként való deklarálása nélkül ír fájlokat a lemezre. Ezért ellenőrizze a kódot, hogy az adatok ne legyenek hibásan megírva az ideiglenes lemezre. Ha ideiglenes lemezre kell fájlokat írnia, és az erőforrás megtelik, fontolja meg a következő szempontokat:
- A virtuális gép méretének növelése nagyobb ideiglenes lemezzel rendelkezőre
- TTL beállítása a gyorsítótárazott adatokon (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) az adatok lemezről való törléséhez
Adatok áthelyezése számítással
Figyelemfelhívás
Ha a tárolás és a számítás különböző régiókban található, a teljesítmény csökken, mert az adatoknak régiók közötti átvitelre van szükség. Ez növeli a költségeket. Győződjön meg arról, hogy a tárfiók és a számítási erőforrások ugyanabban a régióban találhatók.
Ha az adatok és az Azure Machine Learning-munkaterület különböző régiókban vannak tárolva, javasoljuk, hogy másolja az adatokat egy ugyanabban a régióban lévő tárfiókba az azcopy segédprogrammal. Az AzCopy kiszolgálóról kiszolgálóra történő API-kat használ, így az adatok közvetlenül a tárolókiszolgálók között másolnak. Ezek a másolási műveletek nem használják a számítógép hálózati sávszélességét. A környezeti változóval növelheti ezeknek a műveleteknek az átviteli sebességét AZCOPY_CONCURRENCY_VALUE . További információ: Egyidejűség növelése.
Tárterület terhelése
Egy tárfiók szabályozható, ha nagy terhelés alatt áll, amikor:
- A feladat sok GPU-csomópontot használ
- A tárfiók számos egyidejű felhasználóval/alkalmazással rendelkezik, amelyek a feladat futtatásakor férnek hozzá az adatokhoz
Ez a szakasz azokat a számításokat mutatja be, hogy a szabályozás problémát jelenthet-e a számítási feladat számára, és hogyan közelítheti meg a szabályozás csökkentésének módját.
Sávszélességkorlátok kiszámítása
Az Azure Storage-fiókok alapértelmezett kimenőforgalom-korlátja 120 Gbit/s. Az Azure-beli virtuális gépek eltérő hálózati sávszélességekkel rendelkeznek, amelyek hatással vannak a maximális alapértelmezett tárolókapacitás eléréséhez szükséges számítási csomópontok elméleti számára:
| Méret | GPU-kártya | vCPU | Memória: GiB | Ideiglenes tárterület (SSD) GiB | GPU-kártyák száma | GPU-memória: GiB | Várható hálózati sávszélesség (Gbit/s) | Tárfiók kimenő forgalmának alapértelmezett maximális száma (Gbit/s)* | Az alapértelmezett kimenő kapacitást elérő csomópontok száma |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 0 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 0 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 0 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 0 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Az A100/V100 SKU-k maximális hálózati sávszélessége csomópontonként 24 Gbit/s. Ha minden olyan csomópont, amely egyetlen fiókból olvas be adatokat, közel az elméleti maximum 24 Gbit/s-hoz tud olvasni, a kimenő kapacitás öt csomóponttal fog történni. Hat vagy több számítási csomópont használata az összes csomópont adatátengedési sebességének romlásához kezdene.
Fontos
Ha a számítási feladatnak több mint 6 csomópontra van szüksége az A100/V100-hoz, vagy úgy véli, hogy túllépi az alapértelmezett tárolókapacitást (120 Gbit/s), forduljon az ügyfélszolgálathoz (az Azure Portalon keresztül), és kérje a tárterület kimenő forgalmának korlátjának növelését.
Több tárfiók skálázása
Előfordulhat, hogy túllépi a tárterület maximális kimenő kapacitását, és/vagy eléri a kérelmek sebességkorlátját. Ha ezek a problémák jelentkeznek, javasoljuk, hogy először forduljon az ügyfélszolgálathoz, hogy növelje a tárfiókra vonatkozó korlátokat.
Ha nem tudja növelni a maximális kimenő kapacitást vagy a kérelmek sebességkorlátját, érdemes lehet több tárfiókban replikálni az adatokat. Másolja az adatokat több fiókba az Azure Data Factory, az Azure Storage Explorer vagy azcopyaz azure storage explorer használatával, és csatlakoztassa az összes fiókot a betanítási feladathoz. A rendszer csak a csatlakoztatáson elért adatokat tölti le. Ezért a betanítási kód beolvassa a RANK környezeti változóból, és kiválaszthatja, hogy a több bemenet közül melyiket szeretné olvasni. A feladatdefiníció a tárfiókok listájában halad át:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
A betanítási Python-kód ezután az adott csomóponthoz tartozó tárfiók lekérésére használható RANK :
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Sok kis méretű fájllal probléma
A fájlok storage-ból való olvasása minden fájlra vonatkozó kéréseket igényel. A kérések száma fájlonként eltérő a fájlméretek és a fájlolvasásokat kezelő szoftver beállításai alapján.
A fájlok általában 1-4 MB méretű blokkokban olvashatók. A blokknál kisebb fájlokat egyetlen kérelem (GET file.jpg 0-4 MB) olvassa be, a blokknál nagyobb fájlok blokkonként egy kéréssel rendelkeznek (GET file.jpg 0-4 MB, GET file.jpg 4-8 MB). Ez a táblázat azt mutatja, hogy a 4 MB-os blokknál kisebb fájlok több tárolási kérést eredményeznek a nagyobb fájlokhoz képest:
| # Fájlok | Fájlméret | Teljes adatméret | Blokkméret | # Tárolási kérelmek |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 TB | 4 MB | 2,000,000 |
| 1000 | 1 GB | 1 TB | 4 MB | 256,000 |
A kis méretű fájlok esetében a késési időköz általában a tárterületre irányuló kérések kezelését foglalja magában az adatátvitel helyett. Ezért ezeket a javaslatokat ajánljuk a fájlméret növeléséhez:
- Strukturálatlan adatok (képek, szöveg, videó stb.), archív (zip/tar) kis fájlok együtt tárolására, hogy tárolja őket, mint egy nagyobb fájl, amely több adattömbben olvasható. Ezek a nagyobb archivált fájlok megnyithatók a számítási erőforrásban, a PyTorch Archive DataPipes pedig kinyerheti a kisebb fájlokat.
- Strukturált adatok (CSV, parquet stb.) esetén vizsgálja meg az ETL-folyamatot, és győződjön meg arról, hogy a fájlokat a méret növelése érdekében javítja. A Spark a
repartition()fájlméretek növelését segítő módszerekkel éscoalesce()módszerekkel rendelkezik.
Ha nem tudja növelni a fájlméreteket, ismerkedjen meg az Azure Storage beállításaival.
Az Azure Storage beállításai
Az Azure Storage két szintet kínál – standard és prémium:
| Tárolás | Eset |
|---|---|
| Azure Blob – Standard (HDD) | Az adatok nagyobb blobokban – képekben, videókban stb. |
| Azure Blob – Prémium (SSD) | Magas tranzakciós sebesség, kisebb objektumok vagy következetesen alacsony tárolási késési követelmények |
Tipp.
A "sok" kis méretű fájlok (KB-nagyságrend) esetében a prémium (SSD) használatát javasoljuk, mivel a tárterület költsége kisebb, mint a GPU-számítások futtatásának költsége.
V1-adategységek olvasása
Ez a szakasz bemutatja, hogyan olvashatók be a V1 FileDataset és TabularDataset az adatentitások egy V2-feladatban.
Olvasás FileDataset
Az objektumban Input adja meg a type következőt AssetTypes.MLTABLE InputOutputModes.EVAL_MOUNT:mode
Feljegyzés
A kiszolgáló nélküli számítás használatához törölje compute="cpu-cluster", ezt a kódot.
Az MLClient objektumról, az MLClient objektum inicializálási beállításairól és a munkaterülethez való csatlakozásról a Csatlakozás munkaterülethez című témakörben talál további információt.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Olvasás TabularDataset
Az objektumban Input adja meg a type következőt AssetTypes.MLTABLEés mode a következőt InputOutputModes.DIRECT:
Feljegyzés
A kiszolgáló nélküli számítás használatához törölje compute="cpu-cluster", ezt a kódot.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Következő lépések
- Modellek betanítása
- Oktatóanyag: Éles gépi tanulási folyamatok létrehozása a Python SDK 2-es verzióval
- További információ az Azure Machine Learning adatairól