Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azure-ai-ml v2 (aktuális)
Python SDK azure-ai-ml v2 (aktuális)
Feljegyzés
Az SDK v1-et egy folyamat létrehozásához használó oktatóanyagért lásd : Oktatóanyag: Azure Machine Learning-folyamat létrehozása képosztályozáshoz
A gépi tanulási folyamat lényege, hogy egy teljes gépi tanulási feladatot feloszt egy többhelyes munkafolyamatra. Minden lépés egy kezelhető összetevő, amely egyenként fejleszthető, optimalizálható, konfigurálható és automatizálható. A lépések jól definiált felületeken keresztül kapcsolódnak egymáshoz. Az Azure Machine Learning folyamatszolgáltatás automatikusan vezénylik a folyamatlépések közötti összes függőséget. A pipeline használatának előnyei az MLOps gyakorlat standardizálása, a skálázható csapatmunka, a betanulási hatékonyság és a költségcsökkentés. A folyamatok előnyeiről további információt az Azure Machine Learning-folyamatok ismertetése című témakörben talál.
Ebben az oktatóanyagban az Azure Machine Learning használatával hoz létre egy éles üzemre kész gépi tanulási projektet az Azure Machine Learning Python SDK 2-s verziójával. Ez azt jelenti, hogy az Azure Machine Learning Python SDK-t a következőkre használhatja:
- Fogópont lekérése az Azure Machine Learning-munkaterületre
- Azure Machine Learning-adategységek létrehozása
- Újrafelhasználható Azure Machine Learning-összetevők létrehozása
- Azure Machine Learning-folyamatok létrehozása, ellenőrzése és futtatása
Ebben az oktatóanyagban létrehoz egy Azure Machine Learning-folyamatot, amely betanít egy modellt a hitel alapértelmezett előrejelzéséhez. A folyamat két lépést kezel:
- Adatok előkészítése
- A betanított modell betanítása és regisztrálása
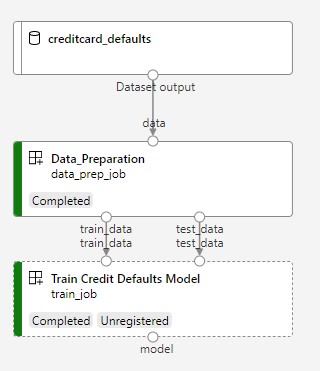
A következő képen egy egyszerű folyamat látható, amint azt az Azure Studióban fogja látni, miután beküldte.
A két lépés az első adatelőkészítés és a második betanítás.
Ez a videó bemutatja, hogyan kezdheti meg az Azure Machine Learning Studiót, hogy követni tudja az oktatóanyag lépéseit. A videó bemutatja, hogyan hozhat létre jegyzetfüzetet, hozhat létre számítási példányt, és klónozhatja a jegyzetfüzetet. A lépéseket a következő szakaszokban is ismertetjük.
Előfeltételek
-
Az Azure Machine Learning használatához munkaterületre van szüksége. Ha nem rendelkezik ilyen erőforrással, végezze el a munkaterület létrehozásához szükséges erőforrások létrehozását, és tudjon meg többet a használatáról.
Fontos
Ha az Azure Machine Learning-munkaterület felügyelt virtuális hálózattal van konfigurálva, előfordulhat, hogy kimenő szabályokat kell hozzáadnia a nyilvános Python-csomagtárakhoz való hozzáférés engedélyezéséhez. További információ: Forgatókönyv: Nyilvános gépi tanulási csomagok elérése.
-
Jelentkezzen be a stúdióba , és válassza ki a munkaterületet, ha még nincs megnyitva.
Végezze el az oktatóanyagot az adatok feltöltéséhez, eléréséhez és feltárásához, hogy létrehozza az ebben az oktatóanyagban szükséges adategységet. Győződjön meg arról, hogy az összes kódot futtatja a kezdeti adategység létrehozásához. Megismerheti az adatokat, és szükség esetén felülvizsgálhatja azokat, de ebben az oktatóanyagban csak a kezdeti adatokra van szüksége.
-
Jegyzetfüzet megnyitása vagy létrehozása a munkaterületen:
- Ha kódot szeretne másolni és beilleszteni a cellákba, hozzon létre egy új jegyzetfüzetet.
- Vagy nyisson meg oktatóanyagokat/get-started-notebooks/pipeline.ipynb-t a Studio Minták szakaszából. Ezután válassza a Klónozás lehetőséget a jegyzetfüzet fájlokhoz való hozzáadásához. A mintajegyzetfüzetek megkereséséhez lásd : Learn from sample notebooks.
A kernel beállítása és megnyitása a Visual Studio Code-ban (VS Code)
A megnyitott jegyzetfüzet fölötti felső sávon hozzon létre egy számítási példányt, ha még nem rendelkezik ilyenrel.

Ha a számítási példány le van állítva, válassza a Számítás indítása lehetőséget, és várja meg, amíg fut.

Várjon, amíg a számítási példány fut. Ezután győződjön meg arról, hogy a jobb felső sarokban található kernel az
Python 3.10 - SDK v2. Ha nem, válassza ki a kernelt a legördülő listából.
Ha nem látja ezt a kernelt, ellenőrizze, hogy fut-e a számítási példány. Ha igen, válassza a jegyzetfüzet jobb felső sarkában található Frissítés gombot.
Ha megjelenik egy szalagcím, amely azt jelzi, hogy hitelesíteni kell, válassza a Hitelesítés lehetőséget.
A jegyzetfüzetet itt futtathatja, vagy megnyithatja a VS Code-ban egy teljes integrált fejlesztési környezethez (IDE) az Azure Machine Learning-erőforrások segítségével. Válassza a Megnyitás a VS Code-ban lehetőséget, majd válassza a webes vagy asztali lehetőséget. Ha így indul el, a VS Code a számítási példányhoz, a kernelhez és a munkaterület fájlrendszeréhez lesz csatolva.





Fontos
Az oktatóanyag többi része az oktatóanyag-jegyzetfüzet celláit tartalmazza. Másolja és illessze be őket az új jegyzetfüzetbe, vagy váltson most a jegyzetfüzetre, ha klónozta.
A folyamat erőforrásainak beállítása
Az Azure Machine Learning-keretrendszer parancssori felületről, Python SDK-ból vagy stúdiófelületről is használható. Ebben a példában az Azure Machine Learning Python SDK v2 használatával hoz létre egy folyamatot.
A folyamat létrehozása előtt az alábbi erőforrásokra van szüksége:
- Az adategység a betanításhoz
- A folyamat futtatásához használandó szoftverkörnyezet
- Számítási erőforrás, ahová a feladat fut
Leíró létrehozása munkaterületre
Mielőtt belemerülnénk a kódba, szüksége lesz egy módszerre a munkaterületre való hivatkozáshoz. Te létrehozol ml_client a munkaterület leírójához. Ezután a ml_client segítségével kezelheti az erőforrásokat és a feladatokat.
A következő cellába írja be az előfizetés azonosítóját, az erőforráscsoport nevét és a munkaterület nevét. Az alábbi értékek megkeresése:
- A jobb felső Azure Machine Learning Studio eszköztáron válassza ki a munkaterület nevét.
- Másolja a munkaterület, az erőforráscsoport és az előfizetés azonosítójának értékét a kódba.
- Ki kell másolnia egy értéket, be kell zárnia a területet, és be kell illesztenie, majd vissza kell térnie a következőhöz.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
SDK-referencia:
Feljegyzés
Az MLClient létrehozása nem fog csatlakozni a munkaterülethez. Az ügyfél inicializálása lusta, az első alkalommal várakozik, amikor hívást kell kezdeményeznie (ez a következő kódcellában történik).
Ellenőrizze a kapcsolatot a következő hívással ml_client: . Mivel ez az első alkalom, hogy hívást kezdeményez a munkaterületre, a rendszer megkérheti a hitelesítésre.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
SDK-referencia:
Hozzáférés a regisztrált adategységhez
Első lépésként lekérte a korábban regisztrált adatokat az oktatóanyagban : Adatok feltöltése, elérése és megismerése az Azure Machine Learningben.
- Az Azure Machine Learning objektummal
Dataregisztrálja az adatok újrafelhasználható definícióját, és felhasználja az adatokat egy folyamaton belül.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
SDK-referencia:
Feladatkörnyezet létrehozása folyamatlépésekhez
Eddig egy fejlesztői környezetet hozott létre a számítási példányon, a fejlesztői gépen. A folyamat minden lépéséhez szükség van egy környezetre is. Minden lépésnek lehet saját környezete, vagy használhat néhány gyakori környezetet több lépéshez is.
Ebben a példában conda környezetet hoz létre a feladatokhoz egy conda yaml-fájl használatával. Először hozzon létre egy könyvtárat a fájl tárolásához.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Most hozza létre a fájlt a függőségek könyvtárában.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
A specifikáció tartalmaz néhány, a folyamatban használt szokásos csomagot (numpy, pip), valamint néhány Azure Machine Learning-specifikus csomagot (azureml-mlflow).
Az Azure Machine Learning-csomagok nem kötelezőek az Azure Machine Learning-feladatok futtatásához. Ezeknek a csomagoknak a hozzáadásával azonban kezelheti az Azure Machine Learninget a metrikák naplózásához és a modellek regisztrálásához, mindezt az Azure Machine Learning-feladatban. Az oktatóanyag későbbi részében a betanítási szkriptben használhatja őket.
A yaml-fájl használatával hozza létre és regisztrálja ezt az egyéni környezetet a munkaterületen:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
SDK-referencia:
A betanítási folyamat létrehozása
Most, hogy rendelkezik a folyamat futtatásához szükséges összes eszközzel, ideje saját maga létrehozni a folyamatot.
Az Azure Machine Learning-folyamatok olyan újrafelhasználható ML-munkafolyamatok, amelyek általában több összetevőből állnak. Az összetevők tipikus élettartama a következő:
- Írja meg az összetevő yaml-specifikációját, vagy hozza létre programozott módon a használatával
ComponentMethod. - Ha szeretné, regisztrálja az összetevőt egy névvel és verzióval a munkaterületen, hogy újrafelhasználható és megosztható legyen.
- Töltse be az összetevőt a folyamatkódból.
- Implementálja a folyamatot az összetevő bemenetei, kimenetei és paraméterei alapján.
- Küldje el a folyamatot.
Az összetevő kétféleképpen hozható létre: programozott és yaml definíció. A következő két szakasz végigvezeti egy összetevő mindkét módon történő létrehozásán. Létrehozhatja a két összetevőt, és mindkét lehetőséget kipróbálhatja, vagy kiválaszthatja az előnyben részesített módszert.
Feljegyzés
Ebben az oktatóanyagban az egyszerűség kedvéért ugyanazt a számítást használjuk az összes összetevőhöz. Az egyes összetevőkhöz azonban különböző számításokat állíthat be, például egy olyan sor hozzáadásával, mint a train_step.compute = "cpu-cluster". Ha egy olyan folyamatot szeretne létrehozni, amely különböző számításokat tartalmaz az egyes összetevőkhöz, tekintse meg a Cifar-10 folyamat oktatóanyagának Alapszintű folyamatfeladat szakaszát.
1. összetevő létrehozása: adat-előkészítés (programozott definíció használatával)
Először hozza létre az első összetevőt. Ez az összetevő kezeli az adatok előfeldolgozását. Az előfeldolgozási feladat a data_prep.py Python-fájlban történik.
Először hozzon létre egy forrásmappát a data_prep összetevőhöz:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Ez a szkript az adatok betanítási és tesztelési adatkészletekre való felosztásának egyszerű feladatát hajtja végre. Az Azure Machine Learning mappákként csatlakoztatja az adathalmazokat a számításokhoz, ezért létrehoztunk egy segédfüggvényt select_first_file , amely a csatlakoztatott bemeneti mappában lévő adatfájlhoz fér hozzá.
Az MLFlow a folyamatok futtatása során naplózza a paramétereket és a metrikákat.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Most, hogy rendelkezik egy szkripttel, amely képes elvégezni a kívánt feladatot, hozzon létre belőle egy Azure Machine Learning-összetevőt.
Használja a parancssori műveletek futtatására szolgáló általános célt CommandComponent . Ez a parancssori művelet közvetlenül meghívhatja a rendszerparancsokat, vagy szkriptet futtathat. A bemenetek/kimenetek a parancssorban a jelölésen keresztül ${{ ... }} vannak megadva.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
SDK-referencia:
Ha szeretné, regisztrálja az összetevőt a munkaterületen a későbbi újrafelhasználáshoz.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
SDK-referencia:
2. összetevő létrehozása: betanítás (yaml-definíció használatával)
A második létrehozott összetevő felhasználja a betanítási és tesztelési adatokat, betanított egy faalapú modellt, és visszaadja a kimeneti modellt. Az Azure Machine Learning naplózási képességeivel rögzíthet és megjeleníthet tanulási folyamatokat.
Az osztály használatával CommandComponent hozta létre az első összetevőt. Ezúttal a yaml-definícióval definiálja a második összetevőt. Minden módszernek megvannak a maga előnyei. A yaml-definíciók ténylegesen beadhatók a kód mentén, és olvasható előzménykövetést biztosítanak. A programozott módszer használata CommandComponent egyszerűbb lehet a beépített osztálydokumentációval és a kódkiegészítéssel.
Hozza létre az összetevő könyvtárát:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Hozza létre a betanítási szkriptet a könyvtárban:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Ahogy ebben a betanítási szkriptben látható, a modell betanítása után a rendszer menti és regisztrálja a modellfájlt a munkaterületen. Most már használhatja a regisztrált modellt a végpontok következtetéséhez.
A lépés környezetéhez az egyik beépített (válogatott) Azure Machine Learning-környezetet kell használnia. A címke azuremlarra utasítja a rendszert, hogy a kijelölt környezetekben keresse meg a nevet.
Először hozza létre az összetevőt leíró yaml-fájlt :
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Most hozza létre és regisztrálja az összetevőt. A regisztrációval újra felhasználhatja más folyamatokban. Emellett a munkaterülethez hozzáféréssel rendelkezők is használhatják a regisztrált összetevőt.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
SDK-referencia:
A folyamat létrehozása összetevőkből
Most, hogy mindkét összetevő definiálva és regisztrálva lett, megkezdheti a folyamat implementálását.
Itt bemeneti adatokat, felosztási arányt és regisztrált modellnevet használ bemeneti változóként. Ezután hívja meg az összetevőket, és csatlakoztassa őket a bemeneti/kimeneti azonosítójukon keresztül. Az egyes lépések kimenetei a .outputs tulajdonságon keresztül érhetők el.
A load_component() által visszaadott Python-függvények úgy működnek, mint bármely szokásos Python-függvény, amelyet a folyamat során használ az egyes lépések meghívásához.
A folyamat kódolásához egy adott @dsl.pipeline dekorátort használ, amely azonosítja az Azure Machine Learning-folyamatokat. A dekorátorban megadhatja a folyamat leírását és az alapértelmezett erőforrásokat, például a számítást és a tárolást. A Python-függvényekhez hasonlóan a folyamatok is tartalmazhatnak bemeneteket. Ezután létrehozhat egy folyamat több példányát különböző bemenetekkel.
Itt bemeneti adatokat, felosztási arányt és regisztrált modellnevet használ bemeneti változóként. Ezután meghívja az összetevőket, és csatlakoztatja őket a bemeneti/kimeneti azonosítójukon keresztül. Az egyes lépések kimenetei a .outputs tulajdonságon keresztül érhetők el.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
SDK-referencia:
Most használja a folyamatdefiníciót egy folyamat példányosításához az adatkészlettel, a választható felosztási aránysal és a modellhez választott névvel.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
SDK-referencia:
Feladat küldése
Itt az ideje, hogy elküldje a feladatot az Azure Machine Learningben való futtatáshoz. Ezúttal a következőt használja create_or_update : ml_client.jobs.
Itt egy kísérlet nevét is átadhatja. A kísérlet egy tároló egy adott projekten végzett összes iterációhoz. Az azonos kísérletnévvel elküldött összes feladat egymás mellett szerepelne az Azure Machine Learning Studióban.
A folyamat a betanítás eredményeként regisztrál egy modellt a munkaterületen.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
SDK-referencia:
A folyamat előrehaladását az előző cellában létrehozott hivatkozással követheti nyomon. Amikor először kiválasztja ezt a hivatkozást, láthatja, hogy a folyamat továbbra is fut. Ha elkészült, megvizsgálhatja az egyes összetevők eredményeit.
Kattintson duplán az Alapértelmezett kreditek betanítása modell összetevőre.
Két fontos eredményt szeretne látni a betanításról:
A naplók megtekintése:
- Válassza a Kimenetek+naplók lapot.
- Nyissa meg a mappákat az Ez a
user_logs>std_log.txtszakasz a szkript futási szakaszát mutatja.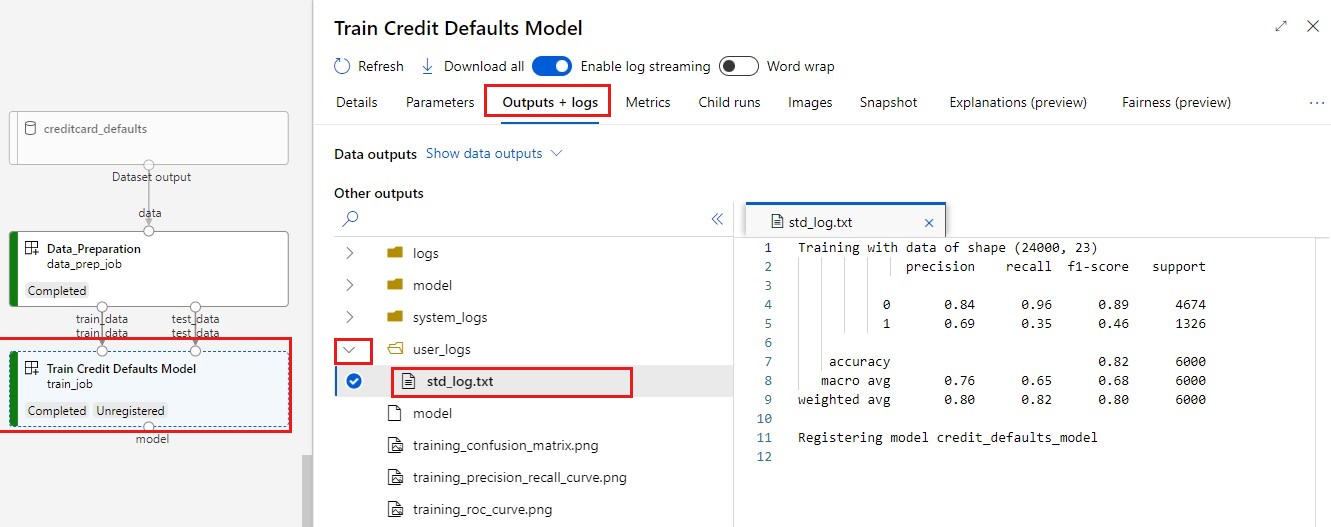
A metrikák megtekintése: Válassza a Metrikák lapot. Ez a szakasz különböző naplózott metrikákat mutat be. Ebben a példában az mlflow
autologgingautomatikusan naplózza a betanítási metrikákat.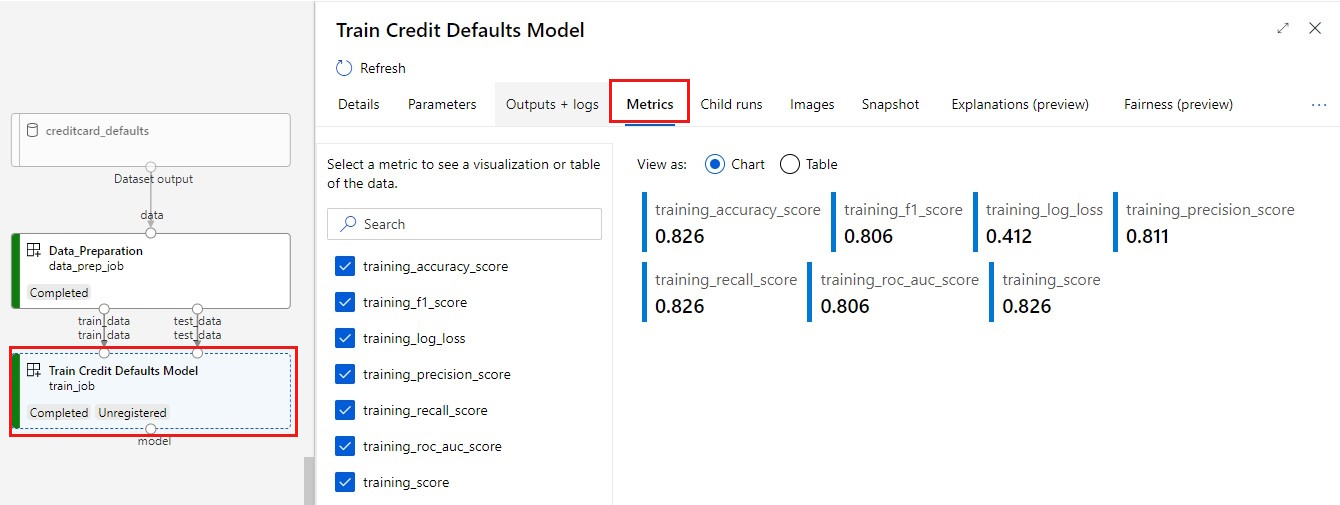


A modell üzembe helyezése online végpontként
A modell online végponton való üzembe helyezésének megismeréséhez tekintse meg a modell online végpontként való üzembe helyezését ismertető oktatóanyagot.
Az erőforrások eltávolítása
Ha most más oktatóanyagokra szeretne továbblépni, ugorjon a Következő lépésekre.
Számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldali paneljén válassza a Számítás lehetőséget.
- A felső lapokban válassza a Számítási példányok lehetőséget
- Válassza ki a számítási példányt a listában.
- A felső eszköztáron válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine Learning-oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portal keresőmezőjében adja meg az erőforráscsoportokat , és válassza ki az eredmények közül.
A listából válassza ki a létrehozott erőforráscsoportot.
Az Áttekintés lapon válassza az Erőforráscsoport törlése lehetőséget.
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
A gépi tanulási folyamat feladatainak ütemezése